思维链(Chain-of-Thought)作为提示
来自:ICI NLP
论文题目: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
论文链接:https://arxiv.org/abs/2201.11903
作者:Jason Wei Xuezhi Wang Dale Schuurmans Maarten Bosma Brian Ichter Fei Xia Ed H. Chi Quoc V. Le Denny Zhou
机构:Google
这篇论文出自google的资深研究科学家Jason Wei,这个人呢大家猜一下他的年纪,2020年本科毕业,每年发N篇的顶会论文,相当厉害,自古英雄出少年。
首先在这里提出个问题:大家对大模型是怎么看的?对prompt的理解。
Background
在NLP领域,这几年模型的大小是越来越大,几亿参数量现在都只能算小模型,只有1000亿以上,比如GPT3 175B这种算是大模型,那大模型的好处显而易见:
推理能力强,采样效率高,因为模型参数大,能储存很多的知识。
但是大模型在做arithmetic, commonsense, and symbolic reasoning 推理时的表现还不够好。最近几年有学者通过构建这种推理的中间过程,来简化推理取得了比较好的效果,而入股我们所知大模型的in-context few shot能力也是极强的。
但问题就是创建很多的中间步骤用来做监督finetune是非常耗时的,而且传统的prompt方式在数学计算、常识推理等做的又不好,怎么结合in-context few shot 和 中间步骤来改善arithmetic, commonsense, and symbolic reasoning等推理能力是一个问题。
Motivation
这篇论文非常简单。非常非常简单。
Motivation就是结合in-context few-shot prompting 以及多步中间推理,通过大模型来改善数学计算、常识推理的效果。如下图所示

和传统的prompt相比呢,COT的区别在于在答案之间多了中间推到的逻辑推理过程。也就是从x->y 变成了 x-chain-of-thought,y
Chain-of-Thought Prompting
COT思维链的灵感来源于人做推理的过程,比如
1.Jane has 12 flowers
2.After Jane gives 2 flowers to her mom she has 10
3.Then after she gives 3 to her dad she will have 7
4. So the answer is 7
作者借鉴了这个过程,通过设计类似于思维链来激发大模型,使之拥有推理能力,并且能由于这个有逻辑性的思维链的存在,多步的中间推到可以得到最终的正确答案。
这里我们可以看几个例子

Arithmetic Reasoning计算推理
这里我列举了作者要用来比较的大语言模型Language models.
•GPT-3 (OpenAI) text-ada-001, text-babbage-001, text-curie-001, and text-davinci-002 350M, 1.3B, 6.7B, and 175B parameters
•LaMDA (Google) 422M, 2B, 8B, 68B, and 137B parameters.
•PaLM (Google) 8B, 62B, and 540B parameters.
•UL2 (Google) 20B parameters.
•Codex (OpenAI) code-davinci-002 175B parameters.
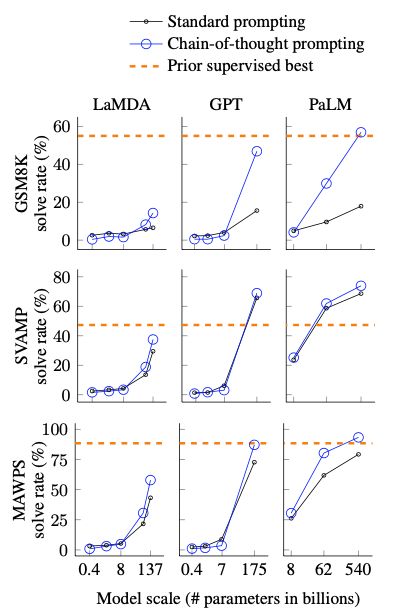
这要的实验结论就是:100B(1000亿参数)参数量以下的模型效果不好,侧面反映了他们的instruct fine-tune不够,COT很难激发他的in-context 推理能力。而在100B以上模型效果很好,甚至超过了之前基于监督训练的SOTA模型。
这里有一个问题:是大模型在参数量大了之后拥有了COT的能力,还是通过instruct fine-tune给大模型注入了这个能力?值得考究。
如何给小模型注入这种能力是一个待解决的问题!
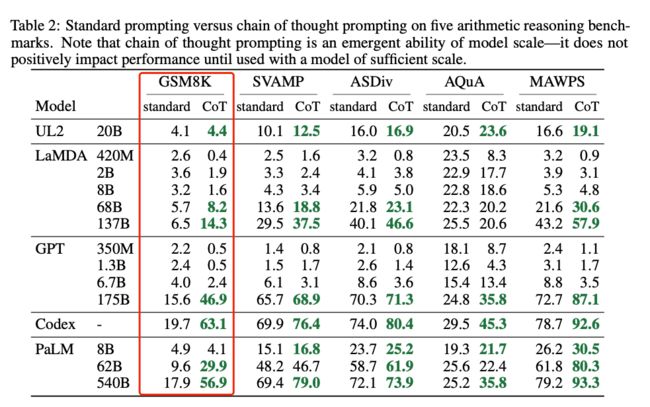
作者说在GSM8K(数学解题)的推理比较复杂,可以看到之前基于监督训练最好的baseline也只有55%正确率,在用了COT之后,在大模型上提升比较明显,特别是Codex + COT可以达到63.1。

但是在单步的数据集MAWPS上,这里列了只有单步运算、一个等式、加减,COT的prompt方式比之前没有什么提升。
作者在GSM8K上,基于LaMDA 137B输出的结果,分别挑选了50个正确/错误的例子:对于正确的例子,作者分析只有一个是通过不对的推理,最后得到了正确的答案。

在所有错误的例子里,计算错误占了8%,符号错误占了16%,少了一步运算的占了22%,入下面这个例子就属于明显的计算错误。
Ablation Study
作者也针对性的做了几组ablation study,第一组如果我们把逻辑推理过程简单地改成等式会怎么样呢,从作者的实验看,效果不会比传统的prompt好,会比COT效果变差,说明了COT的推理是重要的。


有人攻击COT肯定是花了更多的精力在复杂推理上,因此作者这里做了一个验证就是往prompt里加入和那些等式长度相同的点号,发现效果也不好,说明了并非设想的那样,增加了长度之后效果不会变好。
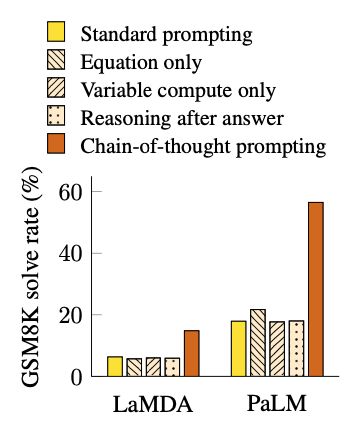
最后一个就是呢:为了回答中间推理过程的顺序是否重要,有意义,作者把答案和推理过程更换了顺序,让模型先输入结果,再来做中间推理过程,发现这样做对效果不会有帮助。
那么这里的一些列操作说明了,prompt的设计非常重要,怎么能更好的激发模型输出比较好的效果。
为此呢,作者还验证了如果写作风格会不会对效果会有影响,如下图
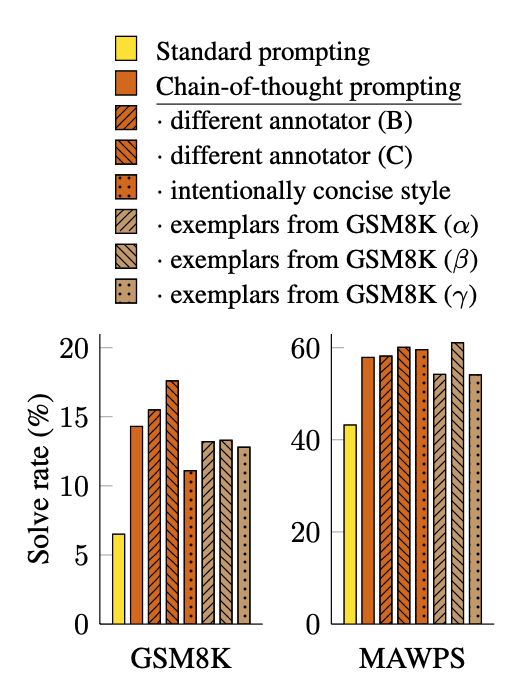
作者首先是邀请了作者其他的两个作者编写了COT的范式,发现呢写作风格对效果影响不大;然后呢他又测试从GSM8K中随机选择8个范例,然后发现范例不同对效果影响虽然有,但也不会太大,还是会明显好于传统的prompt。不同的模型对于COT prompt的反应也是不一样的,例如Palm和GPT3.
Commonsense Reasoning
尝试推理包含哪些 CSQA,会问一些世界性的问题,比如美国的首都是哪,这种? StrategyQA:是多hop的推理,比如 梨子在水里会沉吗?他的推理过程是计算梨子的密度和水的密度,梨子密度小于水的密度,所以不会沉 Date:根据给的文本内容来推理时间 Sports:比如推理法国对是否是2022年世界杯冠军 Saycan是用户输入一个需求,比如给我带点吃的,不要披萨,推理过程是我有汉堡,汉堡不是披萨,所以返回结果是给用户汉堡。

从实验结果呢,我们看出COT的效果在CSQA和StrategyQA上超过了基于监督学习的SITA模型,甚至在Sports上超过了人类的水平,这还挺惊艳的。
Symbolic Reasoning
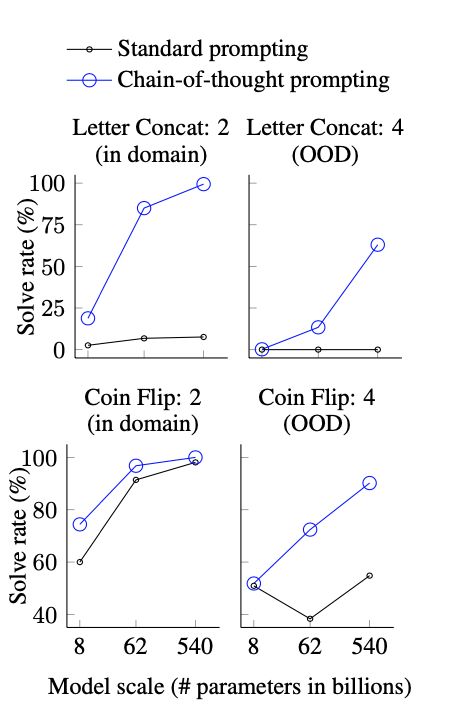
最后一个任务是符号推理,第一个任务是Last letter concatenation,把一个人的名字缩写拼接起来。
“Amy Brown” → “yn”
第二个任务是Coin flip,也就是多次抛掷硬币,然后推理正反:
A coin is heads up. Phoebe flips the coin. Osvaldo does not flip the coin. Is the coin still heads up?
从下图我们可以看出,COT可以轻松击败传统的Prompt形式
Conclusions
这篇论文的实验呢仅仅依靠few shot prompting,没有微调,作者通过实验证明了COT可以激发100B以上模型的推理能力,但是也留下了几个问题:
1. 如果继续扩大模型,效果还会变好吗?
2. 还有其他更好的prompt方法吗
3. 怎么说明模型确实在做推理
4. 是否有比手动写prompt更好的方式
5. 怎么确保推理path的正确性
6. 怎么在小模型上实现类似的效果
看完这篇论文呢,对我的冲击比较大,我以前并不会觉得此类论文是论文,感觉像是博客文章。再就是对大模型的看法发生了转变,以前觉得大模型是头部几家机构玩的,普通人没有机会玩,更别说发论文了,这篇论文给了大家启发。怎么解决上面提的6个问题,值得探讨。
如果这就是趋势,去勇敢的接受他,不要被浪潮抛弃。
现在大家对这个怎么看?
最后给大家推荐一下最近小编从最新的斯坦福NLP的公开课都放到了bilibili上了,都已做了中英翻译,大部分已经更新完毕了,给需要的小伙伴~
是最新的呦~
目录
词向量
神经分类器
反向传播和神经网络
句法结构
RNN
LSTM
机器翻译、Seq2Seq和注意力机制
自注意力和Transformer
Transformers和预训练
问答
自然语言生成
指代消解
T5和大型预训练模型
待更...
点击阅读原文直达b站~
进NLP群—>加入NLP交流群