Verilog基础:casex和full_case、parallel_case的使用
相关文章
Verilog基础:表达式位宽的确定(位宽拓展)
Verilog基础:表达式符号的确定
Verilog基础:数据类型
Verilog基础:位宽拓展和有符号数运算的联系
Verilog基础:case、casex、casez语句
Verilog基础:task和function的使用(一)
Verilog基础:task和function的使用(二)
Verilog基础:表达式中的整数常量(integer)
目录
1.casex的误用
2.casez的误用
3.full_case和parallel_case
3.1 full_case
3.2 不是full的case语句
3.3 是full的case语句
3.4 使用full_case综合指令
3.5 full_case综合指令的缺点
3.6 使用full_case后还是综合出latch
3.7 parallel_case
3.8 不是parallel_case的case语句
3.9 是parallel的case语句
3.9 是parallel的case语句
3.10 parallel_case综合指令的缺点
3.11 没有必要的parallel_case
4. case语句的编码原则
1.casex的误用
casex会导致设计出现问题,因为casex把x当做“不关心”(z同理),不管x是出现在casex的case expression还是case item中。当case expression中出现x,这时就会发生问题,因为前仿真时casex语句不关心case expression中的x,代表着有x的位不参与和case item匹配,此时仅匹配非x的位。而后仿真时,门级模型中并没有不确定值x,结果一定是1或0中的一个,这就导致可能进入不期望分支中去。
下面的code6模块是一个带有enable信号的地址译码器。前仿真时,有的时候,初始化还没有进入有效的状态,外部接口的设计错误会导致enable信号变为x值。当enable为x时,casex会根据addr的值错误匹配一个case item。如果你没有仔细观察enable的值,你可能会认为电路是正常的,enable这时是有效的,输出也是对的。直到后仿真时,enable此时取值为x,则x会在门级电路中传播,输出就会发生改变,这就导致了前后仿真的不确定。
例1 casex导致了前后仿真的不一致
module code6 (memce0, memce1, cs, enable, addr);
output reg memce0, memce1, cs;
input enable;
input [31:30]addr;
always@(*)begin
{memce0, memce1, cs} = 3'b0;
casex({addr, enable})
3'b101: memce0 = 1'b1;
3'b111: memce1 = 1'b1;
3'b0?1: cs = 1'b1;
endcase
end
endmodule举个例子来说,如果前仿真时因为某种原因,enable为1,而addr为2‘bx0,此时memce0会被置位,但如果你看的不仔细,而是根据输出想当然地认为addr此时为2‘b10,或者此时输入addr恰好也应该是2‘b10,就会在后仿真出现问题。后仿真时,x会在门级模型中传播,甚至可能导致输出全为x。
2.casez的误用
casez也会导致与casex类似的问题,就是当case expression中出现了z时,因为前仿真在计算casez语句把z值当做“不关心",这种问题一般在验证时一般不会被忽略。在设计某些高效的逻辑时,使用casez可以写出更加简洁的代码,比如优先级编码器和地址译码器等,所以工程师在设计有用的代码时,casez不应该被取消。
下面的例子与code6一样,只不过这里使用了casez。当case espression中某些信号变为z时,根据其他的输入,错误的匹配就会发生。但是比起casex(z,x都不关心),casez(不关心z)引发错 误匹配的概率小些。所以要小心使用casez,避免出现匹配z的错误。
例2 使用casez语句
module code7 (memce0, memce1, cs, enable, addr);
output reg memce0, memce1, cs;
input enable;
input [31:30]addr;
always@(*)begin
{memce0, memce1, cs} = 3'b0;
casez({addr, enable})
3'b101: memce0 = 1'b1;
3'b111: memce1 = 1'b1;
3'b0?1: cs = 1'b1;
endcase
end
endmodule3.full_case和parallel_case
在verilog中有两条经常使用又饱受指责综合指令://synopsys full_case和//synopsys parallel_case。他们有这样的神话:这两条指令会使设计变得更小更快,而且不会生成latch。这其实根本不对,事实上它们可能对设计毫无影响,甚至把设计变得更大更慢,会使设计晦涩难懂,会综合出latch。这两条指令还会使前后仿真不一致,如果在门级仿真时没有发现这些不一致,就会导致带有问题的ASIC投片。
因此使用这两条指令是很危险的,要避免使用他们。下面详细讨论一下full_case和parallel_case的定义,以及他们对综合代码的影响。
3.1 full_case
full_case指每个可能的case expression的取值都有case item或default与之匹配。即使case语句没有包含default,如果每个case expression都能找到一个与之匹配的case item,那么还是full_case。
3.2 不是full的case语句
对于下面的三选一数据选择器,这里的case语句不是full,因为当sel=2‘b11时,没有对应的y输出赋值。在仿真时,当sel=2'b11时,y就锁存数据,它会保持最后赋值给y的值,而且综合工具会综合出latch。
例3 不是full的case语句
module mux3a(y, a, b, c, sel);
output reg y;
input [1:0]sel;
input a, b, c;
always@(*)
case (sel)
2'b00: y = a;
2'b01: y = b;
2'b10: y = c;
endcase
endmodule注意:case语句不完整并不一定会综合出锁存器, 如果对case_expression信号有所限制,不完整的case语句如果覆盖了所有取值可能,就也不会导致latch生成。
如何消除这个锁存器?可以赋初值,也可以使用default语句,具体见数字IC前端学习笔记:锁存器Latch的综合
3.3 是full的case语句
Verilog不要求case语句在综合或仿真时是full的,但是可以通过添加default使之变为full。对于下面的三选一数据选择器,因为使用了case default,所以这个case语句变为full。在仿真时,当sel为2‘b11时,y就被驱动到x,但在综合时,赋值x代表不关心(综合结果即可能是0,或者是1,甚至是和某个信号连到一起,综合工具看哪个节省逻辑,就用哪个),这就导致了前仿真和后仿真的不一致。为了保证一致性,可以在case default时给y赋一个常数值。
但是我们在设计FSM时,在case default处把next_state赋值为x,可以帮助调试假冒的状态转换,这样如果存在错误的转换,next_state就保持为x,state就会成为x,这样就很方便在波形图中看到。
例4 full的case语句,但会出现前后仿真不一致。
module mux3b(y, a, b, c, sel);
output reg y;
input [1:0]sel;
input a,b,c;
always@(*)
case (sel)
2'b00: y = a;
2'b01: y = b;
2'b10: y = c;
default: y = 1'bx;
//2'b11: y = 1'bx; 另一种方法,同样的效果
//default: y = 1'b0; 这样前后仿真一致
endcase
endmodule如果在case语句前给输出赋一个初始值,这样的话,即使case语句不完整,或者说不full,但依旧不会综合出latch。
例5 在case前面赋初始值,不会出现前后仿真不一致。
module mux3c(y, a, b, c, sel);
output reg y;
input [1:0]sel;
input a,b,c;
always@(*)
y = 1'b0;
case (sel)
2'b00: y = a;
2'b01: y = b;
2'b10: y = c;
endcase
endmodule3.4 使用full_case综合指令
当“//synopsys full_case”被加到case语句的头部时,在Verilog仿真时它没有影响,因为“//synopsys full_case”只被当做是注释。但是Synopsys的Design Complier会把所有“//synopsys”开头的注释解释为综合指令。full_case的作用是,如果case语句不是full的,那么对于所有没有出现的case item,输出就按照“不关心”处理,如果case语句包括default项,那么full_case指令就被忽略。
对于下面的三选一选择器,里面的case语句是不full的,但是在case语句头上加了一条“full_case”指令,综合工具就会把他当做是full的,不会综合出锁存器,就好像加了一句default:y=1'bx一样的效果。在Verilog前仿真时,当sel=2‘b11时,输出y表现为一个Latch,但当综合时,综合工具把Sel=2'b11时的输出当做“不关心”,此时的输出由6合工具决定(看怎样节省逻辑),这会导致前后仿真不一致。
例6 使用full_case综合指令
module mux3d(y, a, b, c, sel);
output reg y;
input [1:0]sel;
input a, b, c;
always@(*)
case(sel) //synopsys full_case
2'b00 : y = a;
2'b01 : y = b;
2'b10 : y = c;
endcase
endmodule以下两图分别是没有和有full_case综合指令的综合结果。
无full_case综合指令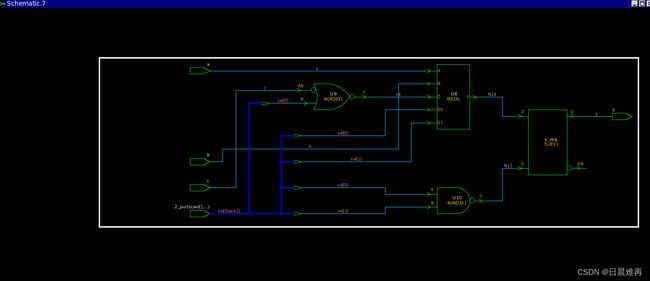
有full_case综合指令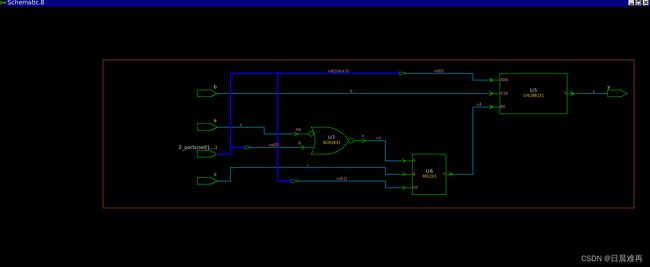
3.5 full_case综合指令的缺点
综合指令“//synopsys full_case”只用于综合工具,而没有作用于仿真工具。这个特殊的指令被用于告诉综合工具case语句是完整的,对于那些无用的case输出赋值是不关心的。如果使用这条指令,综合前后的功能可能会不一样。另外虽然这个指令告诉综合器不用关心那些无用的状态,但是比起不用full_case指令来说,这个指令有时会让设计变得又大又慢。
在code4a中,case语句没有使用任何综合指令,最后输出的逻辑是由3-input与门和反相器组成的译码器,前后仿真是一致的。在code4b中,case语句使用了full_case指令,所以en输入在综合时被优化掉,变成了dangling(悬挂)输入。code4a和code4b的前仿真是一致的,但是code4b的前后仿真不一致。注意,当在case item expression出现的所有信号,在未定义的输入下,都是不关心的,如果出现了向量的变量索引,如y[a],则y的各位信号都是不关心的;如果只出现了常量索引,则出现的这些位是不关心的。
例7 没有使用full_case,前后仿真是一致的
module code4a(y, a, en);
output reg [3:0]y;
input [1:0]a;
input en;
always@(*)begin
y=4'h0;
case({en, a})
3'b100: y[a] = 1'b1;
3'b101: y[a] = 1'b1;
3'b110: y[a] = 1'b1;
3'b111: y[a] = 1'b1;
endcase
end
endmodule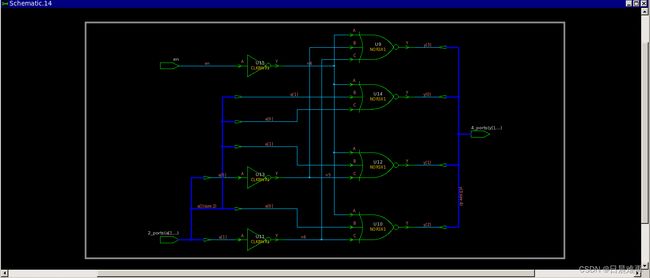
例8 使用full_case,前后仿真是不一致
module code4b(y, a, en);
output reg [3:0]y;
input [1:0]a;
input en;
always@(*)begin
y=4'h0;
case({en, a}) //synopsys full_case
3'b100: y[a] = 1'b1;
3'b101: y[a] = 1'b1;
3'b110: y[a] = 1'b1;
3'b111: y[a] = 1'b1;
endcase
end
endmodule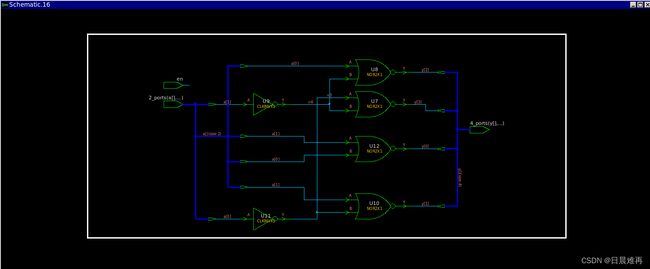
3.6 使用full_case后还是综合出latch
有这样的神话,‘’//synopsys full_case”能消除case语句中的所有latch。如果case语句不加full_case,综合会生成latch,那么使用full_case后,就可以消除它们。
事实上,这次错误的,或者说是不完备的。如果在case语句中,存在对多个输出的赋值,而在某些case item后赋值不完整,即使此时case语句是full的或者有default语句,都会综合出锁存器,即使加上了full_case综合指令。
例如,下面简单的地址译码器就会为mce0_n、mce1_n和rce_n生成latch。虽然这个语句上使用了full_case,但是由于在每个case_item里不是对所有的输出做了赋值,所以就会为所有的输出综合出latch。消除这种latch的方式也很简单,将对所有输出的赋值补充完整或在always块开始时为所有输出赋初值。
例9 即使有full_case,依旧综合出latch
module addrDecode1a(mce0_n, mce1_n, rce_n, addr);
output reg mce0_n, mce1_n, rce_n;
input [31:30] addr;
always@(*)
//{mce1_n, mce0_n,rce_n} = 3'b0;
casez(addr) //synopsys full_case
2'b10: {mce1_n, mce0_n} = 2'b10;
2'b11: {mce1_n, mce0_n} = 2'b01;
2'b0?: rce_n = 1'b0;
endcase
endmodule综合结果
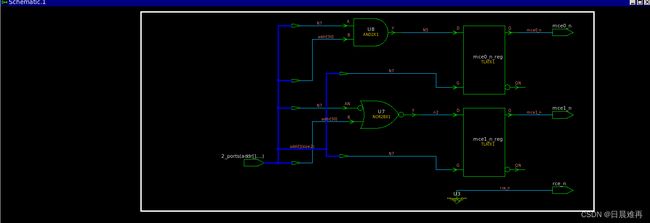
在always块后赋初值的综合结果
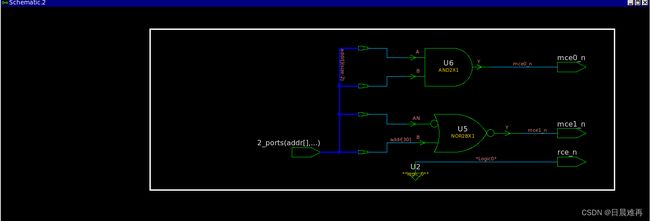
3.7 parallel_case
parallel_case语句是指case expression只能匹配一个case item的语句。如果发现case expression能够匹配超过1个的case item,那么这些匹配的case item被称为overlapping case item,这个case语句就不是parallel的。
3.8 不是parallel_case的case语句
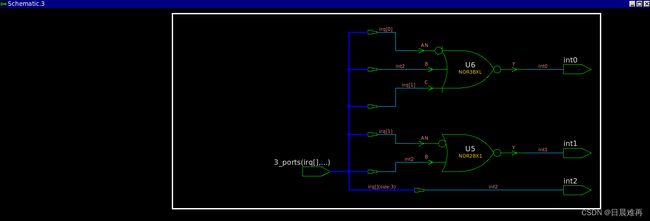
下面使用casez的例子就不是parallel的case语句,因为如果irq=3'b111、3'b101、3'b110或3'b111,就会有多于1个case item与irq匹配。这在仿真时就像一个优先级编码器,irq[2]的优先级最高,大于irq[1],而irq[1]大于irq[0]。这个例子在综合时也会推导出优先级编码器。
例10 不是parallel的case语句
module intctl1a(int2, int1, int0, irq);
output reg int2, int1, int0;
input [2:0] irq;
always@(*)begin
{int2, int1, int0} = 3'b0;
casez(irq)
3'b1??: int2=1'b1;
3'b?1?: int1=1'b1;
3'b??1: int0=1'b1;
endcase
end
endmodule综合结果如下,被展平了,所以看不到优先级结构,但int1想为1必须irq[2]为0,int0想为1必须irq[2]和irq[1]都为0。
3.9 是parallel的case语句
我们对上面的例子修改后得到如下代码,这里的每个case item都是独立的,所以是parallel的。
例11 是parallel的case语句
module intctl2a(int2, int1, int0, irq);
output reg int2, int1, int0;
input [2:0] irq;
always@(*)begin
{int2, int1, int0} = 3'b0;
casez(irq)
3'b1??: int2 = 1'b1;
3'b01?: int1 = 1'b1;
3'b001: int0 = 1'b1;
endcase
end
endmodule综合结果和上例一样。
3.9 是parallel的case语句
下面的例子是在case语句头部加上了“synopsys parallel _case”指令。这个例子在仿真时是按照优先级编码器仿真的,但是在综合时就推导出非优先级编码器。虽然综合时parallel_case指令发生了作用,但是这时前后仿真不一致。
例12 使用parallel_case综合指令,导致前后仿真不一致。
module intctl1b(int2, int1, int0, irq);
output reg int2, int1, int0;
input [2:0] irq;
always@(*)begin
{int2, int1, int0} = 3'b0;
casez(irq) //synopsys parallel_case
3'b1??: int2 = 1'b1;
3'b?1?: int1 = 1'b1;
3'b??1: int0 = 1'b1;
endcase
end
endmodule综合结果表示,此时输入输出直接相连,即如下图Verilog代码所示。

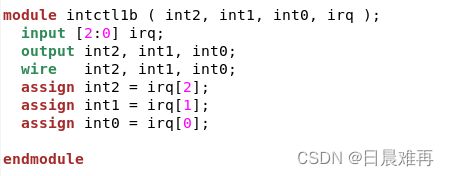
这表现出来的结果是,case语句失去了从上至下检查case item的能力,而是平行地检查所有case item 只要匹配,就平行地执行这些case item后面的statement。
3.10 parallel_case综合指令的缺点
综合指令“//synopsys parallel_case”只用于综合工具,而没有作用于仿真工具。这个特殊的指令用于告诉综合工具,所有的case item都是并行检查的,即使是存在可以推导出优先编码器,存在overlapping的情况下。这个指令有时会让设计变得又大又慢。
code5a和code5b模块的前仿真,code5a的前后仿真是一致的,都是按照优先级编码器工作,即只有在a,b不同时为1的情况下,y才可能为1。但是code5b的综合结果是两个与门,即只要a,b同时为1,z就为1;只要c,d同时为1,y就为1。这个并行结构导致了前后仿真不一致。
例13 不用paralle_case指令,前后仿真是一致的
module code5a(y, z, a, b, c, d);
output reg y, z;
input a, b, c, d;
always@(*)begin
{y, z} = 2'b0;
casez ({a, b, c, d})
4'b11??: z = 1;
4'b??11: y = 1;
endcase
end
endmodule综合结果
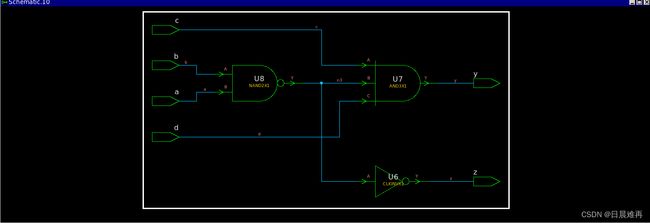 例14 使用parallel_case指令,导致前后仿真不一致
例14 使用parallel_case指令,导致前后仿真不一致
module code5b(y, z, a, b, c, d);
output reg y, z;
input a, b, c, d;
always@(*)begin
{y, z} = 2'b0;
casez ({a, b, c, d}) //synopsys parallel_case
4'b11??: z = 1;
4'b??11: y = 1;
endcase
end
endmodule综合结果
15
3.11 没有必要的parallel_case
下面的casez的例子本来就是parallel的,在case语句头加上parallel_case指令,实际没有多大意义,因为使用parallel_case综合出来的逻辑和不用parallel综合出来的逻辑是一样的。
例15 没有必要的parallel_case指令
module intctl2b(int2, int1, int0, irq);
output reg int2, int1, int0;
input [2:0] irq;
always@(*)begin
{int2, int1, int0} = 3'b0;
casez(irq) //synopsys parallel_case
3'b1??: int2 = 1'b1;
3'b01?: int1 = 1'b1;
3'b001: int0 = 1'b1;
endcase
end
endmodule所以当paralle_case起作用时,parallel_case是很危险的。当parallel_case不起作用时,那么它只是case语句头的额外字符罢了。
4. case语句的编码原则
下面是一些对于使用case语句、full_case和parallel_case指令的原则。
1. 对于编写表达式并行的设计,case语句是不错的选择,而且代码更加简洁清楚。
2. 在设计可综合的代码时,要小心使用casez语句,不要使用casex语句。
3. 要小心使用反向case语句,最好只针对parallel的case语句使用。
4. 要小心使用casez语句设计优先级结构,也可以使用if elsel if语句实现优先级结构,这样意图更明显。
5. 在使用casez语句时,用“?”表示不关心的位,最好不要使用“z”。
6. 最好为case语句添加default,而且不要把输出赋值为“x”,没有必要为了节省一点点的逻辑造成前后仿真的不一致。当然也可以在always块开始时给所有输出赋初值。
7. 通常情况下,不要使用“//synopsys full_case和parallel_case”。因为这两条指令只向综合工具提供了特定的信息,而没向仿真工具提供,很有可能造成前后仿真不一致。
8. 如果你非常明白这两条指令的工作机制,且明确自己的意图,那么可以使用这两条指令。
9. 最好只针对one hot FSM使用“//synopsys full_case”.
10. 检查综合工具输出的关于case语句的报告。当发现异常时,就要修改对应的case语句。
最后的结论是:当full_case和parallel_case综合指令起作用时,其实它们是最危险的。最好的方法是不去使用这两条指令,直接编写full和paralle的case语句。另外是小心使用casez和casex语句。
以上内容来源于《Verilog编程艺术》,有删改。