八、进程等待
文章目录
- 一、进程创建
-
- (一)fork函数概念
-
- 1.概念
- 2.父子进程共享fork之前和fork之后的所有代码,只不过子进程只能执行fork之后的!
- (二)fork之后,操作系统做了什么?
-
- 1.进程具有独立性,代码和数据必须独立的
- 2.写时拷贝
- 3.fork常规用法
- 4.fork调用失败的原因
- (三)fork后子进程保留了父进程的什么?
- (四)fork和exec系统调用
- 二、进程终止
-
- (一)常见进程退出
- (二)关于进程终止的正确认识
-
- 1.进程退出码
- 2.关于终止的常见做法——exit()
- 3.exit和_exit
- 4.关于终止,内核做了什么?
- 三、进程等待
-
- (一)为什么要进行进程等待
- (二)wait
- (三)waitpid
- (四)获取子进程的status
- 四、一些问题
-
- (一)问题一
- (二)问题二
- 五、阻塞等待和非阻塞等待
-
- (一)阻塞等待:
- (二)非阻塞等待:
- 总结:
一、进程创建
(一)fork函数概念
1.概念
在linux 中 fork 函数是非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
函数原型:
#include 返回值:子进程中返回 0 ,父进程返回子进程 id ,出错返回 -1
子找父容易,父找子难,一个孩子只有一个父亲,但是一个父亲可能有多个孩子!
进程调用fork,当控制转移到内核中的fork代码后,内核做:
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表当中(链进运行队列)
- fork返回,开始调度器调度

当一个进程调用 fork 之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的旅程,看如下程序:
#include
2.父子进程共享fork之前和fork之后的所有代码,只不过子进程只能执行fork之后的!
fork之前父进程独立执行,fork之后, 父子两个执行流分别执行。
那么fork之后,是否只有fork之后的代码是被父子进程共享的? ?

fork之后,父子共享所有的代码,但fork之前的代码也是父子共享的,只不过子进程只能执行fork之后的,子进程执行的后续代码! =共享的所有代码,只不过子进程只能从这里开始执行!
为什么呢?
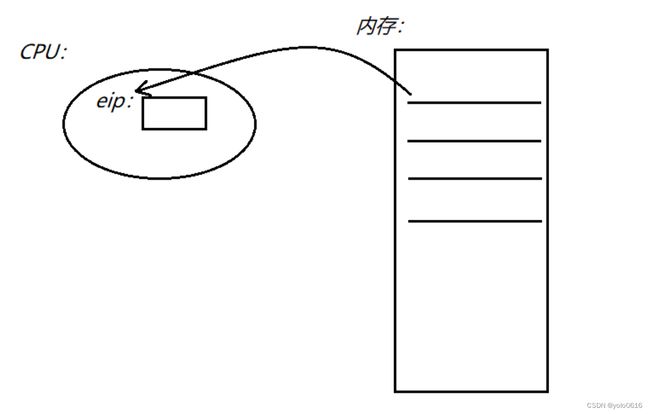
CPU中有一个程序计数器叫eip,也叫做:pc指针,用途是 : 保存当前正在执行指令的下一条指令!(保存当前进程执行到什么位置)。
eip程序计数器会拷贝给子进程,子进程便从该eip所指向的代码处开始执行!
- 如果我想让子进程拿到fork之前的代码,可以让子进程把CPU中的eip改成main函数入口就可以执行fork之前的代码。
(二)fork之后,操作系统做了什么?
进程 = 内核的进程数据结构+进程的代码和数据。
创建子进程的内核数据结构(struct task_ struct + struct mm_ struct +页表) +代码继承父进程,数据以写时拷贝的方式,来进行共享或者独立!
1.进程具有独立性,代码和数据必须独立的
- 数据通过写时拷贝保证独立性
- 代码因为是只读的,不可修改
2.写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。
3.fork常规用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
- 一个进程要执行一个不同的程序。例如子进程从 fork 返回后,调用 exec 函数。
4.fork调用失败的原因
- 系统中有太多的进程
- 实际用户的进程数超过了限制
(三)fork后子进程保留了父进程的什么?
A.环境变量
B.父进程的文件锁,pending alarms和pending signals
C.当前工作目录
D.进程号
fork函数功能是通过复制父进程,创建一个新的子进程。
A选项正确:环境变量默认会继承于父进程,与父进程相同
B选项错误:信号相关信息各自独立,并不会复制
C选项正确:工作路径也相同
D选项错误:每个进程都有自己独立的标识符
根据理解分析,正确选项为A和C选项
(四)fork和exec系统调用
- fork生成的进程是当前进程的一个相同副本(fork调用通过复制父进程创建子进程,子进程与父进程运行的代码和数据完全一样)
- fork系统调用与clone系统调用的工作原理基本相同(fork创建子进程就是在内核中通过调用clone实现)
- exec是程序替换函数,本身并不创建进程
- clone函数的功能是创建一个pcb,fork创建进程以及后边的创建线程本质内部调用的clone函数实现,而exec函数中本身并不创建进程,而是程序替换,因此工作机理并不相同
二、进程终止
(一)常见进程退出
常见进程退出:
- 代码跑完,结果正确
- 代码跑完,结果不正确
- 代码没跑完,程序异常了
(二)关于进程终止的正确认识
C/C++的时候,main函数为什么 return 0 ?
a.return 0,给谁return
b.为何是0?其他值可以吗?
return 0表示进程代码跑完,结果正确!
return 非零:结果不正确!
在main函数中return代表进程结束,其他非main函数return代表函数调用结束。
1.进程退出码
代码跑完,结果正确就没什么好说的就exit(0)/return 0返回码是0;
如果代码跑完,结果不正确,那我们最想知道的是失败的原因!
所以:非零标识不同的原因! 比如exit(13)
return X的X叫做进程退出码,表征进程退出的信息,是让父进程读取的! !
echo $? 查看进程退出码
echo $? :在bash中,最近一次执行完毕时,对应进程的退出码。

解释这里:第一次 echo $? 打印了进程退出码 123 ,第二次 echo $? 打印的是上一次 echo $?的进程退出码,因为上一次 echo $? 执行成功了,所以进程退出码是0。
一般而言,失败的非零值我该如何设置呢? 以及默认表达的含义?
可以自定义,也可以用系统定义的sterror。
错误码退出码可以对应不同的错误原因,方便定位问题!
2.关于终止的常见做法——exit()
- 在main函数中return代表进程结束,其他非main函数return代表函数调用结束。
- 在自己的代码任意地点中main函数/非main函数,调用exit()都叫进程退出,exit(X)中的X是退出码。
3.exit和_exit
exit终止进程刷新缓冲区
_exit,是系统调用,直接中止进程,不会有任何刷新操作
终止进程推荐exit或main函数中的return。

会打印: hello bit,即刷新缓冲区。
如果是_exit(0),就不会打印任何东西,即不刷新缓冲区。
4.关于终止,内核做了什么?
进程 = 内核结构 + 进程代码 和 数据
进程代码 和 数据一定会释放,但是 task/struct && mm_ struct:操作系统可能并不会释放该进程的内核数据结构
因为再次创建对象:
- 开辟空间
- 初始化 都要花时间。
linux会维护一张废弃的数据结构链表叫obj,若释放进程,对应的进程的数据结构会被维护到这个链表中,这个链表没有释放空间,只是被设成无效,需要时就拿,节省开辟时间(这样的链表也称内核的数据结构缓冲池,操作系统叫:slab分派器)。
三、进程等待
(一)为什么要进行进程等待
- 之前讲过,子进程退出,父进程如果不管不顾,就可能造成‘僵尸进程’的问题,进而造成内存泄漏。
- 另外,进程一旦变成僵尸状态,那就刀枪不入,“杀人不眨眼”的kill -9 也无能为力,因为谁也没有办法杀死一个已经死去的进程。
- 最后,父进程派给子进程的任务完成的如何,我们需要知道。如,子进程运行完成,结果对还是不对,或者是否正常退出。
- 父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息
(二)wait
wait()的方案可以解决回收子进程z状态,让子进程进入X,wait是等待任意一个退出的子进程。
#include
(三)waitpid
#include 例子:
(四)获取子进程的status
下面进程等待所使用的两个函数wait和waitpid,都有一个status参数,该参数是一个输出型参数,由操作系统进行填充。
如果对status参数传入NULL,表示不关心子进程的退出状态信息。否则,操作系统会将子进程的退出信息填充到status中。
status是一个整型变量,但status不能简单的当作整型来看待,status的不同比特位所代表的信息不同,在status的低16比特位当中,高8位表示进程的退出状态,即退出码。进程若是被信号所杀,则低7位表示终止信号,而第8位比特位是core dump标志。

我们通过位操作,根据status得到进程的退出码和退出信号。
exitCode = (status >> 8) & 0xFF; //正常退出时的退出码,当异常退出时退出码是没有意义的
exitSignal = status & 0x7F; //退出信号
对于此,系统当中提供了两个宏来获取退出码和退出信号。
WIFEXITED(status):用于查看进程是否是正常退出,本质是检查是否收到信号,正常退出,即为真。
WEXITSTATUS(status):用于获取进程的退出码
需要注意的是,当一个进程非正常退出时,说明该进程是被信号所杀,那么该进程的退出码也就没有意义了。
四、一些问题
(一)问题一
为什么不能定义一个全局变量code,子进程退出的时候就把code设置好特定的值,然后父进程回收的时候直接拿code的数据呢?
(二)问题二
一个子进程既有退出码:0,又有退出信号:11.
那我先看谁?
常见进程退出:
- 代码跑完,结果正确
- 代码跑完,结果不正确
- 代码没跑完,程序异常了
退出码对应的是前两种情况,退出信号是第3种情况!
程序正常跑完,只关心退出码。一旦进程出现异常,只关心退出信号,退出码没有任何意义!
五、阻塞等待和非阻塞等待
如果子进程就是不退出(如死循环),怎么办呢?我的父进程只能阻塞等待。
当我调用某些函数的时候,因为条件不就行,需要我们阻塞等待,本质:就是当前进程自己变成阻塞状态,等条件就绪的时候再被唤醒!
我们今天等待的资源就不是硬件了,而是软件。一个进程在等另一个进程!
(一)阻塞等待:
为了完成一个功能,发起一个调用,如果不具备条件的话则一直等待,直到具备条件则完成。
例子:
你是一个程序员,你有个非常漂亮的女朋友,你们相约一起吃饭(必须一起吃)。
今天,由于你一贯磨磨唧唧,她先来到你的楼下,开始发消息:
她:你快点下来吧,我们去吃饭
你:稍等,5分钟
她:行
五分钟很快过去了
她:你快点下来吧,这都5分钟了
你:稍等哦,再给我3分钟
她:嗯 你快点
三分钟又过去了
她:你好了没呀?
你:等等 再给我2分钟
她:把记忆结成冰?????
这个时候,女朋友肯定生气了,于是一个电话打过来:
她:你不许挂电话,我就在这等着,什么时候下来,什么时候我挂。
在这期间,你磨磨唧唧的时候,她发消息的方式,就是进程非阻塞等待,这种等待的方式,她可以看小说、打游戏等等。
生气以后,她电话打进来,就不能再用手机干别的事情了,这就是进程阻塞等待。
(二)非阻塞等待:
为了完成一个功能,发起一个调用,具备条件直接输出,不具备条件直接报错返回。
总结:
其实就相当于在捕捉一个子进程退出的时候,阻塞则会一直等待,直到这个子进程退出,返回对应的值。
而非阻塞,如果刚好捕捉到子进程的退出则直接输出,如果没有捕捉到,也不进行等待,直接输出报错!如果没有捕捉到,也不进行等待,直接输出报错!