python跨文件夹调用别的文件夹下的py文件或参数方式
目录
摘要:
第一章 运行另一个py文件
(1)在file_A.py中运行file_B.py文件,注意这里是运行,不是引用
(2)file_B.py使用file_A.py传递的参数
(3) 引用另一个py文件中的变量或者方法
第二章 python调用自己写的py文件
(1)同一个目录下的文件
(2)不同目录下的文件
(3)多个文件在多个目录的调用
第三章 关于__init__.py的解释
(1)初始化包中各个模块,批量导入
(2)__init__.py中的__all__,全部导入所声明的模块
第四章 关于pyc与pyo文件
第五章 模块导入时内部的原理
(1)import可导入的对象可以是以下类型:
(2)解释器工作:
(3)因此可以理解导入文件的三种方式:
摘要:
本文章主要介绍了python运行或调用另一个py文件或参数方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,请提出来。
第一章 运行另一个py文件
(1)在file_A.py中运行file_B.py文件,注意这里是运行,不是引用
import os
os.system("python file_B.py para_a1 para_a2")
#其他形式
os.system("python file_B.py %s" % para_A)
os.system("python file_B.py " + para_A)需要注意文件路径的写法,在docker中运行文件,文件名前面需要加/,如os.system("python /file_B.py")
(2)file_B.py使用file_A.py传递的参数
import sys
print(sys.argv)
#由打印的结果可知,sys.argv[1:]是命令行传递的参数,sys.argv[0]是命令行运行的文件名
para_B = sys.argv[1](3) 引用另一个py文件中的变量或者方法
from file_A import df_A第二章 python调用自己写的py文件
(1)同一个目录下的文件
同一个目录下直接写import xx就好了,xx为自己要调用的模块名字,虽然会有下划线报错,其实,没有错,仍然可以调用,这个下划线可以忽略。
(2)不同目录下的文件
不同路径下的文件先要调用添加路径sys.path.append(r"C:\xxx"),再做引用
import sys
#首先,添加路径,windows的路径和linux的路径符号不同\\,/,注意区别
#r是为了告诉python这是路径,别#把\n等特殊组合给转译)
sys.path.append(r"C:\xxx")
#下面import就可以了
import a
import b(3)多个文件在多个目录的调用
首先我们也可以多次写sys.path.append(r"C:\xxx")来添加多个目录,但是这样有点麻烦,每次新建个工程可能就要加很多代码去调用公共单元。
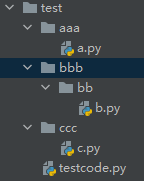
解决方法是添加一个空的__init__.py文件(用于定义包的属性和方法,可以为空),表示这是一个包,比如这样,声明了aaa为一个包,a是内部的方法。
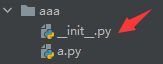
也可以这样,表示bbb是一个包,bb是bbb的子包,b是bb包的内部的方法
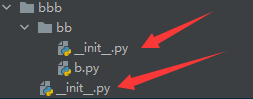
如果你需要调用a.py与b.py:
import aaa.a
import bbb.bb.b
import ccc.c如果你在c.py文件,想要调用a.py,b.py只需要用到步骤2的知识即可,比如
import sys
#添加上级目录
sys.path.append("..//")
import aaa.a
import bbb.bb.b第三章 关于__init__.py的解释
__init__.py作用是将文件夹变为一个Python模块,导入包时,事实上是导入了它的__init__.py文件
__init__.py 文件可以为空,但是也可以添加如下两个功能
(1)初始化包中各个模块,批量导入
pack包,配置__init__.py
| 1 2 |
|
导入pack包
访问__init__.py文件中的引用文件,需要加上包名
(2)__init__.py中的__all__,全部导入所声明的模块
此时导入pack包就相当于导入了a.py,b.py,c.py
pack包,配置__init__.py
| 1 |
|
调用
| 1 |
|
第四章 关于pyc与pyo文件
pyc就是py编译时生成的字节码文件,以后每次导入都会执行pyc,当py文件更新时pyc也会更新
如果解释器添加-o命令,py编译时会生成pyo文件,它相比pyc去掉了断言(assert)、断行号以及其他调试信息,运行速度更快
如果使用-OO选项,生成的pyo文件会忽略文档信息
第五章 模块导入时内部的原理
(1)import可导入的对象可以是以下类型:
- 模块文件(.py文件)
- C或C++扩展(已编译为共享库或DLL文件)
- 包(包含多个模块)
- 内建模块(使用C编写并已链接到Python解释器中)
- 理解为后缀就是.py、.pyo、.pyc、.pyd、.so、.dll
(2)解释器工作:
1.根据导入的文件名创建命名空间(用来访问文件内部属性与方法)
2.在命名空间内执行源代码
3.创建一个源代码文件的对象,这个对象引用对应的命名空间,管理模块的内部函数与变量
4.一个模块可以多次导入,但是后面导入的模块只执行第三步
sys.modules可以打印出导入的模块名与模块对象的映射
(3)因此可以理解导入文件的三种方式:
import a.b:把a.b导入全局命名空间,想要调用c方法需要a.b.cfrom a import b:把b导入全局命名空间,b.cfrom a.b import c:把b的属性c直接导入命名空间