SELECT COUNT(*) 会造成全表扫描?
前言
相信很多人都会有个疑问,针对无 where_clause 的 COUNT(*),MySQL 是有优化的,优化器会选择成本最小的辅助索引查询计数,其实反而性能最高,这种说法对不对呢?
实列说明
首先,我们先准备一个表(以下操作基于 MySQL8.0)
CREATE TABLE `person` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`score` int(11) NOT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `name_score` (`name`(191),`score`),
KEY `create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 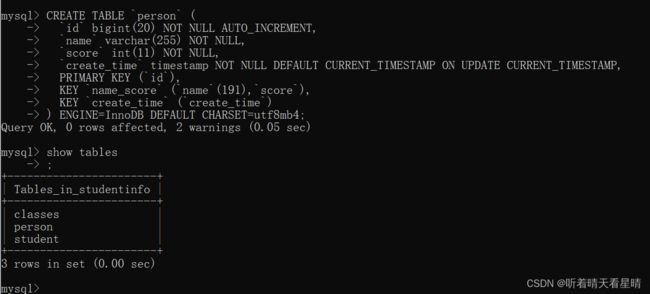
这个表除了主键索引之外,还有另外两个索引, name_score 及 create_time。然后我们在此表中插入 10 w 行数据,只要写一个存储过程调用即可,如下:
create procedure insert_person()
begin
declare i int;
set i=1;
START TRANSACTION;
while(i<=100000)do
insert into person values(i, concat('name',i), i+100, date_sub(NOW(), interval i second));
set i=i+1;
end while;
commit;
end;然后查看是否存在当前创建的存储过程:
show procedure status;结果:

调用该存储过程:
call insert_person();插入之后我们现在使用 EXPLAIN 来计算下统计总行数到底使用的是哪个索引:
EXPLAIN SELECT COUNT(*) FROM person 
从结果上看它选择了 create_time 辅助索引,显然 MySQL 认为使用此索引进行查询成本最小,这也是符合我们的预期,使用辅助索引来查询确实是性能最高的!可以总结出:
发现确实此条语句在此例中用到的并不是主键索引,而是辅助索引,实际上在此例中我试验了,不管是 COUNT(1),还是 COUNT(*),MySQL 都会用成本最小的辅助索引查询方式来计数,也就是使用 COUNT(*) 由于 MySQL 的优化已经保证了它的查询性能是最好的!随带提一句,COUNT(*)是 SQL92 定义的标准统计行数的语法,并且效率高,所以请直接使用COUNT(*)查询表的行数!所以这种说法确实是对的。但有个前提,在 MySQL 5.6 之后的版本中才有这种优化。
那么这个成本最小该怎么定义呢,有时候在 WHERE 中指定了多个条件,为啥最终 MySQL 执行的时候却选择了另一个索引,甚至不选索引?
SQL 选用索引的执行成本如何计算:
就如前文所述,在有多个索引的情况下, 在查询数据前,MySQL 会选择成本最小原则来选择使用对应的索引,这里的成本主要包含两个方面。
-
IO 成本: 即从磁盘把数据加载到内存的成本,默认情况下,读取数据页的 IO 成本是 1,MySQL 是以页的形式读取数据的,即当用到某个数据时,并不会只读取这个数据,而会把这个数据相邻的数据也一起读到内存中,这就是有名的程序局部性原理,所以 MySQL 每次会读取一整页,一页的成本就是 1。所以 IO 的成本主要和页的大小有关
-
CPU 成本:将数据读入内存后,还要检测数据是否满足条件和排序等 CPU 操作的成本,显然它与行数有关,默认情况下,检测记录的成本是 0.2
我们再来看以下 SQL 会使用哪个索引
SELECT * FROM person WHERE NAME >'name84059' AND create_time>'2023-03-18 12:36:46' 
用了range范围扫描!说明从 WHERE 的查询条件来看确实都能命中索引,但是mysql选择使用的是name_score索引,我们覆盖索引使用creat_time索引进行执行,并对比一下两种查询的效率
explain SELECT create_time FROM person force index(create_time) WHERE NAME >'name84059' AND create_time>'2023-03-18 12:36:46';
两条sql执行时间如图所示:

我们发现mysql使用的name_score的效率要高
总结
本文通过一个例子深入剖析了 MySQL 的执行计划是如何选择的,以及为什么它的选择未必是我们认为的最优的,这也提醒我们,在生产中如果有多个索引的情况,使用 WHERE 进行过滤未必会选中你认为的索引,我们可以提前使用 EXPLAIN, optimizer trace 来优化我们的查询语句。