数据湖架构Hudi(二)Hudi版本0.12源码编译、Hudi集成spark、使用IDEA与spark对hudi表增删改查
二、数据湖hudi快速上手
2.1 编译hudi源码
| Hadoop | 3.1.3 |
|---|---|
| Hive | 3.1.2 |
| Flink | 1.13.6,scala-2.12 |
| Spark | 3.2.2,scala-2.12 |
2.1.1 环境准备
[root@centos04 bin]# mvn -version
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: /opt/apps/apache-maven-3.6.3
Java version: 1.8.0_141, vendor: Oracle Corporation, runtime: /opt/apps/jdk1.8.0_141/jre
Default locale: en_US, platform encoding: UTF-8
[root@centos04 bin]# java -version
java version "1.8.0_141"
Java(TM) SE Runtime Environment (build 1.8.0_141-b15)
Java HotSpot(TM) 64-Bit Server VM (build 25.141-b15, mixed mode)
2.1.2 下载源码包
wget http://archive.apache.org/dist/hudi/0.12.0/hudi-0.12.0.src.tgz
tar -zxvf ./hudi-0.12.0.src.tgz
[root@centos04 apps]# ll
total 4
drwxr-xr-x. 6 root root 126 Feb 28 18:12 apache-maven-3.6.3
drwxr-xr-x. 22 501 games 4096 Aug 16 2022 hudi-0.12.0
drwxr-xr-x. 8 10 143 255 Jul 12 2017 jdk1.8.0_141
2.1.3 在pom文件中新增repository加速依赖下载
# 编辑pom文件
vim /opt/apps/hudi-0.12.0/pom.xml
# 新增repository加速依赖下载
<repository>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
在pom文件中修改依赖的组件版本:
<hadoop.version>3.1.3hadoop.version>
<hive.version>3.1.2hive.version>
2.1.4 修改源码兼容hadoop3并添加kafka依赖
Hudi默认依赖的hadoop2,要兼容hadoop3,除了修改版本,还需要修改如下代码:
vim /opt/apps/hudi-0.12.0/hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java
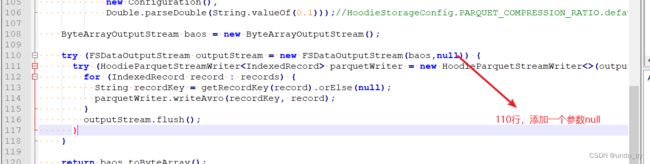
否则会因为hadoop2.x和3.x版本兼容问题(找不到合适的FSDataOutputStream构造器)。
- 有几个kafka的依赖需要手动安装,否则编译会报错。
通过网址下载:http://packages.confluent.io/archive/5.3/confluent-5.3.4-2.12.zip
# 解压后找到以下jar包,上传编译服务器
common-config-5.3.4.jar
common-utils-5.3.4.jar
kafka-avro-serializer-5.3.4.jar
kafka-schema-registry-client-5.3.4.jar
install本地仓库
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-config -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-config-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-utils -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-utils-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-avro-serializer -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-avro-serializer-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-schema-registry-client-5.3.4.jar
2.1.5 解决spark模块依赖冲突
修改了Hive版本为3.1.2,其携带的jetty是0.9.3,hudi本身用的0.9.4,存在依赖冲突。
2.1.5.1 修改hudi-spark-bundle的pom文件
目的:排除低版本jetty,添加hudi指定版本的jetty
pom文件位置:vim /opt/apps/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml (在382行的位置)
<dependency>
<groupId>${hive.groupid}groupId>
<artifactId>hive-serviceartifactId>
<version>${hive.version}version>
<scope>${spark.bundle.hive.scope}scope>
<exclusions>
<exclusion>
<artifactId>guavaartifactId>
<groupId>com.google.guavagroupId>
exclusion>
<exclusion>
<groupId>org.eclipse.jettygroupId>
<artifactId>*artifactId>
exclusion>
<exclusion>
<groupId>org.pentahogroupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>${hive.groupid}groupId>
<artifactId>hive-service-rpcartifactId>
<version>${hive.version}version>
<scope>${spark.bundle.hive.scope}scope>
dependency>
<dependency>
<groupId>${hive.groupid}groupId>
<artifactId>hive-jdbcartifactId>
<version>${hive.version}version>
<scope>${spark.bundle.hive.scope}scope>
<exclusions>
<exclusion>
<groupId>javax.servletgroupId>
<artifactId>*artifactId>
exclusion>
<exclusion>
<groupId>javax.servlet.jspgroupId>
<artifactId>*artifactId>
exclusion>
<exclusion>
<groupId>org.eclipse.jettygroupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>${hive.groupid}groupId>
<artifactId>hive-metastoreartifactId>
<version>${hive.version}version>
<scope>${spark.bundle.hive.scope}scope>
<exclusions>
<exclusion>
<groupId>javax.servletgroupId>
<artifactId>*artifactId>
exclusion>
<exclusion>
<groupId>org.datanucleusgroupId>
<artifactId>datanucleus-coreartifactId>
exclusion>
<exclusion>
<groupId>javax.servlet.jspgroupId>
<artifactId>*artifactId>
exclusion>
<exclusion>
<artifactId>guavaartifactId>
<groupId>com.google.guavagroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>${hive.groupid}groupId>
<artifactId>hive-commonartifactId>
<version>${hive.version}version>
<scope>${spark.bundle.hive.scope}scope>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbitgroupId>
<artifactId>javax.servletartifactId>
exclusion>
<exclusion>
<groupId>org.eclipse.jettygroupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.eclipse.jettygroupId>
<artifactId>jetty-serverartifactId>
<version>${jetty.version}version>
dependency>
<dependency>
<groupId>org.eclipse.jettygroupId>
<artifactId>jetty-utilartifactId>
<version>${jetty.version}version>
dependency>
<dependency>
<groupId>org.eclipse.jettygroupId>
<artifactId>jetty-webappartifactId>
<version>${jetty.version}version>
dependency>
<dependency>
<groupId>org.eclipse.jettygroupId>
<artifactId>jetty-httpartifactId>
<version>${jetty.version}version>
dependency>
否则在使用spark向hudi表插入数据时,会报错
java.lang.NoSuchMethodError: org.apache.hudi.org.apache.jetty.server.session.SessionHandler.setHttpOnly(Z)
2.1.5.2 修改hudi-utilities-bundle的pom文件
目的:排除低版本jetty,添加hudi指定版本的jetty
位置:vim /opt/apps/hudi-0.12.0/packaging/hudi-utilities-bundle/pom.xml(在405行的位置))
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-commonartifactId>
<version>${project.version}version>
<exclusions>
<exclusion>
<groupId>org.eclipse.jettygroupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-client-commonartifactId>
<version>${project.version}version>
<exclusions>
<exclusion>
<groupId>org.eclipse.jettygroupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>${hive.groupid}groupId>
<artifactId>hive-serviceartifactId>
<version>${hive.version}version>
<scope>${utilities.bundle.hive.scope}scope>
<exclusions>
<exclusion>
<artifactId>servlet-apiartifactId>
<groupId>javax.servletgroupId>
exclusion>
<exclusion>
<artifactId>guavaartifactId>
<groupId>com.google.guavagroupId>
exclusion>
<exclusion>
<groupId>org.eclipse.jettygroupId>
<artifactId>*artifactId>
exclusion>
<exclusion>
<groupId>org.pentahogroupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>${hive.groupid}groupId>
<artifactId>hive-service-rpcartifactId>
<version>${hive.version}version>
<scope>${utilities.bundle.hive.scope}scope>
dependency>
<dependency>
<groupId>${hive.groupid}groupId>
<artifactId>hive-jdbcartifactId>
<version>${hive.version}version>
<scope>${utilities.bundle.hive.scope}scope>
<exclusions>
<exclusion>
<groupId>javax.servletgroupId>
<artifactId>*artifactId>
exclusion>
<exclusion>
<groupId>javax.servlet.jspgroupId>
<artifactId>*artifactId>
exclusion>
<exclusion>
<groupId>org.eclipse.jettygroupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>${hive.groupid}groupId>
<artifactId>hive-metastoreartifactId>
<version>${hive.version}version>
<scope>${utilities.bundle.hive.scope}scope>
<exclusions>
<exclusion>
<groupId>javax.servletgroupId>
<artifactId>*artifactId>
exclusion>
<exclusion>
<groupId>org.datanucleusgroupId>
<artifactId>datanucleus-coreartifactId>
exclusion>
<exclusion>
<groupId>javax.servlet.jspgroupId>
<artifactId>*artifactId>
exclusion>
<exclusion>
<artifactId>guavaartifactId>
<groupId>com.google.guavagroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>${hive.groupid}groupId>
<artifactId>hive-commonartifactId>
<version>${hive.version}version>
<scope>${utilities.bundle.hive.scope}scope>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbitgroupId>
<artifactId>javax.servletartifactId>
exclusion>
<exclusion>
<groupId>org.eclipse.jettygroupId>
<artifactId>*artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.eclipse.jettygroupId>
<artifactId>jetty-serverartifactId>
<version>${jetty.version}version>
dependency>
<dependency>
<groupId>org.eclipse.jettygroupId>
<artifactId>jetty-utilartifactId>
<version>${jetty.version}version>
dependency>
<dependency>
<groupId>org.eclipse.jettygroupId>
<artifactId>jetty-webappartifactId>
<version>${jetty.version}version>
dependency>
<dependency>
<groupId>org.eclipse.jettygroupId>
<artifactId>jetty-httpartifactId>
<version>${jetty.version}version>
dependency>
否则在使用DeltaStreamer工具向hudi表插入数据时,也会报Jetty的错误。
2.1.6 编译并进入Hudi客户端
编译命令
mvn clean package -DskipTests -Dspark3.2 -Dflink1.13 -Dscala-2.12 -Dhadoop.version=3.1.3 -Pflink-bundle-shade-hive3
......
[INFO] hudi-kafka-connect ................................. SUCCESS [ 31.294 s]
[INFO] hudi-flink1.13-bundle .............................. SUCCESS [03:04 min]
[INFO] hudi-kafka-connect-bundle .......................... SUCCESS [ 56.169 s]
[INFO] hudi-spark2_2.12 ................................... SUCCESS [ 33.425 s]
[INFO] hudi-spark2-common ................................. SUCCESS [ 0.074 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 29:26 min
[INFO] Finished at: 2023-02-28T19:53:31+08:00
[INFO] ------------------------------------------------------------------------
- 进入hudi-cli说明成功:
$HUDI_HOME/hudi-cli目录, 运行hudi-cli脚本, 如果可以运行, 说明编译成功
[root@centos04 hudi-cli]# ./hudi-cli.sh
===================================================================
* ___ ___ *
* /\__\ ___ /\ \ ___ *
* / / / /\__\ / \ \ /\ \ *
* / /__/ / / / / /\ \ \ \ \ \ *
* / \ \ ___ / / / / / \ \__\ / \__\ *
* / /\ \ /\__\ / /__/ ___ / /__/ \ |__| / /\/__/ *
* \/ \ \/ / / \ \ \ /\__\ \ \ \ / / / /\/ / / *
* \ / / \ \ / / / \ \ / / / \ /__/ *
* / / / \ \/ / / \ \/ / / \ \__\ *
* / / / \ / / \ / / \/__/ *
* \/__/ \/__/ \/__/ Apache Hudi CLI *
* *
===================================================================
Welcome to Apache Hudi CLI. Please type help if you are looking for help.
hudi->
2.2 大数据环境准备
2.2.1 scala2.12.10的安装
linux版本下载地址:https://downloads.lightbend.com/scala/2.12.10/scala-2.12.10.tgz
# 解压
[root@centos04 apps]# tar -zxvf scala-2.12.10.tgz
# 环境变量
[root@centos04 apps]# vim /etc/profile
export SCALA_HOME=/opt/apps/scala-2.12.10
[root@centos04 scala-2.12.10]# source /etc/profile
[root@centos04 scala-2.12.10]# scala -version
Scala code runner version 2.12.10 -- Copyright 2002-2019, LAMP/EPFL and Lightbend, Inc.
2.2.2 hadoop3.1.3单机版安装
(1)下载地址
下载地址:https://archive.apache.org/dist/hadoop/core/hadoop-3.1.3/
或者 wget https://archive.apache.org/dist/hadoop/core/hadoop-3.1.3/hadoop-3.1.3.tar.gz
(2)上传、解压
[root@centos04 apps]# tar -zxvf hadoop-3.1.3.tar.gz
(3) /opt/apps/hadoop-3.1.3/etc/hadoop下修改hadoop-env.sh的文件内容
[root@centos04 hadoop]# vim hadoop-env.sh
# 指定JAVA_HOME
export JAVA_HOME=/opt/apps/jdk1.8.0_141
(4)/opt/apps/hadoop-3.1.3/etc/hadoop下修改core-site.xml的文件内容
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://192.168.100.104:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/apps/hadoop-3.1.3/tmpvalue>
property>
configuration>
(5)/opt/apps/hadoop-3.1.3/etc/hadoop下修改hdfs-site.xml的文件内容
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>
(6)SSH免密登录
#到 root 目录下:
cd /root
#执行生成密钥命令:
ssh-keygen -t rsa
#然后三个回车
#然后复制公钥追加到第一台节点的公钥文件中:
ssh-copy-id -i /root/.ssh/id_rsa.pub root@centos04
#选择 yes
#输入登录第一台节点的密码(操作完成该节点公钥复制到第一台节点中)
(7) 配置环境变量
vim /etc/profile
export JAVA_HOME=/opt/apps/jdk1.8.0_141
export MVN_HOME=/opt/apps/apache-maven-3.6.3
export HADOOP_HOME=/opt/apps/hadoop-3.1.3
export PATH=$PATH:$JAVA_HOME/bin:$MVN_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
(8)hdfs 启动与停止
第一次启动得先格式化(最好不要复制):
hdfs namenode -format
修改sbin/start-dfs.sh和sbin/stop-dfs.sh,在文件头加入以下内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# 启动hdfs
start-dfs.sh
(9)开放9870端口(如果防火墙没有关闭)
添加永久开放的端口
firewall-cmd --add-port=9870/tcp --permanent
firewall-cmd --reload
访问页面:http://192.168.42.104:9870/

2.2.3 spark 3.2.2单机版安装
Spark 3.x安装, 采用本地模式运行, 直接解压, 配置环境变量即可, 直接运行spark-shell
下载地址:https://archive.apache.org/dist/spark/spark-3.2.2/
或者 wget https://archive.apache.org/dist/spark/spark-3.2.2/spark-3.2.2-bin-hadoop3.2.tgz
上传解压
[root@centos04 apps]# tar -zxvf spark-3.2.2-bin-hadoop3.2.tgz
mv /opt/apps/spark-3.2.2-bin-hadoop3.2 /opt/apps/spark-3.2.2
配置环境变量
export SPARK_HOME=/opt/apps/spark-3.2.2
export PATH=$PATH:$JAVA_HOME/bin:$MVN_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin
在spark 的conf文件夹下面,复制一个spark-env.sh 从spark-env.sh.template
[root@centos04 conf]# cp spark-env.sh.template spark-env.sh
# 增加下面配置
JAVA_HOME=/opt/apps/jdk1.8.0_141
SCALA_HOME=/opt/apps/scala-2.12.10
HADOOP_CONF_DIR=/opt/apps/hadoop-3.1.3/etc/hadoop
本地模式启动spark-shell
[root@centos04 spark-3.2.2]# bin/spark-shell --master local[2]
# 使用SparkContext读取文件
scala> val datasRDD = sc.textFile("/datas/hello.txt")
datasRDD: org.apache.spark.rdd.RDD[String] = /datas/hello.txt MapPartitionsRDD[1] at textFile at <console>:23
scala> datasRDD.first
res0: String = hello hudi
# 使用SparkSession对象spark, 加载读取文本数据, 封装至DataFrame中
scala> val df = spark.read.textFile("/datas/hello.txt")
df: org.apache.spark.sql.Dataset[String] = [value: string]
scala> df.show(10)
+----------+
| value|
+----------+
|hello hudi|
+----------+
2.3 hudi集成spark
| Hudi | Supported Spark 3 version |
|---|---|
| 0.12.x | 3.3.x,3.2.x, 3.1.x |
| 0.11.x | 3.2.x(default build, Spark bundle only),3.1.x |
| 0.10.x | 3.1.x(default build), 3.0.x |
| 0.7.0-0.9.0 | 3.0.x |
集成spark,其实就是将上述编译好的安装包拷贝到spark下的jars目录中。
cp /opt/apps/hudi-0.12.0/packaging/hudi-spark-bundle/target/hudi-spark3.2-bundle_2.12-0.12.0.jar /opt/apps/spark-3.2.2/jars
注意:启动Spark之前需要启动Hadoop等相关组件。
当然hudi也能和hive和flink进行集成,后续会进行详细讲解。
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
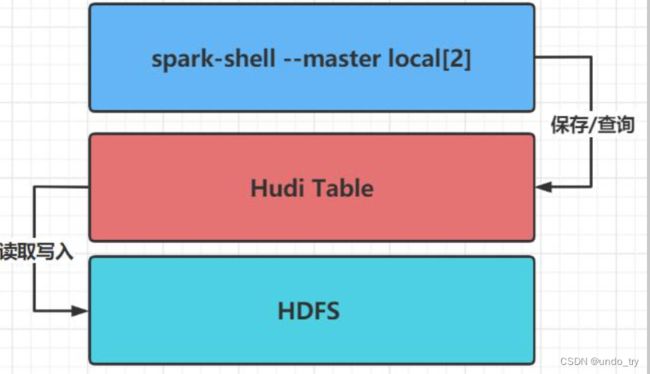
模拟产生Trip乘车交易数据, 将其保存至Hudi表, 并且从Hudi表加载数据查询分析, 其中Hudi表数据最后存储在HDFS分布式文件系统上。
数据格式如下:
{
"ts":1620884930573,
"uuid":"24d44a55-861c-446c-91d2-bcd2140b696a",
"rider":"rider-213",
"driver":"driver-213",
"begin_lat":0.4726905879569653,
"begin_lon":0.46157858458465484,
"end_lat":0.754803407008858,
"end_lon":0.9671159942018241,
"fare":34.158284716382845,
"partitionpath":"americas/brazi1/sao_paulo"
}
// 1、导入Spark及Hudi相关包和定义变量( 表的名称和数据存储路径)
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "hdfs://centos04:9000/datas/hudi_warehouse/hudi_trips_cow"
val dataGen = new DataGenerator
// 2、构建DataGenerator对象, 用于模拟生成Trip乘车数据
val inserts = convertToStringList(dataGen.generateInserts(10))
// 3、将模拟数据List转换为DataFrame数据集
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
// 4、查看转换后DataFrame数据集的Schema信息
scala> df.printSchema
root
|-- begin_lat: double (nullable = true)
|-- begin_lon: double (nullable = true)
|-- driver: string (nullable = true)
|-- end_lat: double (nullable = true)
|-- end_lon: double (nullable = true)
|-- fare: double (nullable = true)
|-- partitionpath: string (nullable = true)
|-- rider: string (nullable = true)
|-- ts: long (nullable = true)
|-- uuid: string (nullable = true)
// 5、选择相关字段, 查看模拟样本数据
scala> df.select("rider","begin_lat","begin_lon","driver","fare","uuid","ts").show(10,truncate=false)
+---------+-------------------+-------------------+----------+------------------+------------------------------------+-------------+
|rider |begin_lat |begin_lon |driver |fare |uuid |ts |
+---------+-------------------+-------------------+----------+------------------+------------------------------------+-------------+
|rider-213|0.4726905879569653 |0.46157858450465483|driver-213|34.158284716382845|cd091690-1d1c-4cfb-b290-c38cf79e87a7|1677011467102|
|rider-213|0.6100070562136587 |0.8779402295427752 |driver-213|43.4923811219014 |ca3398be-7961-4e3f-930a-0f3c4270b415|1677091129046|
|rider-213|0.5731835407930634 |0.4923479652912024 |driver-213|64.27696295884016 |909b447c-862d-4a68-a9f6-68460d15b636|1677404054380|
|rider-213|0.21624150367601136|0.14285051259466197|driver-213|93.56018115236618 |44abf3ac-66e2-4ef0-aa6f-d430378cbd32|1677550687265|
|rider-213|0.40613510977307 |0.5644092139040959 |driver-213|17.851135255091155|a207d41e-31d6-4a42-ba63-bcadb2762cc7|1677370705207|
|rider-213|0.8742041526408587 |0.7528268153249502 |driver-213|19.179139106643607|a348f842-e1d8-433c-93e2-552cba4f457c|1677514697541|
|rider-213|0.1856488085068272 |0.9694586417848392 |driver-213|33.92216483948643 |6df14949-1ff8-44f0-a0f3-988e697e96d2|1677549020097|
|rider-213|0.0750588760043035 |0.03844104444445928|driver-213|66.62084366450246 |b4c63ebb-6948-4f29-8f21-cd3a2c406d44|1677334842602|
|rider-213|0.651058505660742 |0.8192868687714224 |driver-213|41.06290929046368 |d9931660-4c89-4b11-acb9-7e41314335da|1677463651335|
|rider-213|0.11488393157088261|0.6273212202489661 |driver-213|27.79478688582596 |6a2a7929-e5ee-408a-89f7-5240a3cb36ff|1677404116132|
+---------+-------------------+-------------------+----------+------------------+------------------------------------+-------------+
// 6、将模拟产生Trip数据, 保存到Hudi表中, 由于Hudi诞生时基于Spark框架, 所以SparkSQL支持Hudi数据源, 直接通过format指定数据源Source, 设置相关属性保存数据即可
df.write
.format("hudi")
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(RECORDKEY_FIELD_OPT_KEY, "uuid")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath")
.option(TABLE_NAME, tableName)
.mode(Overwrite)
.save(basePath)
保存相关参数解释


- 数据保存成功以后, 查看HDFS文件系统目录: /datas/hudi-warehouse/hudi_trips_cow, 结构如下:

- 可以发现Hudi表数据存储在HDFS上, 以PARQUET列式方式存储的
// 从Hudi表中读取数据, 同样采用SparkSQL外部数据源加载数据方式, 指定format数据源和相关参数options
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
// 其中指定Hudi表数据存储路径即可, 采用正则Regex匹配方式, 由于保存Hudi表属于分区表, 并且为三级分区( 相当于Hive中表指定三个分区字段) , 使用表达式: /*/*/*/* 加载所有数据。
// 打印获取Hudi表数据的Schema信息
// 比原先保存到Hudi表中数据多5个字段, 这些字段属于Hudi管理数据时使用的相关字段。
scala> tripsSnapshotDF.printSchema()
root
|-- _hoodie_commit_time: string (nullable = true) // 数据提交时间
|-- _hoodie_commit_seqno: string (nullable = true) // 数据提交序列号
|-- _hoodie_record_key: string (nullable = true) // 主键
|-- _hoodie_partition_path: string (nullable = true) // 数据所在的存储路径
|-- _hoodie_file_name: string (nullable = true) // 数据所在的文件名称
|-- begin_lat: double (nullable = true)
|-- begin_lon: double (nullable = true)
|-- driver: string (nullable = true)
|-- end_lat: double (nullable = true)
|-- end_lon: double (nullable = true)
|-- fare: double (nullable = true)
|-- partitionpath: string (nullable = true)
|-- rider: string (nullable = true)
|-- ts: long (nullable = true)
|-- uuid: string (nullable = true)

// 将获取Hudi表数据DataFrame注册为临时视图, 采用SQL方式依据业务查询分析数据
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
// 查询乘车费用 大于 20 信息数据
scala> spark.sql("select fare,begin_lat,begin_lon,ts from hudi_trips_snapshot where fare > 20.0 ").show()
+------------------+-------------------+-------------------+-------------+
| fare| begin_lat| begin_lon| ts|
+------------------+-------------------+-------------------+-------------+
| 33.92216483948643| 0.1856488085068272| 0.9694586417848392|1677240304028|
| 93.56018115236618|0.21624150367601136|0.14285051259466197|1677494796495|
| 27.79478688582596|0.11488393157088261| 0.6273212202489661|1677113892502|
| 64.27696295884016| 0.5731835407930634| 0.4923479652912024|1677467198277|
| 66.62084366450246| 0.0750588760043035|0.03844104444445928|1677565096889|
| 43.4923811219014| 0.6100070562136587| 0.8779402295427752|1677599222877|
|34.158284716382845| 0.4726905879569653|0.46157858450465483|1677268476998|
| 41.06290929046368| 0.651058505660742| 0.8192868687714224|1677499817269|
+------------------+-------------------+-------------------+-------------+
至此, 完成将数据保存Hudi表, 及从Hudi进行加载数据分析操作
Hudi 如何管理数据?
使用表Table形式组织数据, 并且每张表中数据类似Hive分区表, 按照分区字段划分数据到不同目录中,每条数据有主键PrimaryKey, 标识数据唯一性。
2.4 初识hudi数据管理
2.4.1 hudi表数据结构
[root@centos04 tmp]# hdfs dfs -ls /datas/hudi_warehouse/hudi_trips_cow/
Found 3 items
drwxr-xr-x - root supergroup 0 2023-03-01 00:00 /datas/hudi_warehouse/hudi_trips_cow/.hoodie
drwxr-xr-x - root supergroup 0 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/americas
drwxr-xr-x - root supergroup 0 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/asia
-
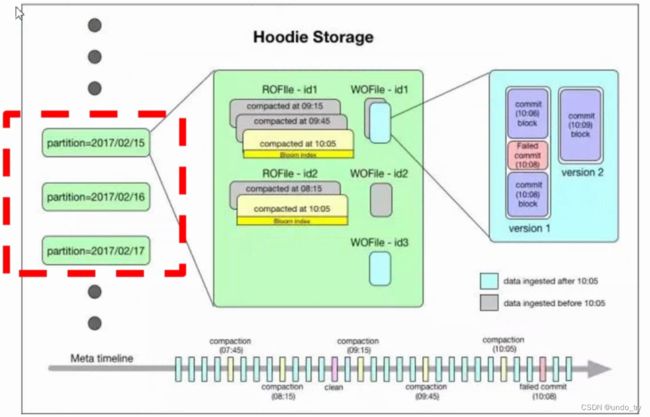
Hudi表的数据文件, 可以使用操作系统的文件系统存储, 也可以使用HDFS这种分布式的文件系统存储。 为了后续分
析性能和数据的可靠性, 一般使用HDFS进行存储。 以HDFS存储来看, 一个Hudi表的存储文件分为两类。 -
.hoodie 文件: 由于CRUD的零散性, 每一次的操作都会生成一个文件, 这些小文件越来越多后, 会严重影响HDFS的
性能, Hudi设计了一套文件合并机制。 .hoodie文件夹中存放了对应的文件合并操作相关的日志文件。 -
amricas和asia相关的路径是实际的数据文件,
按分区存储, 分区的路径key是可以指定的。
2.4.2 .hoodie 文件
Hudi把随着时间流逝, 对表的一系列CRUD操作叫做Timeline, Timeline中某一次的操作, 叫做Instant。
-
Instant Action, 记录本次操作是一次数据提交( COMMITS),还是文件合并(COMPACTION)或者是文件清理( CLEANS)
-
Instant Time, 本次操作发生的时间
-
State, 操作的状态, 发起(REQUESTED), 进行中(INFLIGHT), 还是已完成(COMPLETED)
.hoodie文件夹中存放对应操作的状态记录:
[root@centos04 tmp]# hdfs dfs -ls /datas/hudi_warehouse/hudi_trips_cow/.hoodie
Found 9 items
drwxr-xr-x - root supergroup 0 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/.hoodie/.aux
drwxr-xr-x - root supergroup 0 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/.hoodie/.schema
drwxr-xr-x - root supergroup 0 2023-03-01 00:00 /datas/hudi_warehouse/hudi_trips_cow/.hoodie/.temp
-rw-r--r-- 1 root supergroup 6624 2023-03-01 00:00 /datas/hudi_warehouse/hudi_trips_cow/.hoodie/20230228235948186.commit
-rw-r--r-- 1 root supergroup 0 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/.hoodie/20230228235948186.commit.requested
-rw-r--r-- 1 root supergroup 4334 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/.hoodie/20230228235948186.inflight
drwxr-xr-x - root supergroup 0 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/.hoodie/archived
-rw-r--r-- 1 root supergroup 819 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/.hoodie/hoodie.properties
drwxr-xr-x - root supergroup 0 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/.hoodie/metadata
2.4.3 数据文件
Hudi真实的数据文件使用Parquet文件格式存储
[root@centos04 tmp]# hdfs dfs -ls /datas/hudi_warehouse/hudi_trips_cow/asia/india/chennai
Found 2 items
-rw-r--r-- 1 root supergroup 96 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/asia/india/chennai/.hoodie_partition_metadata
-rw-r--r-- 1 root supergroup 437642 2023-02-28 23:59 /datas/hudi_warehouse/hudi_trips_cow/asia/india/chennai/58a0e589-0449-4216-80ad-7ae9135c90cf-0_2-28-36_20230228235948186.parquet
- 其中包含一个metadata元数据文件和数据文件parquet列式存储。
- Hudi为了实现数据的CRUD, 需要能够唯一标识一条记录, Hudi将把数据集中的
唯一字段(record key )+数据所在分区 (partitionPath)联合起来当做数据的唯一键。
2.4.4 数据存储概述
-
Hudi数据集的组织目录结构与Hive表示非常相似,
一份数据集对应这一个根目录。数据集被打散为多个分区, 分区字段以文件夹形式存在, 该文件夹包含该分区的所有文件。 -
在根目录下, 每个分区都有唯一的分区路径, 每个分区数据存储在多个文件中。
-
每个文件都有惟一的fileId和生成文件的commit所标识。 如果发生更新操作时, 多个文件共享相同的fileId, 但会有不同的commit。
-
以时间轴( timeline) 的形式将数据集上的各项操作元数据维护起来, 以支持数据集的瞬态视图, 这部分元数据存储于根目录下的元数据目录。 一共有三种类型的元数据:
- Commits: 一个单独的commit包含对数据集之上一批数据的一次原子写入操作的相关信息。 我们用单调递增的时间戳来标识
commits, 标定的是一次写入操作的开始。 - Cleans: 用于清除数据集中不再被查询所用到的旧版本文件的后台活动。
- Compactions: 用于协调Hudi内部的数据结构差异的后台活动。 例如, 将更新操作由基于行存的日志文件归集到列存数据上。
- Commits: 一个单独的commit包含对数据集之上一批数据的一次原子写入操作的相关信息。 我们用单调递增的时间戳来标识
-
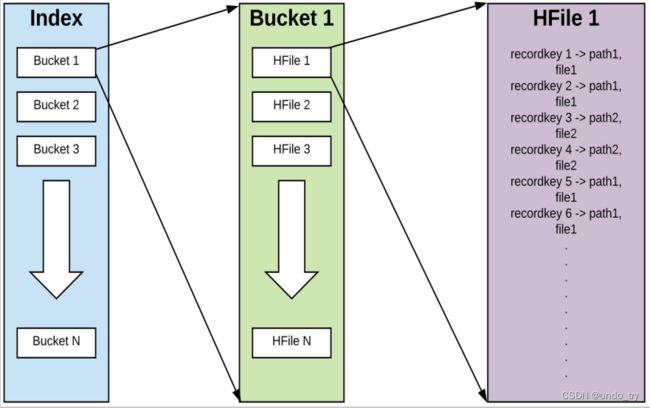
Hudi维护着一个索引, 以支持在记录key存在情况下, 将新记录的key快速映射到对应的fileId。
- Bloom filter: 存储于数据文件页脚。 默认选项, 不依赖外部系统实现。 数据和索引始终保持一致。
- Apache HBase : 可高效查找一小批key。 在索引标记期间, 此选项可能快几秒钟。
-
Hudi以两种不同的存储格式存储所有摄取的数据, 用户可选择满足下列条件的任意数据格式:
- 读优化的列存格式( ROFormat) :缺省值为Apache Parquet;
- 写优化的行存格式( WOFormat) :缺省值为Apache Avro;

2.5 使用IDEA进行开发
Apache Hudi最初是由Uber开发的, 旨在以高效率实现低延迟的数据库访问。 Hudi 提供了Hudi 表的概念, 这些表支持CRUD操作, 基于Spark框架使用Hudi API 进行读写操作。
创建Maven Project工程, 添加Hudi及Spark相关依赖jar包
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>hudi-startartifactId>
<groupId>com.yydsgroupId>
<version>1.0-SNAPSHOTversion>
parent>
<modelVersion>4.0.0modelVersion>
<artifactId>hudi-sparkartifactId>
<properties>
<scala.version>2.12.10scala.version>
<scala.binary.version>2.12scala.binary.version>
<spark.version>3.2.2spark.version>
<hadoop.version>3.1.3hadoop.version>
<hudi.version>0.12.0hudi.version>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-spark3.2-bundle_${scala.binary.version}artifactId>
<version>${hudi.version}version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.4.1version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.83version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.0.0version>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
<configuration>
<archive>
<manifest>
manifest>
archive>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
project>
将HDFS Client配置文件放入工程Project的resources目录下, 方便将Hudi表数据存储HDFS上
2.5.1 插入数据
package com.yyds.hudi
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* 使用官方QuickstartUtils提供模拟产生Trip数据, 模拟100条交易Trip乘车数据,
* 将其转换为DataFrame数据集,保存至Hudi表中, 代码基本与spark-shell命令行一致
*/
object HudiSparkInsert {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","root")
// 创建sparkSQL的运行环境
val conf = new SparkConf().setAppName("insertDatasToHudi").setMaster("local[2]")
val spark = SparkSession.builder().config(conf)
// 设置序列化方式:Kryo
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//定义变量:表名,数据存储路径
val tableName : String = "tb1_trips_cow"
val tablePath : String = "/datas/hudi_warehouse/tb1_trips_cow"
//引入相关包
import spark.implicits._
import scala.collection.JavaConversions._
// 第1步、模拟乘车数据
import org.apache.hudi.QuickstartUtils._
val generator: DataGenerator = new DataGenerator()
val insertDatas = convertToStringList(generator.generateInserts(100))
val insertDF: DataFrame = spark.read.json(spark.sparkContext.parallelize(insertDatas, 2).toDS())
// insertDF.printSchema()
// insertDF.show(2)
//第2步、将数据插入到hudi表
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
insertDF.write
.format("hudi")
.mode(SaveMode.Overwrite)
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性值设置
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), tableName)
.save(tablePath)
//关闭
spark.stop()
}
}
2.5.2 查询数据
package com.yyds.hudi
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object _02_HudiSparkQuery {
def main(args: Array[String]): Unit = {
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val basePath = "/datas/hudi_warehouse/tb1_trips_cow"
val tripsSnapshotDF = sparkSession
.read
.format("hudi")
.load(basePath)
// 时间旅行查询写法一
// sparkSession.read.
// format("hudi").
// option("as.of.instant", "20230228141108200").
// load(basePath)
//
// 时间旅行查询写法二
// sparkSession.read.
// format("hudi").
// option("as.of.instant", "2023-02-28 14:11:08.200").
// load(basePath)
//
// 时间旅行查询写法三:等价于"as.of.instant = 2023-02-28 00:00:00"
// sparkSession.read.
// format("hudi").
// option("as.of.instant", "2023-02-28").
// load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
sparkSession
.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0")
.show()
}
}
2.5.3 更新数据
package com.yyds.hudi
import org.apache.hudi.QuickstartUtils._
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
object _03_HudiSparkUpdate {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","root")
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val spark = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val tableName = "hudi_trips_cow"
val basePath = "/datas/hudi_warehouse/tb1_trips_cow"
val dataGen = new DataGenerator
// 官方提供工具类DataGenerator模拟生成更新update数据时, 必须要与模拟生成插入insert数据使用同一个DataGenerator对象
// 插入数据
val insertDatas = convertToStringList(dataGen.generateInserts(100))
val insertDF: DataFrame = spark.read.json(spark.sparkContext.parallelize(insertDatas, 2))
insertDF.write
.format("hudi")
.mode(SaveMode.Overwrite)
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性值设置
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), tableName)
.save(basePath)
// 更新数据
val updates = convertToStringList(dataGen.generateUpdates(50))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi")
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), tableName)
.mode(Append)
.save(basePath)
}
}
2.5.4 增量查询
-
当Hudi中表的类型为: COW(写时赋值)时, 支持2种方式查询: Snapshot Queries、 Incremental Queries;
-
默认情况下查询属于: Snapshot Queries快照查询, 通过参数: hoodie.datasource.query.type 可以进行设置。
-
如果是incremental增量查询, 需要指定时间戳, 当Hudi表中数据满足: instant_time > beginTime时, 数据将会被加载读取。 此外, 可设置某个时间范围: endTime > instant_time > begionTime, 获取相应的数据。

package com.yyds.hudi
import org.apache.hudi.DataSourceReadOptions._
import org.apache.spark.SparkConf
import org.apache.spark.sql._
/**
* 增量查询
首先从Hudi表加载所有数据, 获取其中字段值: _hoodie_commit_time, 从中选取一个值, 作为增量查询:beginTime开始时间; 再次设置属性参数, 从Hudi表增量查询数据。
*/
object _04_HudiSparkIncrQuery {
def main(args: Array[String]): Unit = {
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val basePath = "/datas/hudi_warehouse/tb1_trips_cow"
import sparkSession.implicits._
// 1、加载hudi表数据,获取commitTime时间,作为增量查询的时间阈值
sparkSession.read
.format("hudi")
.load(basePath)
.createTempView("hudi_trips_snapshot")
val commits: Array[String] = sparkSession.sql(
"""
|
|select
| distinct(_hoodie_commit_time) as commitTime
|from hudi_trips_snapshot
|order by commitTime
|
|""".stripMargin
).map(k => k.getString(0))
.take(50)
// 阈值
val beginTime: String = commits(commits.length - 2)
// 2、设置Hudi数据commitTime时间阈值,进行增量查询数据
val tripsIncrementalDF = sparkSession
.read
.format("hudi")
.option(QUERY_TYPE.key(), QUERY_TYPE_INCREMENTAL_OPT_VAL) // 设置增量查询模式
.option(BEGIN_INSTANTTIME.key(), beginTime) // 增量读取开始时间
.load(basePath)
// 3、将增量查询的数据注册为临时视图,查询乘车费用大于20的数据信息
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
sparkSession.sql(
"""
|
|select
| `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts
|from hudi_trips_incremental
|where fare > 20.0
|
|
|""".stripMargin).show()
}
}
2.5.5 删除数据
使用DataGenerator数据生成器, 基于已有数据构建要删除的数据, 最终保存到Hudi表中, 需要设置属性参数:
hoodie.datasource.write.operation 值为: delete。
package com.yyds.hudi
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.QuickstartUtils._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.spark.SparkConf
import org.apache.spark.sql.SaveMode._
import org.apache.spark.sql._
/**
* 删除数据
*/
object _05_HudiSparkDelete {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","root")
// 创建 SparkSession
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val spark = SparkSession.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
val tableName = "hudi_trips_cow"
val basePath = "/datas/hudi_warehouse/hudi_trips_cow"
val dataGen = new DataGenerator
// 1、加载Hudi表数据,获取数据的条数
spark
.read
.format("hudi")
.load(basePath)
.createOrReplaceTempView("hudi_trips_snapshot")
val cnt: Long = spark.sql(
"""
|
|select
| uuid, partitionpath
|from hudi_trips_snapshot
|""".stripMargin).count()
println(s"beforeCount = ${cnt}")
// 2、模拟要删除的数据
val ds = spark.sql(
"""
|
|select
| uuid, partitionpath
|from hudi_trips_snapshot
|
|""".stripMargin).limit(5)
import scala.collection.JavaConverters._
val deletes: java.util.List[String] = dataGen.generateDeletes(ds.collectAsList())
val df = spark.read.json(spark.sparkContext.parallelize(deletes.asScala, 2))
// 3、保存数据到hudi,设置操作类型为DELETE
df.write.format("hudi")
.options(getQuickstartWriteConfigs)
.option(OPERATION.key(), "delete")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), tableName)
.mode(Append)
.save(basePath)
// 4、再次加载表数据,统计数目
val roAfterDeleteViewDF = spark
.read
.format("hudi")
.load(basePath)
roAfterDeleteViewDF.createOrReplaceTempView("hudi_trips_sp")
// 返回的总行数应该比原来少2行
val afterCnt: Long = spark.sql("select uuid, partitionpath from hudi_trips_sp").count()
println(s"afterCnt = ${afterCnt}")
}
}