年轻小伙竟用python爬取B站视频评论!
大家好,我是啃书君。
今天为大家带来的小demo是爬取B站视频的评论。开始还以为很难,等正真上手的时候发现,也就是那么回事。
高考对于每个人来说都是人生的重大转折点,你考上一所什么样的大学,极大可能改变你未来的人生。因此,读书很重要,读书可以改变自己的命运。
衡水中学的张锡锋,想必很多小伙伴们都认识吧,也是他激励了大多数人的学习热情,他的19年演讲视频在B站已经有1574万的播放量了,最近又出了一个新的视频《无产阶级的孩子跨越阶级的希望》,目前还没有多少人看,没有火起来。因此,我就爬取他在19年衡中的演讲视频,抓取评论数据。
网页分析

和之前的不太一样,在以前,B站视频的评论是一页一页进行加载的,但是现在经过测试发现,目前它是通过Js经行渲染的,想通了这一点,那就可以马上去找接口了。

将滚动条不断往下拉的时候,便也加载出来了我们需要的数据包,数据包里面就有我们需要提取的数据。当我继续往下拉的时候,出现类似的数据包越来越多,接下来要做的就是分析这些数据包。
数据包分析
https://api.bilibili.com/x/v2/reply/main?callback=jQuery17203842468693368224_1623154626698&jsonp=jsonp&next=2&type=1&oid=53043610&mode=3&plat=1&_=1623156094225
https://api.bilibili.com/x/v2/reply/main?callback=jQuery17203842468693368224_1623154626699&jsonp=jsonp&next=3&type=1&oid=53043610&mode=3&plat=1&_=1623156100241
https://api.bilibili.com/x/v2/reply/main?callback=jQuery17203842468693368224_1623154626700&jsonp=jsonp&next=4&type=1&oid=53043610&mode=3&plat=1&_=1623156846207
https://api.bilibili.com/x/v2/reply/main?callback=jQuery17203842468693368224_1623154626701&jsonp=jsonp&next=5&type=1&oid=53043610&mode=3&plat=1&_=1623156849736
上面的是四个数据包的请求地址。
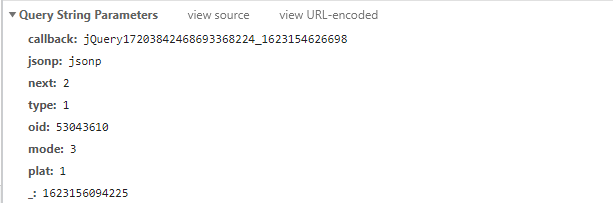
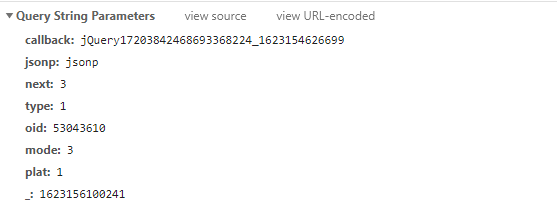
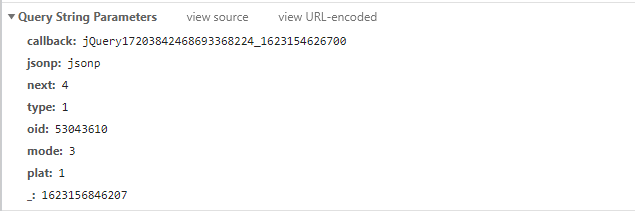
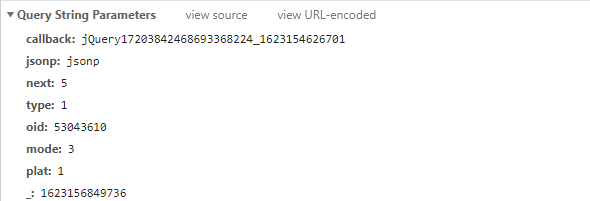
从上面的URL地址以及图片,可以看出一共有8个查询参数。
- callback:每加载出一次便加1操作。
- next:每加载一次便加1操作,next是从0开始加载的。
- _:13位的时间戳。
理清楚了这些,写起代码,那还不是顺风顺水吗?
获取数据
def get_json(url):
response = requests.get(url, headers=headers)
text = response.text[41:-1]
json_data = json.loads(text)
return json_data
运行结果,如下所示:

接下来对上面的代码做简单的解释
text = response.text[41:-1]
这里做了一个切片,因为在这个数据包内获取的数据并不是json格式的,而是字符串。如下图所示:
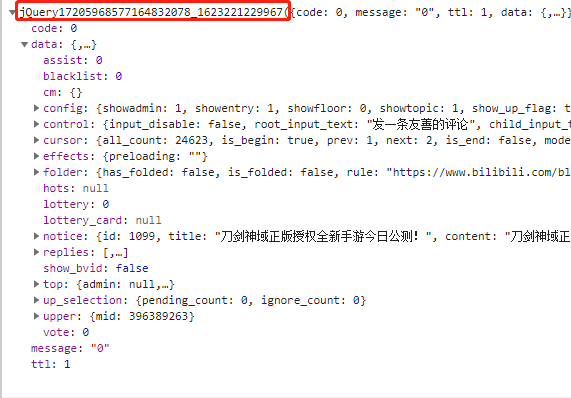
除了上面框起来的内容要去掉以外,还有最后还有圆括号的另一半也要去掉,这样才能保证截取下来的数据是json格式的。
提取数据
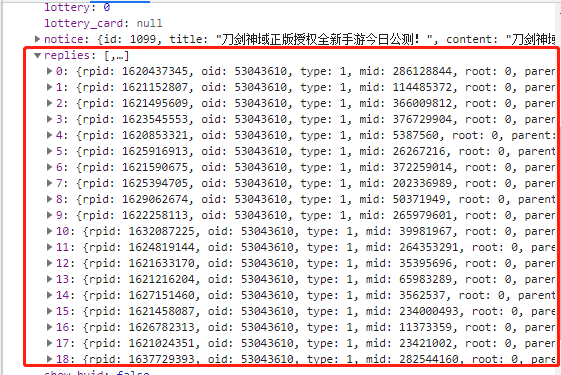
因为,我们要获取的数据都在replies里面,因此我的目标就是先提取到replies里面的数据即可。
代码如下所示:
def get_data(datas):
replies = datas['data']['replies']
return replies
运行结果,如下所示:

从上图可以看到,已经拿下了replies下的所有数据信息。
我需要的数据信息有:
- 用户名
- 性别
- 个性签名
- 评论
- 评论时间
- 点赞数
具体代码如下所示:
def save_data(replies):
for reply in replies:
message = reply.get('content').get('message')
ctime = reply.get('ctime')
content_time = time.strftime('%Y-%m-%d %H:%M', time.localtime(ctime))
like = reply.get('like')
uname = reply.get('member').get('uname')
sex = reply.get('member').get('sex')
sign = reply.get('member').get('sign', '什么都没有写')
print(uname, sex, sign, message, content_time, like)
运行结果,如下所示:

实现翻页爬取
在前面所描述的内容,都只是爬取一页的数据,因此,接下来我要实现类于翻页爬取的效果。
其实只要修改我上面所描述的3个查询参数即可。
具体代码,如下所示:
def main():
for i in range(1000):
try:
print(f'正在获取第{i}页')
time_thick = int(time.time()*1000)
url = f'https://api.bilibili.com/x/v2/reply/main?callback=jQuery17205968577164832078_{1623221229967+i}&jsonp=jsonp&next={i}&type=1&oid=53043610&mode=3&plat=1&_={time_thick}'
datas = get_json(url)
replies = get_data(datas)
save_data(replies)
except:
continue
print('爬取完毕')
保存数据
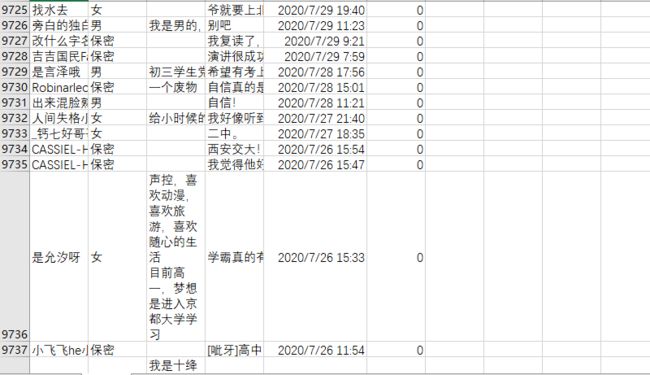
最后将爬取下来的数据,保存至CSV文件中,一共获取到了9千多条数据。