HBase 的关键流程解析
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
正文

HBase 客户端会将查询过的 HRegion 的位置信息进行缓存,如果客户端没有缓存一个HRegion 的位置或者位置信息是不正确的,客户端会重新获取位置信息。
如果客户端的缓存全部失效,则需要进行多次网络访问才能定位到正确的位置。
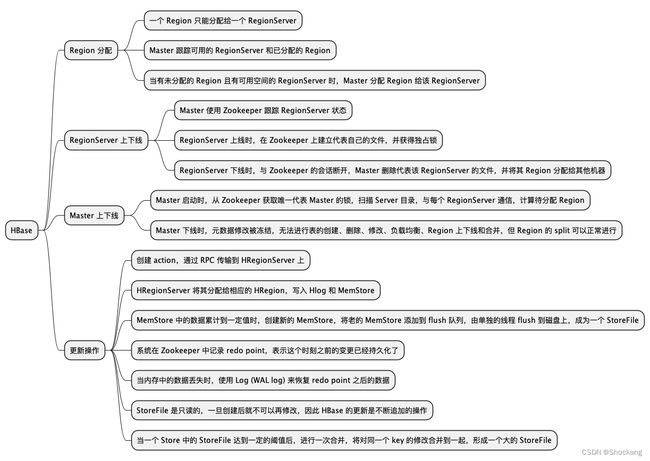
1. Region 的分配
任何时刻,一个Region 只能分配给一个 RegionServer。
Master 跟踪当前有哪些可用的 RegionServer,以及当前哪些 Region 分配给了哪些 RegionServer,哪些Region 还没有分配。
当存在未分配的 Region 且有一个RegionServer 上有可用空间时,Master 就给这个RegionServer 发送一个装载请求,把 Region 分配给这个 RegionServer。
RegionServer 得到请求后,就开始对此 Region 提供服务。
2. RegionServer 上线
Master 使用 Zookeeper 来跟踪 RegionServer 状态。
当某个 RegionServer 启动时,会首先在 ZooKeeper 上的 rs 目录下建立代表自己的文件,并获得该文件的独占锁。
由于 Master 订阅了rs目录上的变更消息,当rs目录下的文件出现新增或删除操作时, Master可以得到来自 ZooKeeper 的实时通知。
因此一旦 RegionServer 上线,Master 能马上得到消息。
3. RegionServer 下线
当 RegionServer 下线时,它和Zookeeper 的会话断开,Zookeeper 会自动释放代表这台 Server 的文件上的独占锁,而 Master 不断轮询 rs 目录下文件的锁状态。
如果Master 发现某个 RegionServer 丢失了它自己的独占锁,Master 就会尝试去获取代表这个RegionServer 的读写锁,一旦获取成功,就可以确定:
- RegionServer 和 ZooKeeper 之间的网络断开了;
- RegionServer 失效了。
只要这两种情况中的一种情况发生了,无论哪种情况,RegionServer 都无法继续为它的 Region 提供服务,此时 Master 会删除 Server 目录下代表这台 RegionServer的文件,并将这台RegionServer的Region 分配给其他还“活者” 的机器。
如果网络短暂出现问题导致 RegionServer 丢失了它的锁,那么 RegionServer 重新连接到Zookeeper 之后,只要代表它的文件还在,它就会不断尝试获取这个文件上的锁,一旦获取到了,就可以继续提供服务。
4. Master 上线
Master 启动上线包括以下步骤。
- 从Zookeeper 上获取唯一代表 Master 的锁,用来阻止其他节点成为 Master
- 扫描 Zookeeper 上的 Server 目录,获得当前可用的 RegionServer 列表。
- 与每个 RegionServer 通信,获得当前已分配的 Region 和 RegionServer 的对应关系。
- 扫描.META.region 的集合,计算得到当前还未分配的 Region,将它们放人待分配 Region 列表。
5. Master 下线
由于 Master 只维护表和 Region 的元数据,而不参与表数据 IO 的过程,所以 Master 下线仅导致所有元数据的修改被冻结。
此时无法创建、删除表,无法修改表的 schema, 无法进行 Region 的负载均衡,无法处理 Region 上下线,无法进行 Region 的合并,唯一例外的是 Region 的split 可以正常进行,因为只有 RegionServer 参与,表的数据读写还可以正常进行。
因此Master 下线短时间内对整个 HBase 集群没有影响。
从上线过程可以看到,Master 保存的信息全是冗余信息,都可以从系统其他地方收集或者计算出来。
因此,一般 HBase 集群中总是有一个 Master 在提供服务,还有一个以上的“Master〞在等待时机抢占它的位置。
当客户端要修改 HBase 的数据时,首先创建一个action(比如 put、delete、incr 等操作),这些action 都会被包装成 Key-Value 对象,然后通过 RPC 将其传输到 HRegionServer 上。
HRegionServer 将其分配给相应的 HRegion, HRegion 先将数据写人 Hlog 中,然后将其写人 MemStore。
MemStore 中的数据是排序的,当 MemStore 累计到一定网值时,就会创建一个新的 MemStore,并且将老的 MemStore 添加到fush 队列,由单独的线程 flush 到磁盘上,成为一个 StoreFile。
与此同时,系统会在Zookeeper 中记录一个redo point,表示这个时刻之前的变更已经持久化了。
当系统出现意外时,可能导致内存 (MemStore) 中的数据丢失,此时使用 Log ( WAL log)来恢复 redo point 之后的数据。
StoreFile 是只读的,一旦创建后就不可以再修改,因此 HBase 的更新其实是不断追加的操作。
当一个 Store 中的 StoreFile 达到一定的阈值后,就会进行一次合并,将对同一个key 的修改合并到一起,形成一个大的 StoreFile。
由于对表的更新是不断追加的,处理读请求时,需要访问 Store 中全部的 StoreFile 和MemStore,将它们的数据按照row key 进行合并,由于 StoreFile 和 MemStore 都是经过排序的,并且 StoreFile 带有内存中索引,所以合并的过程还是比较快的。
总结
本文主要介绍了 HBase 中 Region 的分配、RegionServer 的上下线、Master 的上下线等相关内容。
其中,Region 只能分配给一个 RegionServer,Master 通过 Zookeeper 来跟踪 RegionServer 状态,当 RegionServer 上线或下线时,Master 会相应地进行处理。
Master 下线仅导致所有元数据的修改被冻结,对整个 HBase 集群没有影响。
在 HBase 中,更新是不断追加的操作,处理读请求时需要访问 Store 中全部的 StoreFile 和 MemStore,将它们的数据按照 row key 进行合并。
思维导图