深度学习笔记之循环神经网络(三)循环神经网络思想
深度学习笔记之循环神经网络——循环神经网络思想
- 引言
-
- 回顾:潜变量自回归模型
- 循环神经网络思想
- 困惑度
引言
上一节介绍了基于统计算法的语言模型。本节将介绍基于神经网络的序列模型——循环神经网络。
回顾:潜变量自回归模型
关于潜变量自回归模型,它的概率图结构表示如下:
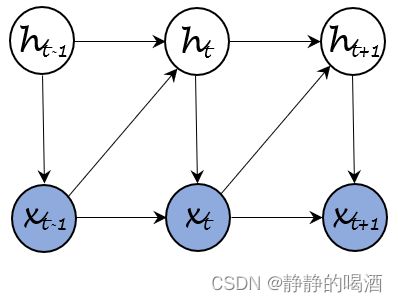
这里仅观察 t t t时刻到 t + 1 t+1 t+1时刻随机变量的变化情况。它的变化过程可划分为两个部分:
- x t − 1 , h t − 1 ⇒ h t x_{t-1},h_{t-1} \Rightarrow h_{t} xt−1,ht−1⇒ht过程。其概率图结构表示为:
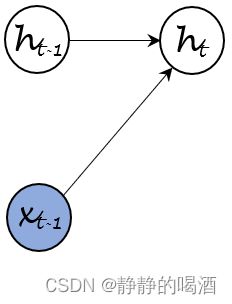
对应的因子分解可表示为: P ( h t ∣ h t − 1 , x t − 1 ) \mathcal P(h_t \mid h_{t-1},x_{t-1}) P(ht∣ht−1,xt−1)。如果使用自回归模型去描述 h t h_t ht的后验概率,它可以表示为:
就是以h t − 1 , x t − 1 h_{t-1},x_{t-1} ht−1,xt−1作为模型输入,其输出结果对h t h_t ht的分布进行描述。λ \lambda λ为模型参数。
P ( h t ∣ h t − 1 , x t − 1 ) = P [ h t ∣ f ( h t − 1 , x t − 1 ; λ ) ] \mathcal P(h_t \mid h_{t-1},x_{t-1}) = \mathcal P [h_t \mid f(h_{t-1},x_{t-1};\lambda)] P(ht∣ht−1,xt−1)=P[ht∣f(ht−1,xt−1;λ)] - x t − 1 , h t ⇒ x t x_{t-1},h_{t} \Rightarrow x_{t} xt−1,ht⇒xt过程。同理,其概率图结构表示为:
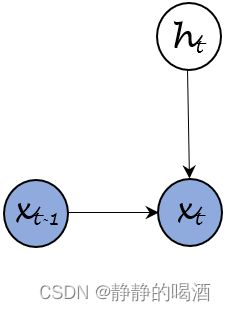
同理,它的因子分解表示为: P ( x t ∣ h t , x t − 1 ) \mathcal P(x_t \mid h_{t},x_{t-1}) P(xt∣ht,xt−1),对该条件概率进行建模,对应后验概率可表示为:
P ( x t ∣ h t , x t − 1 ) = P [ x t ∣ f ( h t , x t − 1 ; η ) ] \mathcal P(x_t \mid h_t,x_{t-1}) = \mathcal P[x_t \mid f(h_t,x_{t-1};\eta)] P(xt∣ht,xt−1)=P[xt∣f(ht,xt−1;η)]
最终通过对上述两步骤的交替执行,从而完成对序列信息的表示。也就是说,在遍历到最后一个随机变量 x T x_{\mathcal T} xT,得到相应的特征结果:
P ( h T + 1 ∣ h T , x T ) = P [ h T + 1 ∣ f ( h T , x T ; θ ) ] \mathcal P(h_{\mathcal T + 1} \mid h_{\mathcal T},x_{\mathcal T}) = \mathcal P[h_{\mathcal T + 1} \mid f(h_{\mathcal T},x_{\mathcal T};\theta)] P(hT+1∣hT,xT)=P[hT+1∣f(hT,xT;θ)]
循环神经网络思想
观察上述步骤,无论是 P ( h t ∣ h t − 1 , x t − 1 ) \mathcal P(h_t \mid h_{t-1},x_{t-1}) P(ht∣ht−1,xt−1)还是 P ( x t ∣ h t , x t − 1 ) \mathcal P(x_t \mid h_t,x_{t-1}) P(xt∣ht,xt−1),它们都属于推断过程。而循环神经网络 ( Recurrent Neural Network ) (\text{Recurrent Neural Network}) (Recurrent Neural Network),就是将上述推断过程通过神经网络的方式描述出来。
循环神经网络隐藏层的计算图展开结构表示如下:
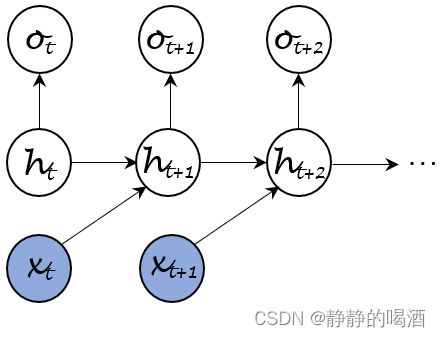
该隐藏层结构的前馈计算过程表示为如下形式:
以 t t t时刻到 t + 1 t+1 t+1时刻的计算过程为例,并且仅包含 1 1 1个隐藏层。
{ h t + 1 = σ ( W h t ⇒ h t + 1 ⋅ h t + W x t ⇒ h t + 1 ⋅ x t + b h t + 1 ) O t + 1 = ϕ ( W h t + 1 ⇒ O t + 1 ⋅ h t + 1 + b O t + 1 ) \begin{cases} h_{t+1} = \sigma(\mathcal W_{h_t \Rightarrow h_{t+1}} \cdot h_{t} + \mathcal W_{x_t \Rightarrow h_{t+1}} \cdot x_t + b_{h_{t+1}}) \\ \mathcal O_{t+1} = \phi(\mathcal W_{h_{t+1} \Rightarrow \mathcal O_{t+1}} \cdot h_{t+1} + b_{\mathcal O_{t+1}}) \\ \end{cases} {ht+1=σ(Wht⇒ht+1⋅ht+Wxt⇒ht+1⋅xt+bht+1)Ot+1=ϕ(Wht+1⇒Ot+1⋅ht+1+bOt+1)
其中, σ ( ⋅ ) \sigma(\cdot) σ(⋅)隐藏层的激活函数; ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)表示输出层的激活函数(如 Softmax \text{Softmax} Softmax)。可以看出:
-
上述第一个公式的输出分布就是后验分布结果 P ( h t + 1 ∣ h t , x t ) \mathcal P(h_{t+1} \mid h_t,x_t) P(ht+1∣ht,xt)的描述——将上一时刻的输入信息 x t x_t xt以及累积的序列信息 h t h_t ht通过 W h t ⇒ h t + 1 , W x t ⇒ h t + 1 \mathcal W_{h_t \Rightarrow h_{t+1}},\mathcal W_{x_t \Rightarrow h_{t+1}} Wht⇒ht+1,Wxt⇒ht+1线性计算的方式累积到隐变量 h t + 1 h_{t+1} ht+1中。
-
那么 P ( x t + 1 ∣ h t + 1 , x t ) \mathcal P(x_{t+1} \mid h_{t+1},x_{t}) P(xt+1∣ht+1,xt)在哪里 ? ? ?它具体实现在了什么位置:我们观察第二个公式:
O t + 1 = W h t + 1 ⇒ O t + 1 ⋅ h t + 1 + b O t + 1 \mathcal O_{t+1} = \mathcal W_{h_{t+1} \Rightarrow \mathcal O_{t+1}} \cdot h_{t+1} + b_{\mathcal O_{t+1}} Ot+1=Wht+1⇒Ot+1⋅ht+1+bOt+1
而这个输出 O t + 1 \mathcal O_{t+1} Ot+1就是关于下一时刻 x t + 1 x_{t+1} xt+1的预测结果 P ( O t + 1 ∣ h t + 1 , x t ) \mathcal P(\mathcal O_{t+1} \mid h_{t+1},x_t) P(Ot+1∣ht+1,xt)。
其中x t x_t xt包含在h t + 1 h_{t+1} ht+1内,这里就这样表示了。观察上图,有意思的是: O t + 1 \mathcal O_{t+1} Ot+1是 t + 1 t+1 t+1时刻产生的输出信息,而同时刻的 x t + 1 x_{t+1} xt+1还没有进入到神经网络内。这意味着:此时的分布 P ( O t + 1 ∣ h t + 1 , x t ) \mathcal P(\mathcal O_{t+1} \mid h_{t+1},x_t) P(Ot+1∣ht+1,xt)仅仅是以 h t + 1 , x t h_{t+1},x_t ht+1,xt作为条件,基于当前时刻的模型信息,对 x t + 1 x_{t+1} xt+1进行预测的幻想粒子。
关于幻想粒子见传送门。那么真正的 P ( x t + 1 ∣ h t + 1 , x t ) \mathcal P(x_{t+1} \mid h_{t+1},x_t) P(xt+1∣ht+1,xt)在哪里呢 ? ? ?——当预测结果 P ( O t + 1 ∣ h t + 1 , x t ) \mathcal P(\mathcal O_{t+1} \mid h_{t+1},x_t) P(Ot+1∣ht+1,xt)作为神经网络的输出直接与真实特征 x t + 1 x_{t+1} xt+1之间进行比较,将比较出的差异性(损失函数) L \mathcal L L以梯度的形式对 W h t + 1 ⇒ O t + 1 \mathcal W_{h_{t+1} \Rightarrow \mathcal O_{t+1}} Wht+1⇒Ot+1进行更新:
这里以'梯度下降法'为例,η \eta η表示学习率。
W h t + 1 ⇒ O t + 1 ⇐ W h t + 1 ⇒ O t + 1 − η ⋅ ∇ L \mathcal W_{h_{t+1} \Rightarrow \mathcal O_{t+1}} \Leftarrow \mathcal W_{h_{t+1} \Rightarrow \mathcal O_{t+1}} - \eta \cdot \nabla\mathcal L Wht+1⇒Ot+1⇐Wht+1⇒Ot+1−η⋅∇L
随着 W h t + 1 ⇒ O t + 1 \mathcal W_{h_{t+1} \Rightarrow \mathcal O_{t+1}} Wht+1⇒Ot+1的优化, P ( O t + 1 ∣ h t + 1 , x t ) \mathcal P(\mathcal O_{t+1} \mid h_{t+1},x_t) P(Ot+1∣ht+1,xt)会逐渐逼近 P ( x t + 1 ∣ h t + 1 , x t ) \mathcal P(x_{t+1} \mid h_{t+1},x_t) P(xt+1∣ht+1,xt)。
当然,也可以将P ( O t + 1 ∣ h t + 1 , x t ) \mathcal P(\mathcal O_{t+1} \mid h_{t+1},x_t) P(Ot+1∣ht+1,xt)看作是P ( x t + 1 ∣ h t + 1 , x t ) \mathcal P(x_{t+1} \mid h_{t+1},x_t) P(xt+1∣ht+1,xt),因为它们之间的关系已经确定,剩余的仅需要去更新W h t + 1 ⇒ O t + 1 \mathcal W_{h_{t+1} \Rightarrow \mathcal O_{t+1}} Wht+1⇒Ot+1让两分布逐渐逼近。如果用一句话描述上述过程:输出 O t \mathcal O_t Ot预测的是对应时刻的输入特征 x t x_t xt,但输出操作发生在输入之前。
困惑度
困惑度 ( Perplexity ) (\text{Perplexity}) (Perplexity)能够衡量一个语言模型的优劣性。其基本思想是:针对测试集的文本序列,语言模型对该序列赋予较高的概率值。也就是说:测试集上的文本序列极大概率是正常的句子/段落,该模型就是优秀模型。公式可表示为如下形式:
这就是‘负对数似然’加上均值和指数。
π = exp { 1 N ∑ t = 1 N − log P ( x t ∣ x t − 1 , ⋯ , x 1 ) } \pi = \exp \left\{\frac{1}{N}\sum_{t=1}^N -\log \mathcal P(x_t \mid x_{t-1},\cdots,x_1)\right\} π=exp{N1t=1∑N−logP(xt∣xt−1,⋯,x1)}
该公式可继续化简至如下形式:
指数的作用是增大相似性结果的映射程度。映射前的值域为 [ 0 , + ∞ ) [0,+\infty) [0,+∞),映射后的值域为 [ 1 , + ∞ ) [1,+\infty) [1,+∞),但由于 log \log log函数的存在,大括号内项的变化量受到约束;而 exp { ⋅ } \exp \{\cdot\} exp{⋅}显然释放掉了这个约束。也就是说,但凡出现一点偏差的风吹草动,都会被 exp { ⋅ } \exp\{\cdot\} exp{⋅}放大。
π = exp { ∑ t = 1 N − log P ( x t ∣ x t − 1 , ⋯ , x 1 ) } N = exp { ∑ t = 1 N log [ 1 P ( x t ∣ x t − 1 , ⋯ , x 1 ) ] } N = ∏ i = 1 N [ exp log 1 P ( x t ∣ x t − 1 , ⋯ , x 1 ) ] N = ∏ t = 1 N 1 P ( x t ∣ x t − 1 , ⋯ , x 1 ) N \begin{aligned} \pi & = \sqrt[N]{\exp \left\{\sum_{t=1}^N -\log \mathcal P(x_t \mid x_{t-1},\cdots,x_1) \right\}} \\ & = \sqrt[N]{\exp \left\{\sum_{t=1}^N \log \left[\frac{1}{\mathcal P(x_t \mid x_{t-1},\cdots,x_1)}\right]\right\}} \\ & = \sqrt[N]{\prod_{i=1}^N \left[\exp \log \frac{1}{\mathcal P(x_t \mid x_{t-1},\cdots,x_1)}\right]} \\ & = \sqrt[N]{\prod_{t=1}^N \frac{1}{\mathcal P(x_t \mid x_{t-1},\cdots,x_1)}} \end{aligned} π=Nexp{t=1∑N−logP(xt∣xt−1,⋯,x1)}=Nexp{t=1∑Nlog[P(xt∣xt−1,⋯,x1)1]}=Ni=1∏N[explogP(xt∣xt−1,⋯,x1)1]=Nt=1∏NP(xt∣xt−1,⋯,x1)1
而根号内的项就是联合概率分布的倒数:
∏ t = 1 N 1 P ( x t ∣ x t − 1 , ⋯ , x 1 ) = 1 ∏ t = 1 N P ( x t ∣ x t − 1 , ⋯ , x 1 ) = 1 P ( x 1 , x 2 , ⋯ , x N ) \prod_{t=1}^N \frac{1}{\mathcal P(x_t \mid x_{t-1},\cdots,x_1)} = \frac{1}{\prod_{t=1}^N \mathcal P(x_t \mid x_{t-1},\cdots,x_1)} = \frac{1}{\mathcal P(x_1,x_2,\cdots,x_N)} t=1∏NP(xt∣xt−1,⋯,x1)1=∏t=1NP(xt∣xt−1,⋯,x1)1=P(x1,x2,⋯,xN)1
最终可表示为:
π = P ( x 1 , x 2 , ⋯ , x N ) − 1 N = 1 P ( x 1 , x 2 , ⋯ , x N ) N \pi = \mathcal P(x_1,x_2,\cdots,x_N)^{-\frac{1}{N}} = \sqrt[N]{\frac{1}{\mathcal P(x_1,x_2,\cdots,x_N)}} π=P(x1,x2,⋯,xN)−N1=NP(x1,x2,⋯,xN)1
- 其中文本序列的概率 P ( x 1 , x 2 , ⋯ , x N ) \mathcal P(x_1,x_2,\cdots,x_{N}) P(x1,x2,⋯,xN)越大,得到的文本序列越优秀;随之,困惑度 π \pi π越小。
- 取平均值 1 N \begin{aligned}\frac{1}{N}\end{aligned} N1的作用在于:每一个 x t ( t = 1 , 2 , ⋯ , N ) x_t(t=1,2,\cdots,N) xt(t=1,2,⋯,N)的后验概率结果必然小于 1 1 1,这导致越长文本序列的概率结果在连乘过程中必然越来越小。而平均操作希望:文本序列中每一个词语的后验概率结果都比较优秀,而不是仅仅个别优秀词语对文本序列的贡献。
但是神经网络中的困惑度常常不是直接使用文本序列的联合概率分布计算的,而是使用交叉熵进行实现。基于上述循环神经网络:
- 首先,在 t t t时刻求解 x t + 1 x_{t+1} xt+1的后验概率 P ( O t + 1 ∣ x t , x t − 1 , ⋯ , x 1 ) \mathcal P(\mathcal O_{t+1} \mid x_t,x_{t-1},\cdots,x_1) P(Ot+1∣xt,xt−1,⋯,x1)本质上是一个分类任务——根据数据集 D \mathcal D D内出现的所有词语结果中,选择概率最高的词作为 x t + 1 x_{t+1} xt+1的结果:
使用softmax \text{softmax} softmax去评估各词语的概率分布信息。
但这个结果只是‘幻想粒子’,关于t + 1 t+1 t+1时刻的输出分布,还需要去与真实分布进行比对。
P ( O t + 1 ∣ x t , ⋯ , x 1 ) = Softmax [ P ( O t + 1 ∣ h t + 1 , x t ) ] \mathcal P(\mathcal O_{t+1} \mid x_t,\cdots,x_1) = \text{Softmax}[\mathcal P(\mathcal O_{t+1} \mid h_{t+1},x_t)] P(Ot+1∣xt,⋯,x1)=Softmax[P(Ot+1∣ht+1,xt)] - 使用交叉熵损失函数对分布 P ( x t + 1 ∣ x t , ⋯ , x 1 ) \mathcal P(x_{t+1} \mid x_t,\cdots,x_1) P(xt+1∣xt,⋯,x1)与 P ( O t + 1 ∣ x t , ⋯ , x 1 ) \mathcal P(\mathcal O_{t+1} \mid x_t,\cdots,x_1) P(Ot+1∣xt,⋯,x1)之间的相似性进行评估:
其中x t + 1 x_{t+1} xt+1表示语料中的某个真实词。
J t + 1 = − ∑ j = 1 ∣ V ∣ P ( x t + 1 ∣ x t , ⋯ , x 1 ) ⋅ log [ P ( O t + 1 ∣ x t , ⋯ , x 1 ) ] \mathcal J_{t+1} = -\sum_{j=1}^{|\mathcal V|} \mathcal P(x_{t+1} \mid x_t,\cdots,x_1) \cdot \log[\mathcal P(\mathcal O_{t+1} \mid x_t,\cdots,x_1)] Jt+1=−j=1∑∣V∣P(xt+1∣xt,⋯,x1)⋅log[P(Ot+1∣xt,⋯,x1)] - 这仅仅是某个词对应分布的相似性结果,在序列大小为 T \mathcal T T的整个语料上使用平均交叉熵的方式对整体进行表示:
这里的均值1 T \begin{aligned}\frac{1}{\mathcal T}\end{aligned} T1和困惑度基本思想中1 N \begin{aligned}\frac{1}{N}\end{aligned} N1的思路完全相同。
J = 1 T ∑ t = 1 T J t = − 1 T ∑ t = 1 T ∑ j = 1 ∣ V ∣ P ( x t + 1 ∣ x t , ⋯ , x 1 ) ⋅ log [ P ( O t + 1 ∣ x t , ⋯ , x 1 ) ] \mathcal J = \frac{1}{\mathcal T} \sum_{t=1}^{\mathcal T} \mathcal J_t = - \frac{1}{\mathcal T} \sum_{t=1}^{\mathcal T} \sum_{j=1}^{|\mathcal V|} \mathcal P(x_{t+1} \mid x_t,\cdots,x_1) \cdot \log[\mathcal P(\mathcal O_{t+1} \mid x_t,\cdots,x_1)] J=T1t=1∑TJt=−T1t=1∑Tj=1∑∣V∣P(xt+1∣xt,⋯,x1)⋅log[P(Ot+1∣xt,⋯,x1)]
最终困惑度是在平均交叉熵的基础上,添加一个指数,进而描述相似性结果:
通常情况下取b = 2 b=2 b=2;这里与视频中取值一样,都取exp \exp exp。
Perplexity = b J = exp { J } ( b = exp ) = exp { − 1 T ∑ t = 1 T ∑ j = 1 ∣ V ∣ P ( x t + 1 ∣ x t , ⋯ , x 1 ) ⋅ log [ P ( O t + 1 ∣ x t , ⋯ , x 1 ) ] } \begin{aligned} \text{Perplexity} & = b^{\mathcal J} \\ & = \exp\{\mathcal J\} \quad (b = \exp) \\ & = \exp \left\{-\frac{1}{\mathcal T}\sum_{t=1}^{\mathcal T}\sum_{j=1}^{|\mathcal V|} \mathcal P(x_{t+1} \mid x_t,\cdots,x_1) \cdot \log[\mathcal P(\mathcal O_{t+1} \mid x_t,\cdots,x_1)]\right\} \end{aligned} Perplexity=bJ=exp{J}(b=exp)=exp⎩ ⎨ ⎧−T1t=1∑Tj=1∑∣V∣P(xt+1∣xt,⋯,x1)⋅log[P(Ot+1∣xt,⋯,x1)]⎭ ⎬ ⎫
相关参考:
54 循环神经网络 RNN【动手学深度学习v2】
困惑度(perplexity)的基本概念及多种模型下的计算(N-gram, 主题模型, 神经网络)