机器学习笔记<一>:PCA降维详解
文章目录
-
- 前言
- 直观理解
- 数学推导
- 代码实现
- PCA的局限性
- 如何选定 k k k值?
- 为什么通过对特征值的选择可以减少噪声?
前言
本篇文章主要从对PCA的降维的直观理解、数学推导等方面对PCA降维进行讨论。
直观理解
主成分分析PCA(Principal Component Analysis)可以用于降维、数据压缩、特征提取以及数据可视化的处理。顾名思义,对数据做PCA之后可以得到数据的主成分信息,而这部分信息可以很好地还原出原数据中的信息,因此某种程度上来说,PCA是对原数据的重构或者是将原数据转换到新的坐标下进行度量(坐标系转换)。
对数据进行重构时保留了原数据中的重要信息同时消除了原数据中的冗余信息(之所以说是冗余信息是因为舍弃的那部分信息可以使用保留下来的信息表示,类似于就算矩阵秩的过程,消除线性相关的项,余下的线性无关),冗余信息的消除在一定程度上简化了计算(特别在高维空间中尤为明显)。例如,有这样一个样本,其中有(浏览量,访客数, 下单数, 成交数, 成交金额),一般情况下“浏览量”和“访客数”、“下单数”和“成交数”存在一定的关系(这里的“关系”是指两者的一种共变关系,即其中一个变大,另外一个也变大),因此可以去除其中的一条记录,总体而言不会损失数据中的太多信息,而这种情况在高维空间中尤为如此。
另外数据中除了冗余信息之外,还可能有噪声,数据中的噪声不仅对后续模型的训练没有帮助,反而会降低模型的鲁棒性,因此必须对数据中的噪声加以处理。
综上所述,PCA的核心思想:使用一些新的特征代替原数据的特征,这些新特征能恰当地总结初始特征空间中包含的信息。换而言之,降维之后的数据要尽可能多地包含原数据中的信息。现在假设已经得到了降维之后的数据,欲度量降维之后的数据是否较多地包含了原数据中的信息,以此来判断新坐标系的“好坏”。如何衡量降维之后数据中包含的信息量?这里采用每个数据点于其均值之间的平均距离来度量,即方差距离(或许可以用熵来度量……)
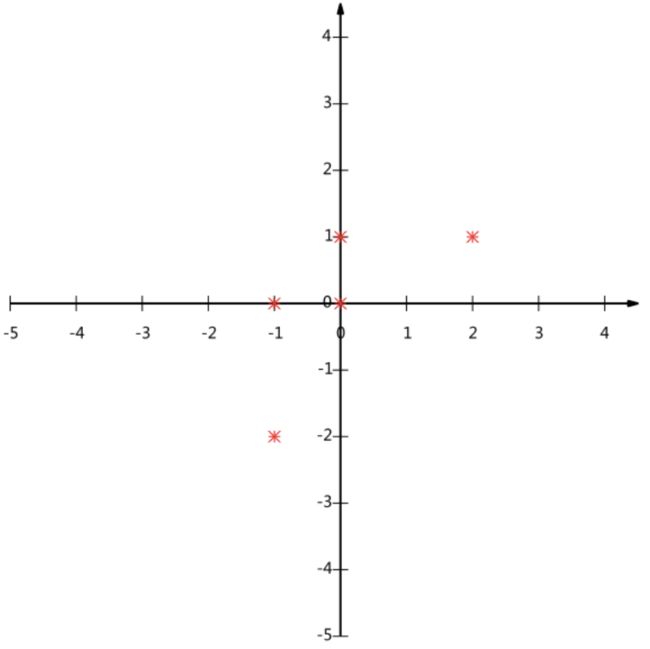
上图中的数据是二维数据,现在需要在坐标系中找得一投影方向使得该数据尽可能清楚地表示。若该投影方向是x方向,则存在两个数据点的重叠;若该投影方向是y方向,则也存在两个数据点的重叠,若投影方向是第一、三象限的角平分线,则原数据可以较好地分布在投影方向上,数据之间不存在重叠部分,如下图所示:

由上图可知,投影之后数据越分散,新的数据就可以较好地反映原数据,也就是说,投影之后的数据方差越大,其包含原数据中的信息就越多。于是PCA的问题就转换成了投影数据方差最大化的问题(解决了方差最大化问题就能找出投影方向(对于高维空间而言就是新的坐标空间),进而计算出降维后的数据)。
数学推导
首先考虑数据之间冗余性的度量方式,这里的冗余性就是前面所说的数据的“共变”特点。先考虑两个变量的情况,一般采用协方差对其线性相关性进行度量,假这两个变量分别为 X X X和 Y Y Y,分别对应的数学期望为 u X u_X uX和 u Y u_Y uY,则协方差的计算可表示为: C o v ( X , Y ) = E [ ( X − u X ) ( Y − u Y ) ] = E [ ( X Y − u Y X − u X Y + u Y u X ) ] = E ( X Y ) − u Y E ( X ) − u X E ( Y ) + u Y u X = E ( X Y ) − u Y u X − u X u Y + u Y u X = E ( X Y ) − u X u Y = E ( X Y ) − E ( X ) E ( Y ) (1) \begin{aligned} Cov(X, Y) & =E{[(X-u_X)(Y-u_Y)]} \\ & =E{[(XY-u_YX-u_XY+u_Yu_X)]} \\ &=E(XY)-u_YE(X)-u_XE(Y)+u_Yu_X \\ &=E(XY)-u_Yu_X-u_Xu_Y+u_Yu_X \\ & =E(XY)-u_Xu_Y \\ &=E(XY)-E(X)E(Y)\tag{1} \end {aligned} Cov(X,Y)=E[(X−uX)(Y−uY)]=E[(XY−uYX−uXY+uYuX)]=E(XY)−uYE(X)−uXE(Y)+uYuX=E(XY)−uYuX−uXuY+uYuX=E(XY)−uXuY=E(XY)−E(X)E(Y)(1)式(1)说明协方差绝对值越大,则说明变量变化越大且偏离其均值很大,若协方差为正且偏大,那么这两个变量都偏向于同一方向的较大值;若协方差为负且偏小,那么这两个变量偏向于不同方向的较大值。
协方差与相关性存在一定的关系,但不完全相同,协方差为零只能说明这两个变量不存在线性相关性,不能说明二者不存在非线性相关性,只要协方差不为零就说明二者存在线性相关性;由式(2)可知,当两个变量相互独立时,协方差为零(若 X X X和 Y Y Y独立,则根据性质, E ( X Y ) = E ( X ) E ( Y ) E(XY)=E(X)E(Y) E(XY)=E(X)E(Y)),因为两变量独立,因此既不存在线性相关性也不存在非线性相关性,独立的条件要比协方差为零强得多。因此可由独立性得出协方差为零,但协方差为零不能得到独立性。
其实大可不必看上面那一段解释,一句话总结就是:若变量的协方差为零,则变量之间不存在线性相关性,因为这里PCA方法是以线性代数为基础,因此只考虑线性相关性(下文均采用“相关性”替代“线性相关性”)。数据中的冗余信息采用协方差矩阵来度量,协方差矩阵描述的是数据中属性之间的相关性,PCA的目标是消除数据中的冗余信息,因此只要让协方差矩阵中不同属性之间的协方差等于零,就可以消除冗余信息(使得不同属性之间不存在相关性)
假设有 N N N个数据样本,每个样本有 n n n个特征/属性,每个样本(n维的列向量)可表示为: x = [ x 1 x 2 x 3 ⋯ x n ] T \bf x =\begin{bmatrix}x_1 & x_2 & x_3 & \cdots & x_n\end{bmatrix}^T x=[x1x2x3⋯xn]T则整个样本数据可以表示为(n行N列的矩阵): X = [ x ( 1 ) x ( 2 ) x ( 3 ) ⋯ x ( N ) ] \bf{X} =\begin{bmatrix} {\bf x^{(1)}} & {\bf x^{(2)}} & {\bf x^{(3)}} & \cdots & {\bf x^{(N)}} \end{bmatrix} X=[x(1)x(2)x(3)⋯x(N)]矩阵的每一行表示每个样本对应的同一种属性,每一列均为一个样本,首先计算每个样本的每种属性对应的均值(即计算 X \bf{X} X中的每一行的均值):
μ j = ∑ i = 1 N x j ( i ) N ; j = 1 , 2 , 3 , 4 , … , n (2) \mu_j = \frac{\sum_{i=1}^{N}{x_j^{(i)}}}{N};j=1,2, 3, 4,\ldots, n \tag{2} μj=N∑i=1Nxj(i);j=1,2,3,4,…,n(2)
X \bf{X} X的方差表示为:
v a r ( x j ) = ∑ i = 1 N ( x j ( i ) − μ j ) 2 N ; j = 1 , 2 , 3 , 4 , … , n (3) var(x_j) = \frac{\sum_{i=1}^{N}{(x_j^{(i)}}- \mu_j)^2}{N};j=1,2, 3, 4,\ldots, n \tag{3} var(xj)=N∑i=1N(xj(i)−μj)2;j=1,2,3,4,…,n(3)
式(3)在计算方差时,当样本很小时,即 N N N很小时,样本方差是有偏估计,因此在样本很小时分母上常用 N − 1 N-1 N−1来校正,这样可以在很大程度上减小偏差,若样本很大,则没必要使用校正,下同。
X \bf{X} X的协方差表示为:
c o v ( x j , x l ) = σ j l = ∑ i = 1 N ( x j ( i ) − μ j ) ( x l ( i ) − μ l ) N ; j , l = 1 , 2 , 3 , 4 , … , n (4) \begin{aligned} cov(x_j, x_l) =\sigma_{jl} = \frac{\sum_{i=1}^{N}{(x_j^{(i)}- \mu_j)(x_l^{(i)}- \mu_l) } }{N}; j, l=1,2, 3, 4,\ldots, n \end{aligned}\tag{4} cov(xj,xl)=σjl=N∑i=1N(xj(i)−μj)(xl(i)−μl);j,l=1,2,3,4,…,n(4)
式(4)进行的运算为:用每个样本的每种属性减去该种属性的均值。再计算这些差值的平方和,再把所有样本的属性差值的平方和相加,最后除以N,协方差用矩阵运算可以表示为( n ∗ n n*n n∗n的矩阵):
Σ = ∑ i = 1 N ( x ( i ) − μ ) ( x ( i ) − μ ) T N = [ σ 1 2 σ 12 ⋯ σ 1 n σ 21 σ 2 2 ⋯ σ 2 n ⋮ ⋮ σ n 1 σ n 2 ⋯ σ n 2 ] (5) \begin{aligned} \Sigma & =\frac{\sum_{i=1}^{N}{(\bf{x}^{(i)}- \bf{ \mu})(\bf{x}^{(i)}- \bf{ \mu})^T}}{N} \\ & =\begin{bmatrix} \sigma_1^2 & \sigma_{12} \cdots \sigma_{1n} \\ \sigma_{21} & \sigma_2^2 \cdots \sigma_{2n} \\ \vdots & \vdots \\ \sigma_{n1} & \sigma_{n2} \cdots \sigma_n^2 \\ \end{bmatrix} \end{aligned}\tag{5} Σ=N∑i=1N(x(i)−μ)(x(i)−μ)T=⎣⎢⎢⎢⎡σ12σ21⋮σn1σ12⋯σ1nσ22⋯σ2n⋮σn2⋯σn2⎦⎥⎥⎥⎤(5)
式(5)中 x ( i ) \bf{x}^{(i)} x(i)为一个样本数据,为n维列向量, μ = [ μ 1 μ 2 μ 3 μ 4 … μ n ] T \bf{\mu}= \begin{bmatrix}\mu_1 & \mu _2 &\mu_3 &\mu _4 &\ldots &\mu _n\end{bmatrix}^T μ=[μ1μ2μ3μ4…μn]T,其对角线元素表示同种属性的方差,非对角线元素表示不同属性的协方差。
由式(4)可知, σ j l = σ l j \sigma_{jl}=\sigma_{lj} σjl=σlj,因此协方差矩阵 Σ \Sigma Σ是对称矩阵,即: Σ = Σ T \Sigma=\Sigma^T Σ=ΣT
式(5)中表明每个样本列向量需要减去总体样本均值,在计算协方差矩阵的时候假设数据 x ( i ) \bf{x}^{(i)} x(i)是已经减去样本均值(已经中心化),则此时样本对应的 μ \mu μ=0,这样更有利于后续的计算。于是式(5)可以简写为:
Σ X = ∑ i = 1 N ( x ( i ) ) ( x ( i ) ) T N = 1 N X X T (6) \begin{aligned} \Sigma_{\bf{{X}}} & =\frac{\sum_{i=1}^{N}{(\bf{x}^{(i)})(\bf{x}^{(i)})^T}}{N} \\ & =\frac{1}{N}\bf{X} \bf{X}^T\tag{6} \end{aligned} ΣX=N∑i=1N(x(i))(x(i))T=N1XXT(6)
只要使PCA降维后的数据属性之间的协方差为0,就可以达到减少原数据冗余信息的目的。假设原数据为 X ^ n ∗ N \bf{\hat{X}_{n *N}} X^n∗N,设 Z ^ n ∗ N = W n ∗ n X ^ n ∗ N \bf{\hat{Z}_{n *N}}=\bf{W}_{n*n}\bf{\hat{X}_{n *N}} Z^n∗N=Wn∗nX^n∗N是重构(坐标转换)后的数据(为什么原数左乘一个 n ∗ n n*n n∗n的矩阵就可以实现数据重构?)计算重构后数据的协方差矩阵:
Σ Z ^ = 1 N Z ^ Z ^ T = 1 N ( W X ^ ) ( W X ^ ) T = 1 N W X ^ X ^ T W T = W Σ X ^ W T (7) \begin{aligned} \Sigma_{\bf{\hat{Z}}} & =\frac{1}{N}\bf{\hat{Z}} \bf{\hat{Z}}^T \\ & =\frac{1}{N}(\bf{W}\bf{\hat{X}})(\bf{W}\bf{\hat{X}})^T \\ & =\frac{1}{N}\bf{W}\bf{\hat{X}}\bf{\hat{X}}^T\bf{W} ^T \\ & =\bf{W}\Sigma_{\bf{\hat{X}}}\bf{W} ^T\tag{7} \\ \end{aligned} ΣZ^=N1Z^Z^T=N1(WX^)(WX^)T=N1WX^X^TWT=WΣX^WT(7)
欲重构后的数据无冗余信息,只要要求其协方差矩阵 Σ Z ^ \Sigma_{\bf{\hat{Z}}} ΣZ^非对角线元素为零即可,由式(7)可知, Σ Z ^ \Sigma_{\bf{\hat{Z}}} ΣZ^对角化问题转化成了寻找一个矩阵 W \bf{W} W对角化 Σ X \Sigma_{\bf{{X}}} ΣX的问题。
由线性代数的知识可知,存在一个可逆矩阵 P P P可以对角化矩阵 A A A,即:
P − 1 A P = Λ = [ λ 1 0 ⋯ 0 0 λ 2 ⋯ 0 ⋮ ⋮ ⋮ 0 0 ⋯ λ n ] (8) \begin{aligned} P^{-1}AP &=\Lambda \\ &=\begin{bmatrix} \lambda_1& 0 & \cdots &0 \\ 0 & \lambda_2 & \cdots& 0 \\ \vdots & \vdots & &\vdots \\ 0 & 0 & \cdots& \lambda_n \\\tag{8} \end{bmatrix} \end{aligned} P−1AP=Λ=⎣⎢⎢⎢⎡λ10⋮00λ2⋮0⋯⋯⋯00⋮λn⎦⎥⎥⎥⎤(8)
上式中矩阵 P P P是由矩阵 A A A的特征向量构成, P = [ p 1 p 2 p 3 ⋯ p n ] P=\begin{bmatrix} \bf{p_1} & \bf{p_2} & \bf{p_3} & \cdots \bf{p_n} \end{bmatrix} P=[p1p2p3⋯pn],矩阵 Λ \Lambda Λ由矩阵 A A A的特征值组成的对角矩阵。由时(4)可知,协方差矩阵是对称矩阵,由线性代数知识可知,矩阵 A A A的特征向量是两两相互正交,因此矩阵 P P P是正交矩阵,因此对于正交矩阵 P P P存在如下关系式:
P T = P − 1 (9) P^T=P^{-1}\tag{9} PT=P−1(9)
将式(9)代入到式(8)中可得: P T A P = Λ (10) P^TAP=\Lambda\tag{10} PTAP=Λ(10)对应到式(7),假设矩阵 A A A是 Σ X ^ \Sigma_{\bf{\hat{X}}} ΣX^,则变换矩阵 W = P T W=P^T W=PT。由此便由原数据的协方差矩阵计算得出变换矩阵 W W W,将变换矩阵 W W W代入进式(7)就可以实现重构数据的协方差矩阵的对角化,至此消除了原数据中的冗余信息,重构后的数据表示为 Z ^ = W X ^ \bf{\hat{Z}}=\bf{W}\bf{\hat{X}} Z^=WX^,数据 Z ^ \bf{\hat{Z}} Z^还是 n n n行 N N N列,与原数据维度一致,只是消除了原数据中的冗余信息。
由式(10)可知,
Σ Z ^ = P T A P = Λ \Sigma_{\bf{\hat{Z}}}=P^TAP=\Lambda ΣZ^=PTAP=Λ因此存在如下关系: [ σ 1 z ^ 2 0 ⋯ 0 0 σ 2 z ^ 2 ⋯ 0 ⋮ ⋮ ⋮ 0 0 ⋯ σ n z ^ 2 ] = [ λ 1 0 ⋯ 0 0 λ 2 ⋯ 0 ⋮ ⋮ ⋮ 0 0 ⋯ λ n ] (11) \begin{bmatrix} \sigma_{1\hat{z}}^2 & 0 &\cdots &0\\ 0 & \sigma_{2\hat{z}}^2& \cdots& 0 \\ \vdots & \vdots &&\vdots \\ 0& 0 &\cdots &\sigma_{n\hat{z}}^2 \\ \end{bmatrix}=\begin{bmatrix} \lambda_1& 0 & \cdots &0 \\ 0 & \lambda_2 & \cdots& 0 \\ \vdots & \vdots & &\vdots \\ 0 & 0 & \cdots& \lambda_n \\\end{bmatrix}\tag{11} ⎣⎢⎢⎢⎡σ1z^20⋮00σ2z^2⋮0⋯⋯⋯00⋮σnz^2⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡λ10⋮00λ2⋮0⋯⋯⋯00⋮λn⎦⎥⎥⎥⎤(11)
由式(11)可知,特征值越大,则数据的方差越大,因此若把特征值降序排列,第一主成分就是最大特征值对应的特征向量,第二主成分就是第二大特征值对应的特征向量,依次类推。因为存在一些特征值对方差的贡献较小,因此可以将其舍弃,则只需要 k k k个特征值对应得特征向量即可。假设降维后的数据维度为 k k k,那数据变换矩阵取的是前 k k k个主成分,于是降维后的数据可以表示为: Z ^ k ∗ N = W k ∗ n X ^ n ∗ N (12) \bf{\hat{Z}_{k *N}}=\bf{W}_{k*n}\bf{\hat{X}_{n *N}}\tag{12} Z^k∗N=Wk∗nX^n∗N(12)式(12)中的 W k ∗ n \bf{W}_{k*n} Wk∗n为变换矩阵,变换矩阵的每一行由特征向量构成。至此实现减少了数据中的噪声的目标(因为在数据可视化中噪声的减少直观表现为数据维度的降低,因此该部分也可以叫做数据降维)
假设样本数据为 X n ∗ N \bf X_{n*N} Xn∗N,样本数为 N N N,每个样本有 n n n个属性,下面以10个样本为例 ( N = 10 ) (N=10) (N=10),每个样本有2个特征 ( n = 2 ) (n =2) (n=2),则PCA降维步骤总结:
1.计算样本中每种属性的均值,对数据作中心化处理
X ^ = [ 0.69 − 1.31 0.39 0.09 1.29 0.49 0.19 − 0.81 − 0.31 − 0.71 0.49 − 1.21 0.99 0.29 1.09 0.79 − 0.31 − 0.81 − 0.31 − 1.01 ] \bf{\hat{X}} =\begin{bmatrix} 0.69 & -1.31&0.39&0.09&1.29&0.49&0.19&-0.81&-0.31&-0.71\\ 0.49 & -1.21&0.99&0.29&1.09&0.79&-0.31&-0.81&-0.31&-1.01 \end{bmatrix} X^=[0.690.49−1.31−1.210.390.990.090.291.291.090.490.790.19−0.31−0.81−0.81−0.31−0.31−0.71−1.01]
上述数据是中心化之后的数据,表示为 2 ∗ 10 2*10 2∗10的矩阵,中心化后数据如下所示:

2.计算协方差矩阵
Σ X ^ = 1 N − 1 X ^ X ^ T = [ 0.617 0.615 0.615 0.717 ] \begin{aligned} \Sigma_{\bf{\hat{X}}} & =\frac{1}{N-1}\bf{\hat X} \bf{\hat X}^T \\ & = \begin{bmatrix}0.617 & 0.615 \\ 0.615 & 0.717\end{bmatrix}\end{aligned} ΣX^=N−11X^X^T=[0.6170.6150.6150.717]
3.计算特征值和特征向量
λ 1 = 0.049 ; λ 2 = 1.284 \lambda_1=0.049;\lambda_2=1.284 λ1=0.049;λ2=1.284 p 1 = [ − 0.735 0.678 ] ; p 2 = [ − 0.678 − 0.735 ] p_1=\begin{bmatrix}-0.735\\0.678\end{bmatrix}; p_2=\begin{bmatrix}-0.678\\-0.735\end{bmatrix} p1=[−0.7350.678];p2=[−0.678−0.735]
特征向量方向如上图红线所示
4.将特征值降序排序,确定主成分个数k,得到变换矩阵
主成分为:
p 2 T = [ − 0.678 − 0.735 ] p_2^T=\begin{bmatrix}-0.678& -0.735\end{bmatrix} p2T=[−0.678−0.735] p 1 T = [ − 0.735 0.678 ] p_1^T=\begin{bmatrix}-0.735&0.678\end{bmatrix} p1T=[−0.7350.678] 若 k = 2 k=2 k=2,则变换矩阵为:
W = [ − 0.678 − 0.735 − 0.735 0.678 ] \bf W = \begin{bmatrix}-0.678& -0.735\\ -0.735&0.678\end{bmatrix} W=[−0.678−0.735−0.7350.678]若 k = 1 k=1 k=1,则变换矩阵为:
W = [ − 0.678 − 0.735 ] \bf W = \begin{bmatrix}-0.678& -0.735\end{bmatrix} W=[−0.678−0.735]
5.计算得到降维数据
若 k = 2 k=2 k=2,则降维后的数据可由式(12)计算得到,即:
Z ^ = [ − 0.828 1.778 − 0.992 − 0.274 − 1.676 − 0.913 0.099 1.145 0.438 1.224 − 0.175 0.143 0.384 0.130 − 0.209 0.175 − 0.350 0.046 0.018 − 0.163 ] \bf{\hat{Z}} =\begin{bmatrix} -0.828 &1.778&-0.992&-0.274&-1.676&-0.913&0.099&1.145&0.438&1.224\\ -0.175& 0.143&0.384&0.130&-0.209&0.175&-0.350&0.046&0.018&-0.163 \end{bmatrix} Z^=[−0.828−0.1751.7780.143−0.9920.384−0.2740.130−1.676−0.209−0.9130.1750.099−0.3501.1450.0460.4380.0181.224−0.163]
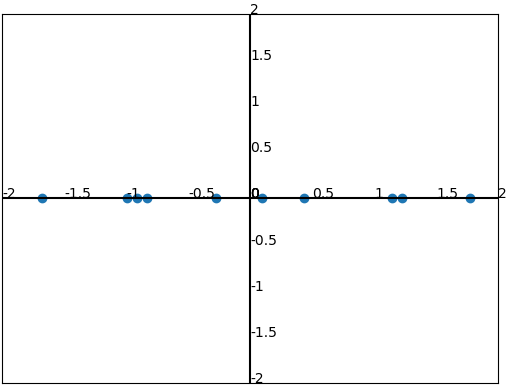
降维后数据分布如下所示:

若 k = 1 k=1 k=1,则降维后的数据可由式(12)计算得到,即:
Z ^ = [ − 0.828 1.778 − 0.992 − 0.274 − 1.676 − 0.913 0.099 1.145 0.438 1.224 ] \bf{\hat{Z}} =\begin{bmatrix} -0.828 &1.778&-0.992&-0.274&-1.676&-0.913&0.099&1.145&0.438&1.224 \end{bmatrix} Z^=[−0.8281.778−0.992−0.274−1.676−0.9130.0991.1450.4381.224]
降维后数据分布如下所示:
代码实现
以鸢尾花数据集为例进行PCA处理,因为该数据集的特征的维度为4维,恰好可以通过PCA减小特征维度到3维,实现数据的可视化,可以较为直观的感受到数据的分类。
- 导入相关函数包
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn import datasets
- 定义PCA类
class PCA():
def __init__(self):
pass
def central_data(self, data):
attributes_mean = np.array([np.mean(data, axis=1)]) #计算总体样本对应的属性均值,attributes_mean.shape=(1, 4)
mean_matrix = np.tile(attributes_mean.T, ( 1, data.shape[1])) #构造和原始数据一样大的均值属性矩阵,mean_matrix.shape=(4, 150)
return data - mean_matrix
def cal_transform_matrix(self, central_data, k):
original_cov = 1/(central_data.shape[1]-1) * central_data.dot(central_data.T)#计算协方差矩阵,original_cov.shape=(4, 4)
eigenvalues, eigenvectors = np.linalg.eig(original_cov) #计算特征值和特征向量
index = np.argsort(-eigenvalues) #将特征值按降序排序并输出对应的索引值
eigenvectors = eigenvectors[:, index] #将特征向量按降序的索引排序
eigenvectors = eigenvectors[:, :k] #取前k个主成分作为转换矩阵
return eigenvectors.T
def reduced_data(self, transform_matrix, central_data):
return transform_matrix.dot(central_data) #计算得到降维后的数据
- 定义plt_show函数
def fig_show(data, label):
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(data[0, :], data[1, :], data[2, :], c=label)
ax.set_xlabel("first_eigenvector")
ax.set_ylabel("second_eigenvector")
ax.set_zlabel("third-eigenvector")
ax.w_xaxis.set_ticklabels(())
ax.w_yaxis.set_ticklabels(())
ax.w_zaxis.set_ticklabels(())
plt.show()
- 定义主函数
def main():
pca = PCA()
iris = datasets.load_iris() #载入鸢尾花数据
data = iris.data.T #样本数据,每一行位样本的一种属性,每一列为一个样本,data.shape = (4, 150)
label = iris.target #标签数据
central_data = pca.central_data(data) #数据中心化
transform_matrix = pca.cal_transform_matrix(central_data, 3) #取前k个主成分作为变换矩阵
reduced_data = pca.reduced_data(transform_matrix, central_data) #计算得到降维后的数据
fig_show(reduced_data, label) #显示降维后的数据
if __name__ == '__main__':
main()
- 实现效果
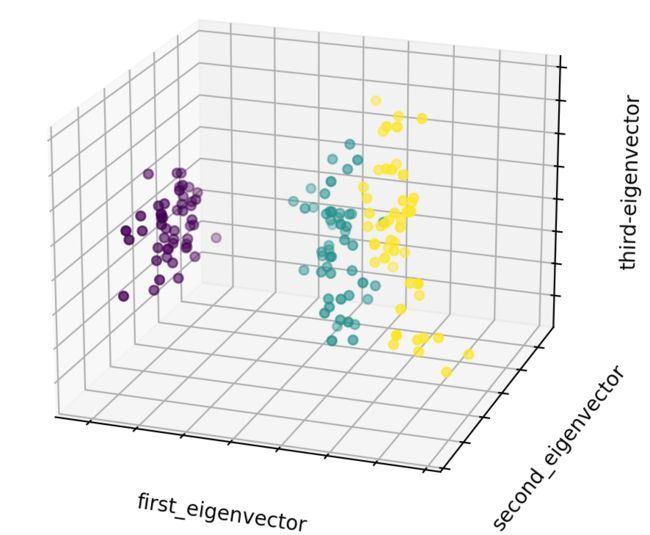
由实现效果可知,数据集经过PCA之后仍然具有较为明显的分类特征,因为在对较大数据集进行处理的时候,可以使用PCA对数据集进行预处理,减少冗余特征,能达到在一定程度上减小计算的复杂度的目的。但在一般情况下,因为丢弃了原始数据中的一些信息,就会导致模型精确度的降低,因此需要考虑精度和计算复杂度的trade-off.
PCA的局限性
- 转换过程复杂,结果难以解释;
- 计算成本昂贵,因为主要依赖于SVD,当数据量和特征点都很大时,SVD对计算能力有较高的要求;
- 对异常值非常敏感。
如何选定 k k k值?
其中一种方法是采用方差所占比例来确定(由式(11)可知,这里的方差可由特征值代替)。假如采用 k k k个主成分来解释方差的90%(这个可以自己设定, 如90%, 95%)的方差,则可以表示为:
λ 1 + λ 2 + λ 3 + ⋯ + λ k λ 1 + λ 2 + λ 3 + ⋯ + λ n > 90 % \frac{\lambda_1+\lambda_2+\lambda_3+\cdots+\lambda_k}{\lambda_1+\lambda_2+\lambda_3+\cdots+\lambda_n}>90\% λ1+λ2+λ3+⋯+λnλ1+λ2+λ3+⋯+λk>90%
通过上式就可以通过已知的特征值来计算 k k k的大小。
另外一种方法就是通过碎石检验(Scree test)来确定 k k k的大小。采用绘图的方式观察与特征值随主成分个数变化的情况从而来确定 k k k。如下图所示:
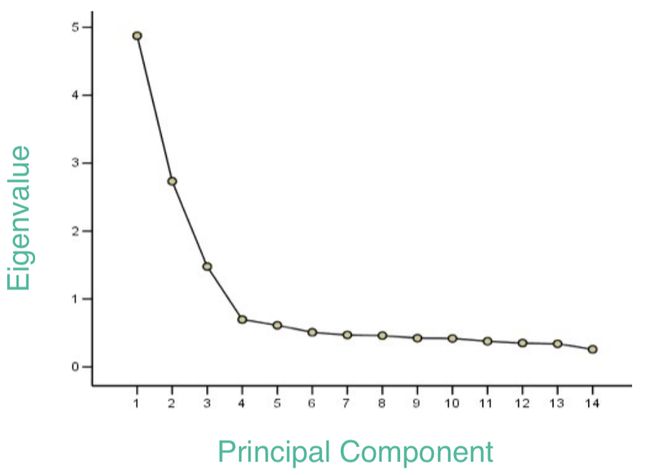
简单来说就是寻找一个因变量随自变量变化特别显著的一个点,如图,前四个主成分构成了一个“悬崖”, 而之后的10个主成分构成了悬崖下的“碎石”,到主成分4为止,特征值已经减小了很多,而且当主成分等于4时,特征值也已经很小了,后面随着主成分的增加特征值变化不大,说明再添加主成分只能增加很少的信息,所以确定主成分数 k k k=4。其缺点就是大多数情况下这样变化显著的点不易确定。
为什么通过对特征值的选择可以减少噪声?
上面减少噪声的过程大概可以描述为:计算出原数据的协方差矩阵 Σ \Sigma Σ,进一步计算出 Σ \Sigma Σ的特征值和特征向量,对特征值进行降序排序,取前 k k k个特征值对应的特征向量构成变换矩阵 W k ∗ N W_{k*N} Wk∗N(特征向量作为变换矩阵的行向量),代入公式即可计算出噪声减少之后的数据 Z k ∗ N Z_{k*N} Zk∗N。
噪声的多少一般可以采用信噪比(signal-to-noise ratio,SNR)来度量,统计学中的信噪比与信号处理中的信噪比稍有不同,下面从统计学的角度解释信噪比,其表示为方差之比,即: S N R = σ s i g n a l 2 σ n o i s e 2 SNR=\frac{\sigma_{signal}^2}{\sigma_{noise}^2} SNR=σnoise2σsignal2若信噪比远大于1,则说明数据中含有的噪声较少,反之说明数据中含有较多噪声。一般情况,高信噪比数据的属性/特征具有较大的方差,代表了真实的数据;低信噪比数据的属性/特征具有较小的方差,而这些小方差的属性就代表了噪声,由上可知,取前k个主成分就是取前k个大的方差,删除了比较小的方差,在一定程度上消除了数据中的噪声。(更为详细的解释请参考引用的论文)
[1]机器学习及其运用
[2]精通特征工程
[3]统计学中的信噪比怎么理解呢?
[4]Phase transition in PCA with missing data:Reduced signal-to-noise ratio, not sample size!