AI孙燕姿项目实现
最近在b站刷到很多关于ai孙笑川唱的歌曲,加上最近大火的ai孙燕姿,
这下“冷门歌手”整成热门歌手了
于是写下一篇文章, 如何实现属于的ai歌手。
注意滥用ai,侵犯他人的名誉是要承担法律责任的
下面是一些所需的文件链接:
sovits:github.com/svc-develop-team/so-vits-svc
一鍵包:www.bilibili.com/video/BV1Cc411H74D/
UVR5:www.bilibili.com/video/BV1ga411S7gP/
RX Audio Editor
123盤:www.123pan.com/s/RiyA-LjS03
夸克網盤:pan.quark.cn/s/f9791f6790d3
百度網盤:pan.baidu.com/s/1xUXd9vVHR11sjJ6wCVuwHQ?pwd=hjhj 提取碼: hjhj
Audio Slicer:
Github鏈接:github.com/flutydeer/audio-slicer/blob/main/README.zh-CN.md
整个项目的使用,从深度学习角度来说,可以分为模型推理和模型训练。
- 第一种,我们可以用已有的ai歌手模型直接进行推理,输出
- 第二种,自己训练一个ai歌手模型
对于模型推理,对电脑性能要求不高,但是模型训练,对显卡要求挺高
本项目主要使用的是So-VITS-SVC 4.0这个项目,github地址是:https://github.com/svc-develop-team/so-vits-svc
AI孙燕姿项目实现
- 本地项目实现
-
- 1.软件安装
- 2.准备数据集
- 3.开始训练 (本地训练)
- 4.模型推理
- 云端项目实现
- ⚠️
本地项目实现
1.软件安装
sovits:github.com/svc-develop-team/so-vits-svc
解压后,找到webui.bat(这就是我们ai合成的工具)
2.准备数据集
注意数据集质量比数量更重要,如果要训练一个歌手,最好的方法就是下载他的唱的歌,下载高品质的音乐,除了歌手,还可以考虑采访的,直播的
做过语音处理的应该知道,语音数据需要经过一些处理,这里用UVR5软件提取出音乐的人声
具体实现
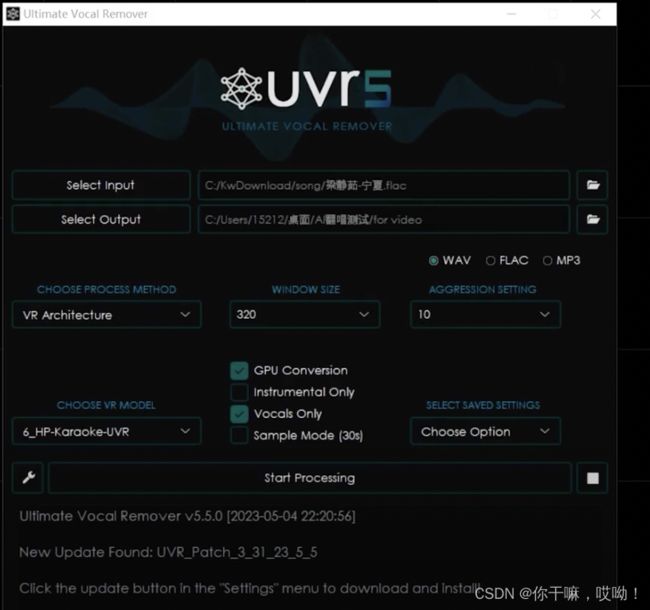
打开软件后,把需要提取的视频,拖到select input,文件最好用wav,设置输出路径select Output(随意),其余的参数,可以看下图
然后点击start processing,运行
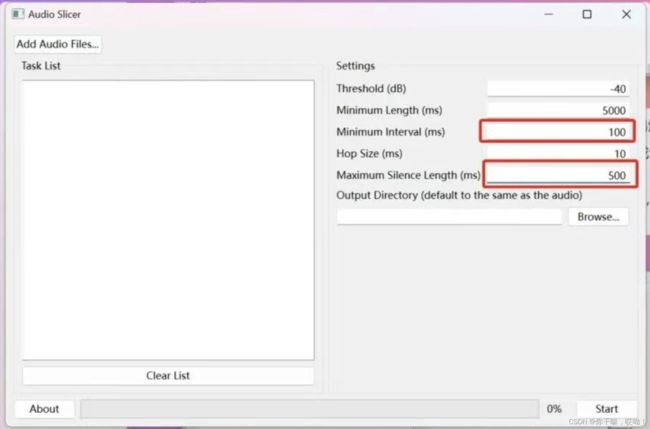
处理完,还可以用RX Audio Editor(音频切片机)进一步处理,类似于做语音处理的,预加重,去燥,也可以用代码去实现
下载RX Audio Editor后解压,找到slicer-gui双击运行,将刚才处理好的,导入到其中,设置输出路径,输出完,把文件放到sovits目录下的dataset_raw
3.开始训练 (本地训练)
打开webui
点击识别数据集
然后点击数据预处理

往下看输出的信息,当看到100%,证明数据已经加载完毕了
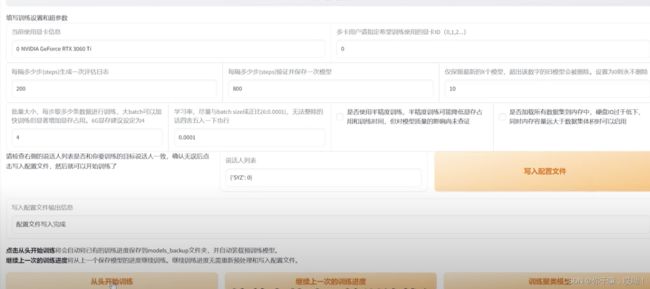
配置自己的训练超参数,信息,然后点击从头开始训练
4.模型推理
回头推理界面,选择G开头的模型。选择配置文件,之后上传要转化的视频

设置音色变调
男转女 设置为5~8,女转男 -5~-8
接着直接点转换

如果音色不太好,可能就是模型训练,迭代次数少了,可以继续上次训练。跟深度学习模型训练原理一样
云端项目实现
跟上面处理数据集一样,把数据集压缩后,上传到云上的sovits项目地址的dataset_raw文件夹下,用命令unzip解压
云端项目实现的流程,在项目文件的reame-v4.ipynb里有详细说明了

按照这个jupyter notebook上面的步骤运行就行了
⚠️
这个github项目最后有一段关于模型使用的说明,以后ai的使用一定也会越来规范,不会滥用
