并查集(算法)
目录
- 一、并查集的概念
- 二、并查集的使用
-
- 合并集合
- 连通块中点的数量
- 食物链
-
- 带权并查集
- 扩展域并查集
一、并查集的概念
最裸并查集:
-
将两个集合合并。
-
询问两个元素是否在一个集合当中 ,近乎 O ( 1 ) O(1) O(1) 时间内支持两个操作
基本原理:每个集合用一棵树来表示,树根的编号就是整个集合的编号,每个节点存储它的父节点,p[x]表示x的父节点。
- 如何判断树根?
if (p[x] == x)
- 如何求x的集合编号?
// 暴力遍历
while (p[x] != x) x = p[x];
// 路径压缩优化
int find(int x)
{
while (p[x] != x) p[x] = find(p[x]);
return p[x];
}
此方法要层层遍历父节点来得到根节点 O ( n ) O(n) O(n)
n - 树的高度
优化方法:①路径压缩(常用) ②按秩合并 ③启发式合并
- 如何合并两个集合?
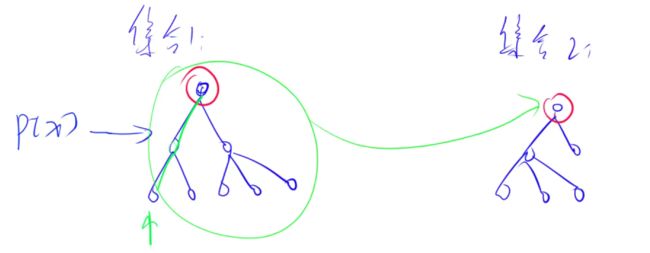
// p[x]是x的集合编号,p[y]是y的集合编号
p[x] = y;
二、并查集的使用
合并集合
题目描述:
一共有 n n n 个数,编号是 1 ∼ n 1∼n 1∼n,最开始每个数各自在一个集合中。
现在要进行 m m m 个操作,操作共有两种:
M a b,将编号为a和b的两个数所在的集合合并,如果两个数已经在同一个集合中,则忽略这个操作;Q a b,询问编号为a和b的两个数是否在同一个集合中;
输入格式:
第一行输入整数 n n n 和 m m m。
接下来 m m m 行,每行包含一个操作指令,指令为 M a b 或 Q a b 中的一种。
输出格式:
对于每个询问指令 Q a b,都要输出一个结果,如果 a 和 b 在同一集合内,则输出 Yes,否则输出 No。
每个结果占一行。
数据范围:
1 ≤ n ≤ 1 0 5 1≤n≤10^5 1≤n≤105
1 ≤ m ≤ 1 0 5 1≤m≤10^5 1≤m≤105
输入样例:
4 5
M 1 2
M 3 4
Q 1 2
Q 1 3
Q 3 4
输出样例:
Yes
No
Yes
代码实现:
#define _CRT_SECURE_NO_WARNINGS
#include连通块中点的数量
题目描述:
给定一个包含 n n n 个点(编号为 1 ∼ n 1∼n 1∼n)的无向图,初始时图中没有边。
现在要进行 m m m 个操作,操作共有三种:
C a b:在点 a a a 和点 b b b 之间连一条边, a a a 和 b b b 可能相等;Q1 a b:询问点 a a a 和点 b b b 是否在同一个连通块中, a a a 和 b b b 可能相等;Q2 a:询问点 a a a 所在连通块中点的数量;
输入格式:
第一行输入整数 n n n 和 m m m。接下来 m m m 行,每行包含一个操作指令,指令为 C a b,Q1 a b 或 Q2 a 中的一种。
输出格式:
对于每个询问指令 Q1 a b,如果 a a a 和 b b b 在同一个连通块中,则输出 Yes,否则输出 No。
对于每个询问指令 Q2 a,输出一个整数表示点 a a a 所在连通块中点的数量。
每个结果占一行。
数据范围:
1 ≤ n ≤ 1 0 5 1≤n≤10^5 1≤n≤105
1 ≤ m ≤ 1 0 5 1≤m≤10^5 1≤m≤105
输入样例:
5 5
C 1 2
Q1 1 2
Q2 1
C 2 5
Q2 5
输出样例:
Yes
2
3
分析:
并查集 + 附加信息,附加信息为家族中成员的数量,需要一个额外的数组 c n t [ N ] cnt[N] cnt[N]。记录以结点i为根的的家族成员数量。
与最祼并查集的区别:
-
初始化时,需要将 c n t [ i ] = 1 cnt[i]=1 cnt[i]=1(每次操作为一个点,故初始化为1)
-
合并时,需要 c n t [ f i n d ( b ) ] + = c n t [ f i n d ( a ) ] cnt[find(b)] += cnt[find(a)] cnt[find(b)]+=cnt[find(a)](利用根节点来计数)
-
查询时,返回 c n t [ f i n d ( a ) ] cnt[find(a)] cnt[find(a)]
代码实现:
#define _CRT_SECURE_NO_WARNINGS
#include食物链
题目描述:
动物王国中有三类动物 A , B , C A,B,C A,B,C,这三类动物的食物链构成了有趣的环形。
A A A 吃 B B B, B B B 吃 C C C, C C C 吃 A A A。
现有 n n n 个动物,以 1 ∼ n 1∼n 1∼n 编号。
每个动物都是 A , B , C A,B,C A,B,C 中的一种,但是我们并不知道它到底是哪一种。
有人用两种说法对这 n n n 个动物所构成的食物链关系进行描述:
第一种说法是 1 X Y,表示 X X X 和 Y Y Y 是同类。
第二种说法是 2 X Y,表示 X X X 吃 Y Y Y。
此人对 n n n 个动物,用上述两种说法,一句接一句地说出 m m m 句话,这 m m m 句话有的是真的,有的是假的。
当一句话满足下列三条之一时,这句话就是假话,否则就是真话。
当前的话与前面的某些真的话冲突,就是假话;
当前的话中 X X X 或 Y Y Y 比 N N N 大,就是假话;
当前的话表示 X X X 吃 X X X,就是假话。
你的任务是根据给定的 n n n 和 m m m 句话,输出假话的总数。
输入格式:
第一行是两个整数 n n n 和 m m m,以一个空格分隔。
以下 K K K 行每行是三个正整数 D , X , Y D,X,Y D,X,Y,两数之间用一个空格隔开,其中 D D D 表示说法的种类。
若 D = 1 D = 1 D=1,则表示 X X X 和 Y Y Y 是同类。
若 D = 2 D = 2 D=2,则表示 X X X 吃 Y Y Y。
输出格式:
只有一个整数,表示假话的数目。
数据范围:
1 ≤ n ≤ 50000 1≤n≤50000 1≤n≤50000
0 ≤ m ≤ 100000 0≤m≤100000 0≤m≤100000
输入样例:
100 7
1 101 1
2 1 2
2 2 3
2 3 3
1 1 3
2 3 1
1 5 5
输出样例:
3
带权并查集
思路:
功能:查询祖先+修改父节点为祖先+更新节点到根的距离(通过到父节点的距离累加和)
d [ i ] d[i] d[i] 的含义:第 i i i 个节点到其父节点距离。

代码实现:
#define _CRT_SECURE_NO_WARNINGS
#include扩展域并查集
思路:
1 ∼ n 1∼n 1∼n个元素扩大为 1 ∼ 3 n 1∼3n 1∼3n个元素,使用 [ 1 ∼ 3 n ] [1∼3n] [1∼3n]个并查集(每一个并查集中的所有元素都具有同一种特性,不同并查集中不存在相同元素)来维护3n元素彼此的关系。
为了形象化思考问题,我们假设三种动物,互为食物链: A 、 B 、 C A、B、C A、B、C关系为:
- A A A 捕食 B B B
- B B B 捕食 C C C
- C C C 捕食 A A A
在这里 x x x元素, x + n x+n x+n元素, x + 2 n x+2n x+2n元素三者的关系被定义为:
-
x x x元素的 p [ x ] p[x] p[x]代表 x x x家族
-
x + n x+n x+n元素的 p [ x + n ] p[x+n] p[x+n]代表 x x x的天敌家族
-
x + 2 n x+2n x+2n元素的 p [ x + 2 n ] p[x+2n] p[x+2n]代表 x x x的猎物家族
对于一句真话:
-
当 x x x和 y y y是同类
- 将他们的天敌集合( x + n x+n x+n与 y + n y+n y+n所在集合)合并
- 将猎物集合( x + 2 n x+2n x+2n元素与 y + 2 n y+2n y+2n元素所在集合)合并
- 将 x , y x,y x,y所在的集合 合并
-
当 x x x是 y y y的天敌
- 将x家族与y的天敌家族合并
- 将y家族和x的猎物家族合并
- 将x的天敌家族和y的猎物家族合并
代码实现:
#define _CRT_SECURE_NO_WARNINGS
#include