python多线程------>这个玩意很哇塞,你不来看看吗
目录
多任务
程序中模拟多任务
多任务的理解
线程完成多任务
查看线程数量
验证⼦线程的执⾏与创建
继承Thread类创建线程
多线程共享全局变量(线程间通信)
多线程参数-args
共享全局变量资源竞争
互斥锁
死锁
避免死锁
Queue线程
_______________________________________________
多任务
class sing():
for i in range(5):
print("我爱python")
print("我爱python---------运行结束")
def dence():
for i in range(5):
print("Pyhon很好玩")
print("python很好玩---------运行结束")
if __name__ == '__main__':
sing()
dence()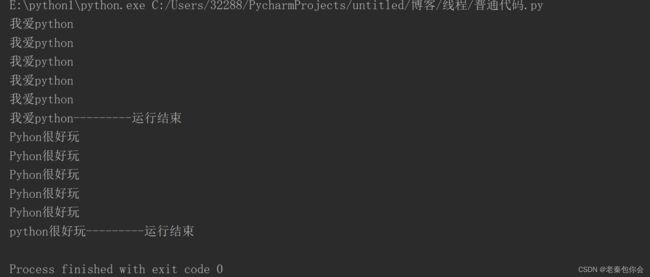
可以看出当我们的代码是从上往下运行的,一个接着一个,但我们有没有想过代码在运行过程难道没有延时吗,如果延时,那可不可以往下运行,把延时的代码往后推,当然有啦,那就是多线程,下面我来介绍
多任务的理解:
一些小可爱们应该听说过并发和并行,这两个词在线程是听得比较多的,小可爱们知道代码的运行是在cpu上运行的,cpu分单核和多核,下面我们画图一下,
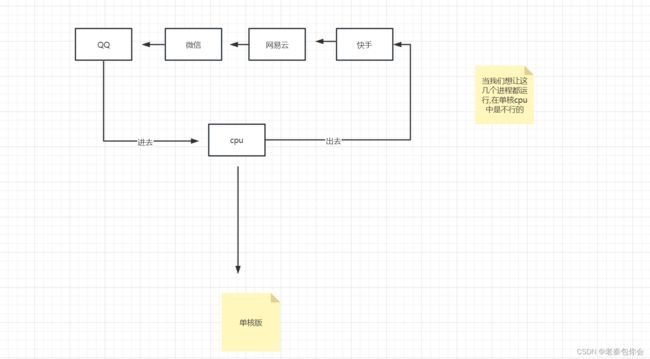
当我们想让这几个进程都运行,在单核cpu中是不行的,但如果这QQ在cpu停留时间很少,紧跟着微信就进去运行,停留一下,出去,然后下一个进来,再出去,就可以误以为这几个进程是同时运行的,但实际是不存在的,这就是并发,并发:假的多任务 cpu⼩于当前执⾏的任务
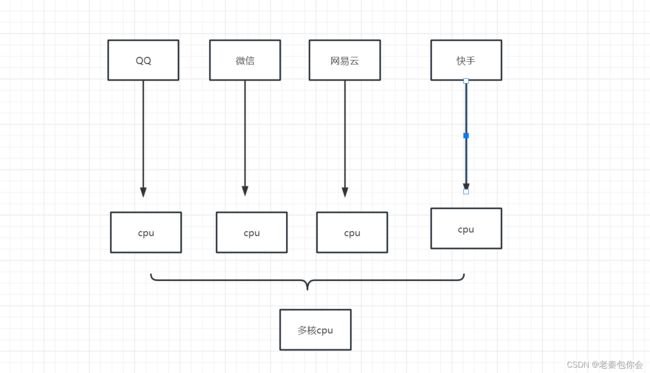
可以看出在多核cpu是可以实现的,这就是并行,并⾏:真的多任务 cpu⼤于当前执⾏的任务
线程完成多任务
下面我们代码演示:
from threading import Thread
def sing():
#子线程
for i in range(5):
print("我爱python")
print("我爱python---------运行结束")
def dence():
#子线程
for i in range(5):
print("Pyhon很好玩")
print("python很好玩---------运行结束")
"""这是一个主线程"""
if __name__ == '__main__':
for i in range(2):
# 创建线程对象(这还不算是创建线程完成)
sin=Thread(target=sing)
# 启动(这里才算完成线程创建)
sin.start()
结果: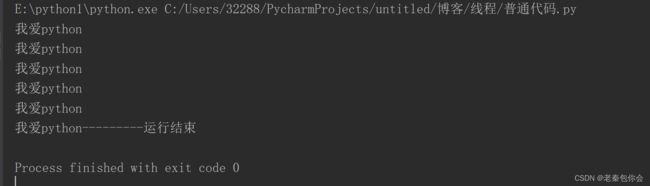
小可爱们看不懂没关系那我来一一解释
首先我们要下载模块threading,前面介绍过了,这里就不过多介绍
导入 threading
创建线程对象(还未完全创建完线程)因为
验证⼦线程的执⾏与创建:
from threading import Thread
import time
def sing():
#子线程
for i in range(5):
print("我爱python")
print("我爱python---------运行结束")
time.sleep(10)
def dence():
#子线程
for i in range(5):
print("Pyhon很好玩")
print("python很好玩---------运行结束")
"""这是一个主线程"""
if __name__ == '__main__':
a=time.time()
for i in range(2):
# 创建线程对象(这还不算是创建线程完成)
sin=Thread(target=sing)
# 启动(这里才算完成线程创建)
sin.start()
b=time.time()
print(b-a)
结果:
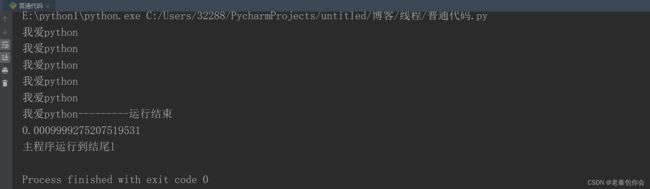
可以看出输出的时间是主程序运行的时间,下面我们看看子线程运行的时间
from threading import Thread
import threading
import time
def sing():
#子线程
for i in range(100):
print("我爱python")
print("我爱python---------运行结束")
time.sleep(2)
def dence():
#子线程
for i in range(100):
print("Pyhon很好玩")
print("python很好玩---------运行结束")
"""这是一个主线程"""
if __name__ == '__main__':
a=time.time()
lis=[]
for i in range(1):
# 创建线程对象(这还不算是创建线程完成)
t=threading.Thread(target=sing)
# 启动(这里才算完成线程创建)
t.start()
lis.append(t)
for i in lis:
i.join()
b = time.time()
print(b-a)
print("主程序运行到结尾")结果:

join()是等待子线程运行结束主程序才开始运行
下面我来一道爬取网页(普通版和多线程版)看看运行时间:
import requests
import threading
from lxml import etree
import time
def prase_url(url,header):
response=requests.get(url, headers=header)
return response
def parse_data(html):
e_html=etree.HTML(html)
new_html=e_html.xpath('//div[@id="htmlContent"]//text()')
# print("".join(new_html).strip())
h1=e_html.xpath('//div[@class="chapter-detail"]/h1/text()')[0]
print(h1)
return h1,"".join(new_html).strip()
def save_data(data):
with open("./小说/{}.txt".format(data[0]),"w",encoding="utf-8")as f:
f.write(data[1])
def main(urls):
"""主要的业务逻辑"""
# url
for url in urls:
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
# 发送请求获取响应
response=prase_url(url,header)
html=response.text
# print(html)
# 数据的提取
data=parse_data(html)
# 保存
save_data(data)
if __name__ == '__main__':
a=time.time()
lis=[]
urls=[]
for i in range(56, 93):
url = "http://www.quannovel.com/read/620/2467{}.html".format(i)
urls.append(url)
# for i in range(2):
# t1=threading.Thread(target=main,args=(urls,))
# t1.start()
# lis.append(t1)
# for t in lis:
# t.join()
# 单线程
main(urls)
b=time.time()
print(b-a)
print("主线程运行结束,等待子线程运行结束")
第一个多线程:
import requests
import threading
from lxml import etree
import time
def prase_url(url,header):
response=requests.get(url, headers=header)
return response
def parse_data(html):
e_html=etree.HTML(html)
new_html=e_html.xpath('//div[@id="htmlContent"]//text()')
# print("".join(new_html).strip())
h1=e_html.xpath('//div[@class="chapter-detail"]/h1/text()')[0]
print(h1)
return h1,"".join(new_html).strip()
def save_data(data):
with open("./小说/{}.txt".format(data[0]),"w",encoding="utf-8")as f:
f.write(data[1])
def main(urls):
"""主要的业务逻辑"""
# url
for url in urls:
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
# 发送请求获取响应
response=prase_url(url,header)
html=response.text
# print(html)
# 数据的提取
data=parse_data(html)
# 保存
save_data(data)
if __name__ == '__main__':
a=time.time()
lis=[]
urls=[]
for i in range(56, 93):
url = "http://www.quannovel.com/read/620/2467{}.html".format(i)
urls.append(url)
for i in range(2):
t1=threading.Thread(target=main,args=(urls,))
t1.start()
lis.append(t1)
for t in lis:
t.join()
# 单线程
# main(urls)
b=time.time()
print(b-a)
print("主线程运行结束,等待子线程运行结束")import requests
import threading
from lxml import etree
import time
def prase_url(url,header):
response=requests.get(url, headers=header)
return response
def parse_data(html):
e_html=etree.HTML(html)
new_html=e_html.xpath('//div[@id="htmlContent"]//text()')
# print("".join(new_html).strip())
h1=e_html.xpath('//div[@class="chapter-detail"]/h1/text()')[0]
print(h1)
return h1,"".join(new_html).strip()
def save_data(data):
with open("./小说/{}.txt".format(data[0]),"w",encoding="utf-8")as f:
f.write(data[1])
def main(i):
"""主要的业务逻辑"""
# url
url="http://www.quannovel.com/read/620/2467{}.html".format(i)
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
# 发送请求获取响应
response=prase_url(url,header)
html=response.text
# print(html)
# 数据的提取
data=parse_data(html)
# 保存
save_data(data)
if __name__ == '__main__':
a=time.time()
lis=[]
for i in range(56,93):
t1=threading.Thread(target=main,args=(i,))
t1.start()
lis.append(t1)
for t in lis:
t.join()
# 单线程
# for i in range(56,93):
# main(i)
b=time.time()
print(b-a)
print("主线程运行结束,等待子线程运行结束")结果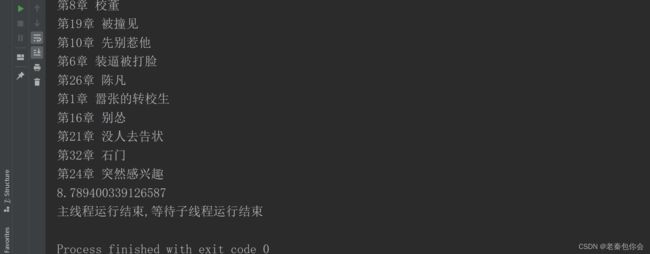
小可爱们看到这里就会发现咋回事,线程用的时间多了,因为线程发生了问题,我们来一一分析,
第一个多线程:发生了资源竞争,因为多个线程共同写入,因为我们的线程运行的时间是由cpu决定的,
当小可爱们运行就会发现,开启了五个线程的运行结果不对,原因是啥,就是我们每一个线程运行都会从头到尾运行一遍,每次创建线程都会重新传参,每个线程互不干预,就好像我们每次买商品,我们一卖完,商家就补上商品, t1=threading.Thread(target=main,args=(urls,))就是这样的原理,要么我们设计一个运行完就去掉一个,要么我们一次性运行完,
如果细心的小可爱们就会发现,数据的保存是错乱的,主要就是发生了资源竞争,下面我来用解释:
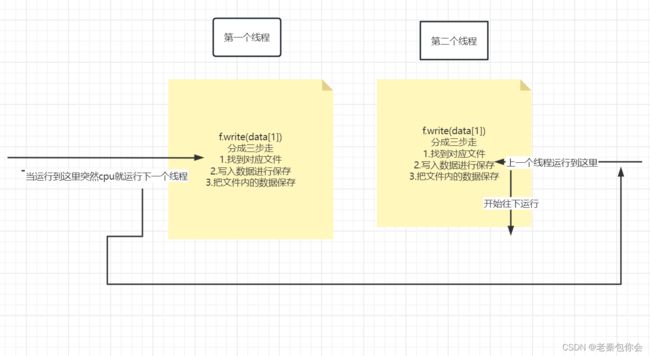
如上图所示第一个多线程就是这样的情况,如果要防止这样就要添加个锁使每一个线程运行到这里,使下一个线程不能写入,后面会讲到锁的使用
第二个多线程:可以看出,我们是创建了许多个线程,但结果是我们创建的每一个线程只爬取一个网站,无形中为代码的运行增加了负担,虽然能爬,但是消耗很大,所有我们创建线程要合适,
继承Thread类创建线程
import requests
import threading
from lxml import etree
import time
import queue
# 这个类用于爬取数据
class My_Thread(threading.Thread):
def __init__(self,urls,header,datas):
super().__init__()
self.urls=urls
self.header=header
self.datas=datas
# print(self.urls.qsize())
def prase_url(self,url):
response=requests.get(url, headers=self.header)
return response
def parse_data(self,html):
e_html=etree.HTML(html)
new_html=e_html.xpath('//div[@id="htmlContent"]//text()')
# print("".join(new_html).strip())
h1=e_html.xpath('//div[@class="chapter-detail"]/h1/text()')[0]
# print(h1)
print("获取中")
return (h1,"".join(new_html).strip())
def run(self):
"""主要的业务逻辑"""
while not self.urls.empty():
# url
a=self.urls.get()
# 发送请求获取响应
response=self.prase_url(a)
html=response.text
# 数据的提取
data=self.parse_data(html)
self.datas.put(data)
# print(self.datas.qsize())
# 这个类用于保存文件
class Save_data(threading.Thread):
def __init__(self,datas):
super().__init__()
self.datas=datas
print(1)
def run(self):
while not self.datas.empty():
a=self.datas.get()
print("保存中")
with open("./小说/{}.txt".format(a[0]), "w", encoding="utf-8")as f:
f.write(a[1])
def main():
# url
urls = queue.Queue()
datas=queue.Queue()
for i in range(56, 93):
url = "http://www.quannovel.com/read/620/2467{}.html".format(i)
urls.put(url)
# print(urls.qsize())
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
# 创建多线程
lis=[]
for i in range(5):
my_thead=My_Thread(urls,header,datas)
my_thead.start()
lis.append(my_thead)
for i in lis:
i.join()
# print(datas.get())
for i in range(5):
sa_da=Save_data(datas)
sa_da.start()
if __name__ == '__main__':
a=time.time()
main()
b=time.time()
print(b-a)
print("主线程运行结束,等待子线程运行结束")结果:
看看多线程运行可以说一下子就爬取了,现在我来分析一下代码:
1.我们创建Threa类的时候要继承父类,父类就是threading.Thread
2.里面有一个方法就是run(self),! ! !这个是能重写,不能更改名字,把你需要运行的代码写入进去相当于我们没学习多线程的时候,的main()
3. 现在里面的mian()函数我主要是用来创建线程
4.
for i in lis:
i.join()
写这个一是等待让爬取的所有数据都爬下来,为后面多线程保存到文件时不至于没有数据保存
5.queue.Queue():创建一个队列
多线程共享全局变量(线程间通信)
简单说就是利用全局变量充当媒介来完成数据的传输
那我们就会遇到一个问题:修改全局变量⼀定需要加global嘛?
import threading
# 修改全局变量是否要加global(根据修改值是否发生地址的改变,地址改变就要加global)
num=0
#写
def task1(nu,n):
global num
num+=nu
print("task1=",num)
print("n=%d"%n)
#读
def task2():
print("task2=",num)
def main():
# 创建子线程
t1=threading.Thread(target=task1,args=(3,4))
t2=threading.Thread(target=task2)
# 启动子线程(这里才是是完全创建子线程)
t1.start()
t2.start()
print("main.....",num)
if __name__ == '__main__':
main()结果:
至于要不要再函数内加global是根据更改值是否造成地址的改变
互斥锁
就是用来解决资源竞争的,所谓资源竞争就是多个线程共同在同一个方向操作,前面我已经有过提示
下面我们再来一个简单代码:
不加锁的情况下:
import threading
import time
"""两个同时写入,不加锁"""
num=0
def task1():
global num
for i in range(100000000):
num+=1
print("task1.......%d"%num)
def task2():
global num
for i in range(100000000):
num+=1
print("task2.......%d"%num)
def main():
# 创建子线程
t1=threading.Thread(target=task1)
t2=threading.Thread(target=task2)
# 启动
t1.start()
t2.start()
print("main....%d"%num)
if __name__ == '__main__':
main()结果:
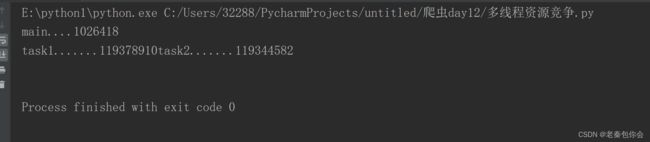
代码:
利用RLock()来创建多把锁
import threading
import time
"""加锁"""
num=0
# 创建一个锁
# mutex=threading.Lock()
mutex=threading.RLock()
def task1():
global num
# 锁定(保证数据能正常存储)
mutex.acquire()
mutex.acquire()
for i in range(100000000):
num+=1
mutex.release()
mutex.release()
# 解锁(使下一个线程能使用)
print("task1.......%d"%num)
def task2():
global num
# 锁定(保证数据能正常存储)
mutex.acquire()
mutex.acquire()
for i in range(100000000):
num+=1
mutex.release()
mutex.release()
# 解锁(使下一个线程能使用)
print("task2.......%d"%num)
def main():
# 创建子线程
t1=threading.Thread(target=task1)
t2=threading.Thread(target=task2)
# 启动
t1.start()
t2.start()
print("main....%d"%num)
if __name__ == '__main__':
main()结果:
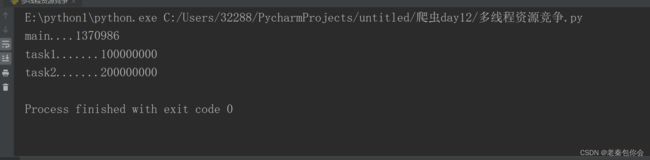
利用Lock创建一把锁
import threading
import time
""加锁"""
num=0
# 创建一个锁
mutex=threading.Lock()
# mutex=threading.RLock()
def task1():
global num
# 锁定(保证数据能正常存储)
# mutex.acquire()
mutex.acquire()
for i in range(100000000):
num+=1
mutex.release()
# mutex.release()
# 解锁(使下一个线程能使用)
print("task1.......%d"%num)
def task2():
global num
# 锁定(保证数据能正常存储)
mutex.acquire()
# mutex.acquire()
for i in range(100000000):
num+=1
mutex.release()
# mutex.release()
# 解锁(使下一个线程能使用)
print("task2.......%d"%num)
def main():
# 创建子线程
t1=threading.Thread(target=task1)
t2=threading.Thread(target=task2)
# 启动
t1.start()
t2.start()
print("main....%d"%num)
if __name__ == '__main__':
main()结果: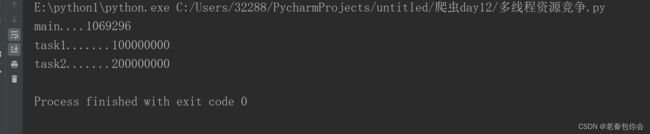
代码:
import threading
import time
mutex=threading.Lock()
def task1():
global num
with mutex:
for i in range(100000000):
num+=1
print("task1.......%d"%num)
def task2():
global num
with mutex:
for i in range(100000000):
num+=1
print("task2.......%d"%num)
def main():
# 创建子线程
t1=threading.Thread(target=task1)
t2=threading.Thread(target=task2)
# 启动
t1.start()
t2.start()
print("main....%d"%num)
if __name__ == '__main__':
main()结果;

threading.Lock(),只能创建一把锁和解一把锁
threading.RLock(),只能创建多把锁和解多把锁
acquire()加锁 release()解锁
with mutex:自动加锁和解锁,和with open一样的效果
Queue线程
import queue
import threading
# 创建队列
# a=queue.Queue(5)
# for i in range(5):
# a.put(i) #存入元素
# print(a.full())
# print(a)
# for i in range(5):
# # print(a.get())
# print(a.get_nowait())
# print(a.empty())
# 创建队列
q=queue.Queue()
num = 0
q.put(num)#把num的值存入
def task1():
for i in range(10000000):
num=q.get() # 创建一个名为num的局部变量
num+=1
q.put(num)
# return q # 反不返回没事
def task2():
for i in range(1000000):
num = q.get() # 创建一个名为num的局部变量
num += 1
q.put(num)
# return q
def main():
# 创建子线程
t1=threading.Thread(target=task1)
t2=threading.Thread(target=task2)
# 启动
t1.start()
t2.start()
t1.join()
t2.join()
print("main....%d"%num)
if __name__ == '__main__':
main()
总结
总的来说,线程就是为了使时间的利用率大大提高,电脑运行的效率提高,爬取太多的东西,没有线程会运行很慢,