Python爬虫学习:思路描述
Python爬虫学习:思路描述
- 前瞻知识
- Requests模块
- 爬虫的思路
- 一个小例子
- 注意点
前瞻知识
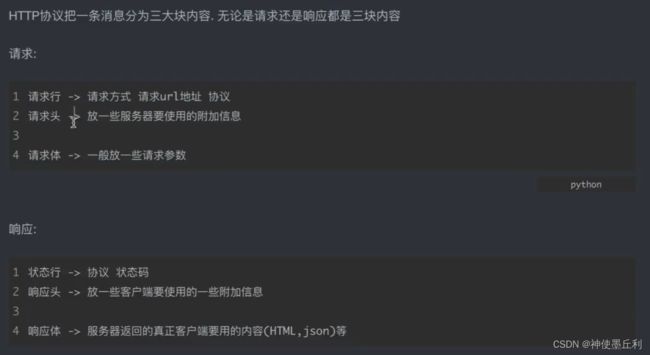
- HTTP协议中一条消息请求和相应的三部分。
我们获取数据都是通过网页,而网页中传输数据是通过HTTP(超文本协议)来完成的。因此,了解HTTP协议传输数据的内容很关键。
- 服务器渲染
服务器端在收到我们用户的请求之后,查询到数据,然后将数据和html整合在一起,统一返回给浏览器。这种情况下,在页面源代码中,可以看到数据。 - 客户端渲染
第一次请求只要一个html骨架,第二次请求才是获取数据的过程(涉及到两个url),然后在用户端将数据和html整合,展示给我们看。这种情况下,在页面源代码中,看不到数据。 - 如何判断数据是服务器渲染还是客户端渲染
按下ctrl+u打开网页源码,选择一个你想要获取的数据,在网页源码中按下ctrl+f查找,如果有查找结果,则表示 数据是打包在网页源码中发送过来的,是服务器渲染,反之则是客户端渲染,需要按下F12在网页调试器中寻找数据文件。
Requests模块
使用requests中的get函数来获取网页源码。
用法如下:
import requests
#设置网页url与header(用作让服务器认为网页链接请求是通过一个浏览器发出的,而不是恶意攻击)
url='xxx'
header={"User-Agent":"xxx"}
resp=requests.get(url,headers=header)
url获取:

headers获取:
按下F12打开页面控制器->点击网络->选择第一个->找到User-Agent
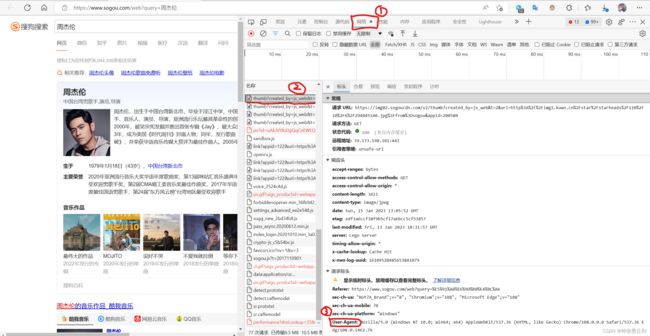
注:如果不设置headers则会出错。表示服务器端设置了一些反爬的措施。

爬虫的思路
- 明确数据是服务器端渲染还是用户端渲染
- 如果是服务器端渲染,则首先获取源码。
如果是用户端渲染,则通过F12获取数据网址,从而获取数据代码。 - 从代码中提取数据。如果是服务器端渲染,则提取过程复杂许多。如果是用户端渲染,则提取过程较为简单。
一个小例子
import requests
#设置网页url
url="https://www.sogou.com/web?query=周杰伦"
#设置header
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76"
}
#使用get方式获取网页源代码
resp=requests.get(url,headers=header)
#将解码方式设置为网页的解码方式
resp.encoding = resp.apparent_encoding
#打印
print(resp.text)
注意点
持续更新!