大数据时代——生活、工作与思维的重大变革
最近读了维克托·迈尔 – 舍恩伯格的《大数据时代》,觉得有不少收获,让我这个大数据的小白第一次理解了大数据。
作者是大数据的元老级先驱。
放一张帅照,膜拜下。

不过这本书我本人不推荐从头读一遍,因为书中的核心理念并不是特别多,可以看看我这篇博客。
1 海量数据从何而来?
互联网的发展使世界彻底改变了,我们进入了信息爆炸的时代。
历史学家伊丽莎白·爱森斯坦(Elizabeth Eisenstein)发现,1453—1503年,这50年之间大约有800万本书籍被印刷,比1200年之前君士坦丁堡建立以来整个欧洲所有的手抄书还要多。换言之,欧洲的信息存储量花了50年才增长了一倍(当时的欧洲还占据了世界上相当部分的信息存储份额),而如今大约每三年就能增长一倍。谷歌公司每天要处理超过24拍字节[插图]的数据,这意味着其每天的数据处理量是美国国家图书馆所有纸质出版物所含数据量的上千背。

站访问记录、社交媒体数据、电子邮件、在线广告、金融交易数据、医疗记录、交通运输数据、能源消耗数据…
海量数据的时代来了!
2 大数据有什么价值——量变产生质变
大数据有什么价值呢,答案就是量变产生质变。
我们就以纳米技术为例。纳米技术专注于把东西变小而不是变大。其原理就是当事物到达分子的级别时,它的物理性质就会发生改变。一旦你知道这些新的性质,你就可以用同样的原料来做以前无法做的事情。铜本来是用来导电的物质,但它一旦到达纳米级别就不能在磁场中导电了。银离子具有抗菌性,但当它以分子形式存在的时候,这种性质会消失。一旦到达纳米级别,金属可以变得柔软,陶土可以具有弹性。同样,当我们增加所利用的数据量时,我们就可以做很多在小数据量的基础上无法完成的事情。

2009年甲型H1N1流感爆发的时候,与习惯性滞后的官方数据相比,谷歌成为了一个更有效、更及时的指示标。
在甲型H1N1流感爆发的几周前,互联网巨头谷歌公司的工程师们在《自然》杂志上发表了一篇引人注目的论文。它令公共卫生官员们和计算机科学家们感到震惊。文中解释了谷歌为什么能够预测冬季流感的传播:不仅是全美范围的传播,而且可以具体到特定的地区和州。谷歌通过观察人们在网上的搜索记录来完成这个预测,而这种方法以前一直是被忽略的。谷歌保存了多年来所有的搜索记录,而且每天都会收到来自全球超过30亿条的搜索指令,如此庞大的数据资源足以支撑和帮助它完成这项工作。
谷歌公司把5000万条美国人最频繁检索的词条和美国疾控中心在2003年至2008年间季节性流感传播时期的数据进行了比较。他们希望通过分析人们的搜索记录来判断这些人是否患上了流感,他们的预测与官方数据的相关性高达97%。和疾控中心一样,他们也能判断出流感是从哪里传播出来的,而且判断非常及时,不会像疾控中心一样要在流感爆发一两周之后才可以做到。

3 随机采样 VS 大数据
小数据时代科学家们采用随机采样,最少的数据获得最多的信息。统计学家们证明:采样分析的精确性随着采样随机性的增加而大幅提高,但与样本数量的增加关系不大。认为样本选择的随机性比样本数量更重要,这种观点是非常有见地的。随机采样取得了巨大的成功,成为现代社会、现代测量领域的主心骨。
但这只是一条捷径,是在不可收集和分析全部数据的情况下的选择,它本身存在许多固有的缺陷。它的成功依赖于采样的绝对随机性,但是实现采样的随机性非常困难。一旦采样过程中存在任何偏见,分析结果就会相去甚远。
2008年在奥巴马与麦凯恩之间进行的美国总统大选中,盖洛普咨询公司、皮尤研究中心(Pew)、美国广播公司和《华盛顿邮报》社这些主要的民调组织都发现,如果他们不把移动用户考虑进来,民意测试结果就会出现三个点的偏差,而一旦考虑进来,偏差就只有一个点。鉴于这次大选的票数差距极其微弱,这已经是非常大的偏差了。

更糟糕的是,随机采样不适合考察子类别的情况。因为一旦继续细分,随机采样结果的错误率会大大增加。这很容易理解。
你设想一下,一个对1000个人进行的调查,如果要细分到“东北部的富裕女性”,调查的人数就远远少于1000人了。即使是完全随机的调查,倘若只用了几十个人来预测整个东北部富裕女性选民的意愿,还是不可能得到精确结果啊!而且,一旦采样过程中存在任何偏见,在细分领域所做的预测就会大错特错。
随机采样就像是模拟照片打印,远看很不错,但是一旦聚焦某个点,就会变得模糊不清。
随机采样也需要严密的安排和执行。人们只能从采样数据中得出事先设计好的问题的结果——千万不要奢求采样的数据还能回答你突然意识到的问题。
大数据中的“大”不是绝对意义上的大,虽然在大多数情况下是这个意思。谷歌流感趋势预测建立在数亿的数学模型上,而它们又建立在数十亿数据节点的基础之上。完整的人体基因组有约30亿个碱基对。但这只是单纯的数据节点的绝对数量,并不代表它们就是大数据。大数据是指不用随机分析法这样的捷径,而采用所有数据的方法。谷歌流感趋势和乔布斯的医生们采取的就是大数据的方法。
大数据与乔布斯的癌症治疗
苹果公司的传奇总裁史蒂夫·乔布斯在与癌症斗争的过程中采用了不同的方式,成为世界上第一个对自身所有DNA和肿瘤DNA进行排序的人。为此,他支付了高达几十万美元的费用,这是23andme报价的几百倍之多。所以,他得到的不是一个只有一系列标记的样本,他得到了包括整个基因密码的数据文档。
对于一个普通的癌症患者,医生只能期望她的DNA排列同试验中使用的样本足够相似。但是,史蒂夫·乔布斯的医生们能够基于乔布斯的特定基因组成,按所需效果用药。如果癌症病变导致药物失效,医生可以及时更换另一种药,也就是乔布斯所说的,“从一片睡莲叶跳到另一片上。”乔布斯开玩笑说:“我要么是第一个通过这种方式战胜癌症的人,要么就是最后一个因为这种方式死于癌症的人。”虽然他的愿望都没有实现,但是这种获得所有数据而不仅是样本的方法还是将他的生命延长了好几年。

相比随机数据聚焦就模糊,大数据就不会有这样的困扰。可以用Lytro相机来打一个恰当的比方。Lytro相机是具有革新性的,因为它把大数据运用到了基本的摄影中。与传统相机只可以记录一束光不同,Lytro相机可以记录整个光场里所有的光,达到1100万束之多。具体生成什么样的照片则可以在拍摄之后再根据需要决定。用户没必要在一开始就聚焦,因为该相机可以捕捉到所有的数据,所以之后可以选择聚焦图像中的任一点。整个光场的光束都被记录了,也就是收集了所有的数据,“样本=总体”。因此,与普通照片相比,这些照片就更具“可循环利用性”。如果使用普通相机,摄影师就必须在拍照之前决定好聚焦点。

4.拥抱更混乱的世界
在越来越多的情况下,使用所有可获取的数据变得更为可能,但为此也要付出一定的代价。数据量的大幅增加会造成结果的不准确,与此同时,一些错误的数据也会混进数据库。
我们从不认为这些问题是无法避免的,而且也正在学会接受它们。
大数据时代要求我们重新审视精确性的优劣.假设你要测量一个葡萄园的温度,但是整个葡萄园只有一个温度测量仪,那你就必须确保这个测量仪是精确的而且能够一直工作。反过来,如果每100棵葡萄树就有一个测量仪,有些测试的数据可能会是错误的,可能会更加混乱,但众多的读数合起来就可以提供一个更加准确的结果。因为这里面包含了更多的数据,而它不仅能抵消掉错误数据造成的影响,还能提供更多的额外价值。
无所不包的谷歌翻译系统
2006年,谷歌公司也开始涉足机器翻译。这被当作实现“收集全世界的数据资源,并让人人都可享受这些资源”这个目标的一个步骤。谷歌翻译开始利用一个更大更繁杂的数据库,也就是全球的互联网,而不再只利用两种语言之间的文本翻译。
谷歌翻译系统为了训练计算机,会吸收它能找到的所有翻译。它会从各种各样语言的公司网站上寻找对译文档,还会去寻找联合国和欧盟这些国际组织发布的官方文件和报告的译本。它甚至会吸收速读项目中的书籍翻译。谷歌翻译部的负责人弗朗兹·奥齐(Franz Och)是机器翻译界的权威,他指出,“谷歌的翻译系统不会像Candide一样只是仔细地翻译300万句话,它会掌握用不同语言翻译的质量参差不齐的数十亿页的文档。”不考虑翻译质量的话,上万亿的语料库就相当于950亿句英语。
尽管其输入源很混乱,但较其他翻译系统而言,谷歌的翻译质量相对而言还是最好的,而且可翻译的内容更多。到2012年年中,谷歌数据库涵盖了60多种语言,甚至能够接受14种语言的语音输入,并有很流利的对等翻译。之所以能做到这些,是因为它将语言视为能够判别可能性的数据,而不是语言本身。如果要将印度语译成加泰罗尼亚语,谷歌就会把英语作为中介语言。因为在翻译的时候它能适当增减词汇,所以谷歌的翻译比其他系统的翻译灵活很多。

混乱还可以指格式的不一致性,因为要达到格式一致,就需要在进行数据处理之前仔细地清洗数据,而这在大数据背景下很难做到。
当我们上传照片到Flickr网站的时候,我们会给照片添加标签。也就是说,我们会使用一组文本标签来编组和搜索这些资源。人们用自己的方式创造和使用标签,所以它是没有标准、没有预先设定的排列和分类,也没有我们必须遵守的类别的。任何人都可以输入新的标签,标签内容事实上就成为了网络资源的分类标准。标签被广泛地应用于Facebook、博客等社交网络上。因为它们的存在,互联网上的资源变得更加容易找到,特别是像图片、视频和音乐这些无法用关键词搜索的非文本类资源。
5.原因真的很重要吗
知道“是什么”就够了,没必要知道“为什么”。在大数据时代,我们不必非得知道现象背后的原因,而是要让数据自己“发声”。
FICO,“我们知道你明天会做什么”
一个人的信用常被用来预测他/她的个人行为。美国个人消费信用评估公司,也被称为FICO,在20世纪50年代发明了信用分。2011年,FICO提出了“遵从医嘱评分”——它分析一系列的变量来确定这个人是否会按时吃药,包括一些看起来有点怪异的变量。比方说,一个人在某地居住了多久,这个人结婚了没有,他多久换一个工作以及他是否有私家车。这个评分会帮助医疗机构节省开支,因为它们会知道哪些人需要得到它们的用药提醒。有私家车和使用抗生素并没有因果关系,这只是一种相关关系。但是这就足够激发FICO的首席执行官扬言,“我们知道你明天会做什么。”这是他在2011年的投资人大会上说的。
大数据从来不care因果关系,而是相关关系。相关关系很有用,不仅仅是因为它能为我们提供新的视角,而且提供的视角都很清晰。而我们一旦把因果关系考虑进来,这些视角就有可能被蒙蔽掉。
Kaggle,一家为所有人提供数据挖掘竞赛平台的公司,举办了关于二手车的质量竞赛。二手车经销商将二手车数据提供给参加比赛的统计学家,统计学家们用这些数据建立一个算法系统来预测经销商拍卖的哪些车有可能出现质量问题。相关关系分析表明,橙色的车有质量问题的可能性只有其他车的一半。
当我们读到这里的时候,不禁也会思考其中的原因。难道是因为橙色车的车主更爱车,所以车被保护得更好吗?或是这种颜色的车子在制造方面更精良些吗?还是因为橙色的车更显眼、出车祸的概率更小,所以转手的时候,各方面的性能保持得更好?

6.一切皆可量化
我们往往忽视数据的价值,认为某些数据不需要。但数据其实可以从看上去最不可能的东西中提取出来。
日本先进工业技术研究所的坐姿研究与汽车防盗系统
日本先进工业技术研究所(Japan’s Advanced Institute of Industrial Technology)的教授越水重臣(Shigeomi Koshimizu)所做的研究就是关于一个人的坐姿。很少有人会认为一个人的坐姿能表现什么信息,但是它真的可以。当一个人坐着的时候,他的身形、姿势和重量分布都可以量化和数据化。越水重臣和他的工程师团队通过在汽车座椅下部安装总共360个压力传感器以测量人对椅子施加压力的方式。把人体屁股特征转化成了数据,并且用从0~256这个数值范围对其进行量化,这样就会产生独属于每个乘坐者的精确数据资料。
在这个实验中,这个系统能根据人体对座位的压力差异识别出乘坐者的身份,准确率高达98%。
这个研究并不愚蠢。这项技术可以作为汽车防盗系统安装在汽车上。有了这个系统之后,汽车就能识别出驾驶者是不是车主;如果不是,系统就会要求司机输入密码;如果司机无法准确输入密码,汽车就会自动熄火。把一个人的坐姿转化成数据后,这些数据就孕育出了一些切实可行的服务和一个前景光明的产业。比方说,通过汇集这些数据,我们可以利用事故发生之前的姿势变化情况,分析出坐姿和行驶安全之间的关系。这个系统同样可以在司机疲劳驾驶的时候发出警示或者自动刹车。同时,这个系统不但可以发现车辆被盗,而且可以通过收集到的数据识别出盗贼的身份。

7.数据化,而不是数字化
数字化和数据化的差异是什么?回答这个问题很容易,我们来看一个两者同时存在并且起作用的领域就可以理解了,这个领域就是书籍。2004年,谷歌发布了一个野心勃勃的计划:它试图把所有版权条例允许的书本内容进行数字化,让世界上所有的人都能通过网络免费阅读这些书籍。为了完成这个伟大的计划,谷歌与全球最大和最著名的图书馆进行了合作,并且还发明了一个能自动翻页的扫描仪,这样对上百万书籍的扫描工作才切实可行且不至于太过昂贵。
刚开始,谷歌所做的是数字化文本,每一页都被扫描然后存入谷歌服务器的一个高分辨率数字图像文件中。书本上的内容变成了网络上的数字文本,所以任何地方的任何人都可以方便地进行查阅了。然而,这还是需要用户要么知道自己要找的内容在哪本书上,要么必须在浩瀚的内容中寻觅自己需要的片段。因为这些数字文本没有被数据化,所以它们不能通过搜索词被查找到,也不能被分析。谷歌所拥有的只是一些图像,这些图像只有依靠人的阅读才能转化为有用的信息。

8.价值"取之不尽,用之不竭"的数据创新
数据就像一个神奇的钻石矿,当它的首要价值被发掘后仍能不断给予。它的真实价值就像漂浮在海洋中的冰山,第一眼只能看到冰山的一角,而绝大部分都隐藏在表面之下。
2000年,22岁大学刚毕业的路易斯·冯·安(Luis Von Ahn)发明了验证码。这使他能够在取得博士学位后进入卡内基梅隆大学工作,教授计算机科学;也使他在27岁时获得了50万美元的麦克阿瑟基金会“天才奖”。但是,当他意识到每天有这么多人要浪费10秒钟的时间输入这堆恼人的字母,而随后大量的信息被随意地丢弃时,他并没有感到自己很聪明。
他很快找到了用户输入的验证码信息的第二个用途:破译数字化文本中不清楚的单词。
他创建了一个新项目ReCaptcha。和原有随机字母输入不同,人们需要从计算机光学字符识别程序无法识别的文本扫描项目中读出两个单词并输入。其中一个单词其他用户也识别过,从而可以从该用户的输入中判断注册者是人;另一个单词则是有待辨识和解疑的新词。为了保证准确度,系统会将同一个模糊单词发给五个不同的人,直到他们都输入正确后才确定这个单词是对的。ReCaptcha的作用得到了认可,2009年谷歌收购了冯·安的公司,并将这一技术用于图书扫描项目。

数据重组是发掘数据价值的重要办法。随着大数据的出现,数据的总和比部分更有价值。当我们将多个数据集的总和重组在一起时,重组总和本身的价值也比单个总和更大
丹麦癌症协会:手机是否增加致癌率
丹麦拥有1985年手机推出以来所有手机用户的数据库。这项研究分析了1990年至2007年间拥有手机的用户(企业用户和其他社会经济数据不可用的用户除外),共涉及358403人。该国同时记录了所有癌症患者的信息,在那期间共有10729名中枢神经系统肿瘤患者。结合这两个数据集后,研究人员开始寻找两者的关系:手机用户是否比非手机用户显示出较高的癌症发病率?使用手机时间较长的用户是否比时间较短的用户更容易患上癌症?
尽管研究的规模很大,数据却没有出现丝毫混乱或含糊不清。为了满足医疗或商业的目的,两个数据集都采用了严格的质量标准,信息的收集不存在偏差。事实上,数据是在多年前就已经生成的,当时的目的与这项研究毫不相关。最重要的是,这项研究并没有基于任何样本,却很接近“样本=总体”的准则,即包括了几乎所有癌症患者和移动用户。数据包含了所有的情况,这意味着研究人员掌握了各种亚人群组信息,比如吸烟人群。
最后,研究没有发现使用移动电话和癌症风险增加之间存在任何关系。因此,当2011年10月研究结果在《英国医学杂志》上发布时,并未在媒体中引起任何轰动。但是如果两者之间存在关联的话,它可能马上就会登上世界各地的头版头条,而“重组数据”也可能会随之名声大噪。

促成数据再利用的方法之一是从一开始就设计好它的可扩展性。
例如,有些零售商在店内安装了监控摄像头,这样不仅能认出商店扒手,还能跟踪在商店里购物的客户流和他们停留的位置。零售商利用后面的信息可以设计店面的最佳布局并判断营销活动的有效性。

数据的折旧值是很值得关注的。随着时间的推移,大多数数据都会失去一部分基本用途。在这种情况下,继续依赖于旧的数据不仅不能增加价值,实际上还会破坏新数据的价值。
比如十年前你在亚马逊买了一本书,而现在你可能已经对它完全不感兴趣。如果亚马逊继续用这个数据来向你推荐其他书籍,你就不太可能购买带有这类标题的书籍,甚至会担心该网站之后的推荐是否合理。这些推荐的依据既有旧的过时的信息又有近期仍然有价值的数据,而旧数据的存在破坏了新数据的价值。
而且很多看似没有用处的数据,我们将其称为数据废气,其实可能有意向不到的用处。
巴诺与NOOK快照
电子书阅读器捕捉了大量关于文学喜好和阅读人群的数据:读者阅读一页或一节需要多长时间,读者是略读还是直接放弃阅读,读者是否画线强调或者在空白处做了笔记,这些他们都会记录下来。这就将阅读这种长期被视为个人行为的动作转换成了一种共同经验。一旦聚集起来,数据废气可以用量化的方式向出版商和作者展示一些他们可能永远都不会知道的信息,如读者的好恶和阅读模式。这是十分具有商业价值的。电子图书出版公司可以将这些信息卖给出版商,从而帮助改进书籍的内容和结构。例如,巴诺通过分析Nook电子阅读器的数据了解到,人们往往会弃读长篇幅的非小说类书籍。公司从中受到启发,从而推出“Nook快照”,加入了一系列健康和时事等专题的短篇作品。

开放数据会给数据创新带来更多可能性。
2008年1月21日,奥巴马总统在就职的第一天发表了一份总统备忘录,命令美国联邦机构的负责人公布尽可能多的数据,这使开放政府数据的想法取得了极大的进展。“面对怀疑,公开优先。”他这样指示道。这真是一个了不起的声明,特别是与那些作出相反指令的前任们相比。奥巴马的指令促成了data.gov网站的建立,这是美国联邦政府的公开信息资料库。网站从2009年的47个数据集迅速发展起来,到2012年7月三周年时,数据集已达45万个左右,涵盖了172个机构。
9.谁会成为大数据时代最大的获利者
如今,我们正处在大数据时代的早期,思维和技术是最有价值的,但是最终大部分的价值还是必须从数据本身中挖掘。
根据所提供价值的不同来源,分别出现了三种大数据公司。这三种来源是指:数据本身、技能与思维。
第一种是基于数据本身的公司。这些公司拥有大量数据或者至少可以收集到大量数据,却不一定有从数据中提取价值或者用数据催生创新思想的技能。最好的例子就是Twitter,它拥有海量数据这一点是毫无疑问的,但是它的数据都通过两个独立的公司授权给别人使用。

第二种是基于技能的公司。它们通常是咨询公司、技术供应商或者分析公司。它们掌握了专业技能但并不一定拥有数据或提出数据创新性用途的才能。比方说,沃尔玛和Pop-Tarts这两个零售商就是借助天睿公司(Teradata)的分析来获得营销点子,天睿就是一家大数据分析公司。

第三种是基于思维的公司。皮特·华登(Pete Warden),Jetpac的联合创始人,就是通过想法获得价值的一个例子。Jetpac通过用户分享到网上的旅行照片来为人们推荐下次旅行的目的地。对于某些公司来说,数据和技能并不是成功的关键。让这些公司脱颖而出的是其创始人和员工的创新思维,他们有怎样挖掘数据的新价值的独特想法。

10.什么是大数据思维
所谓大数据思维,是指一种意识,认为公开的数据一旦处理得当就能为千百万人急需解决的问题提供答案。
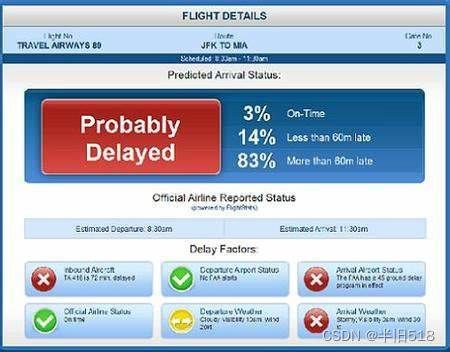
布拉德福德·克罗斯(Bradford Cross)用拟人手法解释了什么是有大数据思维。2009年8月,也就是在他20多岁的时候,他和四个朋友一起创办了FlightCaster.com。和FlyOnTime.us类似,这个网站致力于预测航班是否会晚点。它主要基于分析过去十年里每个航班的情况,然后将其与过去和现实的天气情况进行匹配。
有趣的是,数据拥有者就做不到这样的事情。因为数据拥有者没有这样使用数据的动机和强制要求。事实上,如果美国运输统计局、美国联邦航空局和美国天气服务这些数据拥有者敢将航班晚点预测用作商业用途的话,国会可能就会举办听证会并否决这个提议。所以使用数据的任务就落到了一群不羁的数学才子的身上。同样,航空公司不可以这么做,也不会这么做,因为这些数据所表达的信息越隐蔽对它们就越有利。FlightCaster的预测是如此的准确,就连航空公司的职员也开始使用它了。但是需要注意的一点就是,虽然航空公司是信息的源头,但是不到最后一秒它是不会公布航班晚点的,所以它的信息是不及时的。
11.数据中间商也可以赚差价
谁在这个大数据价值链中获益最大呢?现在看来,应该是那些拥有大数据思维或者说创新性思维的人。
但是,这种先决优势并不能维持很长的时间。随着大数据时代的推进,别人也会吸收这种思维,然后那些先驱者的优势就会逐渐减弱。
那么,核心价值会不会在技术上?
事实上,国外的外包公司使得基础的计算机编程技术越来越廉价,如今它甚至成为了世界贫困人口的致富驱动力,而不再代表着高端技术。
我们正处在大数据时代的早期,思维和技能是最有价值的,但是最终,大部分的价值还是必须从数据本身中挖掘。在有些情况下会出现“数据中间人”,它们会从各种地方搜集数据进行整合,然后再提取有用的信息进行利用。数据拥有者可以让中间人充当这样的角色,因为有些数据的价值只能通过中间人来挖掘。
数据中间商,交通数据处理公司Inrix
总部位于西雅图的交通数据处理公司Inrix就是一个很好的例子。它汇集了来自美洲和欧洲近1亿辆汽车的实时交通数据。这些数据来自宝马、福特、丰田等私家车,还有一些商用车,比如出租车和货车。私家车主的移动电话也是数据的来源。这也解释了为什么它要建立一个免费的智能手机应用程序,因为一方面它可以为用户提供免费的交通信息,另一方面它自己就得到了同步的数据。Inrix通过把这些数据与历史交通数据进行比对,再考虑进天气和其他诸如当地时事等信息来预测交通状况。数据软件分析出的结果会被同步到汽车卫星导航系统中,政府部门和商用车队都会使用它。
Inrix是典型的独立运作的大数据中间商。它汇聚了来自很多汽车制造商的数据,这些数据能产生的价值要远远超过它们被单独利用时的价值。每个汽车制造商可能都会利用它们的车辆在行驶过程中产生的成千上万条数据来预测交通状况,这种预测不是很准确也并不全面。但是随着数据量的激增,预测结果会越来越准确。同样,这些汽车制造商并不一定掌握了分析数据的技能,它们的强项是造车,而不是分析泊松分布。所以它们都愿意第三方来做这个预测的事情。另外,虽然交通状况分析对驾驶员来说非常重要,但是这几乎不会影响到一个人是否会购车。所以,这些同行业的竞争者们并不介意通过行业外的中间商汇聚它们手里的数据。

12.你的隐私还是你的隐私吗
我们时刻都暴露在“第三只眼”之下:亚马逊监视着我们的购物习惯,谷歌监视着我们的网页浏览习惯,而微博似乎什么都知道,不仅窃听到了我们心中的“TA”,还有我们的社交关系网。
如何保证数据安全呢?
第一招:告知与许可
“告知与许可”已经是世界各地执行隐私政策的共识性基础(虽然实际上很多的隐私声明都没有达到效果,但那是另一回事)。over

还有一个办法就是对特定数据模糊化,如果所有人的信息本来都已经在数据库里,那么有意识地避免某些信息就是此地无银三百两。
我们把谷歌街景作为一个例子来看,谷歌的图像采集车在很多国家采集了道路和房屋的图像(以及很多备受争议的数据)。但是,德国媒体和民众强烈地抗议了谷歌的行为,因为民众认为这些图片会帮助黑帮窃贼选择有利可图的目标。有的业主不希望他的房屋或花园出现在这些图片上,顶着巨大的压力,谷歌同意将他们的房屋或花园的影像模糊化。但是这种模糊化却起到了反作用,因为你可以在街景上看到这种有意识的模糊化,对盗贼来说,这又是一个此地无银三百两的例子。
另一条技术途径在大部分情况下也不可行,那就是匿名化。
在小数据时代这样确实可行,但是随着数据量和种类的增多,大数据促进了数据内容的交叉检验。看下面例子。over
2006年8月,美国在线(AOL)公布了大量的旧搜索查询数据,本意是希望研究人员能够从中得出有趣的见解。这个数据库是由从3月1日到5月31日之间的65.7万用户的2000万搜索查询记录组成的,整个数据库进行过精心的匿名化——用户名称和地址等个人信息都使用特殊的数字符号进行了代替。这样,研究人员可以把同一个人的所有搜索查询记录联系在一起来分析,而并不包含任何个人信息。
尽管如此,《纽约时报》还是在几天之内通过把“60岁的单身男性”、“有益健康的茶叶”、“利尔本的园丁”等搜索记录综合分析考虑后,发现数据库中的4417749号代表的是佐治亚州利尔本的一个62岁寡妇塞尔玛·阿诺德(Thelma Arnold)。当记者找到她家的时候,这个老人惊叹道:“天呐!我真没想到一直有人在监视我的私人生活。”这引起了公愤,最终美国在线的首席技术官和另外两名员工都被开除了。