Spark
Spark
概述
Apache Spark是用于大规模数据处理的统一分析计算引擎
Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量硬件之上,形成集群。
spark与Hadoop的区别
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop,Spark主要用于替代Hadoop中的MapReduce计算模型。存储依然可以使用HDFS,但是中间结果可以存放在内存中;调度可以使用Spark内置的,也可以使用更成熟的调度系统YARN等
实际上,Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。
此外,Hadoop可以使用廉价的、异构的机器来做分布式存储与计算,但是,Spark对硬件的要求稍高一些,对内存与CPU有一定的要求。
特点
-
快
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。
-
易用
Spark支持Java、Python、R和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
-
通用
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
-
兼容性
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。
运行模式
local本地模式(单机)
(开发测试使用)
分为local单线程和local-cluster多线程
standalone独立集群模式
(开发测试使用)
典型的Mater/slave模式
standalone-HA高可用模式
(生产环境使用)
基于standalone模式,使用zk搭建高可用,避免Master是有单点故障的
on yarn集群模式
(生产环境使用)
运行在 yarn 集群之上,由 yarn 负责资源管理,Spark 负责任务调度和计算,
好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
FIFO、Fair、Capacity
on mesos集群模式
(国内使用较少)
运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算
on cloud集群模式
(中小公司未来会更多的使用云服务)
比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3
spark-submit
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
以下是一些常用的Spark-submit命令选项以及它们的含义:
--class:应用程序入口点的类名,例如org.apache.spark.examples.SparkPi。--master:集群的主节点URL,例如spark://23.195.26.187:7077。--deploy-mode:决定驱动程序运行在哪里,可以是客户端或集群模式,默认为客户端模式client。--conf:以key=value的格式指定 Spark 配置属性,如果值包含空格,需要将整个 ”key=value“ 用双引号引起来。多个配置应该作为单独的参数传递。 (e.g.--conf)= --conf = application-jar:包含应用程序和所有依赖项的打包 jar 文件的路径。这个 URL 必须在集群中全局可见,例如一个hdfs://路径或者在所有节点上都存在的file://路径。application-arguments:传递给主类 main 方法的参数列表。例如:arg1 arg2 arg3。
例如:
# Run application locally on 8 cores
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \
100
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a YARN cluster in cluster deploy mode
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
手写word count
使用RDD API
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]) {
// 创建SparkConf和SparkContext对象
val conf: SparkConf = new SparkConf().setAppName("WordCount")
val sc: SparkContext = new SparkContext(conf)
// 读取文件并进行Word Count
//val textFile: RDD[String] = sc.textFile("input.txt")
//val words: RDD[String] = textFile.flatMap((line: String) => line.split(" ")) // 将每行文本切分成单词
//val pairs: RDD[(String, Int)] = words.map((word: String) => (word, 1)) // 转换成键值对
//val counts: RDD[(String, Int)] = pairs.reduceByKey((a: Int, b: Int) => a + b) // 按照键进行聚合
val counts = sc.textFile("input.txt")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
// 输出结果到控制台并保存到文本文件
counts.collect().foreach(println)
counts.saveAsTextFile("output.txt")
// 关闭SparkContext
sc.stop()
}
}
使用DataSet API、DataFrame API:
import org.apache.spark.sql.{Dataset, SparkSession}
object WordCount {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder.appName("Word Count").getOrCreate()
// 使用 DataFrame 进行 Word Count
val df: Dataset[(String, Int)] = spark.read.textFile("input.txt")
.flatMap(_.split(" "))
.groupBy("value")
.count()
.as[(String, Int)]
df.show()
df.write.csv("output_df")
// 使用 DataSet 进行 Word Count
val ds: Dataset[(String, Int)] = spark.read.textFile("input.txt")
.flatMap(_.split(" "))
.groupByKey(_._1)
.reduceGroups((a, b) => (a._1, a._2 + b._2))
.map(_._2)
ds.show()
ds.write.csv("output_ds")
spark.stop()
}
}
rdd是什么
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
-
Dataset: 它是一个集合,可以存放很多元素
-
Distributed :它里面的元素是分布式存储的,可以用于分布式计算
-
Resilient :它是弹性的,RDD里面的中的数据可以保存在内存中或者磁盘里面
五大属性
一个RDD对象,包含如下5个核心属性。
1)一个分区列表,每个分区里是RDD的部分数据(或称数据块)。
2)一个依赖列表,存储依赖的其他RDD。
3)一个名为compute的计算函数,用于计算RDD各分区的值。
4)分区器(可选),用于键/值类型的RDD,比如某个RDD是按散列来分区。
5)计算各分区时优先的位置列表(可选),比如从HDFS上的文件生成RDD时,RDD分区的位置优先选择数据所在的节点,这样可以避免数据移动带来的开销。
创建方式
//由一个已经存在的Scala集合创建
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
//由外部存储系统的数据集创建
val distFile = sc.textFile("data.txt")
//distFile: org.apache.spark.rdd.RDD[String] = data.txt MapPartitionsRDD[10] at textFile at :26
算子
-
Transformation转换操作:返回一个新的RDD
-
Action动作操作:返回值不是RDD(无返回值或返回其他的)
transformation算子
| 转换 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | 根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 当对(K,V)对的数据集进行调用时,使用给定的组合函数和中性“零”值返回一个(K,U)对的数据集,其中每个键的值都被聚合。允许聚合值类型与输入值类型不同,同时避免不必要的分配。与groupByKey一样,通过可选的第二个参数来配置减少任务的数量。 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD |
| cartesian(otherDataset) | 笛卡尔积 |
| pipe(command, [envVars]) | 对rdd进行管道操作 |
| coalesce(numPartitions) | 减少 RDD 的分区数到指定值。在过滤大量数据之后,可以执行此操作 |
| repartition(numPartitions) | 重新给 RDD 分区 |
action算子
| 动作 | 含义 |
|---|---|
| reduce(func) | 通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| takeSample(withReplacement,num, [seed]) | 返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
| takeOrdered(n, [ordering]) | 返回自然顺序或者自定义顺序的前 n 个元素 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) | 将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) | 在数据集的每一个元素上,运行函数func进行更新。 |
| foreachPartition(func) | 在数据集的每一个分区上,运行函数func |
checkpoint
持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在在HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用。
具体用法:
sc.setCheckpointDir("hdfs://node01:8020/ckpdir")
//设置检查点目录,会立即在HDFS上创建一个空目录
val rdd1 = sc.textFile("hdfs://node01:8020/wordcount/input/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
rdd1.checkpoint //对rdd1进行检查点保存
rdd1.collect //Action操作才会真正执行checkpoint
//后续如果要使用到rdd1可以从checkpoint中读取
持久化和Checkpoint的区别
- 位置
Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存–实验中)。
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上。
- 生命周期
Cache和Persist的RDD会在程序结束后会被清除或者手动调用unpersist方法。
Checkpoint的RDD在程序结束后依然存在,不会被删除。
- Lineage(血统、依赖链–其实就是依赖关系)
Persist和Cache,不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来。
Checkpoint会斩断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,一般不需要回溯依赖链。
rdd的依赖关系
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
作用
对于窄依赖:
-
Spark可以并行计算;
-
如果有一个分区数据丢失,只需要从父RDD的对应1个分区重新计算即可,不需要重新计算整个任务,提高容错。
对于宽依赖:
- 是划分Stage的依据

DAG
DAG(Directed Acyclic Graph有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是RDD执行的流程)
原始的RDD通过一系列的转换操作就形成了DAG有向无环图,任务执行时,可以按照DAG的描述,执行真正的计算(数据被操作的一个过程)。一个Spark应用中可以有一到多个DAG,取决于触发了多少次Action。
stage的划分
为什么要划分
并行计算
一个复杂的业务逻辑如果有shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照shuffle进行划分(也就是按照宽依赖就行划分),就可以将一个DAG划分成多个Stage/阶段,在同一个Stage中,会有多个算子操作,可以形成一个pipeline流水线,流水线内的多个平行的分区可以并行执行。
如何划分
Spark会根据shuffle/宽依赖使用回溯算法来对DAG进行Stage划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的stage/阶段中。

spark程序的运行流程

构建Spark Application运行环境
/
SparkContext向资源管理器注册
SparkContext向资源管理器申请运行Executor
资源管理器分配Executor
资源管理器启动Executor
Executor发送心跳至资源管理器
/
SparkContext构建成DAG图
将DAG图分解成Stage(TaskSet)
把Stage(TaskSet)发送给TaskScheduler
/
Executor向SparkContext申请Task
TaskScheduler将Task发放给Executor运行
/
Task在Executor上运行,运行完毕释放所有资源
DataFrame 和 DataSet
dataframe
DataFrame的前身是SchemaRDD,不再直接继承自RDD,而是自己实现了RDD的绝大多数功能。
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格,带有Schema元信息(可以理解为数据库的列名和类型)
dataSet
与DataFrame相比,保存了类型信息,是强类型的,提供了编译时类型检查。
DataSet包含了DataFrame的功能,DataFrame=DataSet[Row],即DataSet的子集。

sparkStreaming
Spark Streaming是一个基于Spark Core之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。
Spark Streaming 提供了一种称为离散流或DStream 的高级抽象,它表示连续的数据流。
在内部,一个 DStream 被表示为一个RDDs序列。

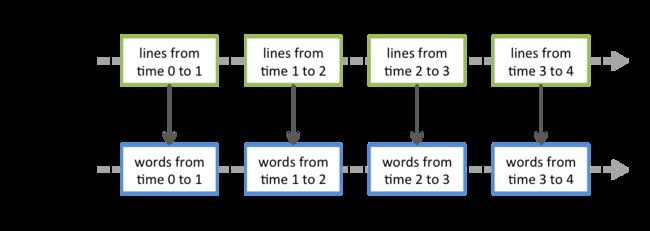
滑动窗口

整合kafka
Receiver接收方式
KafkaUtils.createDstream (不常用)
- Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据(union),再进行处理,很麻烦
- Receiver那台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低
- spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据不一致
Direct直连方式
KafkaUtils.createDirectStream(开发中使用,要求掌握)
- Direct方式是直接连接kafka分区来获取数据,从每个分区直接读取数据大大提高了并行能力
- Direct方式调用Kafka低阶API(底层API),offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与zk不一致的情况
- 当然也可以自己手动维护,把offset存在mysql、redis中
- 所以基于Direct模式可以在开发中使用,且借助Direct模式的特点+手动操作可以保证数据的Exactly once 精准一次
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092,anotherhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topicA", "topicB")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.map(record => (record.key, record.value))
shuffle
HashShuffle
在Map阶段,Mapper任务会根据自己负责的数据块进行计算,并将结果写入磁盘中的本地文件;在Shuffle阶段,Reducer任务会通过网络将Mapper任务产生的partition文件拉取到自己的节点上,然后对相同key的结果进行合并,形成最终结果。
Sort Shuffle
在Map阶段将输出结果按照key排序,然后在Shuffle阶段只传输每个Reducer所需的数据,减少了数据复制和网络通信的开销。
Bypass机制
在Map Task中自行进行分区和排序,跳过Reducer阶段的shuffle处理,从而避免了大量的磁盘I/O和网络I/O操作。
Repartition 和 Coalesce
关系: 两者都是用来改变 RDD 的 partition 数量的,repartition 底层调用的就是 coalesce 方 法。
区别: repartition 一定会发生 shuffle,coalesce 根据传入的参数来判断是否发生 shuffle 。
一般情况下增大 rdd 的 partition 数量使用 repartition,减少 partition 数量时使用 coalesce。
调优
基础调优
-
资源配置
Spark应用程序的性能受到内存、CPU、磁盘I/O等因素的影响。应根据集群硬件配置的情况,合理分配每个执行器(Executor)的内存大小和CPU核数,避免过度分配或低效利用资源。
-
并行度设置
并行度越高,Spark处理数据的速度就越快。可以通过调整RDD的分区数量、设置并发任务数和线程数等方式来增加并行度,同时要避免过度调整造成资源浪费。官方推荐,task数量应该设置为Spark作业总CPU core数量的2~3倍。
-
序列化选择
可以使用Java序列化或Kryo序列化库。Kryo性能更好,但不支持所有的对象,spark默认是Java序列化。
-
缓存和checkpoint:
缓存经常被读取和重用的数据可以有效提高性能,减少计算时间和网络带宽的消耗。在缓存数据时,应注意内存限制和缓存数据更新的策略。使用checkpoint的优点在于提高了Spark作业的可靠性,一旦缓存出现问题,不需要重新计算数据,缺点在于,checkpoint时需要将数据写入HDFS等文件系统,对性能的消耗较大。
-
广播变量
避免某些占空间大的变量随副本在集群中复制。
算子调优
-
优化rdd计算逻辑流程,避免重复计算
-
尽早的filter
-
filter+coalesce减少分区,因为filter后数据变少,资源浪费
-
reducebykey本地预聚合
groupByKey只有reduce端聚合
reduceByKey可以map端预聚合
-
foreachpartition
rrd.foreache(_…)//_表示每一个元素
rrd.forPartitions(_…)//_表示每个分区的数据组成的迭代器
foreachPartition是将RDD的每个分区作为遍历对象,一次处理一个分区的数据,也就是说,如果涉及数据库的相关操作,一个分区的数据只需要创建一次数据库连接。
shuffle调优
-
调整map和reduce端缓冲区大小
-
调整reduce端重试次数和等待时间间隔
数据较大或者网络不佳时,可以调大这两个参数
-
bypass机制开启阈值
数据倾斜
- 提前过滤可能导致数据倾斜的key对应的数据
- 使用随机key
- 提高reduce并行度
- 使用map join,广播小RDD全量数据+map算子