【spring源码】源码分析
【spring源码】源码分析
- (一)mac版idea引入spring源码
- (二)spring的学习流程
- (三)spring源码分析
-
-
- 【1】refresh()方法概览(AbstractApplicationContext抽象类里的refresh方法)
-
-
- (1)阅读源码进行debug调试的方法
-
- 【2】通过一张思维导图说明refresh每个方法主要完成的事
- 【3】spring工作流程图
-
- (四)spring源码设计架构,认识spring框架的工作 流程
-
-
- 【1】spring设计思想图
- 【2】认识一些重要接口
-
-
- (1)BeanFactory接口
- (2)第一阶段:注册BeanDefinition
- (3)第二阶段:执行BeanFactoryPostProcessor
- (4)第三阶段:注册BeanPostProcessor、监听器等
- (5)第四阶段:创建bean(实例化-初始化-放入容器)
- (6)第五阶段:管理生命周期、发布刷新事件
-
-
- (五)spring源码的debug过程
-
- 【1】首先是测试方法的入口【ApplicationContext】
- 【2】读取xml配置文件
- 【3】构造器中调用【refresh】方法
- 【4】为创建bean工厂做准备工作【prepareRefresh】
- 【5】开始创建bean工厂和bean对象加载【obtainFreshBeanFactory】
- 【6】bean工厂里众多属性值需要赋值【prepareBeanFactory】
- 【7】通过增强器对bean进行处理【postProcessBeanFactory】
- 【8】实例化并调用BeanFactoryPostProcessor方法【invokeBeanFactoryPostProcessors】
- 【9】实例化并注册BeanPostProcessor【registerBeanFactoryProcessors】
- 【10】做国际化处理【initmessageSource】(过)
- 【11】初始化应用事件多播器,方便后面的发布监听事件
- 【12】onFresh方法
- 【13】创建监听器,方便后面使用【registerListener】
- 【14】【bean生命周期】开始实例化剩下的非懒加载单例bean对象【finishBeanFactoryInitialization】
-
- (1)把所有的beanName放进List,然后开始遍历完成实例化bean对象
- (2)开始实例化bean对象
- (3)开始填充属性(用户自定义属性赋值)
- (4)开始调用Aware接口(容器对象赋值)
- (5)开始初始化前置处理【BeanpostProcessor:before】
- (6)开始执行初始化调用init方法
- (7)开始初始化后置处理【BeanpostProcessor:after】
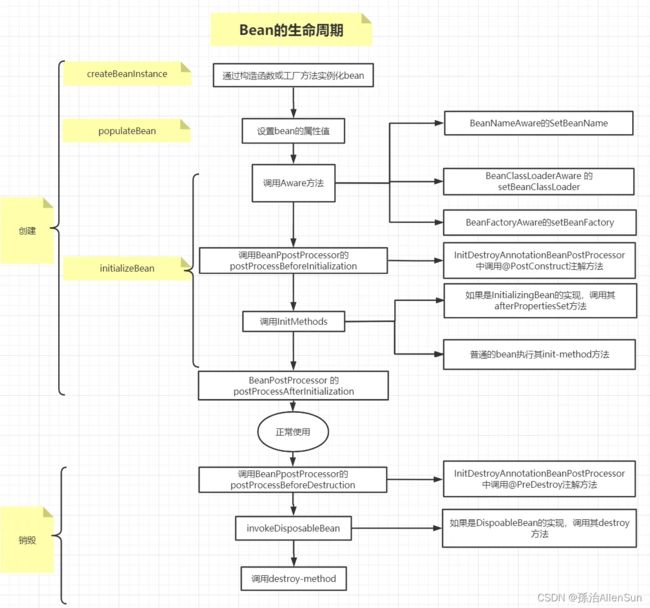
- (六)bean生命周期概述
- (七)循环依赖问题详解
-
- 【1】什么是循环依赖?
- 【2】spring中解决循环依赖的思路
- 【3】三级缓存介绍
-
- (1)三级缓存的代码
- (2)三级缓存的各个功能
- (3)spring三大缓存介绍
- 【4】三级缓存的debug流程详解
-
- (1)源码中留意的6个重要方法
- (2)debug流程
- (3)三级缓存debug流程的总结
-
- 1-第一阶段
- 2-第二阶段
- 3-第三阶段
- 4-第四阶段
- 5-第五阶段
- 6-第六阶段
- 7-过程图
- 【5】三级缓存的重要问题
-
- (1)为什么第三级缓存要使用ObjectFactory?
- (2)什么时候将Bean的引用提前暴露给第三级缓存的ObjectFactory持有?
- (3)如果只有一级缓存
- (4)如果只有二级缓存
- (5)二级缓存已然解决了循环依赖问题,为什么还需要三级缓存?
- (6)Spring是如何解决的循环依赖?
- 【7】spring解决循环依赖的详细流程
-
- (1)前期铺垫工作
- (2)什么情况下循环依赖可以被处理?
- (3)Spring是如何解决的循环依赖?
-
- (1)简单的循环依赖(没有AOP)
-
- (1)案例demo
- (2)Spring在创建Bean的时候默认是按照自然排序来进行创建的,所以第一步Spring会去创建A
- (3)循环依赖处理过程的关键方法步骤流程图
-
- 【1】调用getSingleton(beanName)
- 【2】调用getSingleton(beanName, singletonFactory)
- 【3】调用addSingletonFactory方法
- (2)结合了AOP的循环依赖
- (3)三级缓存真的提高了效率了吗?
- (4)总结
重点问题
1-聊聊spring
2-bean的生命周期
3-循环依赖
4-三级缓存
5-FactoryBean和beanFactory的区别(怎么执行的,执行流程是什么?)
6-ApplicationContext和BeanFactory的区别
7-设计模式
spring框架就是springboot和spingcloud等框架的基石,后来的框架都是在sprig的基础上上进行扩展的。
IOC容器用来存放bean对象,这就引申出来对象存放的数据结构map,通过k-v结构来存放创建的对象和获取对象。存放的方式就是(beanName-bean对象),想要取出对象的时候就可以通过get方法通过beanName取出对应的baean对象
(一)mac版idea引入spring源码
spring源码下载地址:https://github.com/spring-projects/spring-framework/tree/5.0.x
选择版本为5.0.x
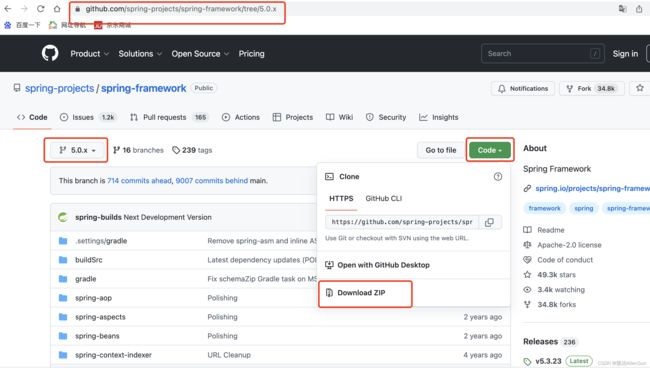
正确的文件目录是这样的

配置gradle,选择版本4.4.1,下载地址:https://gradle.org/releases/
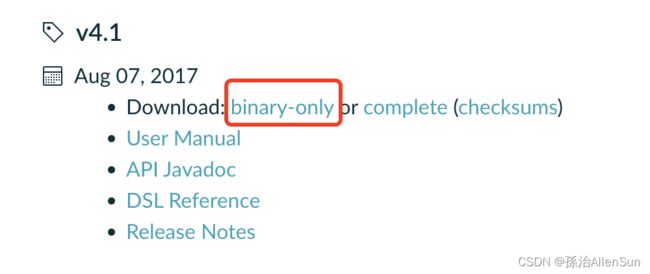
配置完环境变量,查看版本的时候,命令报错了,发现jdk15与gradle4.4不兼容,所以使用homebrew对jdk进行降级
也可以使用homebrew来进行安装,安装的就是最新的版本了:brew install gradle
总结:
1-首先到spring的git上把想要的源码版本压缩包下载下来
2-电脑下载配置gradle才能对源码进行编译测试
3-注意的是spring源码的版本+gradle版本+jdk版本,都要兼容才行,否则会报错
目前的进度是jdk的版本是15,太高了,和gradle的版本不兼容,后面要改一个的版本,目前先看源码,不编译,暂时也没有什么问题。。。
参考的内容:https://www.jianshu.com/p/02f17909e2d6
(二)spring的学习流程
1-熟悉理论上的执行流程,画流程图来记忆
2-对不同部分的源码代码进行解析,添加备注
3-对源码进行debug调试
(三)spring源码分析
【1】refresh()方法概览(AbstractApplicationContext抽象类里的refresh方法)
(1)阅读源码进行debug调试的方法
public static void main(String[] args) {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("classpath:spring.xml");
UserVo userVo = context.getBean(UserVo.class);
EnterpriseVo enterpriseVo = context.getBean(EnterpriseVo.class);
System.out.println("userVo=" + userVo);
System.out.println("enterpriseVo=" + enterpriseVo);
context.close();
}
从上面第2行开始进入下面的方法
public ClassPathXmlApplicationContext(String[] configLocations, boolean refresh, @Nullable ApplicationContext parent) throws BeansException {
super(parent);
this.setConfigLocations(configLocations);
if (refresh) {
this.refresh();
}
}
第3行是设置配置文件,就是传递的classpath:spring.xml
第5行是调用refresh方法,也就是spring容器启动的入口所在,该方法中共有13个子方法
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
/*(1)完成前期的准备工作(其实这一步什么都没有处理,只是准备一些数据)
准备要刷新的上下文:
设置启动日期和激活标志,以便执行任意属性来源的初始化
初始化上下文环境中的占位符属性来演
获取环境信息并校验必传参数
准备早期的应用程序监听器
准备早期应用监听事件,一旦多播器可用就将早期的应用事件发布到多播器中*/
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
//(2)创建容器对象:DefaultListableBeanFactory
//加载xml配置文件的属性值到当前工厂中,最重要的就是BeanDefinition
//获得一个新的bean工厂对象,来装载具体的bean对象
//让子类刷内置的bean工厂,返回的是ConfigurableListableBeanFactory的子类对象DefaultListableBeanFactory
//注意:BeanFactory和ApplicationContext的区别:前者在加载文件时不创建对象,后者在加载文件时就创建好bean对象
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
//(3)beanFactory的准备工作,对各种属性进行填充
//此时只是开辟了空间,还没有赋值,新的bean对象中有很多属性值都是默认的0,在这里要进行赋值
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
//(4)子类覆盖方法做额外的处理,此处我们自己一般不做任何扩展工作,但是可以查看web中的代码,是有具体实现的
//空方法,交给子类来实现
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
//(5)调用各种beanFactory处理器
//实例化并且调用所有的BeanFactoryPostProcessor接口,对bean的定义信息进行加强修改
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
//(6)准备好监听器/监听事件等等,实例化并且注册所有的BeanPostProcessor
//但是此刻不会执行,只是为后续流程做准备工作
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
//(7)做国际化处理
initMessageSource();
// Initialize event multicaster for this context.
//(8)初始化应用事件的多播器,用来发布监听事件
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
//(9)能够被覆盖的模板方法,用来添加特定上下文的更新工作,在特殊bean进行初始化或者单例bean进行实例化时被调用,在该类中是一个空实现
//三个子类中都是调用UiApplicationContextUtils.initThemeSource(this)方法
onRefresh();
// Check for listener beans and register them.
//(10)注册监听器,这一步就完成在实例化bean对象之前完成监听器和监听事件的准备工作
//在所有注册的bean中查找Listener bean,注册到消息广播器中,即向监听器发布事件
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
//(11)实例化剩下的所有的非懒加载的单例对象
//对非延迟初始化的单例进行实例化,一般情况下的单例都会在这里就实例化了,这样的好处是,在程序启动过程中就可以及时发现问题
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
//(12)最后一步:完成刷新过程,通知生命周期处理器lifecycleProcessor刷新过程
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
//当发生异常时销毁已经创建的单例
destroyBeans();
// Reset 'active' flag.
//重置active标识为false
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
//(13)清空所有的缓存,因为单例bean是在容器启动时初始化完毕,所以不需要保留它们的元数据信息
resetCommonCaches();
}
}
}
【2】通过一张思维导图说明refresh每个方法主要完成的事
【3】spring工作流程图
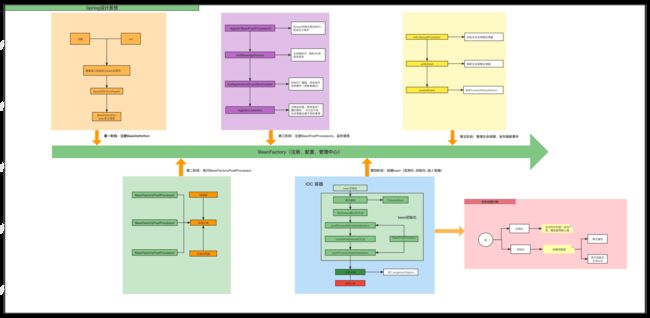
(四)spring源码设计架构,认识spring框架的工作 流程
【1】spring设计思想图
【2】认识一些重要接口
(1)BeanFactory接口
(1)源码的描述信息
(1)访问Spring bean容器的根接口
(2)BeanFactory是访问Spring bean容器的根接口,这是一个bean容器基本的客户端视图,此外还有像ListableBeanFactory和ConfigurableBeanFactory这种为了特定目标使用的接口
(3)该接口会被持有大量bean定义的对象实现,每一个都是通过一个字符串类型的name进行唯一标识。
根据bean的定义信息,工厂既可以返回一个已经存在对象的单独实例实例(原型设计模式),还可以返回一个能够被共享的单例实例(单例模式)
返回什么类型的实例,将依赖bean工厂中scope的配置:具有相同的API。从Spring2.0开始,可以根据具体的应用上下文使用其他的scope,比如web应用中的request和session等
这种实现方式的精髓在于它让BeanFactory成为应用组件的注册和配置中心,比如单个对象将不再需要去读取属性文件
从注释中可以获取的三点重要信息:
1、这是访问spring容器的根接口
2、这个接口被维护BeanDefinition信息的接口所继承,提供了对bean定义信息的管理,通过该接口,可以返回单例或多例的bean实例
3、它就像一个应用组件的注册和配置中心,集中管理容器中的bean,而不需要为了某个单独的bean单独读取配置文件
(1)认识BeanFactory
1-BeanFactory也是一个接口
作用就是:The root interface for accessing a Spring bean container. 翻译过来就是“用来访问spring的bean容器”,把BeanFactory当作一个入口
2-BeanFactory和applicationContext有什么关系?
applicationContext继承了BeanFactory接口,提供了一系列更加完善的功能
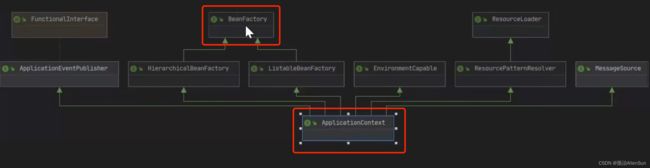
3-DefaultListableBeanFactory
是BeanFactory的一个子类,看作是我们创建的Spring容器,创建的bean对象都是放在这个类里的
4-能不能通过BeanFactory获取BeanDefinition?
能,因为在BeanFactory没有对应的方法,但是可以到子类里去查找,找到ConfigurableBeanFactory,在子类中有更多的获取属性的方法
(2)第一阶段:注册BeanDefinition
(一)BeanDefinition的基本定义
BeanDefinition是一个接口,继承了AttributeAccessor,BeanMetadataElement,用来管理Bean的属性和元数据,管理的数据有属性、构造器、参数、是否单例、是否懒加载等这些我们平时定义的信息。在这个阶段,主要是扫描我们定义的Java类,定义的方式有基于xml和注解两种方式,把每个类的描述信息封装成一个BeanDefinition对象,注册到工厂中,生成一个beanName->BeanDefinition的Map映射关系,以便后续通过get方法根据beanName获取对应的BeanDefinition。
(二)BeanDefinition一些重点信息
(1)IOC容器首先通过xml配置文件或者@controller等注解获取bean的定义信息,对于bean有一个十分重要的接口叫BeanDefinition,把bean的定义信息放进BeanDefinition,然后将BeanDefinition交给容器,当容器识别到BeanDefinition后再根据BeanDefinition里的相关信息把需要的bean对象创建出来
(2)如何读取xml文件和注解
首先通过IO流读取文件获得字符串,字符串解析转成document,然后转成父子关系的node节点,再然后对node节点进行循环遍历能取出其中的具体数据值,最后把数据值交给容器
(3)BeanDefinition接口的源码
在接口的子类实现中,可以把通过配置文件或者注解获取的数据赋值到子类中,然后把赋值后的BeanDefinition交给容器
public interface BeanDefinition extends AttributeAccessor, BeanMetadataElement {
/**
* Scope identifier for the standard singleton scope: "singleton".
* Note that extended bean factories might support further scopes.
* @see #setScope
*/
String SCOPE_SINGLETON = ConfigurableBeanFactory.SCOPE_SINGLETON;
/**
* Scope identifier for the standard prototype scope: "prototype".
* Note that extended bean factories might support further scopes.
* @see #setScope
*/
String SCOPE_PROTOTYPE = ConfigurableBeanFactory.SCOPE_PROTOTYPE;
/**
* Role hint indicating that a {@code BeanDefinition} is a major part
* of the application. Typically corresponds to a user-defined bean.
*/
int ROLE_APPLICATION = 0;
/**
* Role hint indicating that a {@code BeanDefinition} is a supporting
* part of some larger configuration, typically an outer
* {@link org.springframework.beans.factory.parsing.ComponentDefinition}.
* {@code SUPPORT} beans are considered important enough to be aware
* of when looking more closely at a particular
* {@link org.springframework.beans.factory.parsing.ComponentDefinition},
* but not when looking at the overall configuration of an application.
*/
int ROLE_SUPPORT = 1;
/**
* Role hint indicating that a {@code BeanDefinition} is providing an
* entirely background role and has no relevance to the end-user. This hint is
* used when registering beans that are completely part of the internal workings
* of a {@link org.springframework.beans.factory.parsing.ComponentDefinition}.
*/
int ROLE_INFRASTRUCTURE = 2;
// Modifiable attributes
/**
* Set the name of the parent definition of this bean definition, if any.
*/
void setParentName(@Nullable String parentName);
/**
* Return the name of the parent definition of this bean definition, if any.
*/
@Nullable
String getParentName();
/**
* Specify the bean class name of this bean definition.
* The class name can be modified during bean factory post-processing,
* typically replacing the original class name with a parsed variant of it.
* @see #setParentName
* @see #setFactoryBeanName
* @see #setFactoryMethodName
*/
void setBeanClassName(@Nullable String beanClassName);
/**
* Return the current bean class name of this bean definition.
* Note that this does not have to be the actual class name used at runtime, in
* case of a child definition overriding/inheriting the class name from its parent.
* Also, this may just be the class that a factory method is called on, or it may
* even be empty in case of a factory bean reference that a method is called on.
* Hence, do not consider this to be the definitive bean type at runtime but
* rather only use it for parsing purposes at the individual bean definition level.
* @see #getParentName()
* @see #getFactoryBeanName()
* @see #getFactoryMethodName()
*/
@Nullable
String getBeanClassName();
/**
* Override the target scope of this bean, specifying a new scope name.
* @see #SCOPE_SINGLETON
* @see #SCOPE_PROTOTYPE
*/
void setScope(@Nullable String scope);
/**
* Return the name of the current target scope for this bean,
* or {@code null} if not known yet.
*/
@Nullable
String getScope();
/**
* Set whether this bean should be lazily initialized.
* If {@code false}, the bean will get instantiated on startup by bean
* factories that perform eager initialization of singletons.
*/
void setLazyInit(boolean lazyInit);
/**
* Return whether this bean should be lazily initialized, i.e. not
* eagerly instantiated on startup. Only applicable to a singleton bean.
*/
boolean isLazyInit();
/**
* Set the names of the beans that this bean depends on being initialized.
* The bean factory will guarantee that these beans get initialized first.
*/
void setDependsOn(@Nullable String... dependsOn);
/**
* Return the bean names that this bean depends on.
*/
@Nullable
String[] getDependsOn();
/**
* Set whether this bean is a candidate for getting autowired into some other bean.
* Note that this flag is designed to only affect type-based autowiring.
* It does not affect explicit references by name, which will get resolved even
* if the specified bean is not marked as an autowire candidate. As a consequence,
* autowiring by name will nevertheless inject a bean if the name matches.
*/
void setAutowireCandidate(boolean autowireCandidate);
/**
* Return whether this bean is a candidate for getting autowired into some other bean.
*/
boolean isAutowireCandidate();
/**
* Set whether this bean is a primary autowire candidate.
* If this value is {@code true} for exactly one bean among multiple
* matching candidates, it will serve as a tie-breaker.
*/
void setPrimary(boolean primary);
/**
* Return whether this bean is a primary autowire candidate.
*/
boolean isPrimary();
/**
* Specify the factory bean to use, if any.
* This the name of the bean to call the specified factory method on.
* @see #setFactoryMethodName
*/
void setFactoryBeanName(@Nullable String factoryBeanName);
/**
* Return the factory bean name, if any.
*/
@Nullable
String getFactoryBeanName();
/**
* Specify a factory method, if any. This method will be invoked with
* constructor arguments, or with no arguments if none are specified.
* The method will be invoked on the specified factory bean, if any,
* or otherwise as a static method on the local bean class.
* @see #setFactoryBeanName
* @see #setBeanClassName
*/
void setFactoryMethodName(@Nullable String factoryMethodName);
/**
* Return a factory method, if any.
*/
@Nullable
String getFactoryMethodName();
/**
* Return the constructor argument values for this bean.
* The returned instance can be modified during bean factory post-processing.
* @return the ConstructorArgumentValues object (never {@code null})
*/
ConstructorArgumentValues getConstructorArgumentValues();
/**
* Return if there are constructor argument values defined for this bean.
* @since 5.0.2
*/
default boolean hasConstructorArgumentValues() {
return !getConstructorArgumentValues().isEmpty();
}
/**
* Return the property values to be applied to a new instance of the bean.
* The returned instance can be modified during bean factory post-processing.
* @return the MutablePropertyValues object (never {@code null})
*/
MutablePropertyValues getPropertyValues();
/**
* Return if there are property values values defined for this bean.
* @since 5.0.2
*/
default boolean hasPropertyValues() {
return !getPropertyValues().isEmpty();
}
// Read-only attributes
/**
* Return whether this a Singleton, with a single, shared instance
* returned on all calls.
* @see #SCOPE_SINGLETON
*/
boolean isSingleton();
/**
* Return whether this a Prototype, with an independent instance
* returned for each call.
* @since 3.0
* @see #SCOPE_PROTOTYPE
*/
boolean isPrototype();
/**
* Return whether this bean is "abstract", that is, not meant to be instantiated.
*/
boolean isAbstract();
/**
* Get the role hint for this {@code BeanDefinition}. The role hint
* provides the frameworks as well as tools with an indication of
* the role and importance of a particular {@code BeanDefinition}.
* @see #ROLE_APPLICATION
* @see #ROLE_SUPPORT
* @see #ROLE_INFRASTRUCTURE
*/
int getRole();
/**
* Return a human-readable description of this bean definition.
*/
@Nullable
String getDescription();
/**
* Return a description of the resource that this bean definition
* came from (for the purpose of showing context in case of errors).
*/
@Nullable
String getResourceDescription();
/**
* Return the originating BeanDefinition, or {@code null} if none.
* Allows for retrieving the decorated bean definition, if any.
* Note that this method returns the immediate originator. Iterate through the
* originator chain to find the original BeanDefinition as defined by the user.
*/
@Nullable
BeanDefinition getOriginatingBeanDefinition();
}
(3)第二阶段:执行BeanFactoryPostProcessor
(1)源码注释信息
BeanDefinition只是一个最小的接口,设计它的主要目的是为了让BeanFactoryPostProcessor内省并修改属性值和其他bean的元信息,所以执行BeanFactoryPostProcessor的主要目的就是可以通过自定义实现对bean定义信息的修改,比如修改属性等。其实这个接口是bean工厂的后置处理器,它的操作范围是整个工厂,通过实现这个接口,我们可以获取到工厂中已经注册的所有bean的定义信息,并对任意信息进行修改
(2)举个例子
1-首先,定义一个bean
package com.spring.reading.bd.processor;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
import org.springframework.beans.factory.config.BeanDefinition;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;
/**
* @author: cyhua
* @createTime: 2021/12/6
* @description: 定义一个普通的bean,含有一个属性,scope手动设置原型
*/
@Data
@Component
@ToString
@NoArgsConstructor
@AllArgsConstructor
@Scope(value = BeanDefinition.SCOPE_PROTOTYPE)
public class Company {
private String name;
}
@Scope(value = BeanDefinition.SCOPE_PROTOTYPE)
把scope自定义为原型,就是多例,为了在BeanFactoryPostProcessor中对它进行修改!
2-其次,自定义一个BeanFactoryPostProcessor
package com.spring.reading.bd.processor;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.FactoryBean;
import org.springframework.beans.factory.config.BeanDefinition;
import org.springframework.beans.factory.config.BeanFactoryPostProcessor;
import org.springframework.beans.factory.config.ConfigurableListableBeanFactory;
import org.springframework.beans.factory.config.ConstructorArgumentValues;
import org.springframework.beans.factory.support.AbstractBeanDefinition;
import org.springframework.beans.factory.support.BeanDefinitionBuilder;
import org.springframework.stereotype.Component;
/**
* @author: cyhua
* @createTime: 2021/12/5
* @description: bean工厂后置处理器
*/
@Component
public class ReadingBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {
AbstractBeanDefinition beanDefinition = (AbstractBeanDefinition) configurableListableBeanFactory.getBeanDefinition("company");
//获取构造函数的参数值
ConstructorArgumentValues constructorArgumentValues = beanDefinition.getConstructorArgumentValues();
//获取是否懒加载配置
Boolean lazyInit = beanDefinition.isLazyInit();
//获取scope配置
String scope = beanDefinition.getScope();
//获取注入模式配置:byName或byType
int autowireMode = beanDefinition.getAutowireMode();
//scope如果为空或多例,则修改scope为单例
if (StringUtils.isBlank(scope) || scope.equals(BeanDefinition.SCOPE_PROTOTYPE)) {
beanDefinition.setScope(BeanDefinition.SCOPE_SINGLETON);
}
}
}
上面代码获取了几个比较常见的BeanDefinition信息,最后当scope为空或者为多例的时候,修改为单例!
3-接下来,写一个测试类,获取两个company对象,并且进行比较,确认是不是由多例改成了单例!
package com.spring.reading.bd.processor;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
/**
* @author: cyhua
* @createTime: 2021/12/5
* @description:
*/
public class BeanDefinitionCaller {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(BeanDefinitionConfig.class);
Company company1 = context.getBean("company", Company.class);
Company company2 = context.getBean("company", Company.class);
//比较两个对象是否相同:按道理已经设置成单例,会返回true
System.out.println(company1 == company2);
}
}
4-进行debug,看看在BeanFactoryPostProcessor中是否能获取到bean定义信息
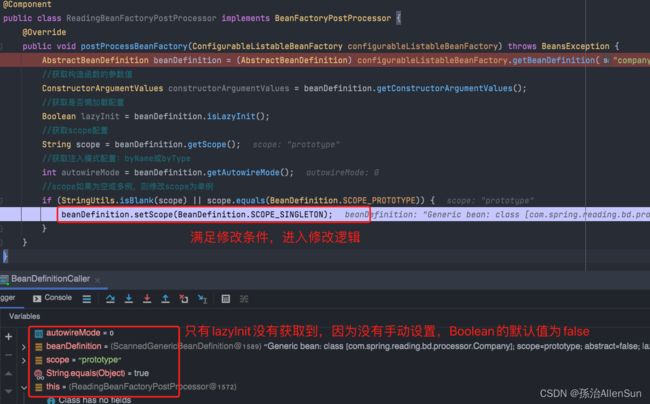 可以看当程序成功进入自定义的bean工厂后置处理器,也获取到了具体的BeanDefinition,下面看执行结果
可以看当程序成功进入自定义的bean工厂后置处理器,也获取到了具体的BeanDefinition,下面看执行结果
 可以看到获取到了两个相同额对象,说明bean工厂后置处理器生效,修改bean定义成功,这就是执行BeanFactoryPostProcessor的作用,主要还是为了处理自定义的逻辑,方便开发者进行扩展,而且整个扩展过程完全满足OCP原则。
可以看到获取到了两个相同额对象,说明bean工厂后置处理器生效,修改bean定义成功,这就是执行BeanFactoryPostProcessor的作用,主要还是为了处理自定义的逻辑,方便开发者进行扩展,而且整个扩展过程完全满足OCP原则。
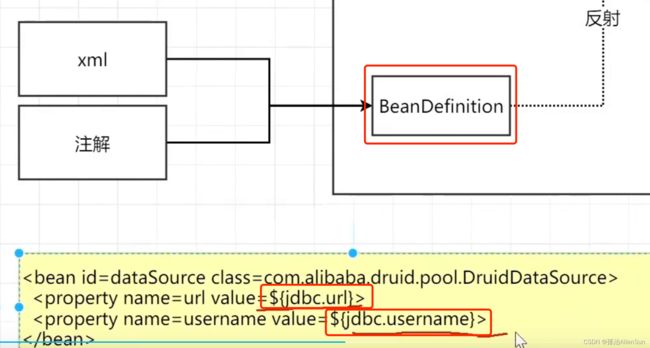
(3)认识BeanFacoryPostProcessor,在把bean的配置信息装进BeanDefinition的时候会不会替换占位符的值?
不会,会在下一步的BeanFacoryPostProcessor里对这个值进行替换,在这个增强器里完成扩展工作
BeanFacoryPostProcessor的作用就是允许自定义修改,完成BeanDefinition信息的替换工作
(5)BeanFacoryPostProcessor和BeanPostProcessor的区别
1-起作用的位置不一样
2-针对的对象不一样,一个是针对bean,一个是针对beanFactory
(4)第三阶段:注册BeanPostProcessor、监听器等
第三个阶段主要还是准备一些后续需要的特殊bean,比如bean的后置处理器BeanPostProcessor、用户处理国际化的MessageSource、发布事件的广播器ApplicationEventMulticaster以及监听事件的监听器,下面针对这四种特殊的bean进行说明:
(1)BeanPostProcessor接口
包含两个方法
/**
* 在bean实例化之后,初始化之前使用,可以对返回对实例进行修改,比如修改属性值
* @param bean 要处理的bean实例
* @param beanName 要处理的bean名称
* @return 返回处理后的实例,默认返回传进来的实例
* @throws BeansException
*/
@Nullable
default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
/**
* 在bean初始化之后执行,可以对完成初始化的对象进行进一步的处理,比如生成代理对象,AOP中使用
* @param bean 要处理的bean
* @param beanName 要处理的bean名称
* @return
* @throws BeansException 返回处理后的实例,默认返回传进来的实例
*/
@Nullable
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
如注释所述,该接口提供了两个默认实现的方法,用于在初始化前后,对已经完成实例化的对象进行处理,虽然是接口,但是因为有了默认实现,开发时无需实现,但是可以通过自定义的后置处理器对bean进行特殊的处理,在AOP中,代理对象的生成就是利用了这里的postProcessAfterInitialization方法

2-MessageSource接口
用于处理国际化的接口,源码中是这样描述的:
1、解析消息的策略接口,能猴支持消息的参数化和国际化
2、在spring中提供了两个开箱即用的实现类:
一个构建在Java标准ResourceBundle之上的类ResourceBundleMessageSource
一个高度可配置的ReloadableResourceBundleMessageSource,值得一提的就是它能够重载消息定义
一般在支持国际化的项目中需要用到,知道有这么个接口即可!
3-ApplicationEventMulticaster接口
用户发布事件的接口,继承关系如下
 有两个存在继承关系的实现类,使用的是观察者模式
有两个存在继承关系的实现类,使用的是观察者模式
4-ApplicationListener
有事件发布,就有事件监听,这个接口跟上面的广播器构成了观察者模式,用来处理spring中各种事件
(5)第四阶段:创建bean(实例化-初始化-放入容器)
是最重要、最复杂的一个阶段,前三个阶段都是在为这个阶段做准备的,在这个阶段,需要一个意识:就是spring创建一个完整的对象需要经过三个大的步骤:实例化—>属性填充—>初始化,而在初始化前后又可能会执行一些后置处理器
实例化阶段:只是在内存汇总开辟了一块空间,底层是通过bean定义信息推断出无参构造函数,然后选择合适的策略进行实例化,最后返回一个被Wrapper包装的实例,核心代码如下,一个位于BeanUtils类中的静态方法:
/**
* Convenience method to instantiate a class using the given constructor.
* Note that this method tries to set the constructor accessible if given a
* non-accessible (that is, non-public) constructor, and supports Kotlin classes
* with optional parameters and default values.
* 使用给定的构造器调用实例化方法,需要注意的是,如果传递的是一个无访问全县的构造器,比如非public的,这个方法首先会尝试开启访问权限
*,而且通过可选参数支持Kotlin类和默认值
* @param ctor the constructor to instantiate 实例化构造器
* @param args the constructor arguments to apply (use {@code null} for an unspecified 构造器参数
* parameter, Kotlin optional parameters and Java primitive types are supported)
* @return the new instance
* @throws BeanInstantiationException if the bean cannot be instantiated
* @see Constructor#newInstance
*/
public static <T> T instantiateClass(Constructor<T> ctor, Object... args) throws BeanInstantiationException {
Assert.notNull(ctor, "Constructor must not be null");
try {
//尝试将构造函数设置为可访问的
ReflectionUtils.makeAccessible(ctor);
if (KotlinDetector.isKotlinReflectPresent() && KotlinDetector.isKotlinType(ctor.getDeclaringClass())) {
return KotlinDelegate.instantiateClass(ctor, args);
}
else {
//获取构造器中的参数
Class<?>[] parameterTypes = ctor.getParameterTypes();
//判断构造器中的参数个数是否比传进来的参数个数少,多则抛异常
Assert.isTrue(args.length <= parameterTypes.length, "Can't specify more arguments than constructor parameters");
Object[] argsWithDefaultValues = new Object[args.length];
//组装构造器的参数
for (int i = 0 ; i < args.length; i++) {
if (args[i] == null) {
Class<?> parameterType = parameterTypes[i];
argsWithDefaultValues[i] = (parameterType.isPrimitive() ? DEFAULT_TYPE_VALUES.get(parameterType) : null);
}
else {
argsWithDefaultValues[i] = args[i];
}
}
//通过构造方法创建一个bean实例
return ctor.newInstance(argsWithDefaultValues);
}
}
catch (InstantiationException ex) {
throw new BeanInstantiationException(ctor, "Is it an abstract class?", ex);
}
catch (IllegalAccessException ex) {
throw new BeanInstantiationException(ctor, "Is the constructor accessible?", ex);
}
catch (IllegalArgumentException ex) {
throw new BeanInstantiationException(ctor, "Illegal arguments for constructor", ex);
}
catch (InvocationTargetException ex) {
throw new BeanInstantiationException(ctor, "Constructor threw exception", ex.getTargetException());
}
}
属性填充阶段:该阶段是在完成时实例化之后,初始化之前执行的,填充属性,就是给属性赋值,比如数据库连接信息中有很多初始化值,就是在这个阶段进行填充。
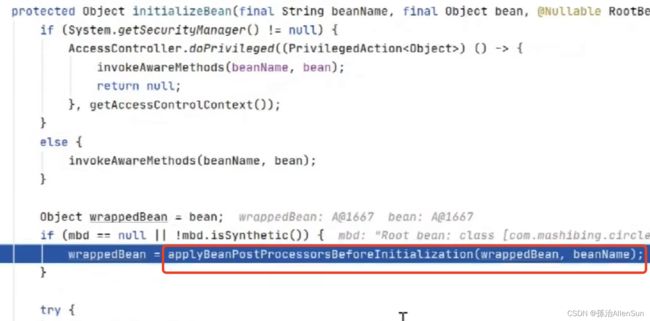
初始化阶段:该阶段是在完成实例化及属性填充之后执行的,而且在执行真正的初始化前后又要执行一些BeanPostProcessor的后置处理器,核心代码如下,调用AbstractAutowireCapableBeanFactory#initializeBean方法:
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
invokeAwareMethods(beanName, bean);
return null;
}, getAccessControlContext());
}
else {
//执行aware:回调实现了Aware接口的方法:设置beanName、classLoader、beanFactory等
invokeAwareMethods(beanName, bean);
}
//初始化之前执行
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
//会执行BeanPostProcessor的postProcessBeforeInitialization方法
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
//执行自定义初始化方法,会执行初始化方法,这个方法可以自定义,就是在bean定义是指定的init-method
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
}
//初始化之后执行
if (mbd == null || !mbd.isSynthetic()) {
//会执行BeanPostProcessor的postProcessAfterInitialization方法
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
下面是完成最终初始化的核心代码,调用AbstractAutowireCapableBeanFactory#invokeInitMethods方法
/**
* Give a bean a chance to react now all its properties are set,
* and a chance to know about its owning bean factory (this object).
* This means checking whether the bean implements InitializingBean or defines
* a custom init method, and invoking the necessary callback(s) if it does.
* 给bean一个反应它所有的属性都完成设置和了解它所属工厂的机会,这意味着不管bean实现了InitializingBean接口还是自定义了一个初始化方法,都会在这个地方被调用
* @param beanName the bean name in the factory (for debugging purposes) :bean在工厂中的名称
* @param bean the new bean instance we may need to initialize:准备去初始化的实例对象
* @param mbd the merged bean definition that the bean was created with 创建该bean的合并bean定义信息
* (can also be {@code null}, if given an existing bean instance)
* @throws Throwable if thrown by init methods or by the invocation process
* @see #invokeCustomInitMethod
*/
protected void invokeInitMethods(String beanName, Object bean, @Nullable RootBeanDefinition mbd)
throws Throwable {
//判断是否实现了InitializingBean接口,如果实现了就去执行afterPropertiesSet方法
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
if (logger.isTraceEnabled()) {
logger.trace("Invoking afterPropertiesSet() on bean with name '" + beanName + "'");
}
if (System.getSecurityManager() != null) {
try {
AccessController.doPrivileged((PrivilegedExceptionAction<Object>) () -> {
((InitializingBean) bean).afterPropertiesSet();
return null;
}, getAccessControlContext());
}
catch (PrivilegedActionException pae) {
throw pae.getException();
}
}
else {
((InitializingBean) bean).afterPropertiesSet();
}
}
//执行自定义的初始化方法
if (mbd != null && bean.getClass() != NullBean.class) {
String initMethodName = mbd.getInitMethodName();
if (StringUtils.hasLength(initMethodName) &&
!(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&
!mbd.isExternallyManagedInitMethod(initMethodName)) {
invokeCustomInitMethod(beanName, bean, mbd);
}
}
}
如注释所述,初始化其实就是调用用户自定义的init-method方法和afterPropertiesSet方法!
(6)第五阶段:管理生命周期、发布刷新事件
这是最后一个阶段,应该说是容器启动过程,或者容器实例化过程中的最后一个阶段,因为完整的过程中最后应该是要执行bean的销毁。
这个阶段主要就是给上下文设置生命周期处理器,以管理这个上下文中bean的生命周期,如果工厂中有,就直接赋值,工厂中没有,就new一个再赋值,核心代码如下,AbstractApplicationContext#initLifecycleProcessor方法:
/**
* Initialize the LifecycleProcessor.
* Uses DefaultLifecycleProcessor if none defined in the context.
*
* @see org.springframework.context.support.DefaultLifecycleProcessor
*/
protected void initLifecycleProcessor() {
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (beanFactory.containsLocalBean(LIFECYCLE_PROCESSOR_BEAN_NAME)) {
this.lifecycleProcessor =
beanFactory.getBean(LIFECYCLE_PROCESSOR_BEAN_NAME, LifecycleProcessor.class);
if (logger.isTraceEnabled()) {
logger.trace("Using LifecycleProcessor [" + this.lifecycleProcessor + "]");
}
} else {
DefaultLifecycleProcessor defaultProcessor = new DefaultLifecycleProcessor();
defaultProcessor.setBeanFactory(beanFactory);
this.lifecycleProcessor = defaultProcessor;
beanFactory.registerSingleton(LIFECYCLE_PROCESSOR_BEAN_NAME, this.lifecycleProcessor);
if (logger.isTraceEnabled()) {
logger.trace("No '" + LIFECYCLE_PROCESSOR_BEAN_NAME + "' bean, using " +
"[" + this.lifecycleProcessor.getClass().getSimpleName() + "]");
}
}
}
然后把上下文刷新事件通过第三阶段注册的广播器进行广播,在广播方法中,实际调用的是监听器的方法,核心代码如下:
protected void publishEvent(Object event, @Nullable ResolvableType eventType) {
Assert.notNull(event, "Event must not be null");
// Decorate event as an ApplicationEvent if necessary
ApplicationEvent applicationEvent;
if (event instanceof ApplicationEvent) {
applicationEvent = (ApplicationEvent) event;
} else {
applicationEvent = new PayloadApplicationEvent<>(this, event);
if (eventType == null) {
eventType = ((PayloadApplicationEvent<?>) applicationEvent).getResolvableType();
}
}
// Multicast right now if possible - or lazily once the multicaster is initialized
if (this.earlyApplicationEvents != null) {
this.earlyApplicationEvents.add(applicationEvent);
} else {
getApplicationEventMulticaster().multicastEvent(applicationEvent, eventType);
}
// Publish event via parent context as well...
if (this.parent != null) {
if (this.parent instanceof AbstractApplicationContext) {
((AbstractApplicationContext) this.parent).publishEvent(event, eventType);
} else {
this.parent.publishEvent(event);
}
}
}
getApplicationEventMulticaster().multicastEvent(applicationEvent, eventType); 获取广播器并广播事件接口会传事件和事件类型:
public void multicastEvent(final ApplicationEvent event, @Nullable ResolvableType eventType) {
//第一步:调用resolveDefaultEventType方法解析事件的类型,会返回类的全限定名
ResolvableType type = (eventType != null ? eventType : resolveDefaultEventType(event));
Executor executor = getTaskExecutor();
//根据事件和事件类型获取监听器
for (ApplicationListener<?> listener : getApplicationListeners(event, type)) {
if (executor != null) {
//异步执行监听任务
executor.execute(() -> invokeListener(listener, event));
}
else if (this.applicationStartup != null) {
StartupStep invocationStep = this.applicationStartup.start("spring.event.invoke-listener");
invokeListener(listener, event);
invocationStep.tag("event", event::toString);
if (eventType != null) {
invocationStep.tag("eventType", eventType::toString);
}
invocationStep.tag("listener", listener::toString);
invocationStep.end();
}
else {
//将事件event通知给监听器listener
invokeListener(listener, event);
}
}
}
(五)spring源码的debug过程
带着下面的问题去实现debug
(1)图解spring IOC容器的核心实现原理
(2)spring的扩展实现一:BeanFactoryPostProcessor接口详解
(3)spring的扩展实现二:BeanPostProcessor接口详解
(4)必知必会的13个Bean生命周期处理机制
(5)spring bean实现Aware接口的意义
(6)BeanFactory和FactoryBean的接口对比
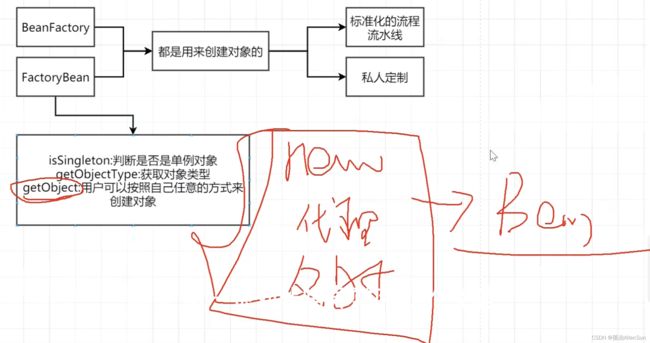
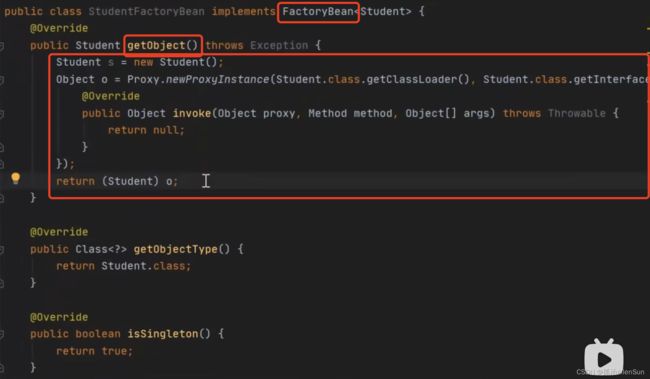 (7)对spring的理解
(7)对spring的理解
spring是个轻量级框架,简化我们的开发,重点包含两个模块,一个是IOC,一个AOP。IOC是控制反转,以前必须去new,使用IOC之后由容器帮我们创建和管理对象。AOP是面向切面编程,可以嵌入一些跟业务无关的核心代码,例如日志权限的增加。
spring的本质是一个容器,IOC容器是如何实现帮我们创建和管理对象的,涉及到bean的生命周期问题,在生命周期的源码中有哪些具体的代码扩展点,在扩展点中引出AOP的原理和功能,
【1】首先是测试方法的入口【ApplicationContext】
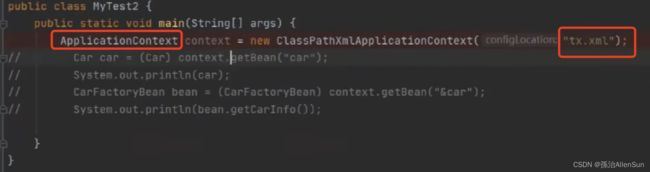
【2】读取xml配置文件
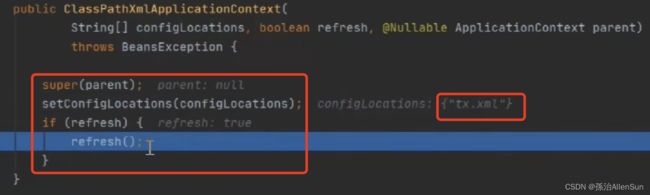
通过setConfigLocations方法指定xml文件
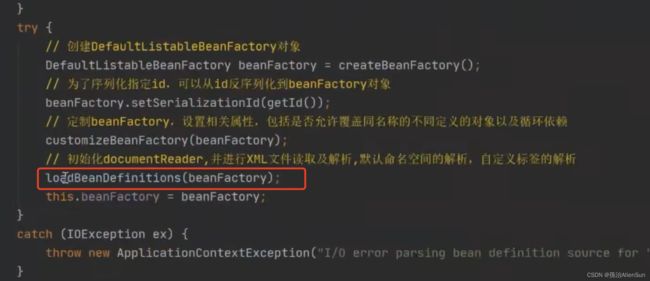
读取xml配置文件的过程如下

找到加载xml配置文件的方法
 在最终实现的地方,先把xml文件通过IO流转成resource文件,
在最终实现的地方,先把xml文件通过IO流转成resource文件,
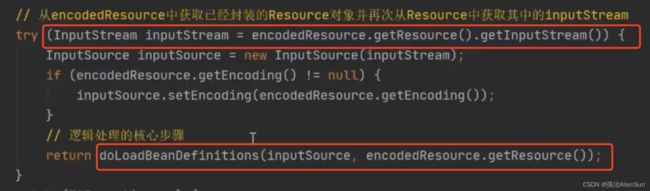
然后点进去开始对resource进行处理,把resource转成document,再把document转成node父子节点

点进来,先获得子节点然后遍历子节点,判断是以默认元素进行解析还是以用户自定义元素进行解析
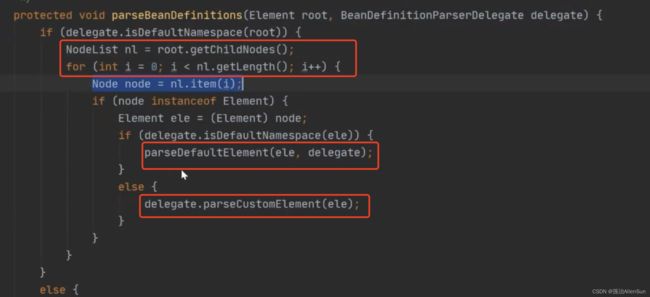
【3】构造器中调用【refresh】方法
在ApplicationContext构造方法里调用到refresh方法。先调用父类构造方法,然后设置配置文件的路径,最后判断调用refresh方法,也就是进入了重点的13个方法
【4】为创建bean工厂做准备工作【prepareRefresh】
接下来的第一步应该是创建bean工厂,有了BeanFactory才能有地方存放bean对象,进入【prepareRefresh】方法。这个方法里准备好一系列的准备工作,但是实际什么都没有执行。
protected void prepareRefresh() {
// Switch to active.
//设置启动时间
this.startupDate = System.currentTimeMillis();
//设置容器关闭为false
this.closed.set(false);
//设置容器活跃为true
this.active.set(true);
if (logger.isInfoEnabled()) {
logger.info("Refreshing " + this);
}
// Initialize any placeholder property sources in the context environment.
//初始化一些属性资源,方法主体是空的,交给子类去实现
initPropertySources();
// Validate that all properties marked as required are resolvable:
// see ConfigurablePropertyResolver#setRequiredProperties
//获取环境对象,并且验证属性值
getEnvironment().validateRequiredProperties();
// Store pre-refresh ApplicationListeners...
//创建一些集合
if (this.earlyApplicationListeners == null) {
this.earlyApplicationListeners = new LinkedHashSet<>(this.applicationListeners);
}
else {
// Reset local application listeners to pre-refresh state.
this.applicationListeners.clear();
this.applicationListeners.addAll(this.earlyApplicationListeners);
}
// Allow for the collection of early ApplicationEvents,
// to be published once the multicaster is available...
this.earlyApplicationEvents = new LinkedHashSet<>();
}
【5】开始创建bean工厂和bean对象加载【obtainFreshBeanFactory】
上面准备工作做完后开始创建bean工厂,进入【obtainFreshBeanFactory】方法,进入【refreshBeanFactory】方法,首先判断是否已存在bean工厂,如果已存在就销毁,并且重新调用【createBeanFactory】方法创建bean工厂
 创建的bean工厂实际的名字就是DefaultListableBeanFactory
创建的bean工厂实际的名字就是DefaultListableBeanFactory

创建完成bean工厂后开始设置属性值

完成属性值设置后,可以先看一下工厂里是否有bean对象,此时存储的量都是0,所以此时是没有bean对象的
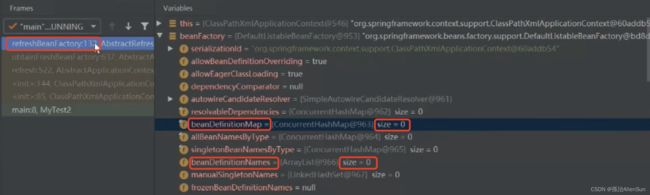
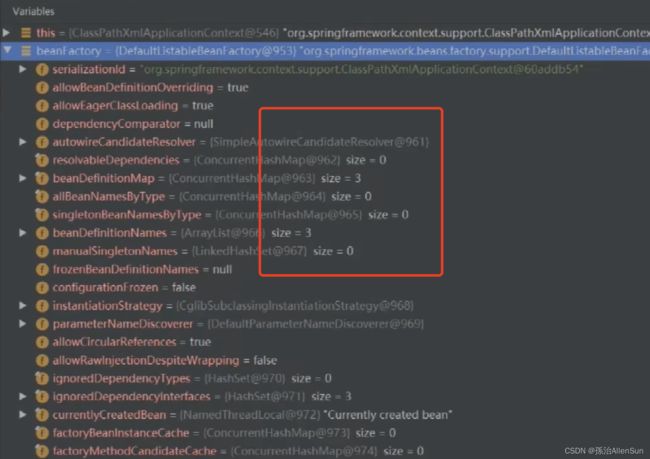
在完成属性值的设置接下来开始读取xml/注解等配置文件来装载BeanDefinition,完成加载后再看就发现已经加载了bean对象了
【6】bean工厂里众多属性值需要赋值【prepareBeanFactory】
方法内部有众多的set方法,可以给bean工厂设置一些属性值
【7】通过增强器对bean进行处理【postProcessBeanFactory】
这个方法点进去是空的,交给具体的接口实现类来实现,真正使用的时候可以通过实现接口来增强处理
 在BeanFactory接口里是没有getBeanDefinition方法来获取BeanDefinition对象的,但是BeanFactory又很多实现类和子接口,而在子类ConfirurableListableBeanFactory中有getBeanDefinition方法可以获取BeanDefinition对象。所以在上面方法中可以用这个类的对象beanFactory来调用方法获取BeanDefinition对象,并且对对象进行修改增强,然后返回BeanDefinition对象。
在BeanFactory接口里是没有getBeanDefinition方法来获取BeanDefinition对象的,但是BeanFactory又很多实现类和子接口,而在子类ConfirurableListableBeanFactory中有getBeanDefinition方法可以获取BeanDefinition对象。所以在上面方法中可以用这个类的对象beanFactory来调用方法获取BeanDefinition对象,并且对对象进行修改增强,然后返回BeanDefinition对象。
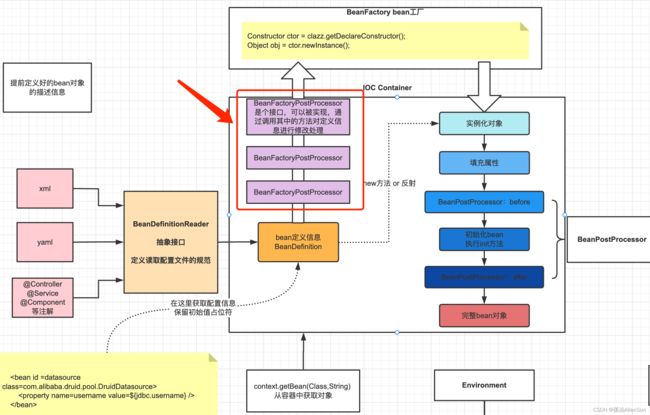
【8】实例化并调用BeanFactoryPostProcessor方法【invokeBeanFactoryPostProcessors】
上面那一步只是准备方法,实际调用增强器BeanFactoryPostProcessor是在这一步
有一点值得注意的是,在前面读取xml配置文件的时候并且注入BeanDefinition对象的时候,文件里的值都是直接装进去的,并没有对原始值做任何的修改,包括配置文件中的一些变量占位符
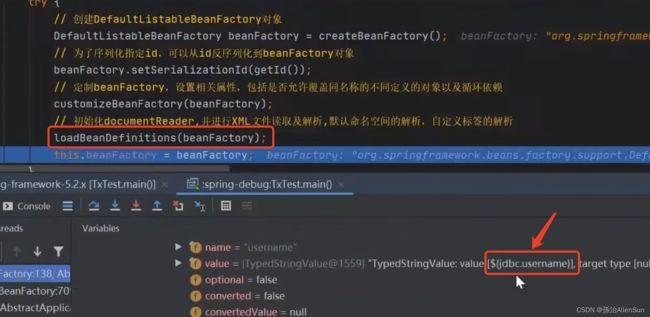 当执行到invokeBeanFactoryPostProcessors这一步的时候,这些占位符还没有被替换
当执行到invokeBeanFactoryPostProcessors这一步的时候,这些占位符还没有被替换
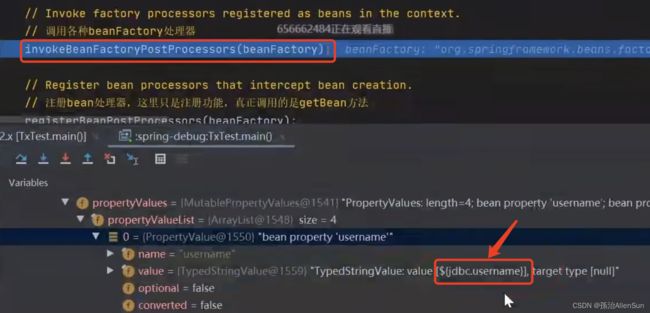 当这一步执行完毕后,这些占位符就已经完成了替换,这就是通过调用增强器BeanFactoryPostProcessor来实现的
当这一步执行完毕后,这些占位符就已经完成了替换,这就是通过调用增强器BeanFactoryPostProcessor来实现的
 上面的实现是spring框架中自带的BeanFactoryPostProcessor实现类完成的,如果我们想对BeanDefinition对象进行一些其他的修改,也可以通过自己实现BeanFactoryPostProcessor接口,然后调用对应的方法来实现修改。
上面的实现是spring框架中自带的BeanFactoryPostProcessor实现类完成的,如果我们想对BeanDefinition对象进行一些其他的修改,也可以通过自己实现BeanFactoryPostProcessor接口,然后调用对应的方法来实现修改。
【9】实例化并注册BeanPostProcessor【registerBeanFactoryProcessors】
在这里只是先进行实例化和注册,但是此时并不会实际的使用,只是为后面调用BeanPostProcessor做好准备,因为后面需要用到观察者模式等等,这些都要在开始实例化bean对象之前都做好准备
【10】做国际化处理【initmessageSource】(过)
【11】初始化应用事件多播器,方便后面的发布监听事件
【12】onFresh方法
空的,一些Tomcat和severlet的扩展功能就是在这里实现
【13】创建监听器,方便后面使用【registerListener】
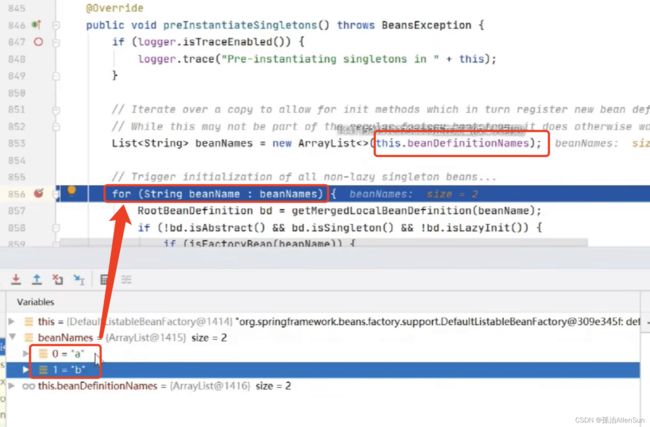
【14】【bean生命周期】开始实例化剩下的非懒加载单例bean对象【finishBeanFactoryInitialization】
从这里开始其实就是开始了bean的生命周期
(1)把所有的beanName放进List,然后开始遍历完成实例化bean对象
(2)开始实例化bean对象
首先判断是不是抽象的,是不是单例的,是不是懒加载的(true)
然后判断工厂里是不是有这个对象(false)
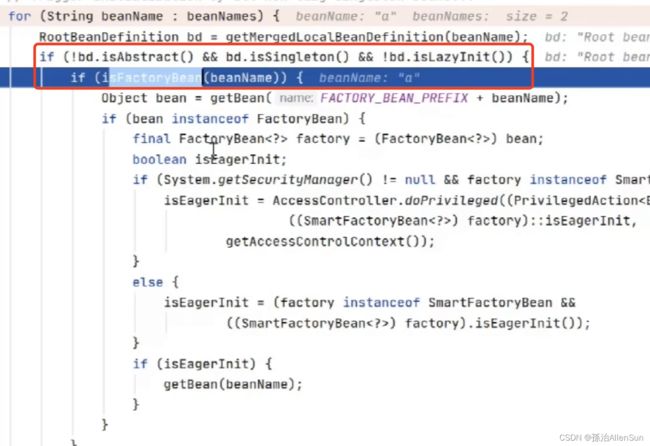
因为这个false,所以走判断的另一个分支,会调用到getBean方法,接着走到doGetBean方法
 首先是调用getSingleton方法尝试从工厂里获取bean对象,结果为null,走判断的另一个分支
首先是调用getSingleton方法尝试从工厂里获取bean对象,结果为null,走判断的另一个分支
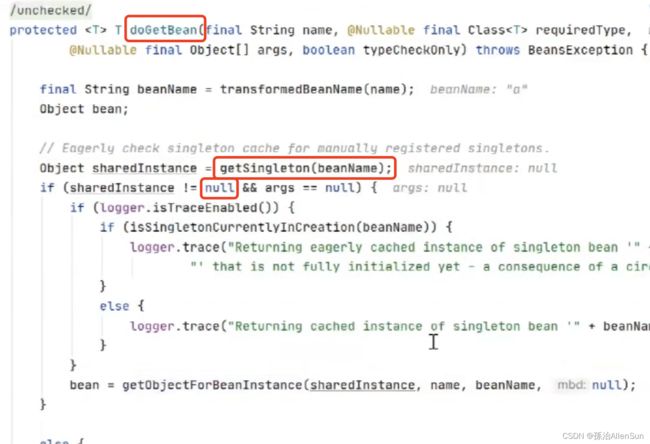
然后就是走循环依赖的那一个步骤,判断有没有依赖属性,然后从三级缓存里尝试获取bean对象。如果都没有找到,那就走到createBean方法来创建这个bean对象。在createBean方法里找到实际干活的doCreateBean方法,然后走到createBeanInstance方法,走到最后可以看到实例化的核心也就是通过反射来实例化对象
确认一下bean对象是否完成实例化,此时已经有了对象A
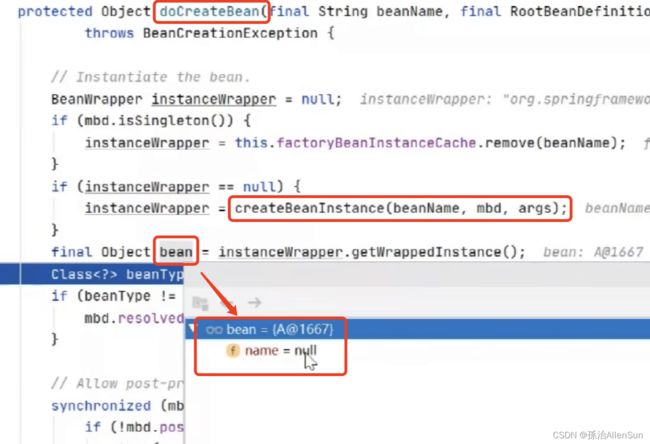
(3)开始填充属性(用户自定义属性赋值)
走到populateBean方法,这里进行属性填充。在方法之前name属性是空的
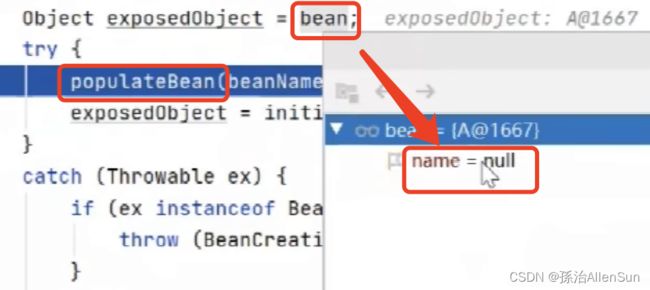
执行完populateBean方法后,name属性是有值的了,完成了属性填充

(4)开始调用Aware接口(容器对象赋值)
在完成对象的属性设置之后,需要调用一些类如setBeanFactory和setApplicationContext的方法,这些方法肯定不是我们自己调用,而是交给容器去调用,但是在启动的时候容器是不知道调用哪个set方法的,所以这里就可以定义统一的规范接口来实现这个功能
Aware接口是空的
但是Aware接口有很多实现子类


通过实现这些接口,就可以调用统一的方法来实现给容器的对象赋值
(5)开始初始化前置处理【BeanpostProcessor:before】
先是调用Aware接口
然后调用BeanpostProcessor:before方法
 在这个方法里对之前已经注册的BeanPostProcessor进行遍历放进一个集合,然后调用实际的before方法
在这个方法里对之前已经注册的BeanPostProcessor进行遍历放进一个集合,然后调用实际的before方法
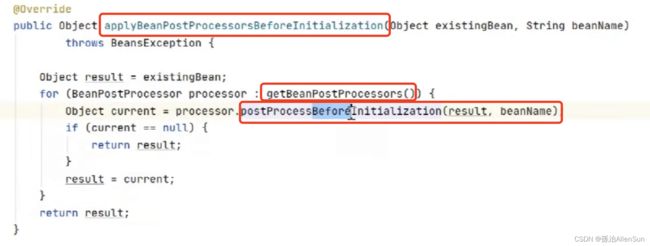
调用实际的before方法,这个方法里其实没有任何实现

(6)开始执行初始化调用init方法
找到invokeInitMethods
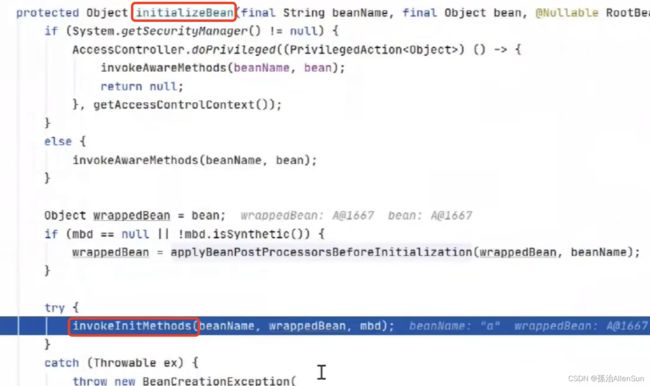
进入invokeInitMethods方法,首先判断是否实现了InitializingBean接口,如果实现了的话就调用afterPropertiesSet方法,这个方法是对象完成初始化之前最后一个入口可以修改对象的属性值

(7)开始初始化后置处理【BeanpostProcessor:after】
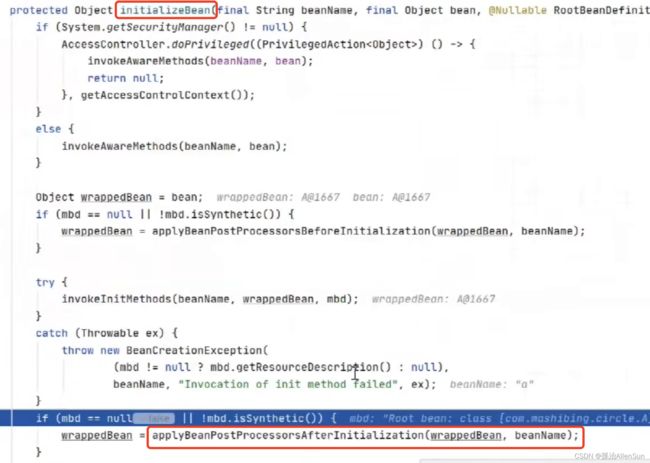 接着调用实际的after方法,在方法中首先获取bean的key,然后判断当前的bean是否正在被代理,如果没有被代理且需要被代理,那么就封装指定的bean
接着调用实际的after方法,在方法中首先获取bean的key,然后判断当前的bean是否正在被代理,如果没有被代理且需要被代理,那么就封装指定的bean
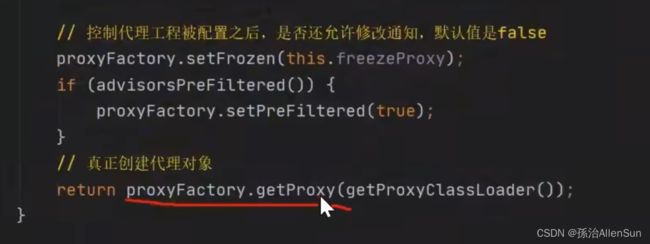
 点进去找到createProxy方法来创建代理
点进去找到createProxy方法来创建代理
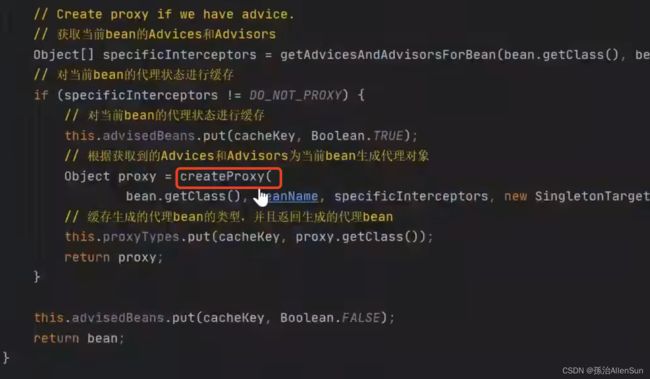
点进去看到工厂模式创建代理对象,通过代理工厂创建代理对象
 点进去看到
点进去看到
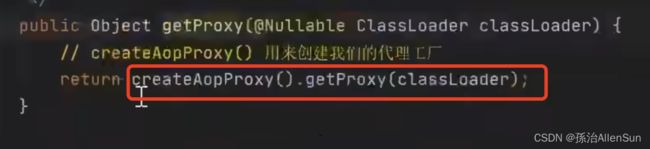 查找getProxy方法的具体实现,就看到了两种代理方式的方法Jdk和Cglib
查找getProxy方法的具体实现,就看到了两种代理方式的方法Jdk和Cglib

到这里也就是通过代理对象实现了AOP功能,所以说AOP功能就是IOC功能的一个扩展实现,是在增强器中实现的。
执行完成后返回这个对象,结束这一次的循环,接着遍历下一个beanName
(六)bean生命周期概述
(1)实例化bean对象
通过反射的方式进行对象的创建,此时的创建只是在堆空间中申请空间,属性都是默认值
(2)设置对象属性
给对象中的属性进行值的设置工作
(3)检查Aware相关接口并设置相关依赖
如果对象中需要引用容器内部的对象,那么需要调用Aware接口的子类方法来进行统一的设置
(4)BeanPostProcessor的前置处理
对生成的bean对象进行前置的处理工作
(5)检查是否是initializingBean的子类来决定是否调用afterPropertiesSet方法
判断当前bean对象是否设置了initializingBean接口,然后进行属性的设置等基本工作
(6)检查是否配置有自定义的init-method方法
如果当前bean对象定义了初始化方法,那么在此处调用初始化方法
(7)BeanPostProcessor后置处理
对生成的bean对象进行后置的处理工作
(8)注册必要的Destruction相关回调接口
为了方便对象的销毁,在此处调用注销的回调接口,方便对象进行销毁操作
(七)循环依赖问题详解
【1】什么是循环依赖?
(1)产生循环依赖的流程图
有两个类A和B,A中调用了对象b,B中调用了对象a,在创建A需要b的时候会去创建B,而在创建B的时候又需要a,此时类A还没有创建完成,这样就形成了类A和类B之间依赖关系的闭环。
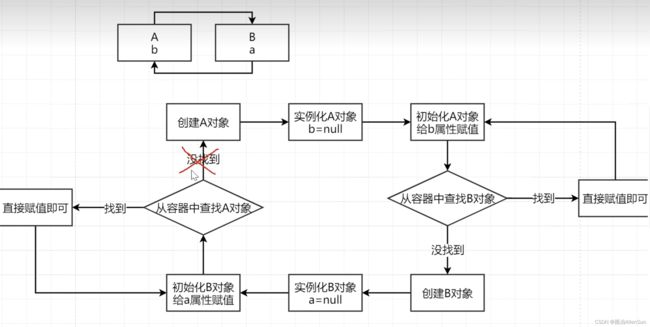 如果想破开这个闭环,突破口就是最后一步的“没有找到A对象”。其实最后一步在容器中查找A对象的时候,此时对象A已经存在,这个要认识两种概念,“对象完成实例化且完成初始化”的称为“成品对象”,而“对象完成实例化但未完成初始化”的称为“半成品对象”,“实例化”和“初始化”不是同时进行的。
如果想破开这个闭环,突破口就是最后一步的“没有找到A对象”。其实最后一步在容器中查找A对象的时候,此时对象A已经存在,这个要认识两种概念,“对象完成实例化且完成初始化”的称为“成品对象”,而“对象完成实例化但未完成初始化”的称为“半成品对象”,“实例化”和“初始化”不是同时进行的。
(2)源码中产生循环依赖的流程
 (3)循环依赖问题的类型
(3)循环依赖问题的类型
循环依赖问题在spring中主要有三种情况
1-通过构造方法进行依赖注入时产生的循环依赖问题。
2-通过setter方法进行依赖注入且是在多例(原型)模式下产生的循环依赖问题。
3-通过setter方法进行依赖注入且是在单例模式下产生的循环依赖问题。
在Spring中,只有第(3)种方式的循环依赖问题被解决了,其他两种方式在遇到循环依赖问题时都会产生异常。其实也很好解释:
1-第(1)种构造方法注入的情况下,在new对象的时候就会堵塞住了,其实也就是”先有鸡还是先有蛋“的历史难题。
2-第(2)种setter方法(多例)的情况下,每一次getBean()时,都会产生一个新的Bean,如此反复下去就会有无穷无尽的Bean产生了,最终就会导致OOM问题的出现。
【2】spring中解决循环依赖的思路
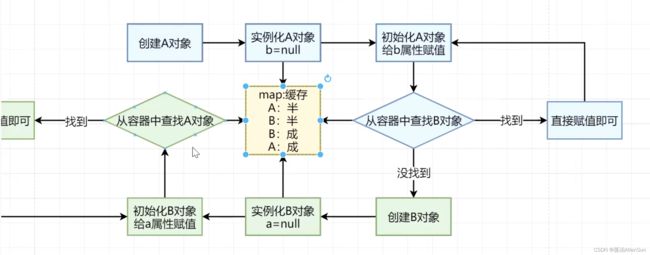
(1)解决循环依赖问题的流程图
1-设置map缓存,用来存放对象,在完成实例化对象A的时候,将半成品对象A放进缓存
2-在实例化对象B的时候,将半成品对象B放进缓存
3-在容器中查找A对象的时候,能找到半成品的对象A,然后完成对象B的初始化工作,得到成品对象B,并且将成品对象B放进缓存
4-回到初始化A对象过程中从容器中查找B对象的那一步,此时就可以查找到一个成品对象B,接着就可以完成对象A的初始化工作了
以上,即可解决对象的循环依赖问题。
【3】三级缓存介绍
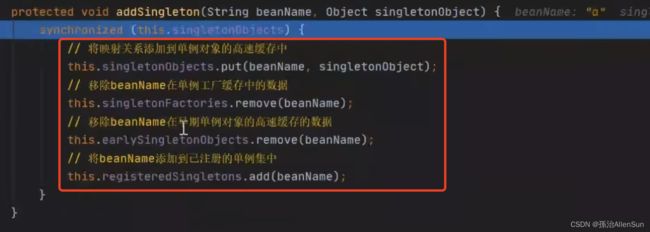
(1)三级缓存的代码
DefaultSingletonBeanRegistry类
/**
* 一级缓存
* Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/**
* 三级缓存
* 用来保存BeanName和创建bean的工厂之间的关系
* Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/**
* 二级缓存
* 保存BeanName和创建bean实例之间的关系,与singletonFactories的不同之处在于,当一个单例bean被放到这里之后,那么当bean还在创建过程中
* 就可以通过getBean方法获取到,可以方便进行循环依赖的检测
* Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
三级缓存的不同点
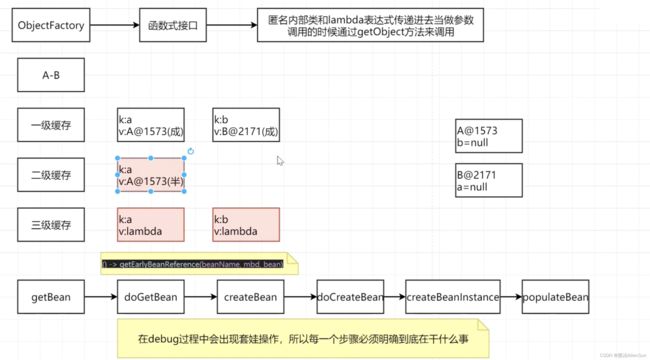
一级缓存和二级缓存的返回结果中Map的参数都是Object,而三级缓存的是ObjectFactory。ObjectFactory也就是“函数式接口”,作用就是“可以把匿名内部类和lambda表达式传递进去当做参数,调用的时候通过getObject方法来调用”
(2)三级缓存的各个功能
一级缓存:存的都是已经创建好的单例对象
二级缓存:存的只有一个引用,只有一个地址,里面的属性都是空的
三级缓存:存放的是一个工厂,二级缓存里的EarlySingletonObjects就需要通过这个工厂来创建。如果需要的只是一个普通的没有AOP的bean,那么可以直接创建EarlySingletonObjects。但是如果需要的是一个有AOP的bean,需要代理,就需要工厂去把代理生成出来。

(3)spring三大缓存介绍
spring汇总有三个缓存,用于存储单例的bean实例,这三个缓存是彼此互斥的,不会针对同一个Bean的实例同时存储。如果调用getBean,则需要从三个缓存中依次获取指定的Bean实例。读取顺序依次是一级缓存 --> 二级缓存 --> 三级缓存。
(1)一级缓存:Map
1、第一级缓存的作用:
- 用于存储单例模式下创建的Bean实例(已经创建完毕)。
- 该缓存是对外使用的,指的就是使用Spring框架的程序员。
2、存储什么数据?
- K:bean的名称
- V:bean的实例对象(有代理对象则指的是代理对象,已经创建完毕)
(2)第二级缓存:Map
第二级缓存的作用:
- 用于存储单例模式下创建的Bean实例(该Bean被提前暴露的引用,该Bean还在创建中,完成了实例化,但是属性都是空的)。
- 该缓存是对内使用的,指的就是Spring框架内部逻辑使用该缓存。
- 为了解决第一个classA引用最终如何替换为代理对象的问题(如果有代理对象)
(3)第三级缓存:Map
1、第三级缓存的作用:
- 通过ObjectFactory对象来存储单例模式下提前暴露的Bean实例的引用(提前暴露的一个单例工厂,二级缓存中存储的就是从这个工厂中获取到的对象)。
- 该缓存是对内使用的,指的就是Spring框架内部逻辑使用该缓存。
- 此缓存是解决循环依赖最大的功臣
2、存储什么数据?
- K:bean的名称
- V:ObjectFactory,该对象持有提前暴露的bean的引用
【4】三级缓存的debug流程详解
(1)源码中留意的6个重要方法
(1)getBean
(2)doGetBean
(3)createBean
(4)doCreateBean
(5)createBeanIntance
(6)populateBean
(2)debug流程
1-在refresh方法中涉及到的位置
当执行到这一步的时候,第一至第三缓存中都是没有东西的,开始!
2-进入DefaultListableBeanFactory类的preInstantiateSingletons方法
@Override
public void preInstantiateSingletons() throws BeansException {
if (logger.isDebugEnabled()) {
logger.debug("Pre-instantiating singletons in " + this);
}
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
//把所有BeanDefinition的名字创建一个集合,根据这里的name值可以获取对应的Definition信息
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// Trigger initialization of all non-lazy singleton beans...
//遍历bean对象的名称,触发所有非延迟加载单例bean的初始化,遍历集合的对象
for (String beanName : beanNames) {
//先获取BeanDefinition,也就是bean的描述信息,合并父类BeanDefinition
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
//判断bean是不是 非抽象的&单例的&非懒加载的
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
//判断是否实现了FactoryBean接口
if (isFactoryBean(beanName)) {
//根据&+beanName来获取具体的对象
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
//进行类型转换
if (bean instanceof FactoryBean) {
FactoryBean<?> factory = (FactoryBean<?>) bean;
//判断这个FactoryBean是否希望立即初始化
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(
(PrivilegedAction<Boolean>) ((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
//如果希望急切的初始化,则通过beanName获取bean实例
if (isEagerInit) {
getBean(beanName);
}
}
}
else {
//获取bean,如果beanName对应的bean不是FactoryBean,只是普通的bean,通过beanName获取bean实例
getBean(beanName);
}
}
}
// Trigger post-initialization callback for all applicable beans...
//遍历beanNames,触发所有SmartInitializingSingleton的后初始化回调
for (String beanName : beanNames) {
//获取beanName对应的bean实例
Object singletonInstance = getSingleton(beanName);
//判断singletonInstance是否实现了SmartInitializingSingleton接口
if (singletonInstance instanceof SmartInitializingSingleton) {
//类型转换
SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
//触发SmartInitializingSingleton实现类的afterSingletonsInstantiated方法
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
}
}
}
在这里可以看到有将要创建的两个对象a和b
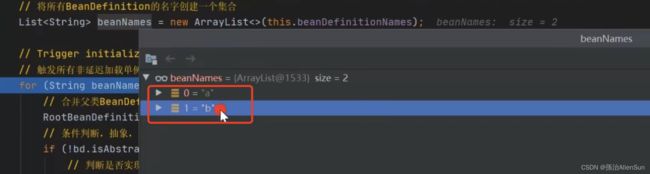 在创建对象的时候,先到容器中根据beanName查一下是不是已经创建这么个bean对象了,调用getBean(beanName)方法来获取,接着调用doGetBean方法,在判断bean的单例对象是否存在的时候,此刻返回的bean对象应该是空的
在创建对象的时候,先到容器中根据beanName查一下是不是已经创建这么个bean对象了,调用getBean(beanName)方法来获取,接着调用doGetBean方法,在判断bean的单例对象是否存在的时候,此刻返回的bean对象应该是空的
 既然是空的就会往下走去创建对象,跳过一系列的判断条件,走到下面这个getSingleton方法,这里方法的参数有一个lambda表达式,表达式中有一个方法createBean用来创建bean对象,实际上它并不会实际被调用,只是当做参数先被传递
既然是空的就会往下走去创建对象,跳过一系列的判断条件,走到下面这个getSingleton方法,这里方法的参数有一个lambda表达式,表达式中有一个方法createBean用来创建bean对象,实际上它并不会实际被调用,只是当做参数先被传递
走到都doCreateBean方法
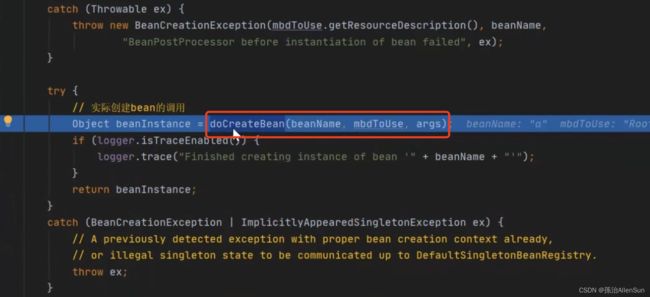
走到createBeanInstance方法,进行具体的实例化操作
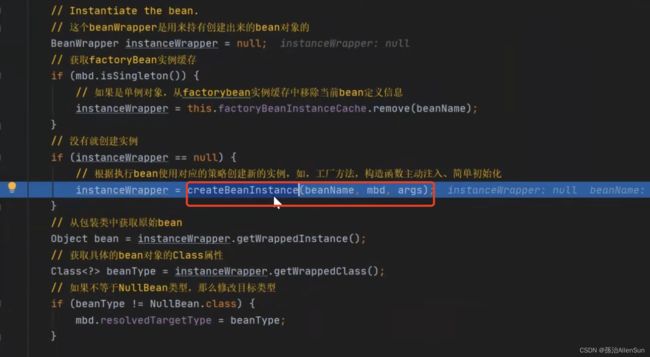
往下走,通过反射获取构造器,然后创建具体的对象
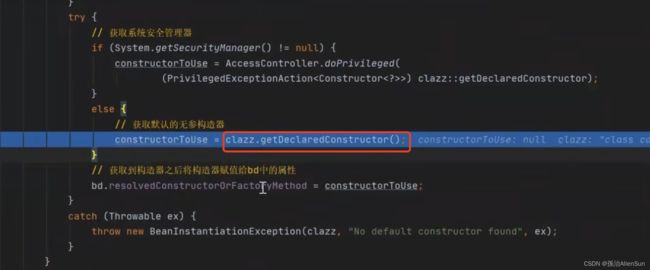 在这里完成通过反射获取对象
在这里完成通过反射获取对象
 此时对象A已经有了
此时对象A已经有了
 在A完成实例化之前,创建代理对象放进三级缓存,传递的又是一个lambda表达式
在A完成实例化之前,创建代理对象放进三级缓存,传递的又是一个lambda表达式
 详细看这个方法时如何实现把对象放入三级缓存的,这里是把参数传进来的lambda表达式当做value,把beanName当做key放进三级缓存的map中去
详细看这个方法时如何实现把对象放入三级缓存的,这里是把参数传进来的lambda表达式当做value,把beanName当做key放进三级缓存的map中去
 此时对象A已经完成了实例化,接下来开始属性填充,就会开始给B对象属性进行赋值
此时对象A已经完成了实例化,接下来开始属性填充,就会开始给B对象属性进行赋值
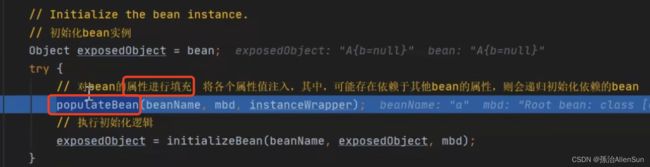 接下来进入属性赋值的最终方法
接下来进入属性赋值的最终方法
 在赋值的过程中遍历属性,获取属性的名字(也就是对象b)和值(记住这个值)
在赋值的过程中遍历属性,获取属性的名字(也就是对象b)和值(记住这个值)
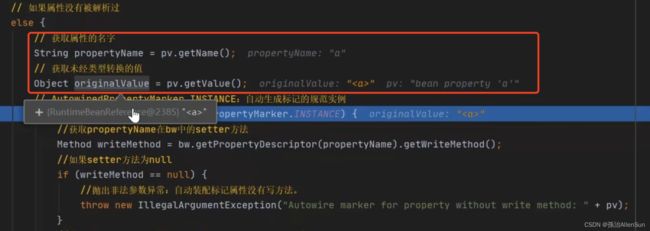
 上面获取的value值不是b类型对象,在必须的情况下要对这个值进行一个处理工作
上面获取的value值不是b类型对象,在必须的情况下要对这个值进行一个处理工作
 进入处理方法后,判断value是否匹配,就跟前面的RuntimeBeanReference对应起来了,就可以进入判断内部。对value值进行强转和解析,得到封装的Bean对象,也就是b对象
进入处理方法后,判断value是否匹配,就跟前面的RuntimeBeanReference对应起来了,就可以进入判断内部。对value值进行强转和解析,得到封装的Bean对象,也就是b对象
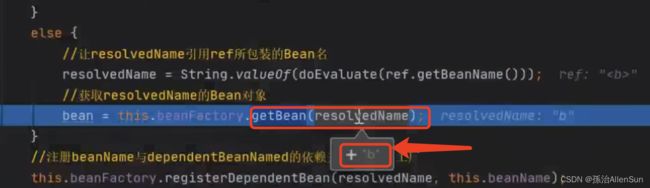
 进入解析的具体方法,就会接触到实际获取b对象的方法,实际就是getBean方法,开始套娃,循环上述流程开始创建b对象。getBean方法先去容器里判断是不是有已经创建好的b对象,然后再决定要不要开始创建。
进入解析的具体方法,就会接触到实际获取b对象的方法,实际就是getBean方法,开始套娃,循环上述流程开始创建b对象。getBean方法先去容器里判断是不是有已经创建好的b对象,然后再决定要不要开始创建。
接下来的步骤跟刚才创建对象a的步骤一模一样,省略其中的步骤,到对象b实例化最后一步的时候,要把对象b的代理对象放进三级缓存
 接下来完成实例化后也要开始b对象的属性填充了,就会碰到属性a对象的填充了,依旧是解析对象a
接下来完成实例化后也要开始b对象的属性填充了,就会碰到属性a对象的填充了,依旧是解析对象a
 往下走又遇到getBean方法,这次要获取的是对象a
往下走又遇到getBean方法,这次要获取的是对象a
 走doGetBean方法进入getSingleton方法尝试去获取对象a
走doGetBean方法进入getSingleton方法尝试去获取对象a
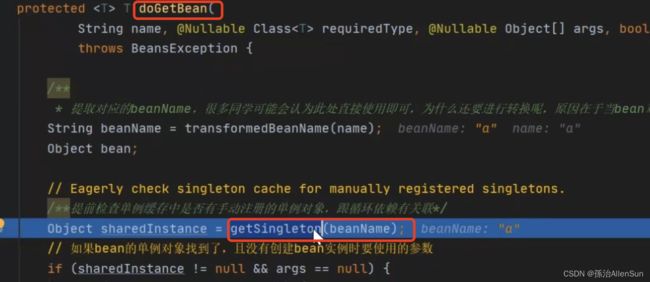 下面就是获取a对象方法的实际主体,在这里会依次到一级缓存、二级缓存、三级缓存中去尝试获取对象a,如果是在三级缓存缓存中找到的对象a的对象工厂(lambda表达式),就要通过getObject方法调用前面传的lambda表达式来创建一个单例对象a
下面就是获取a对象方法的实际主体,在这里会依次到一级缓存、二级缓存、三级缓存中去尝试获取对象a,如果是在三级缓存缓存中找到的对象a的对象工厂(lambda表达式),就要通过getObject方法调用前面传的lambda表达式来创建一个单例对象a
getObject方法跳转进去的就是对应的lambda表达式

进入这个lambda表达式,提前暴露对象,设置代理对象,判断是否有AOP需要处理,返回最终的代理对象
通过getObject方法调用对象工厂的lambda表达式返回一个单例对象a之后,把这个新的单例对象a存入二级缓存,最后把三级缓存中的对象工厂a给删除
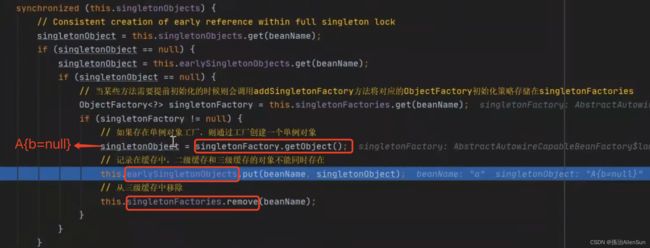 取到a对象了,刚才取a对象的目的就是因为要给b对象进行属性填充,所以有了a对象后就可以完成给b对象的属性填充了,此时b对象中的a是有值的,b也就是成品对象了,把成品对象b放进一级缓存里,并且从三级缓存里删除b的对象工厂。但是此时a对象中的b还是null,a对象还是半成品对象。
取到a对象了,刚才取a对象的目的就是因为要给b对象进行属性填充,所以有了a对象后就可以完成给b对象的属性填充了,此时b对象中的a是有值的,b也就是成品对象了,把成品对象b放进一级缓存里,并且从三级缓存里删除b的对象工厂。但是此时a对象中的b还是null,a对象还是半成品对象。
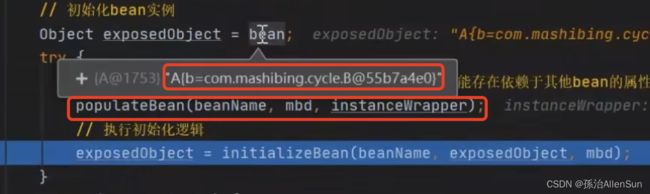
 回到刚才创建b对象的那一步,创建b对象的目的就是为了给a对象进行属性填充,现在有了成品对象b且已经放进了一级缓存,这个时候就可以继续用对象b给对象a进行属性填充了。这个时候a也是成品对象了,其中的b对象不再是null
回到刚才创建b对象的那一步,创建b对象的目的就是为了给a对象进行属性填充,现在有了成品对象b且已经放进了一级缓存,这个时候就可以继续用对象b给对象a进行属性填充了。这个时候a也是成品对象了,其中的b对象不再是null
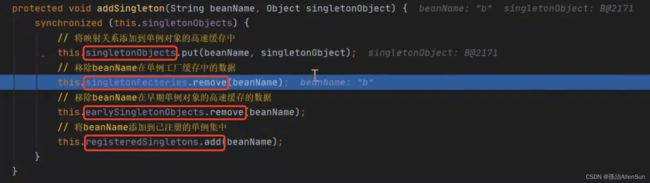
 最后a对象完成了属性填充,重复上面b对象的那一步,把对象a放进一级缓存,并且从三级缓存中删除a对象工厂,并且从二级缓存中删除a对象
最后a对象完成了属性填充,重复上面b对象的那一步,把对象a放进一级缓存,并且从三级缓存中删除a对象工厂,并且从二级缓存中删除a对象
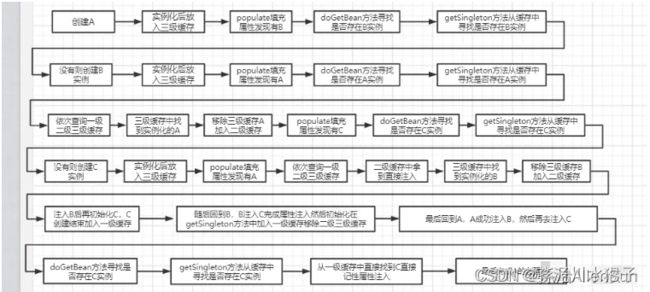
(3)三级缓存debug流程的总结
1-第一阶段
通过反射获取构造器并实例化对象a,把lambda表达式(对象工厂)当做value存进三级缓存的map中,完成对象a的实例化。
这里的lambda表达式就是把实际对象bean交给代理对象,然后判断是否有AOP,如果有就直接对代理对象进行修改,如果没有就不修改直接跳过,最终返回那个代理对象(也就是说如果没有AOP的话,只是进行了一个对象代理,其他什么也没做)
此时三级缓存里有【a对象工厂】
2-第二阶段
完成对象a的实例化后,接着开始对象a的属性填充,遍历属性并且通过解析判断发现依赖对象b,先从容器的三个缓存中依次查找对象b,没有找到,于是开始调用getBean方法创建对象b
3-第三阶段
通过反射获取构造器并实例化对象b,把lambda表达式(对象工厂)当做value存进三级缓存的map中,完成对象b的实例化。
此时三级缓存里有【a对象工厂】和【b对象工厂】
4-第四阶段
完成对象b的实例化后,接着开始对象b的属性填充,遍历属性并且通过解析判断发现依赖对象a,先从容器的三个缓存中依次查找对象a,在三级缓存里找到了对象a的对象工厂(lambda表达式),于是开始通过getObject方法调用前面传到value里的lambda表达式来创建一个单例对象a,完成对象a创建后把对象a放进二级缓存,并且删除三级缓存里的a对象工厂
此时三级缓存里有【b对象工厂】,二级缓存里有【半成品对象A{b=null}】
删除了三级缓存里的【a对象工厂】
5-第五阶段
取到半成品对象a后继续到对象b的属性填充,b对象完成属性填充和初始化,B{a=null}变成B{a=@***},把对象b放进一级缓存,并且删除二级缓存和三级缓存中的b对象
此时三级缓存里啥也没有了,二级缓存里有【半成品对象A{b=null}】,一级缓存里有【成品对象B{a=@***}】
删除了三级缓存里的【b对象工厂】
6-第六阶段
取到成品对象b后继续到对象a的属性填充,a对象完成属性填充和初始化,A{b=null}变成A{b=@***},把对象a放进一级缓存,并且删除二级缓存和三级缓存中的a对象
此时三级缓存里啥也没有了,二级缓存里啥也没有了,一级缓存里有【成品对象B{a=@***}】 和【成品对象A{b=@—}】
删除了二级缓存里的【半成品对象A{b=null}】
7-过程图
至此,一级缓存里有了对象a和对象b
【5】三级缓存的重要问题
(1)为什么第三级缓存要使用ObjectFactory?
如果仅仅是解决循环依赖问题,使用二级缓存就可以了,但是如果对象实现了AOP,那么注入到其他bean的时候,并不是最终的代理对象,而是原始的。这时就需要通过三级缓存的ObjectFactory才能提前产生最终的需要代理的对象。

(2)什么时候将Bean的引用提前暴露给第三级缓存的ObjectFactory持有?
时机就是在第一步实例化之后,第二步依赖注入之前,完成此操作。

(3)如果只有一级缓存
(1)实例化A对象。
(2)填充A的属性阶段时需要去填充B对象,而此时B对象还没有创建,所以这里为了完成A的填充就必须要先去创建B对象;
(3)实例化B对象。
(4)执行到B对象的填充属性阶段,又会需要去获取A对象,而此时Map中没有A,因为A还没有创建完成,导致又需要去创建A对象。
这样,就会循环往复,一直创建下去,只到堆栈溢出。
为什么不能在实例化A之后就放入Map?
因为此时A尚未创建完整,所有属性都是默认值,并不是一个完整的对象,在执行业务时可能会抛出未知的异常。所以必须要在A创建完成之后才能放入Map。
(4)如果只有二级缓存
此时我们引入二级缓存用另外一个Map2 {k:name; v:earlybean} 来存储尚未已经开始创建但是尚未完整创建的对象。
(1)实例化A对象之后,将A对象放入Map2中。
(2)在填充A的属性阶段需要去填充B对象,而此时B对象还没有创建,所以这里为了完成A的填充就必须要先去创建B对象。
(3)创建B对象的过程中,实例化B对象之后,将B对象放入Map2中。
(4)执行到B对象填充属性阶段,又会需要去获取A对象,而此时Map中没有A,因为A还没有创建完成,但是我们继续从Map2中拿到尚未创建完毕的A的引用赋值给a字段。这样B对象其实就已经创建完整了,尽管B.a对象是一个还未创建完成的对象。
(5)此时将B放入Map并且从Map2中删除。
(6)这时候B创建完成,A继续执行b的属性填充可以拿到B对象,这样A也完成了创建。
(7)此时将A对象放入Map并从Map2中删除。
(5)二级缓存已然解决了循环依赖问题,为什么还需要三级缓存?
三级缓存为什么要使用工厂而不是直接使用引用?换而言之,为什么需要这个三级缓存,直接通过二级缓存暴露一个引用不行吗?
这个工厂的目的在于延迟对实例化阶段生成的对象的代理,只有真正发生循环依赖的时候,才去提前生成代理对象,否则只会创建一个工厂并将其放入到三级缓存中,但是不会去通过这个工厂去真正创建对象
即使没有循环依赖,也会将其添加到三级缓存中,而且是不得不添加到三级缓存中,因为到目前为止Spring也不能确定这个Bean有没有跟别的Bean出现循环依赖。
**假设我们在这里直接使用二级缓存的话,那么意味着所有的Bean在这一步都要完成AOP代理。**这样做有必要吗?
不仅没有必要,而且违背了Spring在结合AOP跟Bean的生命周期的设计!Spring结合AOP跟Bean的生命周期本身就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。
(6)Spring是如何解决的循环依赖?
Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
【7】spring解决循环依赖的详细流程
(1)前期铺垫工作
(1)描述流程
1-什么是循环依赖?
2-什么情况下循环依赖可以被处理?
3-spring是如何解决的循环依赖?
(2)错误说法
1-只有在setter方式注入的情况下,循环依赖才能解决(错)
2-三级缓存的目的是为了提高效率(错)
(2)什么情况下循环依赖可以被处理?
(1)Spring解决循环依赖是有前置条件
1-出现循环依赖的Bean必须要是单例
2-依赖注入的方式不能全是构造器注入的方式(很多博客上说,只能解决setter方法的循环依赖,这是错误的)
A中注入B的方式是通过构造器,B中注入A的方式也是通过构造器,这个时候循环依赖是无法被解决,如果你的项目中有两个这样相互依赖的Bean,在启动时就会报出以下错误:
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?

(3)Spring是如何解决的循环依赖?
(1)简单的循环依赖(没有AOP)
(1)案例demo
@Component
public class A {
// A中注入了B
@Autowired
private B b;
}
@Component
public class B {
// B中也注入了A
@Autowired
private A a;
}
(2)Spring在创建Bean的时候默认是按照自然排序来进行创建的,所以第一步Spring会去创建A
Spring在创建Bean的过程中分为三步:
1-实例化,简单理解就是new了一个对象。对应方法:AbstractAutowireCapableBeanFactory中的createBeanInstance方法
2-属性注入,为实例化中new出来的对象填充属性。对应方法:AbstractAutowireCapableBeanFactory的populateBean方法
3-初始化,执行aware接口中的方法,初始化方法,完成AOP代理。对应方法:AbstractAutowireCapableBeanFactory的initializeBean
(3)循环依赖处理过程的关键方法步骤流程图

创建A的过程实际上就是调用getBean方法,这个方法有两层含义:
1-创建一个新的Bean
2-从缓存中获取到已经被创建的对象
此时步骤中的是第一层含义,因为这个时候缓存中还没有A。
【1】调用getSingleton(beanName)
首先调用getSingleton(a)方法,这个方法又会调用getSingleton(beanName, true),在上图中我省略了这一步
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
getSingleton(beanName, true)这个方法实际上就是到缓存中尝试去获取Bean,整个缓存分为三级:
- singletonObjects,一级缓存,存储的是所有创建好了的单例Bean
- earlySingletonObjects,完成实例化,但是还未进行属性注入及初始化的对象
- singletonFactories,提前暴露的一个单例工厂,二级缓存中存储的就是从这个工厂中获取到的对象
因为A是第一次被创建,所以不管哪个缓存中必然都是没有的,因此会进入getSingleton的另外一个重载方法getSingleton(beanName, singletonFactory)。
【2】调用getSingleton(beanName, singletonFactory)
这个方法就是用来创建Bean的,其源码如下:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// ....
// 省略异常处理及日志
// ....
// 在单例对象创建前先做一个标记
// 将beanName放入到singletonsCurrentlyInCreation这个集合中
// 标志着这个单例Bean正在创建
// 如果同一个单例Bean多次被创建,这里会抛出异常
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// 上游传入的lambda在这里会被执行,调用createBean方法创建一个Bean后返回
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// ...
// 省略catch异常处理
// ...
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// 创建完成后将对应的beanName从singletonsCurrentlyInCreation移除
afterSingletonCreation(beanName);
}
if (newSingleton) {
// 添加到一级缓存singletonObjects中
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
上面的代码我们主要抓住一点,通过createBean方法返回的Bean最终被放到了一级缓存,也就是单例池中。
那么到这里我们可以得出一个结论:一级缓存中存储的是已经完全创建好了的单例Bean
【3】调用addSingletonFactory方法
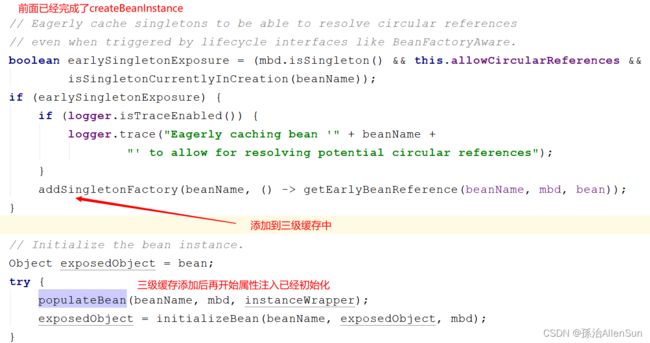
在完成Bean的实例化后,属性注入之前Spring将Bean包装成一个工厂添加进了三级缓存中,对应源码如下:
// 这里传入的参数也是一个lambda表达式,() -> getEarlyBeanReference(beanName, mbd, bean)
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
// 添加到三级缓存中
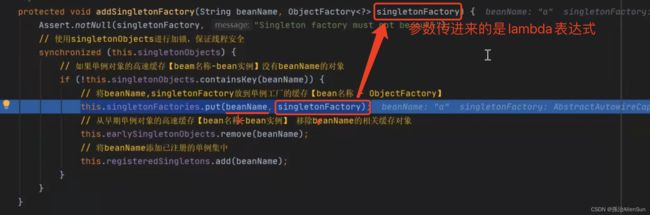
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
这里只是添加了一个工厂,通过这个工厂(ObjectFactory)的getObject方法可以得到一个对象,而这个对象实际上就是通过getEarlyBeanReference这个方法创建的。那么,什么时候会去调用这个工厂的getObject方法呢?这个时候就要到创建B的流程了,目前只是把lambda表达式当做参数传递,并没有实际调用!
当A完成了实例化并添加进了三级缓存后,就要开始为A进行属性注入了,在注入时发现A依赖了B,那么这个时候Spring又会去getBean(b),然后反射调用setter方法完成属性注入。
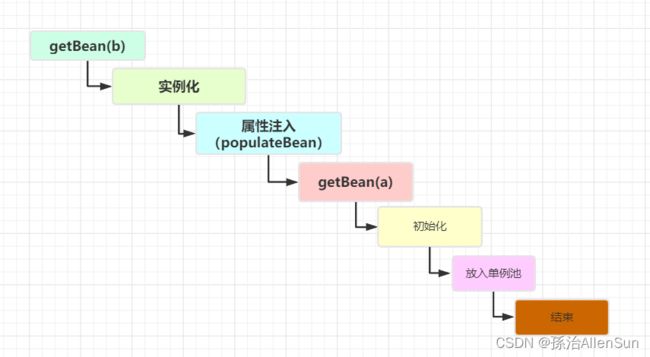 因为B需要注入A,所以在创建B的时候,又会去调用getBean(a),这个时候就又回到之前的流程了,但是不同的是,之前的getBean是为了创建Bean,而此时再调用getBean不是为了创建了,而是要从缓存中获取,因为之前A在实例化后已经将其放入了三级缓存singletonFactories中,所以此时getBean(a)的流程就是这样子了
因为B需要注入A,所以在创建B的时候,又会去调用getBean(a),这个时候就又回到之前的流程了,但是不同的是,之前的getBean是为了创建Bean,而此时再调用getBean不是为了创建了,而是要从缓存中获取,因为之前A在实例化后已经将其放入了三级缓存singletonFactories中,所以此时getBean(a)的流程就是这样子了

从这里我们可以看出,注入到B中的A是通过getEarlyBeanReference方法提前暴露出去的一个对象,还不是一个完整的Bean,那么getEarlyBeanReference到底干了啥了,我们看下它的源码
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
它实际上就是调用了后置处理器的getEarlyBeanReference,而真正实现了这个方法的后置处理器只有一个,就是通过@EnableAspectJAutoProxy注解导入的AnnotationAwareAspectJAutoProxyCreator。也就是说如果在不考虑AOP的情况下,上面的代码等价于:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
return exposedObject;
}
也就是说这个工厂啥都没干,直接将实例化阶段创建的对象返回了!所以说在不考虑AOP的情况下三级缓存有用嘛?没什么用,我直接将这个对象放到二级缓存中不是一点问题都没有吗?在下文结合AOP分析循环依赖的时候你就能体会到三级缓存的作用!
这个时候我们需要将整个创建A这个Bean的流程走完,如下图:
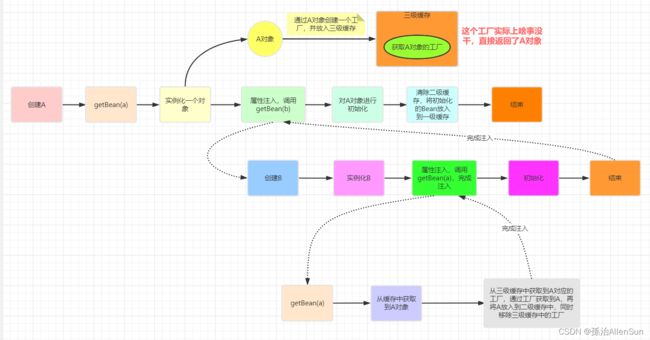 从上图中我们可以看到,虽然在创建B时会提前给B注入了一个还未初始化的A对象,但是在创建A的流程中一直使用的是注入到B中的A对象的引用,之后会根据这个引用对A进行初始化,所以这是没有问题的。
从上图中我们可以看到,虽然在创建B时会提前给B注入了一个还未初始化的A对象,但是在创建A的流程中一直使用的是注入到B中的A对象的引用,之后会根据这个引用对A进行初始化,所以这是没有问题的。
(2)结合了AOP的循环依赖
之前我们已经说过了,在普通的循环依赖的情况下,三级缓存没有任何作用。三级缓存实际上跟Spring中的AOP相关,我们再来看一看getEarlyBeanReference的代码:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
如果在开启AOP的情况下,那么就是调用到AnnotationAwareAspectJAutoProxyCreator的getEarlyBeanReference方法,对应的源码如下:
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
// 如果需要代理,返回一个代理对象,不需要代理,直接返回当前传入的这个bean对象
return wrapIfNecessary(bean, beanName, cacheKey);
}
回到上面的例子,我们对A进行了AOP代理的话,那么此时getEarlyBeanReference将返回一个代理后的对象,而不是实例化阶段创建的对象,这样就意味着B中注入的A将是一个代理对象而不是A的实例化阶段创建后的对象。
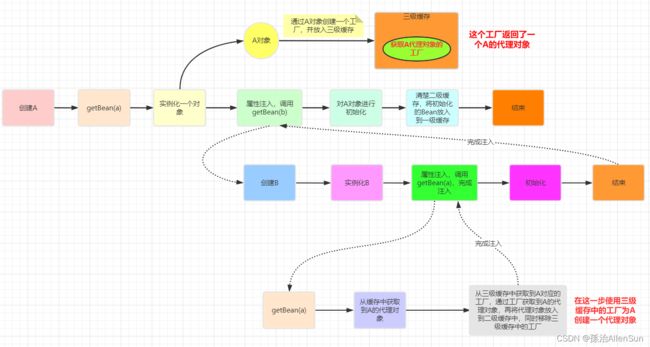
【1】疑问一:在给B注入的时候为什么要注入一个代理对象?
答:当我们对A进行了AOP代理时,说明我们希望从容器中获取到的就是A代理后的对象而不是A本身,因此把A当作依赖进行注入时也要注入它的代理对象
【2】疑问二:明明初始化的时候是A对象,那么Spring是在哪里将代理对象放入到容器中的呢?
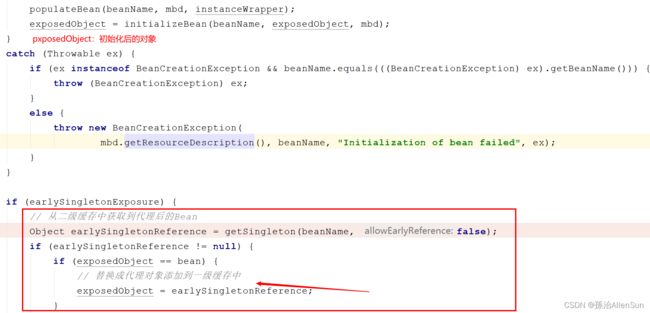 在完成初始化后,Spring又调用了一次getSingleton方法,这一次传入的参数又不一样了,false可以理解为禁用三级缓存,前面图中已经提到过了,在为B中注入A时已经将三级缓存中的工厂取出,并从工厂中获取到了一个对象放入到了二级缓存中,所以这里的这个getSingleton方法做的事件就是从二级缓存中获取到这个代理后的A对象。exposedObject == bean可以认为是必定成立的
在完成初始化后,Spring又调用了一次getSingleton方法,这一次传入的参数又不一样了,false可以理解为禁用三级缓存,前面图中已经提到过了,在为B中注入A时已经将三级缓存中的工厂取出,并从工厂中获取到了一个对象放入到了二级缓存中,所以这里的这个getSingleton方法做的事件就是从二级缓存中获取到这个代理后的A对象。exposedObject == bean可以认为是必定成立的
【3】疑问三:初始化的时候是对A对象本身进行初始化,而容器中以及注入到B中的都是代理对象,这样不会有问题吗?
答:不会,这是因为不管是cglib代理还是jdk动态代理生成的代理类,内部都持有一个目标类的引用,当调用代理对象的方法时,实际会去调用目标对象的方法,A完成初始化相当于代理对象自身也完成了初始化
【4】疑问四:三级缓存为什么要使用工厂而不是直接使用引用?换而言之,为什么需要这个三级缓存,直接通过二级缓存暴露一个引用不行吗?
答:这个工厂的目的在于延迟对实例化阶段生成的对象的代理,只有真正发生循环依赖的时候,才去提前生成代理对象,否则只会创建一个工厂并将其放入到三级缓存中,但是不会去通过这个工厂去真正创建对象
我们思考一种简单的情况,就以单独创建A为例,假设AB之间现在没有依赖关系,但是A被代理了,这个时候当A完成实例化后还是会进入下面这段代码:
// A是单例的,mbd.isSingleton()条件满足
// allowCircularReferences:这个变量代表是否允许循环依赖,默认是开启的,条件也满足
// isSingletonCurrentlyInCreation:正在在创建A,也满足
// 所以earlySingletonExposure=true
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
// 还是会进入到这段代码中
if (earlySingletonExposure) {
// 还是会通过三级缓存提前暴露一个工厂对象
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
看到了吧,即使没有循环依赖,也会将其添加到三级缓存中,而且是不得不添加到三级缓存中,因为到目前为止Spring也不能确定这个Bean有没有跟别的Bean出现循环依赖。
假设我们在这里直接使用二级缓存的话,那么意味着所有的Bean在这一步都要完成AOP代理。这样做有必要吗?
不仅没有必要,而且违背了Spring在结合AOP跟Bean的生命周期的设计!Spring结合AOP跟Bean的生命周期本身就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。
(3)三级缓存真的提高了效率了吗?
分为两点讨论:
(1)没有进行AOP的Bean间的循环依赖
从上文分析可以看出,这种情况下三级缓存根本没用!所以不会存在什么提高了效率的说法
(2)进行了AOP的Bean间的循环依赖
就以我们上的A、B为例,其中A被AOP代理,我们先分析下使用了三级缓存的情况下,A、B的创建流程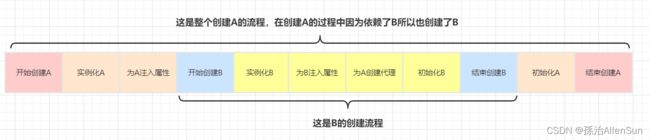 假设不使用三级缓存,直接在二级缓存中
假设不使用三级缓存,直接在二级缓存中
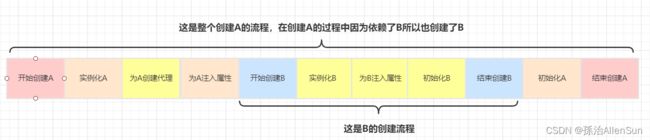 上面两个流程的唯一区别在于为A对象创建代理的时机不同,在使用了三级缓存的情况下为A创建代理的时机是在B中需要注入A的时候,而不使用三级缓存的话在A实例化后就需要马上为A创建代理然后放入到二级缓存中去。对于整个A、B的创建过程而言,消耗的时间是一样的
上面两个流程的唯一区别在于为A对象创建代理的时机不同,在使用了三级缓存的情况下为A创建代理的时机是在B中需要注入A的时候,而不使用三级缓存的话在A实例化后就需要马上为A创建代理然后放入到二级缓存中去。对于整个A、B的创建过程而言,消耗的时间是一样的
综上,不管是哪种情况,三级缓存提高了效率这种说法都是错误的!
(4)总结
问:”Spring是如何解决的循环依赖?“
答:Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
问:”为什么要使用三级缓存呢?二级缓存能解决循环依赖吗?“
答:如果要使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成AOP代理,这样违背了Spring设计的原则,Spring在设计之初就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步来完成AOP代理,而不是在实例化后就立马进行AOP代理。