手撕希尔排序
什么是希尔排序?他的效率怎摸样,如何去实现希尔排序呢?在这之前可能我们已经了解了希尔排序,作为排序中的老大哥一员,希尔排序的效率也是屈指可数的。
想要知道希尔排序如何实现我们就的先了解插入排序。
目录
1.何为插入排序
2.插入排序的实现
3.何为希尔排序
4.希尔排序的实现
5.希尔排序的时间复杂度
1.何为插入排序
插入排序是一种简单直观的排序算法,其基本思想是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。。
具体实现逻辑如下:
从第一个元素开始,该元素可以认为已经被排序。
取出下一个元素,在已经排序的元素序列中从后向前扫描。如果该元素(已排序)大于新元素,将该元素移到下一位置,重复步骤3,直到找到已排序的元素小于或者等于新元素的位置。将新元插入到该位置后,重复步骤2~5。
这里我们可将插入排序形象地理解为打牌时我们摸牌插入到手中牌堆的思想,在日常生活中插入排序也遍布在我们的身边。

2.插入排序的实现
插入排序,从第一个元素开始,将下一个元素tmp与之比较,若大于tmp,则该位置的数据后移一位,此时end--,该位置空出,之后tmp插入到该位置,实现前插。若大于tmp,跳出循环,刚好插到该元素后面的位置。以此往复,实现排序。
插入排序这里的循环条件根据你判断i是小于n还是n-,改变end与tmp对应的位置。
void InsertSort(int* a, int n)
{
for (int i = 0; i < n-1; ++i)
{
// [0, end] 有序,插入tmp依旧有序
int end = i;
int tmp = a[i+1];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}可以看到插入排序的时间复杂度根源数据的顺序度的有关系的,越顺序时间复杂度越小,最好的情况是O(N),最坏的情况是逆序,先还是一个等差数列的求和,故时间复杂度为O(N^2).
实际上插入排序的时间复杂度是较高的了,相对于冒牌排序两者效果差不多,插入略快一点点。
3.何为希尔排序
在深入了解了插入排序时,一个叫shell的大佬就思考如何将在实现插入排序前时,能否将数据先变得更加有序一些,而不是毫无顺序,这样使得排序的时间复杂度低一些,于是他们提出了一个思想,在进行插入排序时,先将数据分组,每一组中的数据相差gap个,每一组数据进行类似插入排序的思想先进行分组排序,之后进行插入排序,于是大名鼎鼎的希尔排序就此诞生!
例如
我们对于组数逆序的数组(我们是降序排列)a[]={9,8,7,6,5,4,3,2,2,1,0},这样更明显的展示。
预排序:
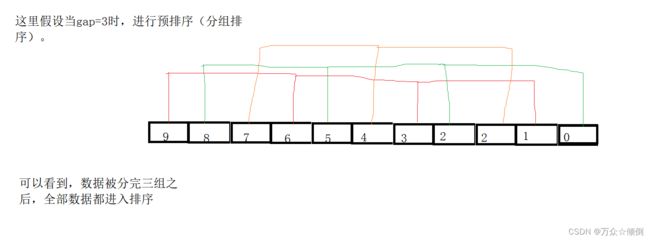
现在就是开始排序
我们已经知道排序的代码:

添加循环,于是分组排序代码就如下
for (int i = 0; i < gap; i++)
{
for (int j = i; j < n - gap; j=j+gap)
{
int end = i;
int tmp = arr[end + gap];
while (end > 0)
{
if (arr[end] > tmp)
{
arr[end + gap] = arr[end];
end = end - gap;
}
else
{
break;
}
arr[end + gap] =tmp;
}
}当然这里的代码我们可以简化一下利用分组数据,每组齐头并进的思想简化如下:
这两种方式效率都是一样的,只不过代码得到了简化:
for (int i = 0; i < n-gap; i++)
{
//每组齐头并进一次插入排序
int end = i;//第i个位置
int tmp = arr[end+gap];//第i+gap个位置
while (end >= 0)
{
if (arr[end] > tmp)
{
arr[end + gap] = arr[end];
end -= gap;
}
else
{
break;
}
arr[i + gap] = tmp;
}我们发现: 
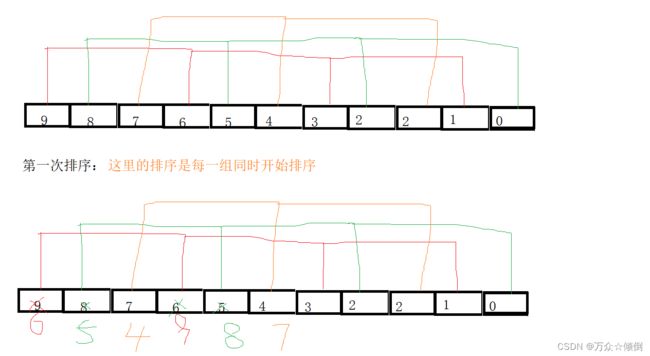
循环最终结果为:

此时我们发现该组数已经变得逐渐有序,这就是最重要的思想之一,当然我们可以发现该代码与插入排序非常的相似,两者的区别仅仅是因为gap的取值,当gap为1时,便就是希尔排序。
4.希尔排序的实现
明白以上的预排序我们就正式进入希尔排序,所谓希尔排序就是:
1.先进行预排序。
2.gap==1时在进行插入排序。
在预排序中我们了解,当gap越大排序越不是那么有序,组数也较少,当gap越小,排的越为顺序,组数较多,可是时间复杂度高且排序的数过多时gap不能越小。于是希尔排序就决定每一次排序就变换gap的值,动态变换排序。
于是就实现了希尔排序:
void ShellSort(int* a, int n)
{
// 1、gap > 1 预排序
// 2、gap == 1 直接插入排序
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1; // +1可以保证最后一次一定是1
// gap = gap / 2;
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}5.希尔排序的时间复杂度
事实上,希尔排序的时间复杂度很难求解,因为随着gap的变化每一次循环的时间复杂度都是不一样的,它是一种动态变化,想要求解比较困难,但我们不难发现,希尔排序的速度时令人震惊的,
因此Hibbard提出了著名的Hibbard增量:1, 3, 7, ..., 2^K−1 。使用这个增量的希尔排序最坏运行时间是 O(N^3/2) 。
通俗来说,能打破二次时间界的核心原因是:
在执行 hk排序之前,我们已经执行了 ℎk+1,hk+2 排序。而这两个排序使得序列在宏观上更有序,并且严格地保证了对于某个位置的元素E,在这个元素左侧,且到E一定距离以上的元素一定小于E。
可以看到希尔排序的时间复杂度已经较低了,他的速度也算得上是老大哥了,我们这里用他和冒泡排序比较一下,看一下什么是小巫见大巫:
#include
#include
#include
void shellsort(int *a,int n)
{
int gap=n;
while(gap>1)
{
gap=gap/3+1;
for(int i=0;i=0)
{
if(a[end]>tmp)
{
a[gap+end]=a[end];
end=end-gap;
}else
{
break;
}
}
a[end+gap]=tmp;
}
}
}
void bubblesort(int *arr,int n)
{
for(int i=0;iarr[i+1])
{
int tmp=arr[i];
arr[i]=arr[i+1];
arr[i+1]=tmp;
}
}
}
}
int*creatarr(int n)
{
int *p;
p=(int *)malloc(sizeof(int)*n);
srand(time(NULL));
for(int i=0;i 这里我们让同时排序十万个数,运行结果如下:
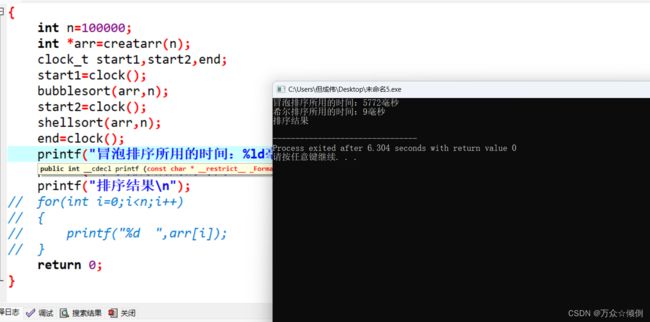
希尔排序确实是老大哥。两者根本不在一个量级。
总的来说:
希尔排序的时间复杂度是O(n^(1.3-2)),空间复杂度为常数阶O(1) 。希尔排序没有时间复杂度为O(n(logn))的快速排序算法快,因此对中等大小规模表现良好,但对规模非常大的数据排序不是最优选择,总之比一般O(n^2)复杂度的算法快得多 。