python内存泄漏浅析
一、概述
以前没有对内存泄漏有过相关的排查手段,一般个人使用python写的程序,不是那种长时间运行的程序,很少会去注意内存是否出现泄漏,但是如果程序是作为服务器的服务,需要长时间运行的,即使是很小的内存泄漏,最后也会特别明显。
对于 python 这种支持垃圾回收的语言来说,怎么还会有内存泄露? 概括来说,
有以下三种原因:
1、所用到的用 C 语言开发的底层模块中出现了内存泄露。
2、代码中用到了全局的 list、 dict 或其它容器,不停的往这些容器中插入对象,
而忘记了在使用完之后进行删除回收
3、代码中有“引用循环”,并且被循环引用的对象定义了del方法,就会发生内存泄
露。垃圾回收具体原理参见:Python的垃圾回收机制(引用计数) - 心系天下1 - 博客园
推荐三种调试Python内存泄漏利器:
memory-profiler、filprofiler、objgraph (https://mg.pov.lt/objgraph/)
二、现象
怎么判断是否存现内存泄漏呢?
简单的方法就是查看 程序占用的内存,从开始运行时记录占用的内存,持续观察一段时间,看内存是否持续在上升。
如linux系统中,可以使用top指令,查看某个进程RES值
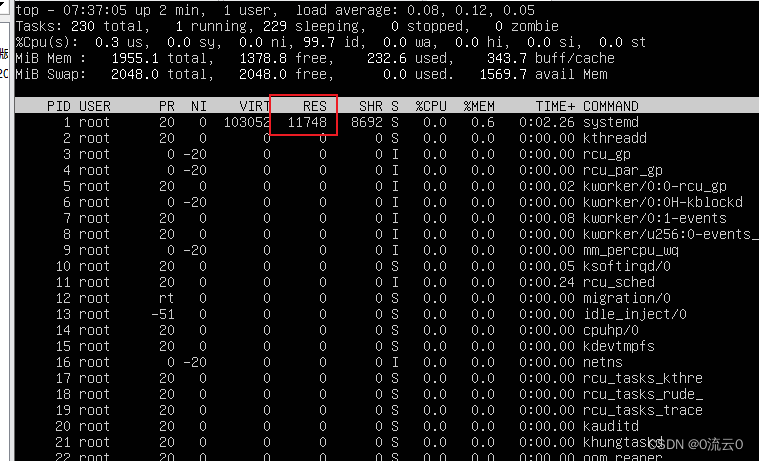
持续一两天观察,某个进程的RES内存占用是否持续升高。如果是docker的话,可以使用
docker stats 容器id 来查看当前容器的内存占用情况
![]()
三、调试
如果说已经确认是内存持续增长,那么我们就需要在python程序中加上一些日志或者利用上面说的工具来确认到底在哪里发生了泄漏,才能针对性的解决。
1、objgraph 具体使用参见官网:https://mg.pov.lt/objgraph/
比较常用的函数:
def count(typename)
返回该类型对象的数目,其实就是通过gc.get_objects()拿到所用的对象,然后统计指定类型的数目。
def by_type(typename)
返回该类型的对象列表。线上项目,可以用这个函数很方便找到一个单例对象
def show_most_common_types(limits = 10)
打印实例最多的前N(limits)个对象,这个函数非常有用。在《Python内存优化》一文中也提到,该函数能发现可以用slots进行内存优化的对象
def show_growth()
统计自上次调用以来增加得最多的对象,这个函数非常有利于发现潜在的内存泄露。函数内部调用了gc.collect(),因此即使有循环引用也不会对判断造成影响。
def show_backrefs()
生产一张有关objs的引用图,看出看出对象为什么不释放。
该API有很多有用的参数,比如层数限制(max_depth)、宽度限制(too_many)、输出格式控制(filename output)、节点过滤(filter, extra_ignore),建议使用之间看一些document。
def find_backref_chain(obj, predicate, max_depth=20, extra_ignore=()):
找到一条指向obj对象的最短路径,且路径的头部节点需要满足predicate函数 (返回值为True)
可以快捷、清晰指出 对象的被引用的情况
def show_chain():
将find_backref_chain 找到的路径画出来, 该函数事实上调用show_backrefs,只是排除了所有不在路径中的节点。
这里使用def show_growth() 来看下到底哪些类型的对象发生率泄漏,show_growth()
limit参数表示打印出最增加最多的对象的数量,file参数可不填写,不写直接在终端界面打印。
show_most_common_types() 打印实例最多的前N(limits)个对象
在程序最后加上以下代码,看下每次执行后的变化
import objgraph
curr_dir = os.path.dirname(os.path.abspath(__file__))
file_name = curr_dir + os.sep + 'objgraph.txt'
with open(file_name, "a", encoding='utf-8') as can:
can.write("-----------show_growth----------------\n")
objgraph.show_growth(limit=8, file=can)
can.write("----------show_most_common_types--------------\n")
objgraph.show_most_common_types(limit=8, file=can)效果:
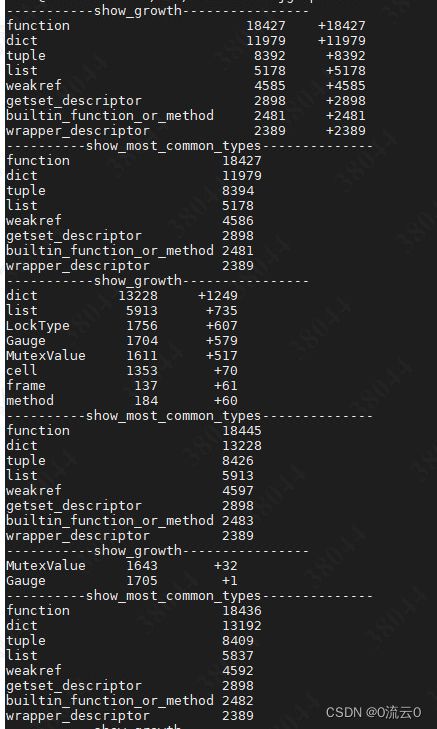
这里第一次执行,增加了较多的对象是正常的。主要看增量,长时间下来哪些类型的变量是持续增加的。
除了上面说的调试手段外,可以加一些日志去判断。比如,在有使用到多线程的编程中,怀疑是python多线程使用后未关闭,可以在程序最后加上线程数的打印
logger.debug(f"线程总数: {len(threading.enumerate())}")
logger.debug(f"threading.activeCount(): {threading.activeCount()}")持续一段时间后,如果是线程数量持续增加,那基本可以判定有线程泄漏
线程关闭可以参考:python线程关闭_0流云0的博客-CSDN博客
一种是使用 ctypes强制杀死的方法,这种方法有时候在linux中会失败,暂时没搞清楚原理。
另一种使用在线程函数中通过信号使用break的方法退出线程。
看是否线程关闭,除了上面的数量外,可以使用is_alive() 函数判断当前线程的状态,为False表示关闭成功。
status = my_thread.is_alive()
# my_thread是threading.Thread创建的线程对象
logger.info(f'线程状态: {status}')调用线程关闭后,最好等待一两秒才获取线程状态,因为有时候状态更新会有点慢。