计算机视觉:语义分割理论及实战
语义分割
语义分割(Semantic Segmentation)是指将一张图像分割成若干个区域,并对每个区域赋予语义标签的任务。它是计算机视觉中的一种重要技术,被广泛应用于自动驾驶、医学图像分析、地理信息系统等领域。
与传统的图像分割任务不同,语义分割不仅需要将图像分割成若干个区域,还需要对每个区域赋予语义标签。例如,在自动驾驶中,语义分割可以将道路、车辆、行人等区域分割出来,并对每个区域赋予相应的语义标签,以帮助车辆进行自动驾驶。在医学图像分析中,语义分割可以将不同的组织结构(如器官、肌肉、骨骼等)分割出来,并对其进行分析和诊断。
语义分割的实现方法主要可以分为基于区域的方法和基于像素的方法。基于区域的方法将图像分割成一系列的区域,然后对每个区域进行分类并赋予相应的语义标签。基于像素的方法则直接对每个像素进行分类,并将其赋予相应的语义标签。目前,基于深度学习的方法已经成为了实现语义分割的主流方法,其中以基于卷积神经网络(CNN)的方法最为常见。常用的语义分割模型包括 FCN、SegNet、U-Net、DeepLab 等。
计算机视觉领域还有2个与语义分割相似的重要问题,即图像分割(image segmentation)和实例分割(instance segmentation)。 我们在这里将它们同语义分割简单区分一下。
图像分割将图像划分为若干组成区域,这类问题的方法通常利用图像中像素之间的相关性。它在训练时不需要有关图像像素的标签信息,在预测时也无法保证分割出的区域具有我们希望得到的语义。
实例分割也叫同时检测并分割(simultaneous detection and segmentation),它研究如何识别图像中各个目标实例的像素级区域。与语义分割不同,实例分割不仅需要区分语义,还要区分不同的目标实例。例如,如果图像中有两条狗,则实例分割需要区分像素属于的两条狗中的哪一条。
文章目录
- 语义分割
- 数据集
-
- 下载数据集
- 读取数据集
- 预处理数据
- 自定义语义分割数据集类
- 整合所有组件
- 全卷积网络
-
- 构造模型
- 初始化转置卷积层
- 训练
- 预测
数据集
最重要的语义分割数据集之一是Pascal VOC2012。
下载数据集
%matplotlib inline
import os
import torch
import torchvision
from d2l import torch as d2l
#@save
d2l.DATA_HUB['voc2012'] = (d2l.DATA_URL + 'VOCtrainval_11-May-2012.tar',
'4e443f8a2eca6b1dac8a6c57641b67dd40621a49')
voc_dir = d2l.download_extract('voc2012', 'VOCdevkit/VOC2012')
读取数据集
#@save
def read_voc_images(voc_dir, is_train=True):
"""读取所有VOC图像并标注"""
txt_fname = os.path.join(voc_dir, 'ImageSets', 'Segmentation',
'train.txt' if is_train else 'val.txt')
mode = torchvision.io.image.ImageReadMode.RGB
with open(txt_fname, 'r') as f:
images = f.read().split()
features, labels = [], []
for i, fname in enumerate(images):
features.append(torchvision.io.read_image(os.path.join(
voc_dir, 'JPEGImages', f'{fname}.jpg')))
labels.append(torchvision.io.read_image(os.path.join(
voc_dir, 'SegmentationClass' ,f'{fname}.png'), mode))
return features, labels
train_features, train_labels = read_voc_images(voc_dir, True)
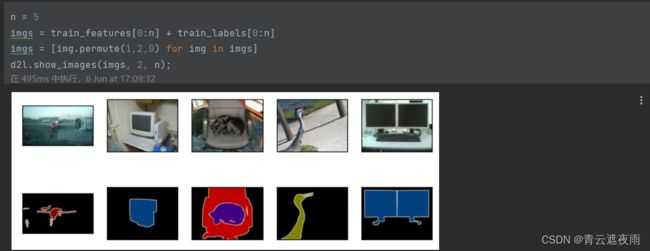
下面我们绘制前5个输入图像及其标签。 在标签图像中,白色和黑色分别表示边框和背景,而其他颜色则对应不同的类别。
n = 5
imgs = train_features[0:n] + train_labels[0:n]
imgs = [img.permute(1,2,0) for img in imgs]
d2l.show_images(imgs, 2, n);
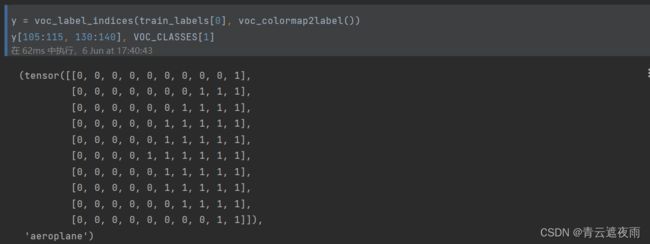
接下来,我们列举RGB颜色值和类名。
VOC_COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]]
#@save
VOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair', 'cow',
'diningtable', 'dog', 'horse', 'motorbike', 'person',
'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']
通过上面定义的两个常量,我们可以方便地查找标签中每个像素的类索引。 我们定义了voc_colormap2label函数来构建从上述RGB颜色值到类别索引的映射,而voc_label_indices函数将RGB值映射到在Pascal VOC2012数据集中的类别索引。
#@save
def voc_colormap2label():
"""构建从RGB到VOC类别索引的映射"""
colormap2label = torch.zeros(256 ** 3, dtype=torch.long)
for i, colormap in enumerate(VOC_COLORMAP):
colormap2label[
(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]] = i
return colormap2label
具体来说,该代码使用了一种将 RGB 颜色值转换为一个唯一整数的方法,即将 R、G、B 三个通道的值分别乘以 25 6 2 256^2 2562、 25 6 1 256^1 2561、 25 6 0 256^0 2560,然后将它们相加。这样可以将一个三元组的 RGB 颜色值转化为一个唯一的整数。
#@save
def voc_label_indices(colormap, colormap2label):
"""将VOC标签中的RGB值映射到它们的类别索引"""
colormap = colormap.permute(1, 2, 0).numpy().astype('int32')
idx = ((colormap[:, :, 0] * 256 + colormap[:, :, 1]) * 256
+ colormap[:, :, 2])
return colormap2label[idx]
具体来说,函数首先将 “colormap” 张量中的 RGB 值转换为一个大小为 (H, W) 的整数张量 “idx”。这是通过将 R、G、B 三个通道的值分别乘以 25 6 2 256^2 2562、 25 6 1 256^1 2561、 25 6 0 256^0 2560,然后将它们相加得到的。然后,该整数作为索引,从 “colormap2label” 张量中提取对应的类别索引。这些类别索引构成了一个与 “colormap” 张量形状相同的新张量 “idx”,其中每个元素都对应于 “colormap” 张量中的一个像素。
预处理数据
在语义分割中,这样做需要将预测的像素类别重新映射回原始尺寸的输入图像。 这样的映射可能不够精确,尤其在不同语义的分割区域。 为了避免这个问题,我们将图像裁剪为固定尺寸,而不是再缩放。 具体来说,我们使用图像增广中的随机裁剪,裁剪输入图像和标签的相同区域。
#@save
def voc_rand_crop(feature, label, height, width):
"""随机裁剪特征和标签图像"""
rect = torchvision.transforms.RandomCrop.get_params(
feature, (height, width))
feature = torchvision.transforms.functional.crop(feature, *rect)
label = torchvision.transforms.functional.crop(label, *rect)
return feature, label
imgs = []
for _ in range(n):
imgs += voc_rand_crop(train_features[0], train_labels[0], 200, 300)
imgs = [img.permute(1, 2, 0) for img in imgs]
d2l.show_images(imgs[::2] + imgs[1::2], 2, n);
该函数使用 torchvision.transforms.RandomCrop.get_params() 获取一个随机裁剪矩形,然后使用 torchvision.transforms.functional.crop() 函数对输入的特征图像和标签图像进行裁剪。最后,该函数返回裁剪后的特征图像和标签图像。具体来说,该函数通过以下步骤实现随机裁剪:
- 使用 torchvision.transforms.RandomCrop.get_params() 获取一个随机裁剪矩形,该矩形的高度和宽度分别为 height 和 width。
- 使用 torchvision.transforms.functional.crop() 对输入的特征图像和标签图像进行裁剪,裁剪矩形为上一步获取的随机矩形。
- 返回裁剪后的特征图像和标签图像。
自定义语义分割数据集类
#@save
class VOCSegDataset(torch.utils.data.Dataset):
"""一个用于加载VOC数据集的自定义数据集"""
def __init__(self, is_train, crop_size, voc_dir):
self.transform = torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.crop_size = crop_size
features, labels = read_voc_images(voc_dir, is_train=is_train)
self.features = [self.normalize_image(feature)
for feature in self.filter(features)]
self.labels = self.filter(labels)
self.colormap2label = voc_colormap2label()
print('read ' + str(len(self.features)) + ' examples')
def normalize_image(self, img):
return self.transform(img.float() / 255)
def filter(self, imgs):
return [img for img in imgs if (
img.shape[1] >= self.crop_size[0] and
img.shape[2] >= self.crop_size[1])]
def __getitem__(self, idx):
feature, label = voc_rand_crop(self.features[idx], self.labels[idx],
*self.crop_size)
return (feature, voc_label_indices(label, self.colormap2label))
def __len__(self):
return len(self.features)
这是一个用于加载 Pascal VOC 数据集的自定义数据集类 VOCSegDataset。该数据集类提供了以下方法:
init(self, is_train, crop_size, voc_dir): 构造函数,用于初始化数据集。该函数接受三个参数:
- is_train: 一个布尔值,指示该数据集是用于训练还是测试。
- crop_size: 一个元组,表示对图像进行随机裁剪后的大小。
- voc_dir: 数据集存储路径。
normalize_image(self, img): 用于对图像进行标准化处理。
filter(self, imgs): 用于过滤掉尺寸小于 crop_size 的图像。
getitem(self, idx): 用于获取数据集中的一个样本。该函数接受一个索引参数 idx,返回一个元组 (feature, label),其中 feature 表示特征图像,label 表示对应的标签图像。
len(self): 用于获取数据集中样本的数量。
在构造函数中,该数据集类首先使用 read_voc_images() 函数读取数据集中的图像和标签,并使用 filter() 方法过滤掉尺寸小于 crop_size 的图像。然后,该数据集类对每个特征图像使用 normalize_image() 方法进行标准化处理,并使用 voc_rand_crop() 和 voc_label_indices() 方法实现对特征图像和标签图像的随机裁剪和标签映射。最后,该数据集类在 getitem() 方法中返回裁剪后的特征图像和标签图像。
该数据集类的主要作用是将 Pascal VOC 数据集转换为 PyTorch 中的 Dataset 类型,以便于在训练模型时使用 PyTorch 提供的 DataLoader 类对数据进行批量处理。
crop_size = (320, 480)
voc_train = VOCSegDataset(True, crop_size, voc_dir)
voc_test = VOCSegDataset(False, crop_size, voc_dir)
batch_size = 64
train_iter = torch.utils.data.DataLoader(voc_train, batch_size, shuffle=True,
drop_last=True,
num_workers=d2l.get_dataloader_workers())
for X, Y in train_iter:
print(X.shape)
print(Y.shape)
break
整合所有组件
#@save
def load_data_voc(batch_size, crop_size):
"""加载VOC语义分割数据集"""
voc_dir = d2l.download_extract('voc2012', os.path.join(
'VOCdevkit', 'VOC2012'))
num_workers = d2l.get_dataloader_workers()
train_iter = torch.utils.data.DataLoader(
VOCSegDataset(True, crop_size, voc_dir), batch_size,
shuffle=True, drop_last=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(
VOCSegDataset(False, crop_size, voc_dir), batch_size,
drop_last=True, num_workers=num_workers)
return train_iter, test_iter
全卷积网络
全卷积模型是一种特殊的卷积神经网络,它可以对输入图像进行像素级别的分类或分割,输出一个与输入图像尺寸相同的分割结果。全卷积模型通常由卷积层、反卷积层和池化层组成,其中卷积层用于提取图像特征,反卷积层用于将特征图像还原为原始图像大小,池化层用于减小特征图像的尺寸。
全卷积模型最常用于图像分割任务,如语义分割、实例分割和边缘检测等。其中,语义分割任务是将图像中的每个像素分配到其对应的类别中,而实例分割任务则是将图像中的每个物体实例分配到不同的类别中。
全卷积模型的一种经典结构是 U-Net,它由编码器和解码器两部分组成。编码器通常采用卷积层和池化层的组合,用于提取图像特征并减小特征图像的尺寸。解码器则采用反卷积层和跳跃连接的方式,用于将特征图像还原为原始图像大小,并将编码器中的特征图像与解码器中的特征图像进行融合。
在训练全卷积模型时,通常使用交叉熵损失函数来度量模型输出与真实标签之间的差异,并使用反向传播算法更新模型参数。由于全卷积模型的输出是一个分割图像,因此在计算损失函数时通常需要将其展平为一个向量。
构造模型
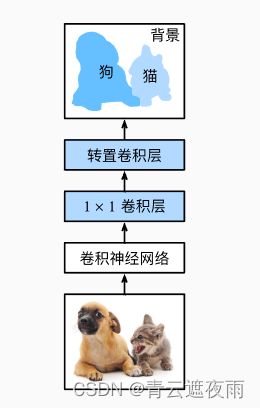
下面我们了解一下全卷积网络模型最基本的设计。 如下图所示,全卷积网络先使用卷积神经网络抽取图像特征,然后通过 1 × 1 1\times 1 1×1卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。 因此,模型输出与输入图像的高和宽相同,且最终输出通道包含了该空间位置像素的类别预测。
下面,我们使用在ImageNet数据集上预训练的ResNet-18模型来提取图像特征,并将该网络记为pretrained_net。 ResNet-18模型的最后几层包括全局平均汇聚层和全连接层,然而全卷积网络中不需要它们。

接下来,我们创建一个全卷积网络net。 它复制了ResNet-18中大部分的预训练层,除了最后的全局平均汇聚层和最接近输出的全连接层。
net = nn.Sequential(*list(pretrained_net.children())[:-2])
给定高度为320和宽度为480的输入,net的前向传播将输入的高和宽减小至原来的 1 32 \frac{1}{32} 321,即10和15。
X = torch.rand(size=(1, 3, 320, 480))
net(X).shape
![]()
接下来使用 1 × 1 1\times 1 1×1卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)。 最后需要将特征图的高度和宽度增加32倍,从而将其变回输入图像的高和宽。 由于 ( 320 − 64 + 16 ∗ 2 + 32 ) / 32 = 10 (320-64+16*2+32)/32=10 (320−64+16∗2+32)/32=10且 ( 480 − 64 + 16 ∗ 2 + 32 ) / 32 = 15 (480-64+16*2+32)/32=15 (480−64+16∗2+32)/32=15,我们构造一个步幅为 32 32 32的转置卷积层,并将卷积核的高和宽设为 64 64 64,填充为 16 16 16。 我们可以看到如果步幅为 s s s,填充为 s / 2 s/2 s/2(假设 s s s是整数)且卷积核的高和宽为 2 s 2s 2s,转置卷积核会将输入的高和宽分别放大 s s s倍。
初始化转置卷积层
在图像处理中,我们有时需要将图像放大,即上采样(upsampling)。 双线性插值(bilinear interpolation) 是常用的上采样方法之一,它也经常用于初始化转置卷积层。
上采样是一种将低分辨率图像或信号增加到高分辨率的方法。双线性插值是一种常用的上采样方法之一,它可以通过对已有的低分辨率图像进行插值,生成更高分辨率的图像。
在双线性插值中,假设要将一个低分辨率图像上采样两倍,即将每个像素变成一个 2 × 2 2 \times 2 2×2 的像素块。对于每个新像素块中的像素,双线性插值会根据周围的四个已知像素值值进行计算。具体来说,对于目标图像中的一个新像素 ( x , y ) (x, y) (x,y),它的灰度值可以通过以下步骤计算:
找到目标像素 ( x , y ) (x, y) (x,y) 在原始低分辨率图像中对应的四个像素 ( x 1 , y 1 ) (x_1, y_1) (x1,y1), ( x 2 , y 1 ) (x_2, y_1) (x2,y1), ( x 1 , y 2 ) (x_1, y_2) (x1,y2), ( x 2 , y 2 ) (x_2, y_2) (x2,y2),其中 ( x 1 , y 1 ) (x_1, y_1) (x1,y1) 和 ( x 2 , y 2 ) (x_2, y_2) (x2,y2) 是最靠近 ( x , y ) (x, y) (x,y) 的两个像素, ( x 1 , y 2 ) (x_1, y_2) (x1,y2) 和 ( x 2 , y 1 ) (x_2, y_1) (x2,y1) 是另外两个像素。
计算目标像素 ( x , y ) (x, y) (x,y) 与四个已知像素之间的距离,即 d 1 = ( x − x 1 ) 2 + ( y − y 1 ) 2 d_{1} = \sqrt{(x-x_1)^2 + (y-y_1)^2} d1=(x−x1)2+(y−y1)2, d 2 = ( x − x 2 ) 2 + ( y − y 1 ) 2 d_{2} = \sqrt{(x-x_2)^2 + (y-y_1)^2} d2=(x−x2)2+(y−y1)2, d 3 = ( x − x 1 ) 2 + ( y − y 2 ) 2 d_{3} = \sqrt{(x-x_1)^2 + (y-y_2)^2} d3=(x−x1)2+(y−y2)2, d 4 = ( x − x 2 ) 2 + ( y − y 2 ) 2 d_{4} = \sqrt{(x-x_2)^2 + (y-y_2)^2} d4=(x−x2)2+(y−y2)2。
计算目标像素 ( x , y ) (x, y) (x,y) 的灰度值,用周围四个像素的灰度值进行加权平均,权重与目标像素与四个已知像素之间的距离成反比。即:
f ( x , y ) = 1 d 1 d 3 f ( x 1 , y 1 ) + 1 d 2 d 3 f ( x 2 , y 1 ) + 1 d 1 d 4 f ( x 1 , y 2 ) + 1 d 2 d 4 f ( x 2 , y 2 ) f(x, y) = \frac{1}{d_{1}d_{3}}f(x_1, y_1) + \frac{1}{d_{2}d_{3}}f(x_2, y_1) + \frac{1}{d_{1}d_{4}}f(x_1, y_2) + \frac{1}{d_{2}d_{4}}f(x_2, y_2) f(x,y)=d1d31f(x1,y1)+d2d31f(x2,y1)+d1d41f(x1,y2)+d2d41f(x2,y2)
其中 f ( x 1 , y 1 ) f(x_1, y_1) f(x1,y1), f ( x 2 , y 1 ) f(x_2, y_1) f(x2,y1), f ( x 1 , y 2 ) f(x_1, y_2) f(x1,y2), f ( x 2 , y 2 ) f(x_2, y_2) f(x2,y2) 分别表示四个已知像素的灰度值。
通过双线性插值,我们可以将低分辨率图像上采样到更高分辨率,从而得到更清晰的图像。
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = (torch.arange(kernel_size).reshape(-1, 1),
torch.arange(kernel_size).reshape(1, -1))
filt = (1 - torch.abs(og[0] - center) / factor) * \
(1 - torch.abs(og[1] - center) / factor)
weight = torch.zeros((in_channels, out_channels,
kernel_size, kernel_size))
weight[range(in_channels), range(out_channels), :, :] = filt
return weight
这是一个用于生成双线性插值卷积核的函数。它的输入包括输入通道数、输出通道数和卷积核大小,它的输出是一个形状为 (in_channels, out_channels, kernel_size, kernel_size) 的张量,表示由该函数生成的双线性插值卷积核。
具体来说,该函数首先计算出卷积核中心的位置,然后生成一个形状为 (kernel_size, kernel_size) 的张量 filt,其中 filt 的每个元素表示双线性插值卷积核中对应位置的权重。最后,该函数根据输入通道数和输出通道数,生成形状为 (in_channels, out_channels, kernel_size, kernel_size) 的张量 weight,其中 weight 的每个元素表示双线性插值卷积核中对应位置的权重。具体来说,weight[i, j, :, :] 表示从第 i 个输入通道到第 j 个输出通道的双线性插值卷积核。
这个函数可以用于定义卷积神经网络中的双线性插值卷积层,该层将输入张量上采样到更高分辨率。
全卷积网络用双线性插值的上采样初始化转置卷积层。对于 1 × 1 1\times 1 1×1卷积层,我们使用Xavier初始化参数。
W = bilinear_kernel(num_classes, num_classes, 64)
net.transpose_conv.weight.data.copy_(W);
训练
def loss(inputs, targets):
return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)
num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
预测
在预测时,我们需要将输入图像在各个通道做标准化,并转成卷积神经网络所需要的四维输入格式。
def predict(img):
X = test_iter.dataset.normalize_image(img).unsqueeze(0)
pred = net(X.to(devices[0])).argmax(dim=1)
return pred.reshape(pred.shape[1], pred.shape[2])
为了可视化预测的类别给每个像素,我们将预测类别映射回它们在数据集中的标注颜色。
def label2image(pred):
colormap = torch.tensor(VOC_COLORMAP, device=devices[0])
X = pred.long()
return colormap[X, :]
测试数据集中的图像大小和形状各异。 由于模型使用了步幅为32的转置卷积层,因此当输入图像的高或宽无法被32整除时,转置卷积层输出的高或宽会与输入图像的尺寸有偏差。 为了解决这个问题,我们可以在图像中截取多块高和宽为32的整数倍的矩形区域,并分别对这些区域中的像素做前向传播。 请注意,这些区域的并集需要完整覆盖输入图像。 当一个像素被多个区域所覆盖时,它在不同区域前向传播中转置卷积层输出的平均值可以作为softmax运算的输入,从而预测类别。
为简单起见,我们只读取几张较大的测试图像,并从图像的左上角开始截取形状为 320 × 480 320\times 480 320×480的区域用于预测。 对于这些测试图像,我们逐一打印它们截取的区域,再打印预测结果,最后打印标注的类别。
