Pytorch从零开始实现Transformer (from scratch)

Pytorch从零开始实现Transformer
- 前言
- 一、Transformer架构介绍
-
- 1. Embedding
- 2. Multi-Head Attention
-
- Query,Key,Value
- 3. Transformer Block
-
- LayerNorm
- Feed Forward
- 4. Decoder Block
- 二、Transformer代码实现
-
- 0. 导入库
- 1. Word Embedding
- 2. Positional Encoding
- 3. Multi-Head Attention
- 4. Transformer Encoder
- 5. Transformer Decoder
-
- Decoder attention
- Encoder decoder attention
- 6. Overrall Transformer
- 7. Test Code
- 总结
- 日志
- 参考文献
前言
2023年可以说是AI备受关注的一年,ChatGPT(GPT3.5)的问世引起了世界的轰动,近期GPT4的出现更是颠覆了各界对深度学习的认知,AI不止停留在特定任务的学习上,诸如此类的大模型已经初步符合人们最开始对AI的幻想——通用模型,通用模型可以处理多种场景下的难题。总所周知这些大模型背后的基础就是Transformer,于2017年提出后就席卷了整个学术界,各领域学者纷纷投入到Transformer的研究中,比如用Transformer取代ResNet作为Backbone取得更好的下游任务,或是单纯就Transformer的网络架构进行改进。“树要长多高,根就要扎多深”,在Transformer构建的金碧辉煌的大厦逐步建起时,不能忘记其最原初的根本。
正值论文写作稍微告一段落,有时间深入理解Transformer工作原理,复现Transformer和Transformer相关问题在工作面试中也是比较常见的,对于深度学习初学者,从零开始实现Transformer即Code the Transformer from scratch可能会是一个很艰巨的任务,甚至望而却步,不可否认在写这篇博客前我也是这样。Transformer的衍生比如BERT、Vision Transformer这种比较大的模型,下意识就会被这个“大”所吓到,觉得凭自己贫瘠的代码功底应该是难以实现。可实际做起来并没有想象那么难,“Just do it!”
希望每位读者看完这篇文章后能手撕Transformer或者对其有更深入的理解。
一、Transformer架构介绍
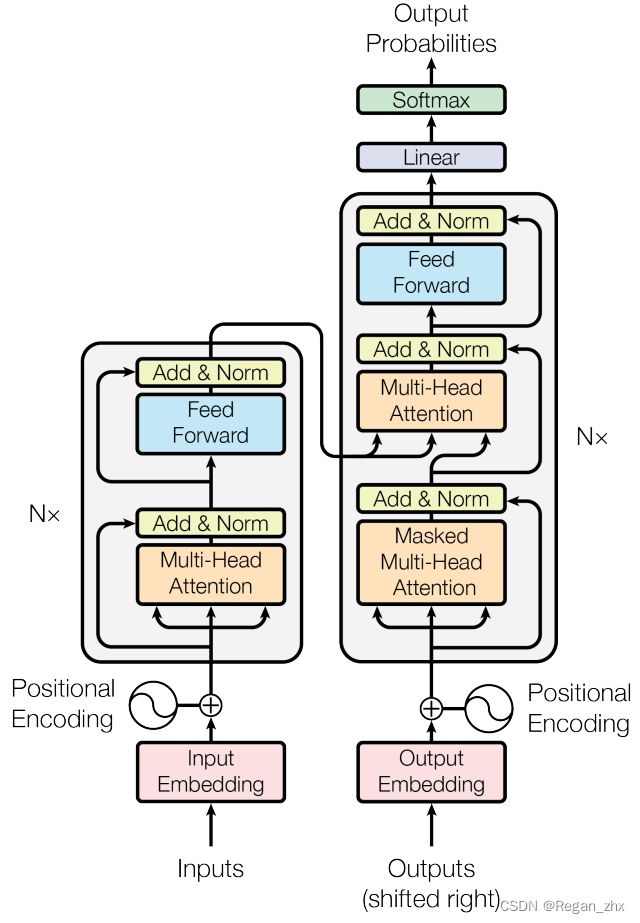
Transformer的模型流程图如上,取自原论文 Attention is all you need,目前引用量是69364。论文于2017年发表,由Google Brain和Google Research团队研发。据我所知,Transformer最初就是设计出来解决NLP领域问题的,比如机器翻译。
Tip:对于学习的建议是首先观看视频讲解,然后手打打一遍代码,最后看些博客对每个模块细致理解。(推荐视频和博客将放到文末参考文献部分)
接下来会简短介绍一下流程图中的各个部分,之后在下一节详细说明并实现代码。
1. Embedding
此处的Embedding包含上图中的Input Embedding和Output Embedding,实际上这部分代码的实现是一样的。按Input Embedding为例,其分为Word Embedding和Positional Embedding(即图中Positional Encoding)。Word Embedding作用是将一个个单词转化为向量,即词嵌入,位置编码Positional Encoding这是给单词句子对应词向量添加位置信息。

论文对位置编码这块并没有解释说明,就直接通过sin和cos对词向量的每个位置元素进行操作,偶数位(2i)使用sin,奇数位(2i+1)使用cos,然后将位置编码直接加(+)到词向量上。
2. Multi-Head Attention
多头注意力机制,也可称为Self-attention自注意力机制,叫法不一。仔细看可以看到图中在Embedding后引申出4路,有3路进入Multi-Head Attention模块,另1路在之后和多头注意力模块的结果Norm后汇合(其实就是相加)。Multi-Head Attention是Transformer的核心,而这3路信息则是Multi-Head Attention的核心。3路分别为Query,Key和Value。
Query,Key,Value
举个例子,图源自The Illustrated Transformer,
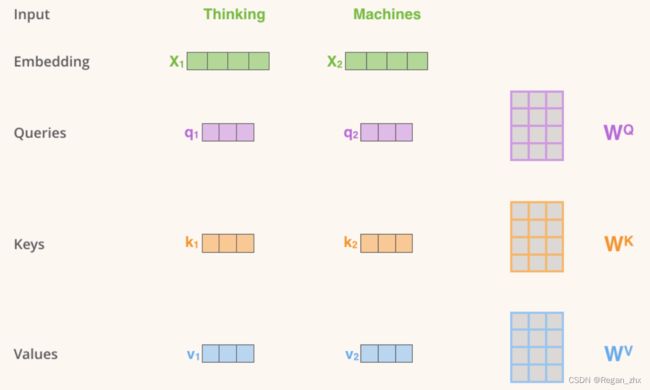
假如“Thinking”和“Machines”这两个单词经过Word Embedding和Positional Embedding后为x1和x2,
Tip:其实这里也体现了“Multi”,多头注意力模块把一整个Embedding(比如一个句子的词向量)切分为若干份(比如Heads为8就均分为8段)作为输入,旨在学习不同维度的特征(并没有证明,合情推理)。
然后将x1、x2分别和预先定义好的 W Q W^Q WQ, W K W^K WK, W V W^V WV矩阵进行矩阵乘(或者说线性组合),即可得到q1,k1,v1(同理,q2,k2,v2)。从变量命名不难看出这是基于一套字典检索匹配的策略,给一个Query,然后找到对应的Key,而这个Value呢其实就是所要保存的值。Query是网络当前待查询的值,Key记录着上一次迭代网络的值,Value则负责保存这些值,可能听上去很抽象,类比RNN循环神经网络,Q是现在,K是过去,V用于记录和更新。而注意力所体现的地方就在于矩阵的乘法,类似余弦相似度,Q和K的转置相乘即可得到相似性,相似性越大则Q和K越匹配。如有不懂,可以观看第二节代码帮助理解。
3. Transformer Block
Transformer Block也指Encoder Block,在经过Multi-Head Attention和Add&Norm后,此处必要一提,算是一个细节,Multi-Head Attention后的结果和之前未曾细说的那1路即Value进行相加(Add),这里足以体现Value的记录和存储作用,可见Value在模型中重要性。
这种让模型某一路直接跳到某个模块后相加的操作(ShortCut操作)灵感来源于何恺明大神的ResNet,这是毋庸置疑的。残差的操作避免了梯度弥散的问题,同时也起到特征融合的作用,保留原本的特征。
LayerNorm
必要一提,不同于ResNet这些卷积神经网络使用BatchNorm,Transformer使用的是LayerNorm。
LayerNorm论文发表于2016年,见Layer Normalization,可以直接用于RNN神经网络的训练,因为RNN特质对整个Batch的归一化并不现实,这也决定LayerNorm对。
BatchNorm和LayerNorm的比较见下图,图源于paperswithcode.com/method/layer-normalization
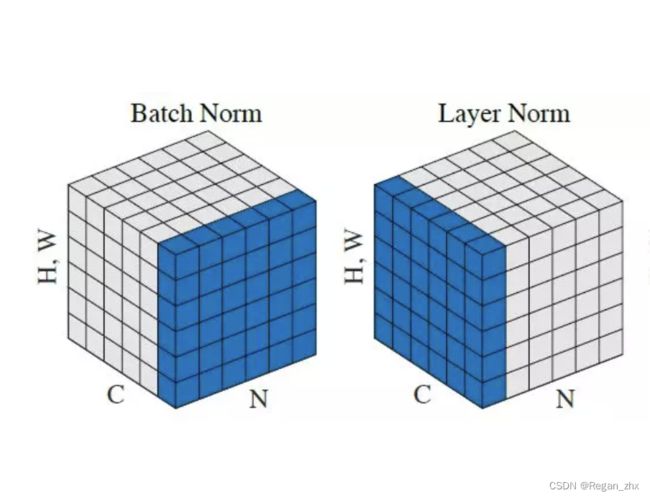
N为batch size,C为channel(通道数),H,W代表每个特征向量的高和宽。
简单的理解就是BatchNorm是对一个batch size样本内的每个特征做归一化,LayerNorm是对每个样本的所有特征做归一化。(后续会补充细讲)
Feed Forward
使用两层全连接层(Linear)和ReLU激活函数。
4. Decoder Block
Decoder Block的架构大体上和Encoder Block是一致的,唯独不同的是Decoder比Encoder多了Masked Multi-Head Attention。
那么为什么要在Decode阶段对特征(或者说tokens)做mask呢?
Mask的样式如下,白格为0,蓝格为1, 1表示保留的部分,0表示mask的部分:
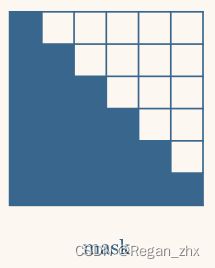
Transformer针对序列化特征,比如文本数据,这些特征是有前后关系的,为了不让Decoder通过未来的单词(或者说特征)来猜测出当前的特征,将后面的token进行mask,这样模型只能通过过去的词或者说特征元素来预测当前特征元素。
二、Transformer代码实现
本节的代码取自https://www.kaggle.com/code/arunmohan003/transformer-from-scratch-using-pytorch/notebook,但代码会有些许不同但保证是正确的(因为原来代码一些地方有瑕疵),本人做的工作更多是翻译和整理网上对Transformer的讲解。
0. 导入库
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import warnings
warnings.simplefilter("ignore")
1. Word Embedding
首先,我们需要将输入序列中的每个单词转换为embedding向量。
假设每个embedding维数(embed_dim)是512维,vocabulary词汇表大小(vocab_size)是100,那么embedding词嵌入矩阵的大小将是100x512(行x列)。这些矩阵将在训练中学习,在inference即推理过程中,每个单词将被映射到相应的512维向量。如果batch size为32,序列长度(seq_len)为10(10个单词)。输出将是32x10x512。
Tip:inference推理过程在深度学习中指把从训练中学习到的能⼒应⽤到⼯作中去,也就是在训练完模型后将模型对实际的输入(可以是训练集里的数据也可以是其他数据)进行在线推演输出结果的过程。
对于词嵌入矩阵的构造有专门的nn.Embedding,pytorch官方文档将其称为Sparse Layer(稀疏层),是一个保存了固定字典和大小的简单查找表。这个模块常用来保存词嵌入和用下标检索它们。模块的输入是一个下标的列表,输出是对应的词嵌入。
class WordEmbedding(nn.Module):
def __init__(self, vocab_size, embed_dim):
"""
Args:
vocab_size: size of vocabulary
embed_dim: dimension of embeddings
"""
super(WordEmbedding, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
def forward(self, x):
"""
Args:
x: input vector
Returns:
out: embedding vector
"""
out = self.embed(x)
return out
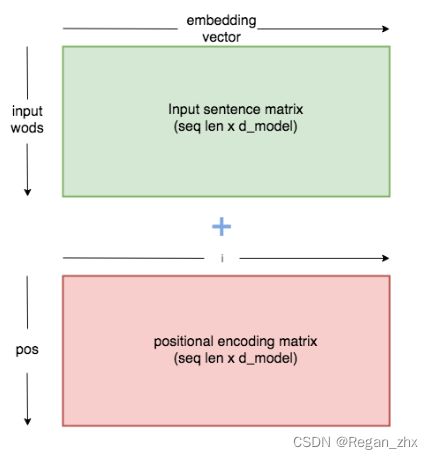
2. Positional Encoding
回顾到上一节位置编码的公式,公式细节解释:
pos -->指的是当前词在句子中的顺序 [0,max_seq_len)
i -->指沿embedding维度的位置,即 [0,512)
这里注意pos范围不是[0,10),10是输入序列的长度seq_len,因为输入的序列长度一般是小于等于max_seq_len的,也就是位置编码矩阵是固定大小,输入embedding序列是随机长度。
前面我们已经得到32 x 10 x 512的embedding向量。类似地,我们将有尺寸为32 x 10 x 512的位置编码向量。然后我们把两者相加(实际上位置编码矩阵会更大)。
class PositionalEmbedding(nn.Module):
def __init__(self, max_seq_len, embed_model_dim):
"""
Args:
seq_len: length of input sequence
embed_model_dim: demension of embedding
"""
super(PositionalEmbedding, self).__init__()
self.embed_dim = embed_model_dim
pe = torch.zeros(max_seq_len, self.embed_dim)
for pos in range(max_seq_len):
for i in range(0, self.embed_dim, 2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i) / self.embed_dim)))
pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1)) / self.embed_dim)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
"""
Args:
x: input vector
Returns:
out : output
"""
# make embeddings relatively larger
x = x * math.sqrt(self.embed_dim)
# add constant to embedding
seq_len = x.size(1)
out = x + torch.autograd.Variable(self.pe[:, :seq_len], requires_grad=False)
return out
3. Multi-Head Attention
什么是self-attention自注意力机制?
对于某个句子比如“Dog is crossing the street because it saw the kitchen”,人类可以很容易理解这句话重点是在说狗,而对机器来说就不是那么容易的了。
当模型处理每个单词时,self-attention可以查看输入序列中的其他位置以寻找线索。它将根据每个单词与其他单词的依赖关系创建一个向量。也就是所谓的“完形填空”。这里插播一些非计算机知识,算是一种联想来帮助读者理解。
格式塔系德文“Gestalt”的音译,主要指完形,即具有不同部分分离特性的有机整体。格式塔作为心理学术语,具有两种含义:一指事物的一般属性,即形式;一指事物的个别实体,即分离的整体,形式仅为其属性之一。也就是说,“假使有一种经验的现象,它的每一成分都牵连到其他成分;而且每一成分之所以有其特性,即因为它和其他部分具有关系,这种现象便称为格式塔。”总之,格式塔不是孤立不变的现象,而是指通体相关的完整的现象。完整的现象具有它本身完整的特性,它既不能割裂成简单的元素,同时它的特性又不包含于任何元素之内。——百度百科
下面进入到实例的讲解:
Step1:首先从Encoder的每个输入向量(在本例中,是每个单词的嵌入)中创建三个向量,分别是Query向量、Key向量和Value向量,每个向量的维数都是1x64。这里64是配合上文 512 / 8 = 64 512/8=64 512/8=64,其中8为多头注意力的头的数量。我们将有一个Key矩阵、Query矩阵和一个Value矩阵来生成Key、Query和Value向量,这些矩阵都是在训练中可学习的。
对于经过WordEmbedding和PositionEncoding后的输入张量32x10x512,将其调整为32x10x8x64。
Step2:对应Transformer原论文的Scaled Dot-Product Attention:
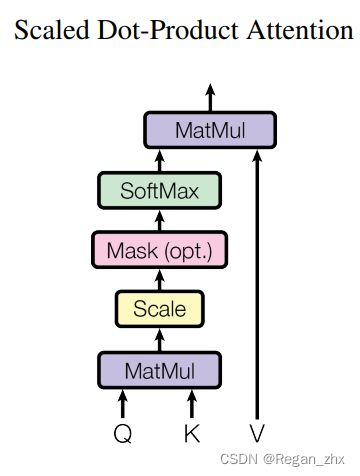
Mask是optional(即可选项),Encoder时不需要Mask,Decoder需要Mask。
根据公式:

将Query矩阵与Key矩阵相乘,[Q x K T K^T KT]
当前Key、Query和Key矩阵维度是32x10x8x64。QK相乘之前,我们将对它们进行转置(transpose)以方便相乘(32x8x10x64)。
现在将Query矩阵与转置的Key矩阵相乘。即(32x8x10x64) x (32x8x64x10) -> (32x8x10x10)。
然后将矩阵乘的结果除以Key维度,将32x8x10x10向量除以8,即除以64的平方根(Key矩阵的维数)
接下来是softmax之后结果和Value矩阵(32x8x10x64)相乘:
(32x8x10x10) x (32x8x10x64) -> (32x8x10x64)
Step3:通过Step2得到矩阵,将多头的结果进行合并(concat),然后让其通过线性层,这就形成了多头注意力的输出。图中h表示number of heads,即多头注意力的数量。
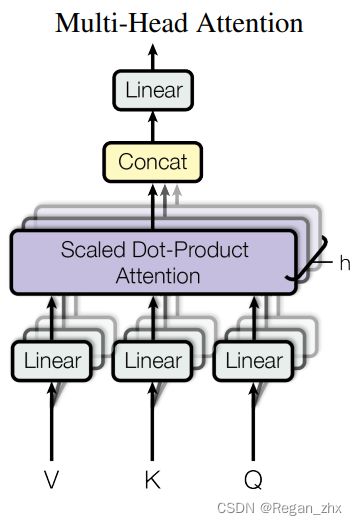

(32x8x10x64)张量被转置回为(32x10x8x64),然后Concat为(32x10x512)。最后通过Linear线性层得到(32x10x512)的输出。
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim=512, n_heads=8):
"""
Args:
embed_dim: dimension of embeding vector output
n_heads: number of self attention heads
"""
super(MultiHeadAttention, self).__init__()
self.embed_dim = embed_dim # 512 dim
self.n_heads = n_heads # 8
self.single_head_dim = int(self.embed_dim / self.n_heads) # 512/8 = 64 . each key,query, value will be of 64d
# key,query and value matrixes #64 x 64
self.query_matrix = nn.Linear(self.single_head_dim, self.single_head_dim,
bias=False) # single key matrix for all 8 keys #512x512
self.key_matrix = nn.Linear(self.single_head_dim, self.single_head_dim, bias=False)
self.value_matrix = nn.Linear(self.single_head_dim, self.single_head_dim, bias=False)
self.out = nn.Linear(self.n_heads * self.single_head_dim, self.embed_dim)
def forward(self, key, query, value, mask=None): # batch_size x sequence_length x embedding_dim # 32 x 10 x 512
"""
Args:
key : key vector
query : query vector
value : value vector
mask: mask for decoder
Returns:
output vector from multihead attention
"""
batch_size = key.size(0)
seq_length = key.size(1)
# query dimension can change in decoder during inference.
# so we cant take general seq_length
seq_length_query = query.size(1)
# 32x10x512
key = key.view(batch_size, seq_length, self.n_heads,
self.single_head_dim) # batch_size x sequence_length x n_heads x single_head_dim = (32x10x8x64)
query = query.view(batch_size, seq_length_query, self.n_heads, self.single_head_dim) # (32x10x8x64)
value = value.view(batch_size, seq_length, self.n_heads, self.single_head_dim) # (32x10x8x64)
k = self.key_matrix(key) # (32x10x8x64)
q = self.query_matrix(query)
v = self.value_matrix(value)
q = q.transpose(1, 2) # (batch_size, n_heads, seq_len, single_head_dim) # (32 x 8 x 10 x 64)
k = k.transpose(1, 2) # (batch_size, n_heads, seq_len, single_head_dim)
v = v.transpose(1, 2) # (batch_size, n_heads, seq_len, single_head_dim)
# computes attention
# adjust key for matrix multiplication
k_adjusted = k.transpose(-1, -2) # (batch_size, n_heads, single_head_dim, seq_ken) #(32 x 8 x 64 x 10)
product = torch.matmul(q, k_adjusted) # (32 x 8 x 10 x 64) x (32 x 8 x 64 x 10) = #(32x8x10x10)
# fill those positions of product matrix as (-1e20) where mask positions are 0
if mask is not None:
product = product.masked_fill(mask == 0, float("-1e20"))
# divising by square root of key dimension
product = product / math.sqrt(self.single_head_dim) # / sqrt(64)
# applying softmax
scores = F.softmax(product, dim=-1)
# mutiply with value matrix
scores = torch.matmul(scores, v) ##(32x8x 10x 10) x (32 x 8 x 10 x 64) = (32 x 8 x 10 x 64)
# concatenated output
concat = scores.transpose(1, 2).contiguous().view(batch_size, seq_length_query,
self.single_head_dim * self.n_heads) # (32x8x10x64) -> (32x10x8x64) -> (32,10,512)
output = self.out(concat) # (32,10,512) -> (32,10,512)
return output
Warning: 在学习Vision Transformer代码时,回过头来发现以上的MultiHeadAttention这部分代码是有些许问题,因为这部分代码是借用Kaggle上的,所以写作当时没有意识到。不过也谈不上错误,只能说那么设计有些不恰当,不知道读者能否找出问题所在。答案将在Pytorch动手实现Transformer机器翻译这篇博客中给出,历时请对比代码。
4. Transformer Encoder
class TransformerBlock(nn.Module):
def __init__(self, embed_dim, expansion_factor=4, n_heads=8):
super(TransformerBlock, self).__init__()
"""
Args:
embed_dim: dimension of the embedding
expansion_factor: fator ehich determines output dimension of linear layer
n_heads: number of attention heads
"""
self.attention = MultiHeadAttention(embed_dim, n_heads)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
self.feed_forward = nn.Sequential(
nn.Linear(embed_dim, expansion_factor * embed_dim),
nn.ReLU(),
nn.Linear(expansion_factor * embed_dim, embed_dim)
)
self.dropout1 = nn.Dropout(0.2)
self.dropout2 = nn.Dropout(0.2)
def forward(self, key, query, value):
"""
Args:
key: key vector
query: query vector
value: value vector
norm2_out: output of transformer block
"""
attention_out = self.attention(key, query, value) # 32x10x512
attention_residual_out = attention_out + value # 32x10x512
norm1_out = self.dropout1(self.norm1(attention_residual_out)) # 32x10x512
feed_fwd_out = self.feed_forward(norm1_out) # 32x10x512 -> #32x10x2048 -> 32x10x512
feed_fwd_residual_out = feed_fwd_out + norm1_out # 32x10x512
norm2_out = self.dropout2(self.norm2(feed_fwd_residual_out)) # 32x10x512
return norm2_out
class TransformerEncoder(nn.Module):
"""
Args:
seq_len : length of input sequence
embed_dim: dimension of embedding
num_layers: number of encoder layers
expansion_factor: factor which determines number of linear layers in feed forward layer
n_heads: number of heads in multihead attention
Returns:
out: output of the encoder
"""
def __init__(self, seq_len, vocab_size, embed_dim, num_layers=2, expansion_factor=4, n_heads=8):
super(TransformerEncoder, self).__init__()
self.embedding_layer = WordEmbedding(vocab_size, embed_dim)
self.positional_encoder = PositionalEmbedding(seq_len, embed_dim)
self.layers = nn.ModuleList([TransformerBlock(embed_dim, expansion_factor, n_heads) for i in range(num_layers)])
def forward(self, x):
embed_out = self.embedding_layer(x)
out = self.positional_encoder(embed_out)
for layer in self.layers:
out = layer(out, out, out)
return out # 32x10x512
5. Transformer Decoder
在Decoder中有两种multi-head attention,一种叫decoder attention,另一种叫encoder decoder attention。
Decoder attention
首先是使用带mask的multi-head attention即decoder attention。
为什么要使用Mask呢?
使用mask掩码是因为在创建目标词的注意力时,我们不需要一个词来查看将来的词来检查依赖关系。其实也是一个历史问题,在NLP发展史中对文本序列token的处理类似GPT2的Auto-regressive(自回归)的Mask,就只对先前的tokens进行注意力学习,而不让模型通过未知的后续token来猜测当前token,否则模型会直接copy下一个单词的token。后来的BERT用的就是双向的策略,而不只是看过去的token而是从过去到未来再从未来到过去两个方向进行预测。
例如:在单词“I am a student”中,我们不需要单词“a”来查找单词“student”,没有mask的话当模型看到“a”就会直接给出"student"的预测。
对于Mask这一三角矩阵,如第一节中Decoder Block的图所示,对于所有零位置,用负无穷大填充,而在代码中,用一个非常小的数字填充它以避免除法错误(比如 -1e20)。
Encoder decoder attention
对于这个多头注意力,从Encoder的输出中创建Key和Value向量。Query是从上一个Decoder层的输出创建得到的。流程就如下图所示:

class DecoderBlock(nn.Module):
def __init__(self, embed_dim, expansion_factor=4, n_heads=8):
super(DecoderBlock, self).__init__()
"""
Args:
embed_dim: dimension of the embedding
expansion_factor: fator ehich determines output dimension of linear layer
n_heads: number of attention heads
"""
self.attention = MultiHeadAttention(embed_dim, n_heads=8)
self.norm = nn.LayerNorm(embed_dim)
self.dropout = nn.Dropout(0.2)
self.transformer_block = TransformerBlock(embed_dim, expansion_factor, n_heads)
def forward(self, key, query, x, mask):
"""
Args:
key: key vector
query: query vector
x: value vector
mask: mask to be given for multi head attention
Returns:
out: output of transformer block
"""
# we need to pass mask mask only to fst attention
attention = self.attention(x, x, x, mask=mask) # 32x10x512
value = self.dropout(self.norm(attention + x))
out = self.transformer_block(key, query, value)
return out
class TransformerDecoder(nn.Module):
def __init__(self, target_vocab_size, embed_dim, seq_len, num_layers=2, expansion_factor=4, n_heads=8):
super(TransformerDecoder, self).__init__()
"""
Args:
target_vocab_size: vocabulary size of taget
embed_dim: dimension of embedding
seq_len : length of input sequence
num_layers: number of encoder layers
expansion_factor: factor which determines number of linear layers in feed forward layer
n_heads: number of heads in multihead attention
"""
self.word_embedding = WordEmbedding(target_vocab_size, embed_dim)
self.position_embedding = PositionalEmbedding(seq_len, embed_dim)
self.layers = nn.ModuleList(
[
DecoderBlock(embed_dim, expansion_factor=4, n_heads=8)
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_dim, target_vocab_size)
self.dropout = nn.Dropout(0.2)
def forward(self, x, enc_out, mask):
"""
Args:
x: input vector from target
enc_out : output from encoder layer
trg_mask: mask for decoder self attention
Returns:
out: output vector
"""
x = self.word_embedding(x) # 32x10x512
x = self.position_embedding(x) # 32x10x512
x = self.dropout(x)
for layer in self.layers:
x = layer(enc_out, x, enc_out, mask)
out = F.softmax(self.fc_out(x))
return out
6. Overrall Transformer
class Transformer(nn.Module):
def __init__(self, embed_dim, src_vocab_size, target_vocab_size, seq_length, num_layers=2, expansion_factor=4,
n_heads=8):
super(Transformer, self).__init__()
"""
Args:
embed_dim: dimension of embedding
src_vocab_size: vocabulary size of source
target_vocab_size: vocabulary size of target
seq_length : length of input sequence
num_layers: number of encoder layers
expansion_factor: factor which determines number of linear layers in feed forward layer
n_heads: number of heads in multihead attention
"""
self.target_vocab_size = target_vocab_size
self.encoder = TransformerEncoder(seq_length, src_vocab_size, embed_dim, num_layers=num_layers,
expansion_factor=expansion_factor, n_heads=n_heads)
self.decoder = TransformerDecoder(target_vocab_size, embed_dim, seq_length, num_layers=num_layers,
expansion_factor=expansion_factor, n_heads=n_heads)
def make_trg_mask(self, trg):
"""
Args:
trg: target sequence
Returns:
trg_mask: target mask
"""
batch_size, trg_len = trg.shape
# returns the lower triangular part of matrix filled with ones
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
batch_size, 1, trg_len, trg_len
)
return trg_mask
def decode(self, src, trg):
"""
for inference
Args:
src: input to encoder
trg: input to decoder
out:
out_labels : returns final prediction of sequence
"""
trg_mask = self.make_trg_mask(trg)
enc_out = self.encoder(src)
out_labels = []
batch_size, seq_len = src.shape[0], src.shape[1]
# outputs = torch.zeros(seq_len, batch_size, self.target_vocab_size)
out = trg
for i in range(seq_len): # 10
out = self.decoder(out, enc_out, trg_mask) # bs x seq_len x vocab_dim
# taking the last token
out = out[:, -1, :]
out = out.argmax(-1)
out_labels.append(out.item())
out = torch.unsqueeze(out, 0)
return out_labels
def forward(self, src, trg):
"""
Args:
src: input to encoder
trg: input to decoder
out:
out: final vector which returns probabilities of each target word
"""
trg_mask = self.make_trg_mask(trg)
enc_out = self.encoder(src)
outputs = self.decoder(trg, enc_out, trg_mask)
return outputs
7. Test Code
验证模型是否可正常运行,可以通过如下代码进行测试。如果没有报错,能输出结果那就没有问题。
if __name__ == '__main__':
src_vocab_size = 11
target_vocab_size = 11
num_layers = 6
seq_length = 12
# let 0 be sos(start operation signal) token and 1 be eos(end operation signal) token
src = torch.tensor([[0, 2, 5, 6, 4, 3, 9, 5, 2, 9, 10, 1],
[0, 2, 8, 7, 3, 4, 5, 6, 7, 2, 10, 1]])
target = torch.tensor([[0, 1, 7, 4, 3, 5, 9, 2, 8, 10, 9, 1],
[0, 1, 5, 6, 2, 4, 7, 6, 2, 8, 10, 1]])
print(src.shape, target.shape)
model = Transformer(embed_dim=512, src_vocab_size=src_vocab_size,
target_vocab_size=target_vocab_size, seq_length=seq_length,
num_layers=num_layers, expansion_factor=4, n_heads=8)
# print(model)
out = model(src, target)
print(out)
print(out.shape)
print("=" * 50)
# inference
src = torch.tensor([[0, 2, 5, 6, 4, 3, 9, 5, 2, 9, 10, 1]])
trg = torch.tensor([[0]])
print(src.shape, trg.shape)
out = model.decode(src, trg)
print(out)
总结
即使现在ChatGPT等大模型的问世引起了社会广泛关注,但仍理性看待Transformer及其应用范围,在工业界仍旧是以ResNet为首的卷积神经网络占大头。而Transformer在学术界的地位是无法取代的,因此了解最基础的Transformer(Naive Transformer)也是很有必要性的。后续可以关注一下本博客衍生出的Vision Transformer的介绍和实现(挖个坑)……
日志
2023.3.26.18:43 由于时间关系,先发布出来,后面会继续更进补充每个模块的要点和细节讲解。
2023.3.27.13:22 补充Word Embedding和Position Encoding的讲解。
2023.3.27.19:23 补充Multi-Head Attention讲解
2023.3.28.15:27 补充Transformer Decoder讲解
参考文献
B站视频链接:Transformer从零详细解读(可能是你见过最通俗易懂的讲解)
YouTube视频链接:Pytorch Transformers from Scratch (Attention is all you need) 【友情提示:此视频的代码有略微错误】
Ba J L, Kiros J R, Hinton G E. Layer normalization[J]. arXiv preprint arXiv:1607.06450, 2016.
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
https://www.kaggle.com/code/arunmohan003/transformer-from-scratch-using-pytorch/notebook
http://jalammar.github.io/illustrated-transformer/
https://theaisummer.com/transformer/
https://towardsdatascience.com/7-things-you-didnt-know-about-the-transformer-a70d93ced6b2
http://nlp.seas.harvard.edu/2018/04/03/attention.html
https://peterbloem.nl/blog/transformers
https://towardsdatascience.com/how-to-code-the-transformer-in-pytorch-24db27c8f9ec
https://github.com/hyunwoongko/transformer