MySql创建分区
Python微信订餐小程序课程视频
https://blog.csdn.net/m0_56069948/article/details/122285951
Python实战量化交易理财系统
https://blog.csdn.net/m0_56069948/article/details/122285941
一、Mysql分区类型
1、RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区。
2、HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL中有效的、产生非负整数值的任何表达式。
3、KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
4、复合分区:基于RANGE/LIST 类型的分区表中每个分区的再次分割。子分区可以是 HASH/KEY 等类型。
二、RANGE分区
缺点:1、只能通过整形类型的主键建进行分区
2、分区数据不平均
1、创建分区
DROP TABLE IF EXISTS `product\_partiton\_range`;
CREATE TABLE `product\_partiton\_range` (
`Id` int(11) NOT NULL AUTO\_INCREMENT,
`ProductName` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4\_general\_ci NOT NULL,
`ProductId` int(11) NOT NULL,
PRIMARY KEY (`Id`) USING BTREE
) ENGINE = InnoDB AUTO\_INCREMENT = 1 CHARACTER SET = utf8mb4
PARTITION BY RANGE (Id) PARTITIONS 3 (
PARTITION part0 VALUES LESS THAN (1000),
PARTITION part1 VALUES LESS THAN (2000),
PARTITION part2 VALUES LESS THAN MAXVALUE);
2、批量添加数据
DROP PROCEDURE IF EXISTS PROC\_USER\_INSERT;
delimiter $$
-- 创建存储过程
CREATE PROCEDURE PROC\_USER\_INSERT(
IN START\_NUM INT,
IN MAX\_NUM INT
)
BEGIN
DECLARE TEMP\_NUM INT DEFAULT 0;
SET TEMP\_NUM=START\_NUM;
WHILE TEMP\_NUM<=MAX\_NUM DO
INSERT INTO product\_partiton\_range(ProductName,ProductId) VALUES('XIAOHEMIAO',TEMP\_NUM);
SET TEMP\_NUM=TEMP\_NUM+1;
END WHILE;
END$$ ;
delimiter;
-- 调用存储过程
CALL PROC\_USER\_INSERT(1,5000);
3、通过EXPLAIN PARTITIONS命令发现SQL优化器只需搜对应的区,不会搜索所有分区
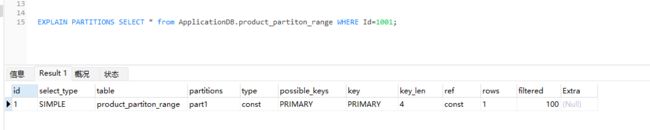
4、如果sql语句有问题,那么会走所有区。会很危险。所以分区表后,select语句必须走分区键。

5、查看当前表的分区情况
SELECT
partition\_name part,
partition\_expression expr,
partition\_description descr,
table\_rows
FROM information\_schema.partitions WHERE
table\_schema = SCHEMA()
AND table\_name='product\_partiton\_range';
二、Hash分区
优点:分区数据比较平均
缺陷:HASH分区只能对数字字段进行分区,无法对字符字段进行分区。如果需要对字段值进行分区,必须包含在主键字段内
1、创建分区
DROP TABLE IF EXISTS `product\_partiton\_hash`;
CREATE TABLE `product\_partiton\_hash` (
`Id` int(11) NOT NULL AUTO\_INCREMENT,
`ProductName` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4\_general\_ci NOT NULL,
`ProductId` int(11) NOT NULL,
PRIMARY KEY (`Id`) USING BTREE
) ENGINE = InnoDB AUTO\_INCREMENT = 1 CHARACTER SET = utf8mb4
PARTITION BY HASH (Id) PARTITIONS 3 ;
三、Key分区
优点:除了text,blob类型字段,其他类型字段都可以进行分区
缺陷:不支持text,blob(二进制)类型的字段进行分区
1、创建分区
DROP TABLE IF EXISTS `product\_partiton\_key`;
CREATE TABLE `product\_partiton\_key` (
`Id` int(11) NOT NULL AUTO\_INCREMENT,
`ProductName` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4\_general\_ci NOT NULL,
`ProductId` int(11) NOT NULL,
PRIMARY KEY (`Id`,`ProductName`) ,
INDEX `ProductId\_index`(`ProductId`)
) ENGINE = InnoDB AUTO\_INCREMENT = 1 CHARACTER SET = utf8mb4
PARTITION BY KEY (ProductName) PARTITIONS 3 ;
四、List分区
优点:支持枚举类型的字段进行分区,比如商品状态,商品类型
1、创建分区
DROP TABLE IF EXISTS `product\_partiton\_list`;
CREATE TABLE `product\_partiton\_list` (
`Id` int(11) NOT NULL AUTO\_INCREMENT,
`ProductName` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4\_general\_ci NOT NULL,
`ProductId` int(11) NOT NULL,
`ProductStatus` int(11) NOT NULL,
PRIMARY KEY (`Id`,`ProductStatus`) ,
INDEX `ProductId\_index` (`ProductId`)
) ENGINE = InnoDB AUTO\_INCREMENT = 1 CHARACTER SET = utf8mb4
PARTITION BY LIST(ProductStatus)(
PARTITION p0 VALUES in(0,1),
PARTITION p1 VALUES in(2,3,4)
);
2、插入数据
INSERT INTO product\_partiton\_list(ProductName,ProductId,ProductStatus) VALUES('XIAOHEMIAO',1,0);
INSERT INTO product\_partiton\_list(ProductName,ProductId,ProductStatus) VALUES('XIAOHEMIAO',1,1);
INSERT INTO product\_partiton\_list(ProductName,ProductId,ProductStatus) VALUES('XIAOHEMIAO',1,2);
INSERT INTO product\_partiton\_list(ProductName,ProductId,ProductStatus) VALUES('XIAOHEMIAO',1,3);
INSERT INTO product\_partiton\_list(ProductName,ProductId,ProductStatus) VALUES('XIAOHEMIAO',1,4);
3、查看当前表的分区情况
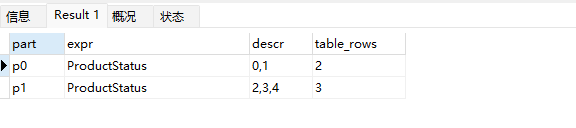
总结
1、分区字段必须是主键
2、分区字段,必须以分区字段进行查询,否则分区失效
友情链接
https://blog.csdn.net/chenmh/p/5643174.html
https://blog.csdn.net/qq_35190486/article/details/108758205
https://blog.csdn.net/qq_34202873/article/details/121111232