R语言安装及基础知识
一、简介
R语言是一门计算机的编程语言,就跟传统的C语言,Java语言类似,但是,它又不仅仅是一门计算机语言。R语言天生为统计而生,所以,它做不到像C语言那般的普适。数据分析、统计建模、数据可视化才是它的舞台。R语言的核心是解释计算机语言,其允许分支和循环以及使用函数的模块化编程。 允许与以C,C ++,.Net,Python或FORTRAN语言编写的过程集成以提高效率。是一种用于统计分析和为此目的创建图形的编程语言。不是数据类型,它具有用于计算的数据对象。它用于数据挖掘,回归分析,概率估计等领域,使用其中可用的许多软件包。
对于医学科研工作者来说,对于软件的需求其实真的不是很大,基本的统计分析基本能够满足我们。但是,在生物信息(生信)领域,当我们碰到复杂的数据时,也不要怕,从数据的预处理到数据的分析建模,以及后续的绘图,R都能帮你搞定。
二、特点
R语言是用于统计分析,图形表示和报告的编程语言和软件环境。 以下是R语言的重要特点:
-
R语言是一种开发良好,简单有效的编程语言,包括条件,循环,用户定义的递归函数以及输入和输出设施。
-
R语言具有有效的数据处理和存储设施,
-
R语言提供了一套用于数组,列表,向量和矩阵计算的运算符。
-
R语言为数据分析提供了大型,一致和集成的工具集合。
-
R语言提供直接在计算机上或在纸张上打印的图形设施用于数据分析和显示。
-
R语言是彻底面向对象的统计编程语言。
三、安装
3.1安装R
官网:R: The R Project for Statistical Computing




3.2安装Rstudio
RGUI是R 默认的图形化界面,功能不多且图形界面比较简陋,使用起来不是很友好,所以这时就需要一款集成开发环境——studio软件,使用Rstudio可以更加容易的使用R软件,Rstudio是第三方开发的很好用的集成开发环境,也是一款免费的软件,相比较与R默认的RGUI,Rstudio具有更丰富的功能,使用时更加人性化,例如,软件将R控制台,控制窗口,帮助窗口集成到同一个界面下,并且支持代码高亮,自动补齐,可以补齐对象名,函数名等,非常的方便,避免输入的错误。
官网:RStudio | Open source & professional software for data science teams - RStudio



3.3linux安装R
yum -y install gcc glibc-headers gcc-c++ gcc-gfortran readline-devel libXt-devel bzip2-devel xz-devel perl* pcre* zlib-devel libcurl-devel
wget https://cran.r-project.org/src/base/R-4/R-4.2.1.tar.gz
tar -zxvf R-4.2.1.tar.gz
mkdir /etc/R
./configure --enable-R-shlib --prefix=/etc/R --with-readline=no --with-libpng --with-jpeglib
--enable-R-shlib 【必须写】
–prefix=/etc/R这个参数是用来定义R的安装位置的,一定要保证这个目录存在,如果没有这个目录,请先建立这个目录,不指定这个目录的话会安装到解压目录即/home/007/R-3.1.2中,不建议这样,请指定一个空的目录
–with-x=no表示不使用X-Windows系统,也就是类Unix操作系统的GUI,一般不会使用这个,但默认为yes,如果你没有安装libx的话会报错的,所以我们直接设置为no
–with-readline=no表示不使用系统的readline库,如果系统上没有libreadline,此选项填“no“,默认是yes,但是我的系统下没有安装readline库,而且我也不会在RedHat的命令终端中一行一行的写R程序,我将其设置了为no,其结果是我们无法使用上下左右键来查找使用过的命令了,呵呵,也罢,反正我也不会写在终端中写多少行R命令,如果你要用的话,建议你先查找下你的机器上是否安装了readline,如果没有的话我的安装包中有,将其安装上之后再设置为yes,执行上面的命令即可
【如果报错请按一下方法解决】提示错误:

yum install gcc-gfortran
然后运行继续报错:
yum install gcc-c++
然后运行:
错误描述:–with-readline=yes(默认)和头文件/库不可用
解决办法:安装头文件和库,记得连续选中Y,否则该错误无法避
yum install readline-devel
然后运行:
解决办法:安装头文件和库,记得连续选中Y,否则该错误无法避免
yum install libXt-devel
然后运行:
yum -y install xz-devel.x86_64
运行:
yum install libcurl-devel.x86_64 libcurl.x86_64
运行:





make
make install

vi /etc/profile
添加一行:

大功告成:
查看版本:R --version

3.4在线安装
yum install epel-release
yum install R
3.5卸载
R.home() ## 查看R的安装目录
R.Version()[13] ## 查看R版本
Sys.getenv(“R_HOME”)
.Library ##查看lib位置
.libPaths() ##查看lib位置
yum list installed | grep R
R.x86_64 2.15.2-1.el5 installed
R-core.x86_64 2.15.2-1.el5 installed
R-devel.x86_64 2.15.2-1.el5 installed
yum remove R.x86_64
yum remove R-core.x86_64
3.6修改Rstudio工作目录
默认的为:
![]()
修改:
1.找到R的安装路径

在第一行添加:

重新进入Rstudio:

四、基础知识
4.1数据类型
R语言基本的数据类型有:数值、逻辑型(TRUE,FALSE)、文本(字符串)。
R语言数据结构包括:向量、矩阵和数据框、多维数组、列表、对象等。
最基本的是向量类型。
4.2数值型向量及其运算
4.2.1数值型向量
向量是将若干个基础类型相同的值存储在一起,各个元素可以按序号访问。如果将若干个数值存储在一起可以用序号访问,就叫做一个数值型向量。
c()函数:把多个元素或向量组合成一个向量。
例: x = c(10,6,4,7,8)
length(x)可以求x的长度
numeric()函数可以用来初始化一个指定元素个数而元素都等于0的数值型向量,如numeric(10)会生成元素为10个0的向量。
4.2.2运算
标量与标量运算:R中四则运算用+ - * / ^(加、减、乘、除、乘方)%/%表示整除,%%表示求余。
向量与标量运算 、等长向量运算、不等长向量运算
4.3向量化的相关函数
R中的函数一般都是向量化的。
一元函数:在R中,如果普通的一元函数以向量为自变量,一般会对每个元素计算。这样的函数包括sqrt,log10,log,exp,sin,cos,tan等许多。
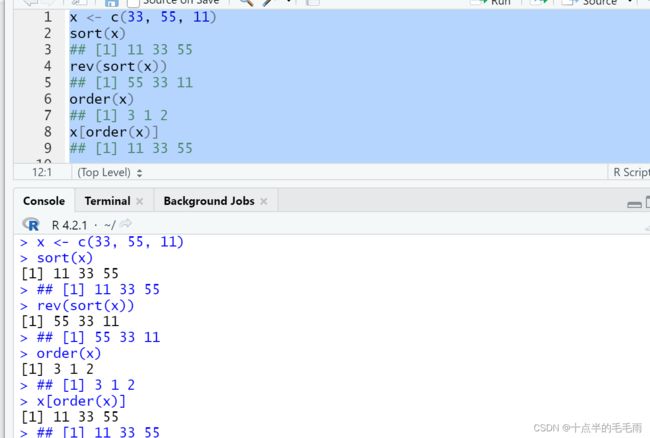
排序函数:sort(x)返回排序结果。rev(x)返回把各元素排列次序反转后的结果。order(x)返回排序用的下标。
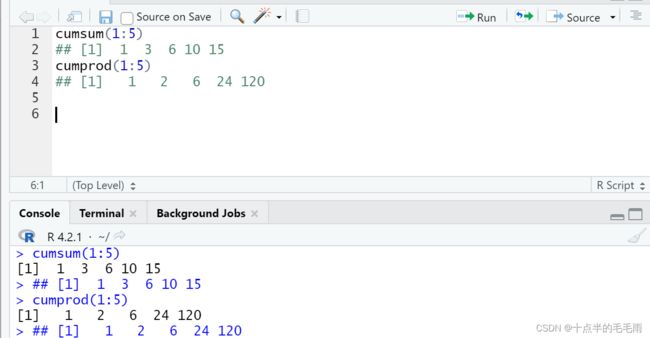
统计函数:sum(求和),mean(求平均值) ,var(求样本方差),sd(求样本标准差),min(求最小值),max(求最大值),range(求最小值和最大值)等函数称为统计函数,把输入向量看作样本,计算样本统计量。prod求所有元素的乘积。comsum和cumprod计算累加和累乘积。
生成规则序列的函数:
seq函数时冒号运算符的推广。比如,seq(5)等同于1:5,seq(11,15,by=2)产生11,13,15
rep函数用来产生重复数值。rep(c(1,3),2)把第一个自变量重复两次,结果相当于c(1,3,1,3)。
rep(c(1,3),c(2,4))相当于c(1,1,3,3,3,3)。
rep(c(1,3),each=2))结果相当于c(1,1,3,3)
4.3逻辑型向量及其运算
4.3.1比较运算
is.na()函数:判断向量每个元素是否NA。is.na(c(1,NA,3)>2)
is.finite()函数:判断向量每个元素是否Inf值,比较运算符包括 < <= > >= == != %in%
注:%in%是比较特殊的比较, x %in% y的运算把向量y看成集合,运算结果是一个逻辑型向量。
c(1,3) %in% c(NA,3,4)
## [1] FALSE TRUE
函数match(x,y)起到和x %in% y 运算类似的作用,但是其返回结果不是找到与否,而是对x的每个元素,找到其在y中首次出现的下标,找不到时取缺失值,如:
match(c(1,3),c(2,3,4,3))
## [1] NA 2
4.3.2逻辑运算
逻辑运算符为&,|和!,分别表示“同时成立”、“两者至少其一成立”、“条件的反面”
4.3.3逻辑运算函数
若c是逻辑向量,用all(c)测试c的所有元素为真;用any(c)测试c至少一个元素为真
all(c(1, NA, 3) > 2)
## [1] FALSE
any(c(1, NA, 3) > 2)
## [1] TRUE
函数which()返回真值对应的所有下标。如:
which(c(FALSE, TRUE, TRUE, FALSE, NA))
## [1] 2 3
which((11:15) > 12)
## [1] 3 4 5
函数identical(x,y)比较两个R对象x和y的内容是否完全相同,结果只会取标量TRUE与FALSE两种。如:
identical(c(1,2,3), c(1,2,NA))
## [1] FALSE
函数duplicated()返回每个元素是否为重复值的结果,如:
duplicated(c(1,2,1,3,NA,4,NA))
## [1] FALSE FALSE TRUE FALSE FALSE FALSE TRUE
用函数unique()可以返回去掉重复值的结果。
4.4字符型数据及其处理
4.4.1字符型向量
字符型向量是元素为字符串的向量
4.4.2常用函数
paste():连接两个字符型向量,元素一一对应连接,默认用空格连接。如paste(c(“ab”,“cd”),c(“ef”,“gh”))结果相当于c(“ab ef”,“cd gh”),其中:sep= 指定分隔符,用collapse= 参数可以把字符型向量的各个元素连接成一个单一的字符串。如paste(c(“a”,“b”,“c”),collapse="")结果相当于“abc”
toupper():把字符型向量内容转为大写
tolower():把字符型向量转为小写
nchar(x,type=‘bytes’):计算字符型向量x中每个字符串的以字节为单位的长度。
nchar(x,type=‘chars’):计算字符型向量x中每个字符串的以字符个数为单位的长度。
substr(x,start,stop):从字符串x中取出从第start个到第stop个的子串
substring(x,start):从字符串x中取出从第start个到末尾的子串
substring(c('JAN07', 'MAR66'), 4)
## [1] "07" "66"
4.5类型转化
as.numeric():把内容是数字的字符型值转换为数值。
as.numeric():是向量化的,可以转换一个向量的每个元素为数值型。
as.character():把数值型转换为字符型
sprintf():用指定的格式数值型转换为字符型,其用法与C语言的sprintf()函数相似,只不过是向量化的。
sprintf('file%03d.txt', c(1, 99, 100))
## [1] "file001.txt" "file099.txt" "file100.txt"
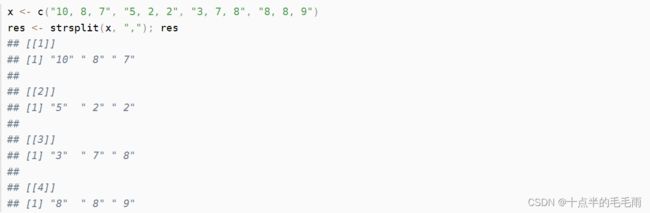
strsplit():把一个字符串按照某种分隔符拆分开
x <- '10,8,7'
strsplit(x, ',', fixed=TRUE)[[1]]
## [1] "10" "8" "7"
gsub():替换字符串中的子串,这样的功能经常用在数据清理中。比如,把数据中的中文标点改为英文标点,去掉空格等等。
x <- '1, 3; 5'
gsub(';', ',', x, fixed=TRUE)
## [1] "1, 3, 5"
4.6向量下标和子集
4.6.1正整数下标
从1开始

x[0]是一种少见的做法,结果返回类型相同、长度为零的向量,如numeric(0)。相当于空集。
4.6.2负整数下标
负下标表示扣除相应的元素后的子集
4.6.3空下标和零下标
取x的全部元素作为子集。
4.7条件函数
which():用来找到满足条件的下标

which.min()、which.max()求最小值的下标和最大值的下标,不唯一时只取第一个
4.8元素名

用unname(x)返回去掉了元素名的x的副本
用names(x) <- NULL 可以去掉x的元素名
4.9集合元素
unique(x):可以获得x的所有不同值
a %in% x :判断a的每个元素是否属于向量x
match(x,table):对向量x的每个元素,从向量table中查找其首次出现位置并返回这些位置。没有匹配到的元素位置返回NA_integer_
intersect(x,y):求交集,结果中不含重复元素
union(x,y):求并集,结果中不含重复元素
setdiff(x,y):求差集,即x的元素中不属于y的元素组成的集合,结果中不含重复元素
setequal(x,y):判断两个集合是否相等
4.10数据类型的性质
4.10.1基本类型
typeof():返回一个变量或表达式的类型
typeof(1:3)
## [1] "integer"
typeof(c(1,2,3))
## [1] "double"
typeof(factor(c('F', 'M', 'M', 'F')))
## [1] "integer"
注意:因子的结果是integer而不是因子
R还有两个函数mode()和storage.mode()起到与typeof()类似的作用
R中数据的最基本的类型包括:logical,integer,double,character,complex,raw
为了判断某个向量x保存的基本类型,可以用is.xxx()类函数
在R语言中数值一般看作double,如果需要明确表明某些数值是整数,可以再数值后面附加字母L
is.integer(c(1, -3))
## [1] FALSE
is.integer(c(1L, -3L))
## [1] TRUE
4.10.2类型转换
四则运算中数值会被统一转换为double类型,逻辑运算中运算元素会被统一转换为logical类型。
在用c()函数合并若干元素时,如果元素基本类型不同,将统一转换成最复杂的一个,复杂程度从简单到复杂依次为:logical < integer < double < character
4.11因子类型
4.11.1因子
用factor()函数把字符型向量转换成因子

4.11.2 table()函数
用table()函数统计因子各水平的出现次数(称为频数或频率)。也可以对一般的向量统计每个不同元素的出现个数。
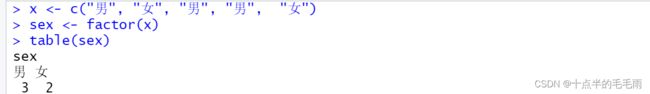
4.12列表类型
4.12.1列表
R中列表(list)类型来保存不同类型的数据。一个主要目的是提供R分析结果输出包装:输出一个变量,这个变量包括回归系数、预测值、残差、检验结果等等一系列不能放到规则形状数据结构中的内容。实际上,数据框也是列表的一种,但是数据框要求各列等长,而列表不要求。列表可以有多个元素,但是与向量不同的是,列表的不同元素的类型可以不同,比如,一个元素是字符串,一个元素是标量,一个元素是另一个列表。
用typeof()函数判断一个列表,返回结果是list。可以用is.list()函数判断某个对象是否列表类型
如果是创建的元素为数值类型,可:
4.12.2列表元素访问

4.12.3列表类型转换
用as.list()把一个其它类型的对象转换成列表;用unlist()函数把列表转换成基本向量。
4.13R矩阵和数组
4.13.1R矩阵
矩阵用matrix函数定义,实际存储成一个向量,根据保存的行数和列数对应到矩阵的元素,存储次序为按列存储。
用nrow()和ncol()函数可以访问矩阵的行数和列数。
4.13.2矩阵子集
colnames()函数可以给矩阵每列命名
rownames()函数可以给矩阵每行命名
4.13.3行列向量转换
若x是向量,cbind(x)把x变成列向量,rbind(x)把x变成行向量
4.13.4apply()函数
apply(A,2,FUN)把矩阵A的每一列分别输入到函数FUN中,得到对应于每一列的结果,如:
D <- matrix(c(6,2,3,5,4,1), nrow=3, ncol=2); D
## [,1] [,2]
## [1,] 6 5
## [2,] 2 4
## [3,] 3 1
apply(D, 2, sum)
## [1] 11 10
4.14数据库
函数data.frame()可以生成数据框。
d <- data.frame(
name=c("李明", "张聪", "王建"),
age=c(30, 35, 28),
height=c(180, 162, 175),
stringsAsFactors=FALSE)
print(d)
## name age height
## 1 李明 30 180
## 2 张聪 35 162
## 3 王建 28 175
data.frame()函数会将字符型列转换成因子,加选项stringsAsFactors=FALSE可以避免这样的转换。
nrow(d)求d的行数,ncol(d)或length(d)求d的列数。数据框每列叫做一个变量,每列都有名字,称为列名或变量名,可以用names()函数和colnames()函数访问。
4.15R语言中的索引
“[“, $和@都可以根据索引取值,但是它们使用范围不一样。
4.15.1 "["
"[":是按索引取值,或者名称取值,返回结果不改变数据类型;
"["(x,n)
参数介绍:
x: 具有索引值的对象,如vector,list
n: 是一个整数或者字符串
h=data.frame(abc=c(5,6))
'['(h,'abc')
# abc
# 1 5
# 2 6
'['(h,1)
# abc
# 1 5
# 2 6
4.15.2 $和[[]]的用法
[[]]也是根据索引或者名称取值,和$使用的对象一样,X[[‘a’,exact=FALSE]]和X$a是等价的。
$采用模糊配合的模式从对象中取值
x <- list(abc = 1)
x$a
# [1] 1
h=data.frame(abc=c(5,6))
h$a
# [1] 5 6
h[['a',exact=FALSE]]
# [1] 5
注意从大数据的计算效率来看,[[]]的运算效率更高
4.15.3 @的用法
@是针对S4对象进行取值的。
library(ROCR)
data(ROCR.simple)
pred <- prediction( ROCR.simple$predictions, ROCR.simple$labels)
performance(pred,'auc')@y.values
# [[1]]
# [1] 0.8341875