物联网IIoT平台技术框架
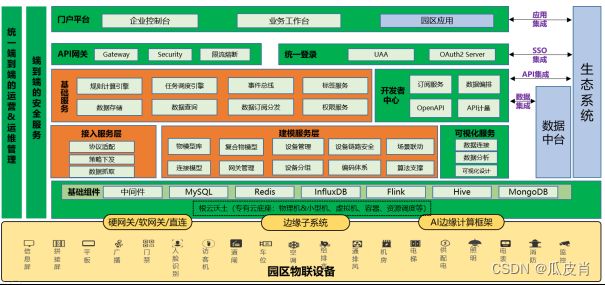
1.1 设备接入服务层
该层服务覆盖南向接入功能,支持多种型号的网关(包括硬件网关和软网关)、直连设备、边缘子系统,边缘计算平台的数据采集,支持多种数据协议解析、转换等一系列服务,并实现多种连接方式的情况下,将数据轻松发送到云端,同时支持在边缘侧执行关键的业务流程,支持MQTT、HTTP行业主流接入协议,并且提供VPN、MQTTS、HTTPS的安全技术来保障数据传输到云端的安全性。
1.2 建模服务层
该层服务覆盖面向物联设备及复合设备的物模型定义能力。物联平台的模型库中包含丰富的标准化模型供客户选择,也支持自定义物模型。模型通过连接模型、物模型、复合物模型来定义。连接模型定义了通信协议、网关采集策略;物模型定义了设备属性、事件、计算规则、设备指令等,复合物模型用来定义多个单设备组合成一个设备的耦合关系。
1.3 通用基础服务层
采用分布式服务框架,构建了通用基础服务,包括规则计算引擎、数据存储、数据查询、数据订阅分发、事件总线、通用标签服务、任务调度引擎等模块。
1.3.1 规则计算引擎
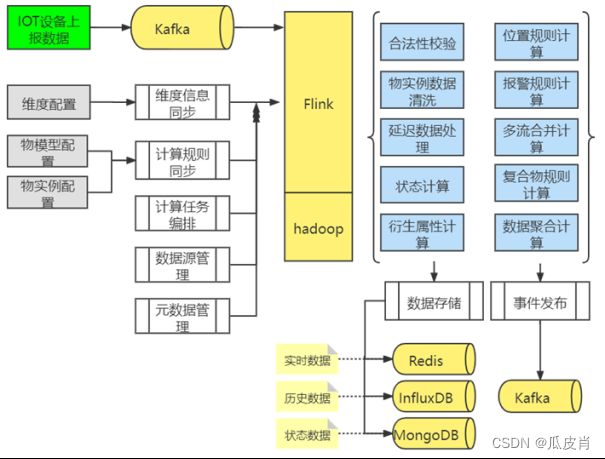
根据物联网平台数据计算的需求,平台采用Hadoop+Flink的流批一体计算框架,实现了规则计算引擎,整体数据流结构如上图所示,OT数据经过设备接入服务层进入系统,使用统一的消息中心Kafka来缓存,然后流入Flink计算引擎。Kafka用来隔离前后端,起缓冲解耦的作用。
Flink的计算输入包括物模型、物实例中配置的规则策略、维度信息、计算任务编排信息、数据源信息、元数据信息等。Flink的计算过程包括数据合法性校验、物实例数据清洗、延迟数据处理、设备状态计算、衍生属性计算、位置规则计算、报警规则计算、多流合并计算、复合物规则计算、数据聚合计算等。
1.3.2 数据储存
根据物联网平台数据特点,平台建设部署多种数据库存储形式,为设备物联数据采集接收提供存储资源,为数据平台层、应用服务层的数据业务应用、可视化数据分析展示应用提供合理的存储建设和数据使用优化建设。
- Mysql
存储本系统主要的业务数据,如设备信息、物模型信息、连接模型信息、云盒信息等等,也记录设备最新的在线状态、云盒的在线状态等。
- Redis
缓存用户权限数据、模型规则计算数据、报警规则数据,存储经过规则计算的实时工况数据以及未经规则计算的原始工况数据等。
- MongoDB
存储设备最新上报的位置数据、设备最后一次上报时间、报警数据、事件数据等。
- Influxdb
存储经过规则计算的历史工况数据,针对本系统的工况数据,通过自研的集群算法,将设备的工况数据存储到指定的influxdb实例中,通过配套的查询服务,即可实现历史工况数据的查询。
- 云对象存储
将各类文件存储到云平台中,本系统支持腾讯云对象存储及aws 文件存储,可由用户根据实际情况开通相应服务后直接使用。
1.3.3 数据查询
业务层应用通过两种途径来使用物联网平台的OT数据,一种是通过API来查询实时数据,历史数据,包括插值查询,聚合查询等等;另一种方式是通过数据订阅通道,将OT数据分发到消费者应用。
数据查询支持单设备单属性、单设备多属性、多设备单属性、多设备多属性等多少查询方式,考虑到历史数据存储可能跨Influxdb的特点,设计了多规则合并的查询逻辑;考虑到物模型发布前后,时序数据中的字段类型会发生改变的问题,平台设计了数据类型转换层,统一处理类型错位的问题。
1.3.4 数据订阅分发
平台可以通过数据订阅通道,将OT数据分发到消费者应用,提高了数据消费的及时性,对跨体系的系统集成提供了支持。平台的数据订阅发布基于Kafka+netty构建,具体的功能逻辑图如下所示。
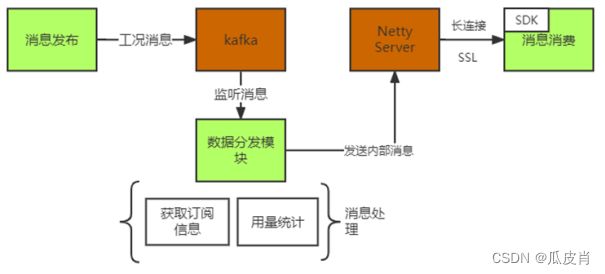
消费端集成了平台提供的SDK,向netty服务端建立长连接,考虑到跨系统之间数据传输,需要开启SSL,信道加密传输。消费端将订阅信息配置到平台,平台维护此订阅路由表。当设备上行工况发送到Kafka中时,数据分发模块根据订阅信息将消息转发到netty通道中,考虑到中间可能发生丢消息的可能,因此数据分发模型需要保证送到netty后,才能给Kafka回消费成功的消息。
1.3.5 事件总线
平台基于Spring Cloud技术栈构建了标准的事件总线,用来流转所有业务层、规则计算、设备上报的事件流转,对Spring Cloud Stream进行轻量级简化封装,借助其对RabbitMQ、Kafka消息中间件的支持,采用消息中间件对事件进行发布和监听。其完整逻辑如图所示:
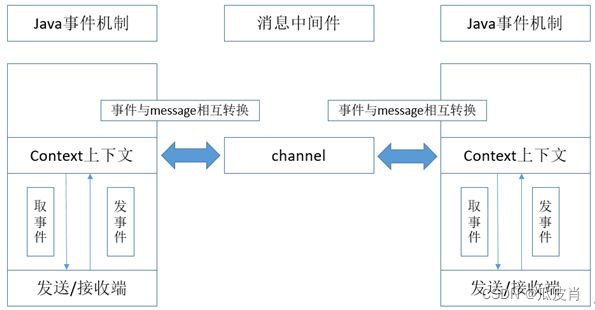
平台构建了统一的事件与message的转换层,支持编解码、压缩传输等特性,channel支持两种RabbitMQ、Kafka两种实现模式,可以根据需要选择部署。服务内、跨服务、跨系统之间的事件通信全部纳入到该事件总线中,统一管理,提高了系统的整体扩展性和高可用性。
1.3.6 任务调度引擎
任务调度引擎的核心功能就是它可以根据我们定义好的调度规则,在线程池中创建线程来执行我们的业务方法。平台基于quartz构建了通用的任务调度服务,供其他服务调用,其功能模块图如下所示:
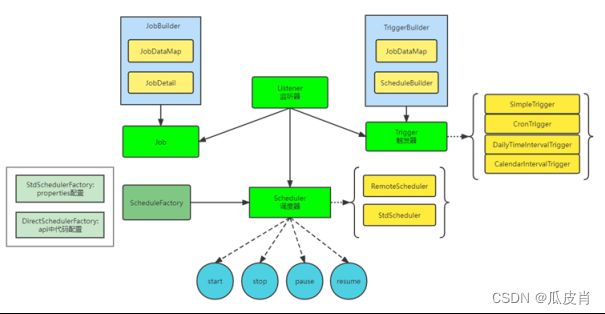
- 灵活的触发规则
触发规则就是我的这个业务方法需要在什么时候开始执行,每隔多少时间执行,一共需要执行多少次。对于触发规则来说我们使用corn表达式,来进行任务触发规则的表达。
- 任务的持久化
任务的持久化就是弥补内存中保存任务的不足。比如说程序异常退出,那么此时我们就无法知道上一次执行的状态,只能够重新开始执行。因此平台使用了JDBC任务(作业)存储方式,将用户任务存储在mysql中。
- 负载均衡
为了解决单点故障的问题,服务需要多实例部署。因此需要将这些任务平均分配到对应的服务器上,这里就需要使用负载均衡策略,比如说随机分配,加权轮询等。
- 任务监控
作为使用者来说,我们当然希望知道此时程序任务的执行状态。而通过日志,数据库表查询状态的方式并不直接,也比较费时费力,也不通用。因此,平台提供监控界面,可以实时查看任务的总体情况,以及某一个任务的执行历史。
1.3.7 通用标签服务
标签服务,是一种统一管理标签的基础服务,提供了对管理资源进行分类的功能,可以实现设备的多维度管理,主要有以下功能:
- 资源标签管理:通过给资源添加标签,可以进行自定义标记,同时系统内置了多个维度的标签供用户选择。
- 资源标签搜索:用户可以在页面中按标签搜索,可以实现标签的key和value的联合搜索,可以实现多标签的组合搜索。
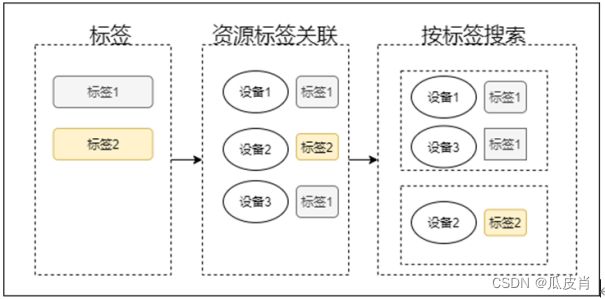
标签服务提供了标准的API供业务系统调用,如基于位置标签,配合智慧园区的空间编码标准,可以实现园区设备的空间管理。
1.3.8 权限服务
平台权限体系包括三部分:应用权限、菜单功能权限、设备数据权限。
- 应用权限
物联网平台中将所有的功能都封装成了应用,例如设备接入与建模、设备管理。这些应用通过标准的上架流程在物联网平台进行上架发布。超级管理员账号可以给租户分配这些已发布的应用。租户可以使用分配给自己的应用。
- 菜单功能权限
针对应用内的菜单功能权限,平台支持两种控制模式:应用自己控制本应用内的菜单功能权限;同时平台提供了一套基于RBAC权限管理模式,如下图:
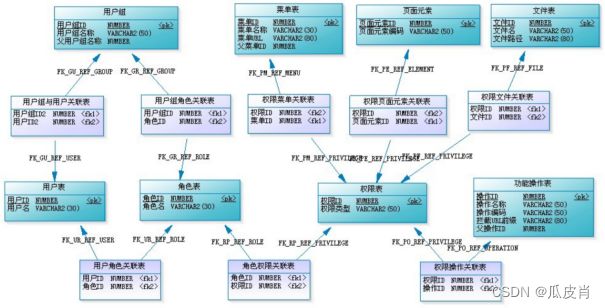
角色是一组功能权限的集合,可实现对角色、功能的控制,以及对设备数据的权限控制。支持给账号角色置顶操作权限,不同的角色的账号登录后只能看到自己操作权限内的工作台。
平台内的原生应用、工作台的菜单功能权限均采用这套标准的权限体系来控制,同时向外提供了API,非原生应用也可以选择使用。
- 设备数据权限
租户管理员可以为企业下游的用户及企业员工分配设备权限。授权之后,用户登录系统就可以看到自己账号绑定的设备,未绑定的设备是看不到的。授权支持指定用户和指定部门,将设备分组授权给指定部门相当于授权给该部门下的所有用户。

1.4 统一运维&运营支撑
统一运维&运营支撑服务,采用通用 PaaS 平台技术栈来构建,主要面向上层云应用、运行时、开发人员等提供开发流程管理、应用运行环境支撑、运维部署等,涉及应用的全生命周期管理;是向外提供服务的基础,可以集中管理调度 IaaS 资源,提供快速开发框架、常用中间件及大数据组件,便于快速构建平台应用,同时提供运维管理工具和 IT 治理服务。
系统具备私有云、公有云两种建设方案(平台可支持公有云和私有云部署,本次建设为私有云建设),系统以轻量级容器机器Docker为主的服务快速部署,使得云平台应用部署和弹性扩容更加容易;
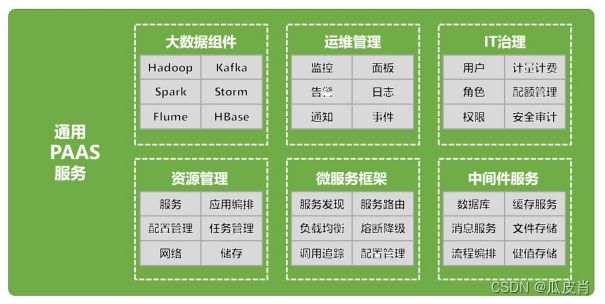
图 通用PAAS服务模块功能图
1.4.1 资源管理
通用PaaS平台管理的资源主要包括计算资源、存储资源、网络资源、服务资源、应用资源、任务资源等。
提供稳定快速的物理环境保障、跨云服务管理,简化多集群的资源隔离和管理,灵活集群托管,全面加速和优化云的管理水平。分区域部署,集中管理的基础设施平台,为确保上层平台的稳定性运行提供强有力的支撑。
1.4.2 微服务框架
平台采用SpringCloud微服务框架及运行环境,支持服务发现、服务路由、负载均衡、熔断降级、调用跟踪、配置管理等。让平台开发者可以将更多关注度放在业务方向,提高业务输出能力。
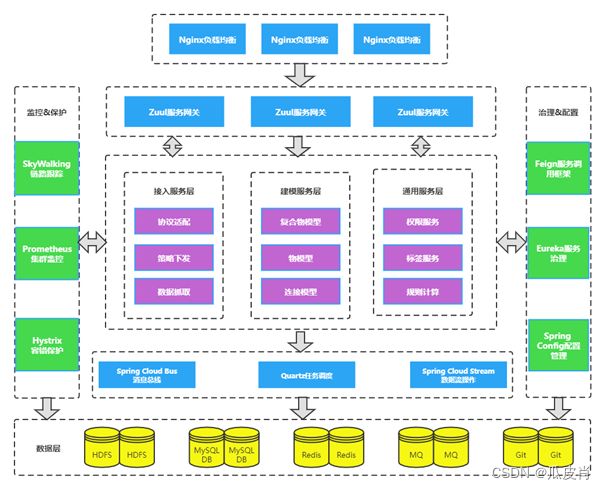
平台集成SpringCloud框架主要核心组件包括:
• Spring Cloud Eureka:服务注册管理中心,负责服务注册与发现;
• Spring Cloud Ribbon:客户端负载均衡器;
• Spring Cloud Hystrix:断路器,容错管理工具;
• Spring Cloud Config:配置管理中心;
• Spring Cloud Zuul:服务网关,具备服务路由、负载均衡、权限控制等功能。
1.4.3 中间件服务
根据物联网平台数据特点,结合先进的微服务框架技术,抽象出平台公共的中间件服务,方便快速高效打造高可用的数据存储和流程服务,提升平台整体服务的高稳定性和高可用性。
中间件服务是 PaaS 平台的核心功能模块,用户发布应用至平台时,只需发布应用本身,应用所依赖的操作系统、软件环境、中间件服务等都平台提供,用户通过自动化方式配置和部署即可。为了方便开发者快速搭建应用运行环境所需的中间件,平台借助 Docker 化封装能力,搭建了中间件服务池,包括常用数据库中间件、消息中间件、日志管理中间件、开发管理中间件等,开发者可以一键部署。
平台建设部署多种数据库存储形式,为设备物联数据采集接收提供存储资源,为数据平台层、应用服务层的数据业务应用、可视化数据分析展示应用提供合理的存储建设和数据使用优化建设。
1.4.4 大数据组件
平台提供常用的开源大数据服务组件,并结合 PaaS平台进行了服务调优,覆盖大数据采集、消息处理、流式计算、离线分析、分布式存储等多种大数据应用场景。
平台构建了大数据环境,包括Hadoop、Kafka、Flink、hdfs、hbase、MySQL、spark等基础组件,以及基于这些基础组件的开发、管理和运维工具。
• Hadoop
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构,用于开发运行分布式应用程序,可充分利用集群的威力进行高速运算和存储,具有可靠、高效、可伸缩的特点。
• Kafka
一种高吞吐量的分布式发布订阅消息系统,最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于 hadoop的批处理系统、低延迟的实时系统、Storm\Flink流式处理引擎,web\nginx日志、访问日志,消息服务等等。
• Flink
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。
1.4.5 运维管理
平台提供了监控、日志、事件、告警、通知等层级的运维管理服务,提供对计算资源、存储资源、网络资源、服务资源、应用资源等的运维服务,以可视化的运维方式,极大降低了运维难度、提高了运维效率。
针对运行在PaaS平台的容器应用,平台通过采集组件可以采集到所有应用的性能数据,如健康状态、CPU使用率、内存使用率、IO、磁盘使用率等等,并统一汇总至时序数据库中,平台通过查询数据库进行报表展示以及根据预先设置的阈值进行报警。
1.4.6 IT治理
PaaS平台具有良好的自服务式 IT治理能力,支撑企业级多租户体系,提供资源隔离机制,保证租户信息安全。
提供基于用户、角色、权限的资源服务管理方式,具有细粒度权限管理控制能力,保证服务调用安全可靠。提供安全审计管理功能,保证资源使用可信、可追溯。
提供多种计费方式供用户选择,既可以按照资源占用周期性(按年、月等)计费,也可以按照资源实际使用情况实时计费。提供统一费用中心,可以方便用户查询资源使用、账户消费情况。