Go学习圣经:0基础精通GO开发与高并发架构(1)
GO 学习圣经:底层原理和实操
说在前面:
现在拿到offer超级难,甚至连面试电话,一个都搞不到。
尼恩的技术社群中(50+),很多小伙伴凭借 “左手云原生+右手大数据”的绝活,拿到了offer,并且是非常优质的offer,据说年终奖都足足18个月。
从Java高薪岗位和就业岗位来看,云原生、K8S、GO 现在对于 高级工程师/架构师来说,越来越重要。尼恩从架构师视角出发,基于自己的尼恩 3高架构师知识体系和知识宇宙,写一本《GO学习圣经》

最终的学习目标
咱们的目标,不仅仅在于 GO 应用编程自由,更在于 GO 架构自由。
前段时间,一个2年小伙伴希望涨薪到18K, 尼恩把GO 语言的项目架构,给他写入了简历,导致他的简历金光闪闪,脱胎换股,完全可以去拿头条、腾讯等30K的offer, 年薪可以直接多 20W。
足以说明,GO 架构的含金量。
另外,前面尼恩的云原生是没有涉及GO的,但是,没有GO的云原生是不完整的。
所以, GO语言、GO架构学习完了之后,咱们在去打个回马枪,完成云原生的第二部分: 《Istio + K8S CRD的架构与开发实操》 ,帮助大家彻底穿透云原生。

本文目录
文章目录
- GO 学习圣经:底层原理和实操
-
- 说在前面:
- 最终的学习目标
- 本文目录
- 学习 GO 的相关资料:
- Go/C/C++/Java四大语言的对比
-
- 面向过程C语言
- 面向对象 C++语言
- Java语言
- Golang:
- Golang与Java等其他语言的对比
-
- Java
- c#
- C/C++
- Javascript
- Python
- scala
- Go
- Go语言的官网
- Go语言主要发展过程
- Go语言的特色
- Go语言的核心特性
-
- 1 并发:
- 2 内存回收(GC)
- 3 内存分配
- 4 快速编译:
- 5 简单易学
- 6 跨平台支持:
- 7 丰富的工具链:
- 8 天然支持网络编程:
- Go语言行业案例
- GO语言产生的宽松工作环境
- Go语言开发环境搭建
-
- 常用链接
- Go语言SDK工具包括以下几种:
- Go编译器SDK的安装
- GoLang SDK 安装和 Java SDK的安装比较
- Golang 集成开发工具IDE
- GoLand 安装和使用
-
- 创建项目:
- 配置Go SDK:
- 编写代码:
- 编写一个 hello world 案例:
- 运行程序:
- Go的执行原理以及Go的命令
-
- Go 的源码文件分类:
-
- 1、命令源码文件:
- 2、库源码文件
- 3、测试源码文件
- 主要的Go的命令
- 1、go run
-
- 详解:go run命令 的执行过程
- go run命令 的执行步骤
- 什么是.a 文件?
- go run 的参数详解
- `importcfg.link` 文件
- 2、go build
-
- 详解: go build 究竟干了些什么呢?
- go build 命令参数
- 3、go install 命令
-
- 什么 是`GOBIN` ?
- 详解: go install 究竟干了些什么呢?
- go install 命令参数
- 4、go get
- 5、其他命令
-
- go clean
- go fmt
- go test 命令
- go fix
- go version
- go env
- go list
- golang 代码规范
-
- 好的规范的价值
- Import 规范
- 错误处理
- panic
- recover
- 单元测试
- 类型断言失败处理
- 注释
- 命名规范
-
- 包命名
- 文件命名
- 结构体命名
- 接口命名
- 首字母访问控制规则
- 方法命名
- 变量命名
- 常量命名
- 单元测试命名
- 控制结构
- 函数
- Defer
- 魔法数字
- 代码规范性常用工具
- 包和文件
-
- 包的价值: 进行模块的隔离
- 包的init 初始化函数
- 包的导入
- 作用域
- 文件命名
- 函数
-
- 函数定义:
- 函数如何调用
- 函数的变长参数
- 只有声明没有body的函数
- 返回多值的函数
- 命名返回值
- 匿名返回值
- 将函数作为参数传递
- 内置函数
- 递归函数
- 匿名函数
- 闭包函数
- defer延迟函数
- 变量
-
- 变量的初始化
- 短变量声明
- 零值
- 常量
-
- 数值常量
- GO数据基本类型
-
- 类型转换
- 类型推导
- 整型
- 浮点型
- 复数
- 布尔型
- rune类型
- 字符串
- 整型运算
- bit位操作运算符:
- 复合数据类型
-
- 数组
-
- 一个数组的案例
- 数组的定义
- 元素的访问
- 数组作为参数
- Slice
-
- 从数组或切片生成新的切片
- 一个Slice的案例
- 从指定范围中生成切片
- 重置切片,清空拥有的元素
- 直接声明新的切片
- 共享底层的数据
- 切片Slice的长度len与容量cap
- slice创建方式
- 使用 make() 函数构造切片
- append()为切片添加元素
- 切片复制(切片拷贝)
- Go语言从切片中删除元素
-
- 从开头位置删除
- 从中间位置删除
- 从尾部删除
- range循环迭代切片
-
- range 提供了每个元素的副本
- 使用空白标识符(下划线)来忽略索引值
- 使用传统的 for 循环对切片进行迭代
- 映射Map
-
- map的申明和创建
- map的使用案例
- 禁止对map元素取址
- 结构体
-
- 一个结构体的例子
- 结构体参数传递方式
- 结构体组合函数
- 结构体特性
- 结构体嵌入和匿名成员
- 结构体tag
- & 和 `*符号`的区别
- JSON
-
- 解析JSON
- 反序列化:json解析到结构体
- 序列化:结构体转json
- json中的Encoder和Decoder
- 流程控制语句:for、if、else、switch 和 defer
-
- for语句
-
- for 使用案例
- for 是 Go 中的 “while”
- 无限循环
- if语句
-
- if 后的简短语句
- switch 语句
-
- switch 的例子
- switch 的求值顺序
- 没有条件的 switch
- defer语句
-
- defer 栈
- panic异常
-
- panic 使用示例
- 错误和异常
- 异常处理流程
- recover捕获异常
- 还有 5W字待发布
- 参考文献:
- 技术自由的实现路径 PDF:
-
-
- 实现你的 架构自由:
- 实现你的 响应式 自由:
- 实现你的 spring cloud 自由:
- 实现你的 linux 自由:
- 实现你的 网络 自由:
- 实现你的 分布式锁 自由:
- 实现你的 王者组件 自由:
- 实现你的 面试题 自由:
-
学习 GO 的相关资料:
The Go Programming Language (google.cn)
Dubbo Java 3.1.4 正式发布 | Apache Dubbo
dubbo-go
安装 Dubbo-go 开发环境 | Apache Dubbo
完成一次 RPC 调用 | Apache Dubbo
Go/C/C++/Java四大语言的对比
面向过程C语言
C语言产生的背景主要有以下几个方面:
- 软件危机:在20世纪60年代,随着计算机软件规模的扩大,软件设计和开发面临了巨大的挑战。很多软件项目的开发进度缓慢、成本高昂,甚至出现了完全失败的情况。为了解决这个问题,需要一种更加高效、可靠的编程语言。
- ALGOL语言的不足:ALGOL语言是20世纪60年代最流行的编程语言之一,但它的表达能力和可读性都不够强。因此,需要一种新的编程语言,既能保留ALGOL的优点,又能增强表达能力和可读性。
- UNIX操作系统的出现:在20世纪70年代初,贝尔实验室开发了UNIX操作系统,而操作系统的核心部分就是用C语言编写的。由于C语言效率高、灵活性好,逐渐成为了UNIX操作系统和其他系统软件的首选开发语言。
基于以上原因,Dennis Ritchie在20世纪70年代初开始着手开发C语言,并于1972年正式发布了第一个稳定版本。C语言具有效率高、表达能力强、可移植性好等特点,成为了通用编程语言中非常重要的一种。目前,C语言被广泛用于操作系统、嵌入式系统、程序语言解释器等方面,也是很多编程语言的基础。
到了70年代,诞生了一门非常重要的语言,这就是今天的大名鼎鼎的C语言。而C语言之父是美国著名的计算机专家。丹尼斯.利奇。
目前 C语言是世界上最常用的程序语言之一。

C语言之父:Dennis Ritchie(丹尼斯·里奇)。美国著名计算机专家、C语言发明人、UNIX之父。在1969-1973年期间发明了C语言和Unix操作系统。
面向对象 C++语言
1982年,美国贝尔实验室的Bjarne Stroustrup博士在C语言的基础上引入并扩充了面向对象的概念,发明了—种新的程序语言。为了表达该语言与c语言的渊源关系,它被命名为C++。
C++语言产生的背景主要有以下几个方面:
- C语言的问题:C语言是一种高效、灵活的编程语言,但它在类型安全性、模块化和代码复用等方面存在一些问题。因此,Bjarne Stroustrup希望开发一种新的编程语言,在保留C语言的优点基础上解决这些问题。
- 面向对象编程的兴起:在20世纪80年代,面向对象编程开始蓬勃发展,Smalltalk、Simula等语言引领了这股潮流。Bjarne Stroustrup希望能开发一种新的编程语言,可以实现面向对象编程。
- 硬件性能的提升:在20世纪80年代末和90年代初,计算机硬件性能得到了极大的提升,使得程序员可以使用更加复杂的编程语言来编写程序。因此,Bjarne Stroustrup希望开发一种新的编程语言,可以满足这种需求。
基于以上原因,Bjarne Stroustrup在1983年开始着手开发C++语言,并于1985年正式发布了第一个稳定版本。C++语言结合了C语言的效率和面向对象编程的特性,成为了通用编程语言中非常重要的一种。
C++语言被广泛用于游戏开发、操作系统、大型软件系统等领域,也是很多编程语言的基础。

C++之父:Bjarne Stroustrup(本贾尼·斯特劳斯特卢普)。
Java语言
1995年5月正式Java 发布。java的出现,正是互联网大力兴起的时候,而java因为语言的特性,在互联网上有很大的优势,发布最初就异常火爆。
Java语言产生的背景主要有以下几个方面:
- 面向对象编程的兴起:在上世纪80年代末和90年代初,面向对象编程开始逐渐成为主流编程范式,C++等语言受到广泛关注。Sun Microsystems公司希望能开发一种新的、更加高级的面向对象编程语言。
- 跨平台需求:在90年代初期,计算机硬件和操作系统环境比较复杂,软件需要针对不同的平台进行编写和调试。Sun Microsystems公司希望能开发一种新的编程语言,可以实现跨平台的编写和运行。
- 互联网的出现:互联网的出现让人们开始追求大规模分布式应用程序的开发。Sun Microsystems公司希望能开发一种新的编程语言,能够轻松地构建分布式网络应用程序。
基于以上原因,Sun Microsystems公司在1991年启动了Oak项目(后改名为Java),并于1995年正式发布了第一个稳定版本。Java语言最初被设计用于家电控制器,但随着互联网的发展,Java语言迅速成为网络应用程序的首选开发语言。目前,Java语言已经成为了企业级应用程序开发的主流,广泛应用于金融、电子商务、大数据等多个领域。
java最初的模型是在1991年的时候开发出,他的创始人詹姆斯高斯林。那个时候还叫做Oak橡树,后来詹姆斯希望使用java语言可以像喝咖啡一样轻松,愉悦。改名为java。

Java之父是James Gosling(詹姆斯.高斯林)。
Golang:
Go语言,也被称为Golang,是一种由Google公司开发的静态类型、编译型、并发性强的编程语言。
它最初于2007年由Robert Griesemer、Rob Pike和Ken Thompson等人设计,并于2009年正式发布第一个稳定版本。
Go语言产生的背景主要有以下几个方面:
- 并发编程需求:随着计算机性能的提升和互联网应用的普及,越来越多的应用需要具备高并发处理能力。然而,传统的编程语言如C++和Java等,在并发编程方面存在诸多问题。因此,Google公司希望开发一种新的编程语言,可以更好地满足这种需求。
- 程序员生产效率:Google公司拥有大量的程序员和代码库,而传统的编程语言复杂度较高,代码量也比较大,导致程序员生产效率不高。因此,Google公司希望开发一种简洁、易于学习和使用的编程语言。
- 代码安全性:在编写大型软件系统时,常常会出现缓冲区溢出等安全问题。因此,Google公司希望开发一种新的编程语言,可以避免这些问题。
基于以上原因,Google在2007年启动了Go语言的开发工作。
Go语言的设计者之一Rob Pike表示,Go语言的目标是“使编程更加愉悦和生产力更高”。
经过数年的开发和完善,Go语言逐渐得到广泛应用,并且在某些领域已经成为了首选语言。
Go语言在设计上注重简洁性和性能,目标是提供一种高效、可靠、易于编写和维护的系统级编程语言。它具有以下特点:
- 简单易学:Go语言语法简单,仅有25个关键字,易于学习和使用。
- 并发性强:Go语言原生支持协程和通道,可以轻松实现高并发程序。
- 内存管理:Go语言具有自动内存管理和垃圾回收机制,可以避免常见的内存错误。
- 高性能:Go语言编译速度快,生成的二进制文件体积小,运行速度快。
- 跨平台支持:Go语言可以在多个操作系统和硬件平台上编译执行。
- 天然支持网络:Go语言标准库中包含了丰富的网络编程接口,可以轻松实现Web应用程序。
总之,Go语言是一种面向现代编程需求的编程语言,其简洁性、高性能和并发性强等特点,使得其在互联网、大数据、网络编程等领域得到了广泛的应用。目前,Go语言已经成为了众多开发者的首选语言之一。

Go的三个作者分别是: Rob Pike(罗伯.派克),Ken Thompson(肯.汤普森)和Robert Griesemer(罗伯特.格利茨默)
Golang与Java等其他语言的对比
Golang、Java和C都是常见的编程语言,它们具有以下关系:
- Golang是由Google公司开发的一种编程语言,最初用于应对大规模网络应用程序的需求。Java也是由Sun Microsystems(现在是Oracle)发明的语言,目前被广泛应用于企业级应用程序的开发。
- Java和C都是传统的编程语言,已经有很长的历史和广泛的应用领域。与之相比,Golang是一种较为年轻的语言,但其标准库丰富、性能优越等特点使得其在某些场景下具有优势。
- Java和Golang都有良好的跨平台支持。Java使用Java虚拟机(JVM)来实现跨平台,而Golang则通过自身的编译器来实现跨平台。C虽然也可以实现跨平台,但需要手动编写平台相关的代码,并且不如Java和Golang方便。
- 在使用领域上,Java主要用于构建大型企业应用,例如电子商务网站、金融系统等;Golang则主要用于构建互联网应用、分布式系统和网络服务器等;而C则主要用于操作系统、嵌入式系统、驱动程序等方面。
- 在语言特性上,Java和Golang都是强类型语言,具有良好的代码可读性和维护性。C则是一种相对较为底层的编程语言,需要手动管理内存等资源。
总之,Golang、Java和C都是不同的编程语言,在特性、应用场景和语言生态等方面都有所不同。在选择使用何种编程语言时,需要根据实际应用需求和个人技能水平进行评估和选择。
Go的很多语言特性借鉴与它的三个祖先:C,Pascal和CSP。
Go的语法、数据类型、控制流等继承于C,Go的包、面对对象等思想来源于Pascal分支,而Go最大的语言特色,基于管道通信的协程并发模型,则借鉴于CSP分支。
Java
编译语言,速度适中(2.67s),目前的大型网站都是拿java写的,比如淘宝、京东等。
主要特点是稳定,开源性好,具有自己的一套编写规范,开发效率适中,目前最主流的语言。
作为编程语言中的大腕。具有最大的知名度和用户群。无论风起云涌,我自巍然不动。他强任他强,清风拂山岗;他横由他横,明月照大江。
c#
执行速度快(4.28),学习难度适中,开发速度适中。但是由于c#存在很多缺点,京东、携程等大型网站前身都是用c#开发的,但是现在都迁移到了java上。
C/C++
现存编程语言中的老祖,其他语言皆由此而生。执行速度最快无人能及。但是写起来最为复杂,开发难度大。
Javascript
编程语言中特立独行的傲娇美女。前端处理能力是其它语言无法比拟。发展中的js后端处理能力也是卓越不凡。前后端通吃,舍我其谁?
Python
脚本语言,速度最慢(258s),代码简洁、学习进度短,开发速度快。豆瓣就是拿python写的。Python著名的服务器框架有django,flask。但是python在大型项目上不太稳定,因此有些用python的企业后来迁移到了java上。
scala
编译语言,比python快十倍,和java差不多,但是学习进度慢,而且在实际编程中,如果对语言不够精通,很容易造成性能严重下降。,后来比如Yammer就从scala迁移到了java上。微服务框架有lagom等。
Go
编程界的小鲜肉。高并发能力无人能及。即具有像Python一样的简洁代码、开发速度,又具有C语言一样的执行效率,优势突出。
Go语言的官网
设计Go语言是为了解决当时Google开发遇到的问题:
- 大量的C++代码,同时又引入了Java和Python
- 成千上万的工程师
- 数以万计行的代码
- 分布式的编译系统
- 数百万的服务器
Google开发中的痛点:
- 编译慢
- 失控的依赖
- 每个工程师只是用了一个语言里面的一部分
- 程序难以维护(可读性差、文档不清晰等)
- 更新的花费越来越长
- 交叉编译困难
如何解决google的问题和痛点?
Go希望成为互联网时代的C语言。多数系统级语言(包括Java和C#)的根本编程哲学来源于C++,将C++的面向对象进一步发扬光大。但是Go语言的设计者却有不同的看法,他们认为值得学习的是C语言。C语言经久不衰的根源是它足够简单。因此,Go语言也是足够简单。
所以,他们当时设计Go的目标是为了消除各种缓慢和笨重、改进各种低效和扩展性。Go是由那些开发大型系统的人设计的,同时也是为了这些人服务的;它是为了解决工程上的问题,不是为了研究语言设计;它还是为了让我们的编程变得更舒适和方便。
但是结合Google当时内部的一些现实情况,如很多工程师都是C系的,所以新设计的语言一定要易学习,最好是类似C的语言;20年没有出新的语言了,所以新设计的语言必须是现代化的(例如内置GC)等情况。最后根据实战经验,他们向着目标设计了Go这个语言。
Go语言语法简单,包含了类C语法。因为Go语言容易学习,所以一个普通的大学生花几个星期就能写出来可以上手的、高性能的应用。在国内大家都追求快,这也是为什么国内Go流行的原因之一。
Go之所以叫Go,是想表达这门语言的运行速度、开发速度、学习速度(develop)都像gopher一样快。
gopher是一种生活在加拿大的小动物,go的吉祥物就是这个小动物, 它的中文名叫做囊地鼠,他们最大的特点就是挖洞速度特别快,当然可能不止是挖洞啦。

Go的官网: https://golang.google.cn/
Go语言主要发展过程
Go语言是谷歌2009发布的第二款开源编程语言。
Go语言专门针对多处理器系统应用程序的编程进行了优化,使用Go编译的程序可以媲美C或C++代码的速度,而且更加安全、支持并行进程。
- 2007年9月,雏形设计 ,Rob Pike(罗伯.派克) 正式命名为Go;
- 2008年5月,Google全力支持该项目;
- 2009年11月10日,首次公开发布,Go将代码全部开源,它获得了当年的年度语言;
- 2011年3月16日,Go语言的第一个稳定(stable)版本r56发布。
- 2012年3月28日,Go语言的第一个正式版本Go1发布。
- 2013年4月04日,Go语言的第一个Go 1.1beta1测试版发布。
- 2013年4月08日,Go语言的第二个Go 1.1beta2测试版发布。
- 2013年5月02日,Go语言Go 1.1RC1版发布。
- 2013年5月07日,Go语言Go 1.1RC2版发布。
- 2013年5月09日,Go语言Go 1.1RC3版发布。
- 2013年5月13日,Go语言Go 1.1正式版发布。
- 2013年9月20日,Go语言Go 1.2RC1版发布。
- 2013年12月1日,Go语言Go 1.2正式版发布。
- 2014年6月18日,Go语言Go 1.3版发布。
- 2014年12月10日,Go语言Go 1.4版发布。
- 2015年8月19日,Go语言Go 1.5版发布,本次更新中移除了”最后残余的C代码”。
- 2016年2月17日,Go语言Go 1.6版发布。
- 2016年8月15日,Go语言Go 1.7版发布。
- 2017年2月17日,Go语言Go 1.8版发布。
- 2017年8月24日,Go语言Go 1.9版发布。
- 2018年2月16日,Go语言Go 1.10版发布。
- 2018年8月24日,Go语言Go 1.11版发布。
- 2019年2月25日,GO语言Go1.12版发布。
Go 语言起源 2007 年,并于 2009 年正式对外发布。它从 2009 年 9 月 21 日开始作为谷歌公司 20% 兼职项目,即相关员工利用 20% 的空余时间来参与 Go 语言的研发工作。
其实可以看到,Go语言的历史不算很短。
2009年11月 GO语言第一个版本发布。2012年3月 第一个正式版本Go1.0发布。
2015年8月 go1.5发布,这个版本被认为是历史性的。完全移除C语言部分,使用GO编译GO,少量代码使用汇编实现。另外,他们请来了内存管理方面的权威专家Rick Hudson,对GC进行了重新设计,支持并发GC,解决了一直以来广为诟病的GC时延(STW)问题。并且在此后的版本中,又对GC做了更进一步的优化。到go1.8时,相同业务场景下的GC时延已经可以从go1.1的数秒,控制在1ms以内。GC问题的解决,可以说GO语言在服务端开发方面,几乎抹平了所有的弱点。
直到今年的2月25日,Go语言发布最新的版本是Go 1.12。
在GO语言的版本迭代过程中,语言特性基本上没有太大的变化,基本上维持在GO1.1的基准上,并且官方承诺,新版本对老版本下开发的代码完全兼容。事实上,GO开发团队在新增语言特性上显得非常谨慎,而在稳定性、编译速度、执行效率以及GC性能等方面进行了持续不断的优化。
Go语言的特色
Go语言具有以下几个特点:
- 高并发性:Go语言原生支持协程和通道,可以轻松实现高并发程序,并且在多核、分布式等场景下表现优异。
- 内存安全:Go语言通过垃圾回收机制和指针限制等手段,避免了常见的内存错误(如缓冲区溢出、野指针等),提高了程序的可靠性。
- 快速编译:Go语言的编译速度很快,即使在大型项目中也不会出现明显的编译延迟。同时,Go语言生成的可执行文件体积小,运行速度快。
- 简单易学:Go语言语法简单、结构清晰,易于学习和使用。它的标准库设计也非常简洁,便于开发者上手使用。
- 跨平台支持:Go语言可以在多个操作系统和硬件平台上编译执行,具有很好的跨平台支持性能。
- 丰富的工具链:Go语言提供了一系列的工具,例如go fmt、go vet、go test等,帮助开发者更加方便地进行代码格式化、检查、测试等工作。
- 天然支持网络编程:Go语言标准库中包含了丰富的网络编程接口,可以轻松实现Web应用程序和分布式系统等。
总之,Go语言是一种简单、高效、安全、易学、并发性强的编程语言。它因其多个特点而备受青睐,在互联网、大数据、网络编程等领域得到了广泛的应用。
简单来说, Go语言是一种 在执行效率和开发效率上都能兼备的语言。

go出现之前,无论汇编语言、还是动态脚本语言,在执行效率和开发效率上都不能兼备。
执行效率 execution speed: C/C++ > Java > PHP
开发效率 developing efficiency: PHP > Java > C/C++
Go语言的核心特性
Go语言之所以厉害,是因为它在服务端的开发中,总能抓住程序员的痛点,以最直接、简单、高效、稳定的方式来解决问题。
Go语言的核心特性包括以下几点:
1 并发:
Go语言天生具有高并发能力,通过goroutine(轻量级线程)和channel(通道)的方式,可以轻松实现并发编程,避免了多线程编程中的一些问题。
2 内存回收(GC)
从C到C++,从程序性能的角度来考虑,这两种语言允许程序员自己管理内存,包括内存的申请和释放等。因为没有垃圾回收机制所以C/C++运行起来速度很快,但是随着而来的是程序员对内存使用上的很谨小慎微的考虑。因为哪怕一点不小心就可能会导致“内存泄露”使得资源浪费或者“野指针”使得程序崩溃等,尽管C++11后来使用了智能指针的概念,但是程序员仍然需要很小心的使用。后来为了提高程序开发的速度以及程序的健壮性,java和C#等高级语言引入了GC机制,即程序员不需要再考虑内存的回收等,而是由语言特性提供垃圾回收器来回收内存。但是随之而来的可能是程序运行效率的降低。
GC过程是:先stop the world,扫描所有对象判活,把可回收对象在一段bitmap区中标记下来,接着立即start the world,恢复服务,同时起一个专门gorountine回收内存到空闲list中以备复用,不物理释放。物理释放由专门线程定期来执行。
GC瓶颈在于每次都要扫描所有对象来判活,待收集的对象数目越多,速度越慢。
一个经验值是扫描10w个对象需要花费1ms,所以尽量使用对象少的方案,比如我们同时考虑链表、map、slice、数组来进行存储,链表和map每个元素都是一个对象,而slice或数组是一个对象,因此slice或数组有利于GC。
GC性能可能随着版本不断更新会不断优化,这块没仔细调研,团队中有HotSpot开发者,应该会借鉴jvm gc的设计思想,比如分代回收、safepoint等。
- 内存自动回收,再也不需要开发人员管理内存
- 开发人员专注业务实现,降低了心智负担
- 只需要new分配内存,不需要释放
3 内存分配
初始化阶段直接分配一块大内存区域,大内存被切分成各个大小等级的块,放入不同的空闲list中,对象分配空间时从空闲list中取出大小合适的内存块。
内存回收时,会把不用的内存重放回空闲list。
空闲内存会按照一定策略合并,以减少碎片。
4 快速编译:
Go语言的编译速度相对较快,在大型项目中也不会出现明显的编译延迟。同时,Go语言生成的可执行文件体积小,运行速度快。
5 简单易学
Go语言语法简单、结构清晰,易于学习和使用。它的标准库设计也非常简洁,便于开发者上手使用。
6 跨平台支持:
Go语言可以在多个操作系统和硬件平台上编译执行,具有很好的跨平台支持性能。
7 丰富的工具链:
Go语言提供了一系列的工具,例如go fmt、go vet、go test等,帮助开发者更加方便地进行代码格式化、检查、测试等工作。
8 天然支持网络编程:
Go语言标准库中包含了丰富的网络编程接口,可以轻松实现Web应用程序和分布式系统等。
总之,Go语言具有高并发、内存安全、快速编译、简单易学、跨平台支持、丰富的工具链等核心特性,使得它成为一种很受欢迎的编程语言,在互联网、大数据、网络编程等领域得到了广泛的应用。
Go语言行业案例
Go语言在多个行业中都有广泛的应用,以下是一些代表性的行业案例:
- 互联网:谷歌、知乎等众多互联网公司都在采用Go语言进行后台开发。例如,谷歌的网络爬虫系统Google Crawler就是用Go语言编写的。
- 金融:很多金融领域的公司也开始采用Go语言进行开发。例如,美国在线支付公司Stripe使用Go语言编写了一个高性能的数据分析系统。
- 游戏:Go语言在游戏行业中也有着广泛应用。例如,腾讯的游戏服务器框架TarsGO就是用Go语言编写的。
- 大数据:Go语言具有高并发和高性能的特点,因此在大数据领域中也受到欢迎。例如,Uber公司的Cherami消息传递系统就是用Go语言编写的。
- 区块链:Go语言也成为了区块链领域的首选编程语言之一。例如,以太坊的客户端Geth就是使用Go语言编写的。
总之,Go语言在多个行业中都得到了广泛的应用,并且随着其不断完善和优化,其使用范围还将进一步扩大。

除了大名鼎鼎的Docker,完全用GO实现。业界最为火爆的容器编排管理系统kubernetes完全用GO实现。之后的Docker Swarm,完全用GO实现。
除此之外,还有各种有名的项目,如etcd/consul/flannel,七牛云存储等等均使用GO实现。
有人说,GO语言之所以出名,是赶上了云时代。
但为什么不能换种说法?也是GO语言促使了云的发展。
除了云项目外,还有像今日头条、UBER这样的公司,他们也使用GO语言对自己的业务进行了彻底的重构。
GO语言产生的宽松工作环境
go语言的产生,得益于谷歌 宽松的技术研究环境。
谷歌的“20%时间”工作方式,允许工程师拿出20%的时间来研究自己喜欢的项目。
语音服务Google Now、谷歌新闻Google News、谷歌地图Google Map上的交通信息等,全都是20%时间的产物。
Go语言最开始也是20%时间的产物。
这点,特别值得 国内大厂 学习。 国内大厂 流行 996,极致压榨 大家的 工作时间 ,严格管控 大家的 技术产出, 大家没有任何的 创新空间、创造空间。
国内大厂的管理方式,极度不利于技术创新。 享受不到技术创新、专利创新带来的 赢家通吃 红利。
Go语言开发环境搭建
常用链接
Go语言SDK工具包括以下几种:
- Go编译器:
Go编译器是将Go源代码编译成可执行文件的工具。Go编译器可以通过命令行或者集成开发环境(IDE)中进行使用。 - Go开发环境(IDE):
Go语言没有官方推荐的IDE,但是有很多第三方的IDE可以供开发者使用。
例如,GoLand、Visual Studio Code、Sublime Text等。 - Go fmt:
Go fmt是一个格式化代码的工具,可以让Go代码更加规范和易读。 - Go vet:
Go vet是一个静态代码分析工具,可以检查代码中的潜在问题,并提供相应的建议。 - Go test:
Go test是一个单元测试工具,可以帮助开发者编写测试用例并进行自动化测试。
总之,Go语言的开发工具丰富多样,可以根据个人需求选择最适合自己的工具进行开发。
Go编译器SDK的安装
Golang是一种编程语言,其安装和使用步骤如下:
安装Golang:
从官方网站下载对应操作系统的安装文件。
All releases - The Go Programming Language (google.cn)
尼恩的工具包里边,给大家都准备好了

Golang的官方网站提供了多个版本的二进制安装程序,可以根据不同的操作系统和硬件架构选择相应的版本。
- 对于Windows系统,可以下载.msi文件的安装程序,
- 对于Linux或Mac OS X系统,可以下载源代码或二进制文件的压缩包。
Windows系统,使用.msi文件的安装程序,一路按照向导,安装就ok了。

Golang的安装路径

配置环境变量:
安装完成后,我们需要将Golang的安装路径添加到系统的环境变量中。
对于Windows系统,可在“计算机”或“我的电脑”右键选择“属性”,在“高级系统设置”中点击“环境变量”,在“系统变量”中添加环境变量“GO_HOME”和“GOPATH”,分别指向Golang的安装路径和工作目录。
GO_HOME 指向 Golang的安装路径
GOPATH 指向 工作目录
GO_HOME 环境变量如下:

在Windows系统上,可以打开“控制面板” -> “系统与安全” -> “系统”,点击“高级系统设置”,然后点击“环境变量”按钮,在“系统变量”中找到“Path”变量,添加Golang的bin目录路径,例如“C:\Go\bin”。
C:\Program Files\Go\bin 已经自动进入到了 path 环境变量里边,不需要手动添加了:
对于Linux或Mac OS X系统,可将Golang的安装路径添加到PATH环境变量中,例如在~/.bashrc文件中添加:
export PATH=$PATH:/usr/local/go/bin
以上就是Golang的安装和使用步骤。Golang具有高效、简单、安全等优点,适合构建各种类型的应用程序,例如服务器、网络服务、命令行工具等。
GoLang SDK 安装和 Java SDK的安装比较
简直是一模一样,就是 名字不同而已。
Golang 集成开发工具IDE
以下是一些常用的 Golang 开发工具:
- GoLand:由 JetBrains 开发,拥有丰富的功能和插件支持的集成开发环境(IDE)。
- Visual Studio Code:轻量级的代码编辑器,使用 Go 扩展可以获得与 GoLand 类似的功能。
- Sublime Text:另一个流行的代码编辑器,也有很多插件可用于支持 Golang 开发。
- Vim:强大的文本编辑器,可以通过添加插件和配置来支持 Golang 开发。
- LiteIDE:专门为 Golang 打造的开发环境,支持自动补全等基本功能,适合初学者。
- Eclipse:一个广泛使用的 IDE,可以通过安装相应的插件来支持 Golang 开发。
以上是一些常用的 Golang 开发工具,您可以根据个人偏好选择最适合您的开发工具。
GoLand 安装和使用
大部分小伙伴,非常熟悉 JetBrains公司 的idea, 这里推荐的是 这个公司 提供的 GoLand。
GoLand是一款由JetBrains公司开发的集成开发环境(IDE),专门用于Go编程语言。
下面是GoLand的安装和使用步骤:
下载安装包:
从官方网站https://www.jetbrains.com/go/download/ 下载对应操作系统的安装文件。尼恩的工具包里边,给大家都准备好了
安装GoLand:
运行安装包并按照提示进行安装。
打开GoLand:
打开GoLand后,会看到一个欢迎界面。在这里可以新建项目、打开已有项目等。

创建项目:
在欢迎界面选择"Create New Project",选择项目类型和存储位置,然后点击"Create"按钮。
创建一个项目
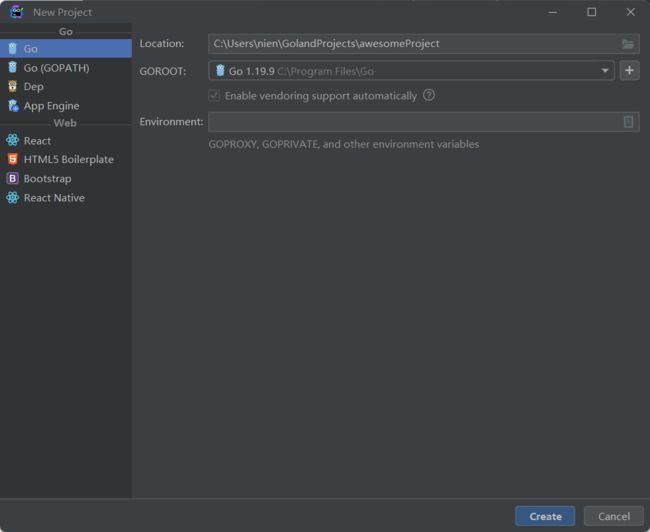
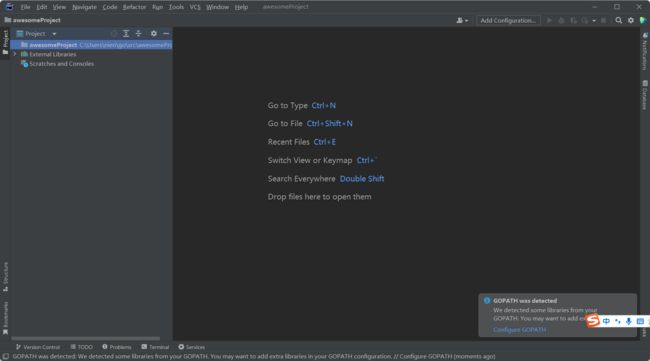
配置Go SDK:
打开File -> Settings菜单,在左侧导航栏中选择"Go",然后在右侧"GOROOT"选项中添加你的Go SDK路径,例如“/usr/local/go”。

完成之后,空项目如下:
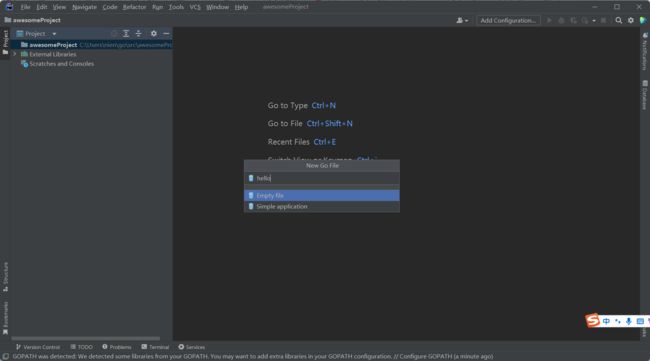
编写代码:
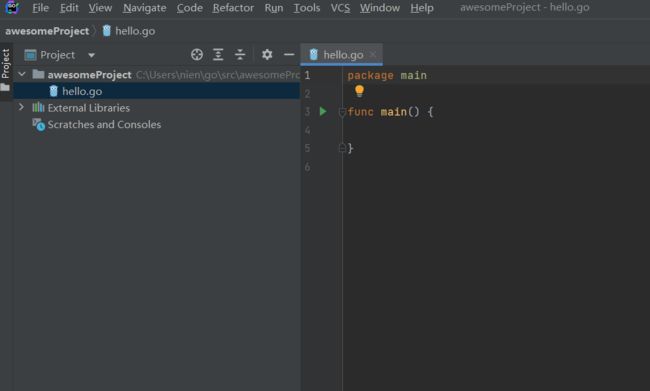
在编辑器中编写代码,new 一个新的文件,名字为hello,类型为 simple application , 如下:
新的go 文件创建好了,如下:
编写一个 hello world 案例:
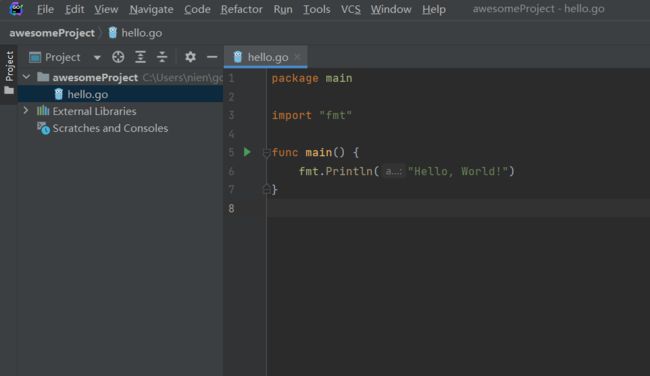
一共是两句:
- 一句是 import “fmt”
- 一句是 fmt.Println(“Hello, World!”)
第一句什么意思呢? import "fmt" 是 Go 语言中用于导入标准库 fmt 的语句。
fmt提供了格式化输入输出的函数,例如:Println() 和 Printf() 等,可以在控制台打印输出内容。
这个包也包括了一些其他的函数,如字符串格式化和解析、文件读写等。
使用 import "fmt" 可以让你在Go程序中使用fmt包中的函数,从而方便地进行输入输出操作。
例如上面的代码:
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
这段代码中,我们使用 import "fmt" 导入了 fmt 包。
第二句 fmt.Println(“Hello, World!”) 是什么意思呢?
fmt.Println("Hello, World!") 是 Go 语言中用于向控制台输出 “Hello, World!” 的语句。
Println 是位于 fmt 包中的 Println() 函数。
在这个例子中,我们使用 fmt.Println() 函数按顺序打印给定参数,并在最后一个参数后添加换行符。
因此,将 "Hello, World!" 作为参数传递给 fmt.Println() 函数将在控制台上显示 Hello, World! 并自动换行。
main() 函数中调用了 Println() 函数来输出 Hello, World! 到控制台上。
运行程序:
点击编辑器顶部的运行按钮(绿色三角形)或者使用快捷键Shift+F10来运行程序。
运行结果如下:

以上就是GoLand的安装和使用步骤。
GoLand具有良好的用户界面、丰富的功能和插件支持,可以提高开发效率,让Go语言的开发变得更加简单和高效。
Go的执行原理以及Go的命令
Go 的源码文件分类:
在 Go 中,源码文件分为4种类型:
- 命令源码文件:
- 以
.go为扩展名的文件 - 命令源码文件属于main包
- 包含main方法,是程序的运行入口,是每个可独立运行的程序必须拥有的。
- 库源码文件:
- 以
.go为扩展名的文件。 - 不包含main入口方法。
- 测试文件:
- 以
_test.go为后缀的源码文件 - 测试文件用于编写单元测试和性能测试等测试代码。
- C 语言源码文件:
以 .c、.h 或 .s 等后缀名的文件,用于包含一些 C 语言实现的辅助代码或工具。
- 无源码文件:
- 不包含代码的文件,例如 README、LICENSE 等。
- 这些文件虽然对于程序的运行没有影响,但对于开发者来说具有重要意义。
其中,.go 源码文件和 _test.go 测试文件是最常见的文件类型。
总体而言:
- 在一个 Go 工程中,通常将所有的源码文件组织在一个或多个 package 中,并对外提供相应的接口。测试文件则用于测试这些接口的正确性和性能。
- 除此之外,Go 还支持嵌套的 package 和 vendor 目录,使得工程的组织结构更加灵活和清晰。
- 同时,在 Go 编译时,会自动生成相关的二进制文件、静态库或动态链接库等文件。
1、命令源码文件:
命令源码文件的两个特征:
- 声明自己属于 main 代码包、
- 包含 main 函数, 这是一个无参数声明和结果声明、名字叫做 main 的函数。
命令源码文件 的作用:
- 命令源码文件是 Go 程序的入口。
- 命令源码文件是可以单独运行的。
可以使用 go run 命令直接运行,也可以通过 go build 或 go install 命令得到相应的可执行文件。所以命令源码文件是可以在机器的任何目录下运行的。
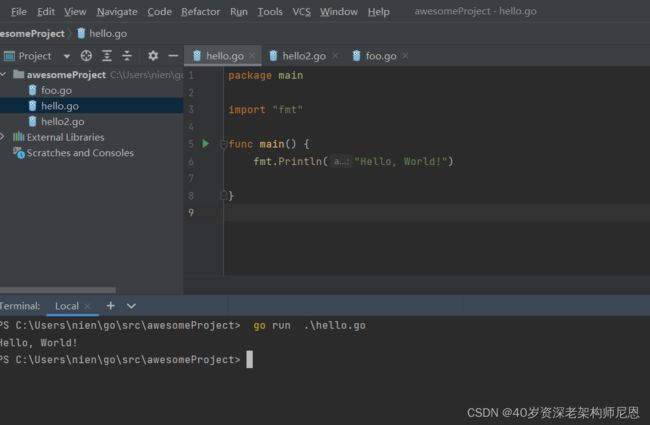
step1: 通过 go run 命令直接运行 命令源码文件:
同一个代码包中最好也不要放多个命令源码文件。多个命令源码文件虽然可以分开单独 go run 运行起来,但是无法通过 go build 和 go install。
命令源码文件被 go install 安装以后,变成了exe可执行文件,一般去了哪儿呢?
- 如果GOPATH 只有一个工作区,那么相应的可执行文件会被存放当前工作区的 bin 文件夹下;
- 如果有多个工作区,就会安装到 GOBIN 指向的目录下。
复制hello.go为hello2.go文件,并修改里面的内容:
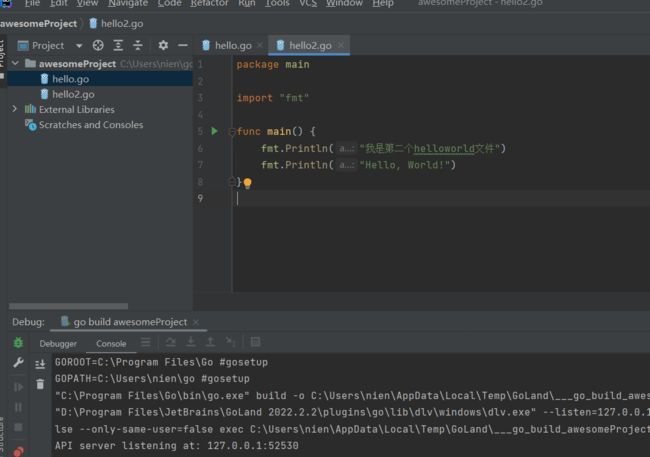
hello目录下有两个go文件了,两个命令源码文件:
- 一个是hello.go
- 一个是hello2.go。
先说明一下,在上述文件夹中放了两个命令源码文件,同时都声明自己属于 main 代码包 : package main 。
打开 控制台 终端,进入工目录,执行go run命令执行两个 命令源码文件,可以看到两个go文件都可以被执行:

上面执行go run没有问题,但是 执行 go build 和 go install 问题就来了。
看看会发生什么:
PS C:\Users\nien\go\src\awesomeProject> go build
# awesomeProject
.\hello2.go:5:6: main redeclared in this block
.\hello.go:5:6: other declaration of main
PS C:\Users\nien\go\src\awesomeProject> go install
# awesomeProject
.\hello2.go:5:6: main redeclared in this block
.\hello.go:5:6: other declaration of main
运行效果图:
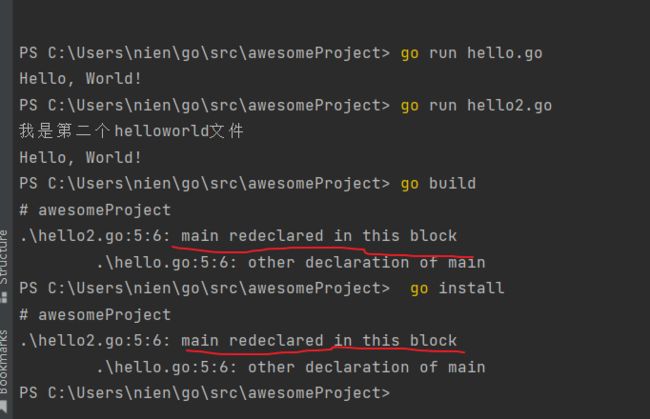
这也就证明了一个问题:多个命令源码文件虽然可以分开单独 go run 运行起来,但是无法通过 go build 和 go install。
2、库源码文件
库源码文件就是不具备命令源码文件上述两个特征的源码文件。存在于某个代码包中的普通的源码文件。
在 Go 语言中,库源码文件也需要遵循一定的命名规则和编写规范。
以下是一些通用的概念和步骤:
- 创建一个新的 package,package 名称应该与文件夹名称相同。
- 在 package 中编写代码,可以包含多个源码文件。
- 对外暴露需要让其他 package 访问的函数、类型或变量,需要在其名称前面添加大写字母。
func Add(a, b int) int {
return a + b
}
- 编写文档注释,可以使用
go doc命令来查看文档。
// Add 将两个整数相加并返回结果
func Add(a, b int) int {
return a + b
}
- 使用
go build或go install命令来构建和安装库,安装后可以在其他程序中 import 并使用。
$ go install github.com/xxx/yyy
以上是库源码文件的基本流程和示例,更多细节和高级用法可以参考官方文档:
How to Write Go Code - The Go Programming Language (google.cn)
库源码文件被安装后,相应的归档文件(.a 文件)会被存放到当前工作区的 pkg 的平台相关目录下。
3、测试源码文件
在 Go 语言中,测试源码文件需要遵循一定的命名规则和编写规范。
以下是一些通用的概念和步骤:
- 在同一个 package 中创建一个名为
xxx_test.go的文件,其中xxx是要测试的源码文件的名称。 - 在测试文件中导入
testing包。
import "testing"
- 编写测试函数,函数名以
Test开头,函数签名为func TestXxx(*testing.T),其中Xxx是要测试的函数的名称。
func TestAdd(t *testing.T) {
// 测试代码...
}
- 在测试函数中,可以使用
t.Error或t.Fail等方法判断测试结果是否符合预期。
func TestAdd(t *testing.T) {
if add(1, 2) != 3 {
t.Errorf("add function failed")
}
}
- 运行测试程序,可以使用
go test命令来运行当前目录下所有测试文件。
$ go test
PASS
ok command-line-arguments 0.001s
更多细节和高级用法可以参考官方文档:https://golang.google.cn/pkg/testing/
另外,名称以 _test.go 为后缀的代码文件,并且必须包含 Test 或者 Benchmark 名称前缀的函数:
- TestXXX 是功能测试函数
- BenchmarkXXX 性能测试函数
具体如下:
func TestXXX( t *testing.T) {
}
名称以 Test 为名称前缀的函数,只能接受 *testing.T 的参数,这种测试函数是功能测试函数。
func BenchmarkXXX( b *testing.B) {
}
名称以 Benchmark 为名称前缀的函数,只能接受 *testing.B 的参数,这种测试函数是性能测试函数。
主要的Go的命令
目前Go的最新版1.12里面基本命令有以下17个。
我们可以打开终端输入:go help即可看到Go的这些命令以及简介。
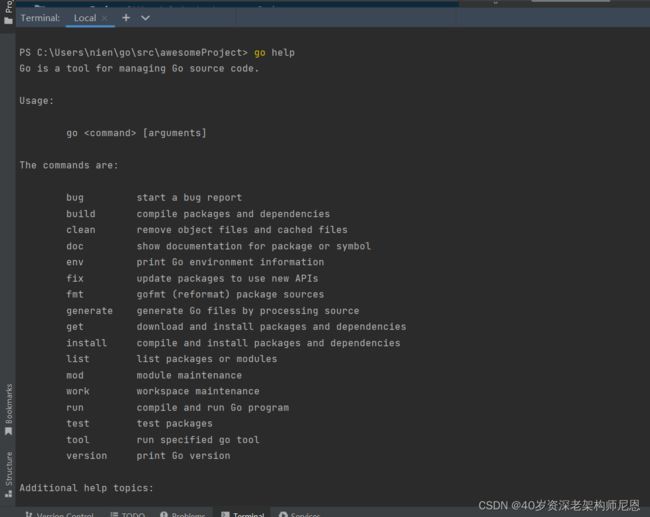
其中和编译相关的有build、get、install、run这4个。接下来就依次看看这四个的作用。
在详细分析这4个命令之前,先罗列一下通用的命令标记,以下这些命令都可适用的:
| 名称 | 说明 |
|---|---|
| -a | 用于强制重新编译所有涉及的 Go 语言代码包(包括 Go 语言标准库中的代码包),即使它们已经是最新的了。该标记可以让我们有机会通过改动底层的代码包做一些实验。 |
| -n | 使命令仅打印其执行过程中用到的所有命令,而不去真正执行它们。如果不只想查看或者验证命令的执行过程,而不想改变任何东西,使用它正好合适。 |
| -race | 用于检测并报告指定 Go 语言程序中存在的数据竞争问题。当用 Go 语言编写并发程序的时候,这是很重要的检测手段之一。 |
| -v | 用于打印命令执行过程中涉及的代码包。这一定包括我们指定的目标代码包,并且有时还会包括该代码包直接或间接依赖的那些代码包。这会让你知道哪些代码包被执行过了。 |
| -work | 用于打印命令执行时生成和使用的临时工作目录的名字,且命令执行完成后不删除它。这个目录下的文件可能会对你有用,也可以从侧面了解命令的执行过程。如果不添加此标记,那么临时工作目录会在命令执行完毕前删除。 |
| -x | 使命令打印其执行过程中用到的所有命令,并同时执行它们。 |
1、go run
go run 命令是 Go 语言内置的一个命令,用于编译并运行一个或多个 Go 源代码文件。
其功能,大致类似于 Java语言当中的 javac + java 两个命令的组合,也就是先编译,后运行。
它可以在不产生可执行文件的情况下直接运行 Go 程序,对于一些小型的项目或者临时测试可以省去编译过程。
注意,这个命令不是用来运行所有 Go 的源码文件的!go run 命令只能接受一个命令源码文件以及若干个库源码文件(必须同属于 main 包)作为文件参数,且不能接受测试源码文件。
它在执行时会检查源码文件的类型。如果参数中有多个或者没有命令源码文件,那么 go run 命令就只会打印错误提示信息并退出,而不会继续执行。
下面介绍 go run 命令的详细用法:
- 只有一个源文件
如果只有一个源文件,使用go run命令非常简单,只需要指定源文件的路径即可运行程序:
$ go run hello.go
- 多个源文件
如果有多个源文件,可以将所有源文件都列出来,按照依赖关系进行编译运行:
$ go run file1.go file2.go file3.go
或者使用通配符匹配所有符合条件的源文件:
$ go run *.go
- 传递参数
我们可以通过在go run命令后面加上参数来传递参数给程序。这些参数会保存在os.Args切片中,可以在程序中访问。例如:
$ go run hello.go arg1 arg2 arg3
- 交互式输入
如果需要从标准输入读取用户输入,可以使用fmt.Scan等函数读取输入:
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
var input string
fmt.Scanln(&input)
fmt.Println("你的输入是:%s", input)
}
然后通过 go run 命令运行程序并在终端中输入:
$ go run hello.go

- 指定环境变量
可以使用 -e 标志来设置一个或多个环境变量。
$ go run -e GOPATH=$HOME/go hello.go
接下来,看看 go run 的执行过程。 这个命令具体干了些什么事情呢?
详解:go run命令 的执行过程
go run 命令的执行过程可以分为以下几个步骤:
- Go 工具链会自动查找当前目录下所有以
.go结尾的文件,并将它们编译成一个可执行文件。如果有多个文件,则根据文件名进行依赖排序。 - 编译完成后,Go 工具链会将生成的二进制文件加载到内存中,并使用运行时环境来运行程序。
- Go 运行时初始化一些必要的资源,例如 Goroutine 调度器、垃圾回收器等。
- 程序开始执行
main()函数,命令行参数保存在os.Args切片中。 - 如果程序需要从标准输入读取用户输入,Go 运行时会阻塞等待用户输入。
- 当程序执行完毕或者遇到异常情况(例如 panic、os.Exit),Go 运行时会释放已分配的资源,并将控制权返回给操作系统。
总之,go run 命令实际上是将 Go 源代码编译成可执行文件并直接运行该可执行文件。由于没有产生中间文件,所以这个过程非常快速和方便。
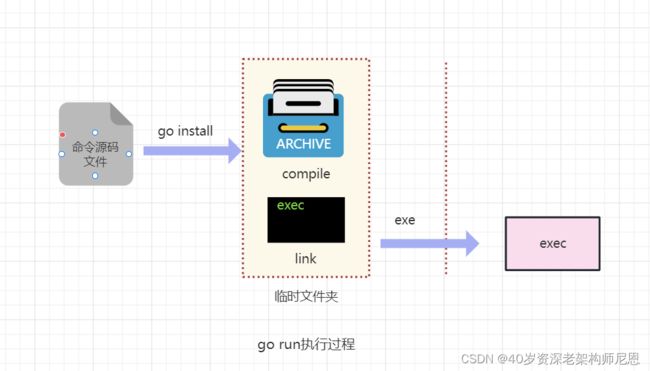
go run命令 的执行步骤
第一步是 compile: 编译 成为 .a 文件
第二步是 link: 链接其他的 .a 文件 ,成为 exe 文件
第三步是exec: 执行 exe 文件
示例:
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
var input string
fmt.Scanln(&input)
fmt.Println("你的输入是:%s", input)
}

什么是.a 文件?
在 Golang 中,.a 文件是静态库文件,也被称为归档文件。
.a 文件包含了一组已编译的目标文件(.o 文件)和一个索引表,用于快速查找其中的符号。当链接程序需要使用这些目标文件中的符号时,它可以从 .a 文件中提取所需的目标文件,并将它们与其他目标文件和库链接在一起。
使用静态库文件可以将代码打包成一个单独的文件,方便分发和使用。
.a文件是编译过程中生成的,每个package都会生成对应的.a文件,Go在编译的时候先判断package的源码是否有改动,如果没有的话,就不再重新编译.a文件,这样可以加快速度。
在链接时,链接器会将静态库文件中的代码复制到最终的可执行文件中,因此可执行文件不需要依赖外部的库文件。
但是,静态库文件的缺点是它们会增加可执行文件的大小,并且每次更新库文件时都需要重新编译整个程序。
go run源码 和源码编译后再执行 ,有何区别呢?
1.如果是对源码编译后再执行,Go的执行流程细节如下:
- .go文件(源文件)——>go build(编译)——>可执行文件(.exe或可执行文件)——>运行——>结果
2.如果我们是对源代码直接执行go run源码,Go的执行流程细节如下:
- .go文件(源文件)——>go run(编译运行下一步)——>结果
- 两种编译方式的区别是 第一个是通过go build生成一个exe的可执行文件,在通过运行exe二进制文件运行结果,第二中是通过用go run来直接运行,第一种会直接运行时间快,第二种会比第一种长,因为编译和运行放在一起了。
问题:如果看到 go run 的执行过程呢? 可以使用 -n 选项。
go run -n 命令可以实现将 go run 命令所执行的编译和链接过程打印出来而不运行程序。这个命令非常有用,可以检查代码是否正确编译和链接以及依赖库是否正确引入。
需要注意的是,go run -n 命令只是将编译、汇编和链接输出到控制台,而不会运行生成的可执行文件。如果需要运行程序,请使用 go run 命令或者直接运行生成的可执行文件。
下面是一个使用 go run -n 命令的示例:
PS C:\Users\nien\go\src\awesomeProject> go run -n hello.go
mkdir -p $WORK\b001\
cat >$WORK\b001\importcfg.link << 'EOF' # internal
packagefile command-line-arguments=C:\Users\nien\AppData\Local\go-build\69\692a2eab765b2347d83f7dbba3333eeb19fd3151614ee8c7a70f2d5270f9fa95-d
packagefile fmt=C:\Program Files\Go\pkg\windows_amd64\fmt.a
packagefile runtime=C:\Program Files\Go\pkg\windows_amd64\runtime.a
packagefile errors=C:\Program Files\Go\pkg\windows_amd64\errors.a
packagefile internal/fmtsort=C:\Program Files\Go\pkg\windows_amd64\internal\fmtsort.a
packagefile io=C:\Program Files\Go\pkg\windows_amd64\io.a
packagefile math=C:\Program Files\Go\pkg\windows_amd64\math.a
packagefile os=C:\Program Files\Go\pkg\windows_amd64\os.a
packagefile reflect=C:\Program Files\Go\pkg\windows_amd64\reflect.a
packagefile strconv=C:\Program Files\Go\pkg\windows_amd64\strconv.a
packagefile sync=C:\Program Files\Go\pkg\windows_amd64\sync.a
packagefile unicode/utf8=C:\Program Files\Go\pkg\windows_amd64\unicode\utf8.a
packagefile internal/abi=C:\Program Files\Go\pkg\windows_amd64\internal\abi.a
packagefile internal/bytealg=C:\Program Files\Go\pkg\windows_amd64\internal\bytealg.a
packagefile internal/cpu=C:\Program Files\Go\pkg\windows_amd64\internal\cpu.a
packagefile internal/goarch=C:\Program Files\Go\pkg\windows_amd64\internal\goarch.a
packagefile internal/goexperiment=C:\Program Files\Go\pkg\windows_amd64\internal\goexperiment.a
packagefile internal/goos=C:\Program Files\Go\pkg\windows_amd64\internal\goos.a
packagefile runtime/internal/atomic=C:\Program Files\Go\pkg\windows_amd64\runtime\internal\atomic.a
packagefile runtime/internal/math=C:\Program Files\Go\pkg\windows_amd64\runtime\internal\math.a
packagefile runtime/internal/sys=C:\Program Files\Go\pkg\windows_amd64\runtime\internal\sys.a
packagefile internal/reflectlite=C:\Program Files\Go\pkg\windows_amd64\internal\reflectlite.a
packagefile sort=C:\Program Files\Go\pkg\windows_amd64\sort.a
packagefile math/bits=C:\Program Files\Go\pkg\windows_amd64\math\bits.a
packagefile internal/itoa=C:\Program Files\Go\pkg\windows_amd64\internal\itoa.a
packagefile unicode/utf16=C:\Program Files\Go\pkg\windows_amd64\unicode\utf16.a
packagefile unicode=C:\Program Files\Go\pkg\windows_amd64\unicode.a
packagefile internal/race=C:\Program Files\Go\pkg\windows_amd64\internal\race.a
packagefile internal/syscall/windows/sysdll=C:\Program Files\Go\pkg\windows_amd64\internal\syscall\windows\sysdll.a
packagefile path=C:\Program Files\Go\pkg\windows_amd64\path.a
packagefile internal/syscall/windows/registry=C:\Program Files\Go\pkg\windows_amd64\internal\syscall\windows\registry.a
modinfo "0w\xaf\f\x92t\b\x02A\xe1\xc1\a\xe6\xd6\x18\xe6path\tcommand-line-arguments\nbuild\t-compiler=gc\nbuild\tCGO_ENABLED=1\nbuild\tCGO_CFLAGS=\nbuild\tCGO_CPPFLAGS=\nbuild\tCGO_CXXFLAGS=\nbuild\tCGO_LDFLAGS=\nbuild\tGOARCH=amd64\nbuild\tGOOS=windows\nbuild\tGOAMD64=v1\n\xf92C1\x86\x18 r\x00\x82B\x10A\x16\xd8\xf2"
EOF
mkdir -p $WORK\b001\exe\
cd .
"C:\\Program Files\\Go\\pkg\\tool\\windows_amd64\\link.exe" -o "$WORK\\b001\\exe\\hello.exe" -importcfg "$WORK\\b001\\importcfg.link" -s -w -buildmode=pie -buildid=0bpO_A9QPFYvfKrLftok/uW5e8pk9X87KweqPqgKm/3kCXaL5ldAaRrmyF6wVL/0bpO_A9QPFYvfKrLftok -extld=gcc "C:\\Users\\nien\\AppData\\Local\\go-build\\69\\692a2eab765b2347d83f7dbba3333eeb19fd3151614ee8c7a70f2d5270f9fa95-d"
$WORK\b001\exe\hello.exe
这里可以看到创建了两个临时文件夹 b001 和 exe,先执行了 compile 命令,然后 link,生成了归档文件.a 和 最终可执行文件,最终的可执行文件放在 exe 文件夹里面。
命令的最后一步就是执行了可执行文件。
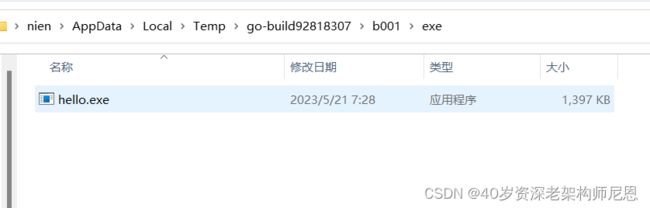
go run 的参数详解
命令格式:go run [可选参数] 。
命令作用:编译完成并马上运行 Go 程序。
特殊说明:go run 只支持属于 main 包的一个或多个文件作为参数,不然是不能进行编译的。如下示例:
1. 有一个属于包 hello 的文件 hello.go。
2. 执行编译 go run hello/hello.go
然后提示错误:go run: cannot run non-main package
常用参数:
| 参数名 | 格式 | 含义 |
|---|---|---|
| -o | -o file | 指定编译后二进制文件名 |
| -importcfg | -importcfg file | 从文件中读取倒入配置 |
| -s | -s | 省略符号表并调试信息 |
| -w | -w | 省略 DWARF 符号表 |
| -buildmode | -buildmode mode | 设置构建模式 - 默认为 exe |
| -buildid | -buildid id | 将ID记录为Go工具链的构建ID |
| -extld | -extld linker | 设置外部链接器 - 默认为 clang 或者 gcc |
| -work | -work | 设置该参数后不会在程序结束后删掉编译的临时文件,可用于参看编译生成的文件 |
| -n | -n | 加上该参数可以查看编译的过程,但不会继续执行编译后的二进制文件 |
| -x | -x | 加上该参数可以查看编译的过程,会继续执行编译后的二进制文件 |
这里需要对后面两个参数进行额外说明。
在使用 go run 编译时候会将二进制文件放到一个临时目录(位置和操作系统或GOTMPDIR有关。
所以想进行查看可以使用 -s 或 -n 命令。这里简单执行如下:
执行:go run -n -work hello.go
输出:(不同的环境和版本可能有一些区别)
上面的输出主要干了这些事:
- 创建编译依赖需要的临时目录。在编译过程中设置一个临时环境变量 WORK,用于编译的工作区并执行编译后的二进制文件。可以通过 GOTMPDIR 设置。
- 编译和生产编译所需的依赖。编译如标准库、外部依赖、自身代码,然后生成、链接对应的归档和编译配置文件。
- 创建exe目录。 创建并进入编译二进制需要的零食目录。
- 生成可执行文件。
- 执行可执行文件。如上列中:$WORK/b001/exe/hello.exe。
可以看到,最终go run命令是生成了2个文件,一个是归档文件,一个是可执行文件。
归档文件在哪儿呢?
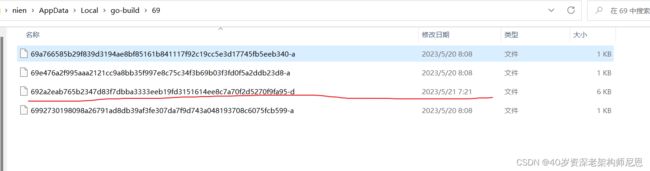
go run 命令在第二次执行的时候,如果发现导入的代码包没有发生变化,那么 go run 不会再次编译这个导入的代码包。直接静态链接进来。
importcfg.link 文件
importcfg.link 是 Go 1.17 中引入的一个新特性,用于指定链接器的行为。
importcfg.link 文件是一个文本文件,其中包含一组指令,可以控制程序的链接方式和依赖项。
在默认情况下,Go 工具链会自动处理程序的依赖关系并链接生成可执行文件。但是在某些情况下,例如需要使用特定的链接器、链接静态库或者禁止使用某些库等,可能需要手动配置链接器的行为。
下面是一个 importcfg.link 文件的示例:
packagefile mypkg.a=/path/to/mypkg.a
import (
"crypto/tls"
_ "github.com/mattn/go-sqlite3"
)
unresolved x/x_test.go: import "x" is not a known import path.
在上面的示例中,我们使用 packagefile 指令将 mypkg.a 静态库的路径设置为 /path/to/mypkg.a,然后使用 import 命令导入 crypto/tls 和 github.com/mattn/go-sqlite3 包,并显示一个 unresolved 的错误消息来指示未知的导入路径。
**需要注意的是,**只有在支持 -importcfg 标志的 Go 工具链版本中才能使用 importcfg.link 文件,例如 Go 1.17 及更高版本。对于旧版本的 Go 工具链,可以使用 -extldflags 等标志来手动指定链接器的行为。
2、go build
go build 命令主要是用于测试编译。在包的编译过程中,若有必要,会同时编译与之相关联的包。
- 如果是普通包,当你执行go build命令后,不会产生任何文件。
- 如果是main包,当只执行go build命令后,会在当前目录下生成一个可执行文件。如果需要在$GOPATH/bin目录下生成相应的exe文件,需要执行go install 或者使用 go build -o 路径/可执行文件。
- go build 命令默认会编译当前目录下的所有go文件。如果某个文件夹下有多个文件,而你只想编译其中某一个文件,可以在 go build 之后加上文件名,例如 go build a.go;
- 你也可以指定编译输出的文件名。比如,我们可以指定go build -o 可执行文件名,默认情况是你的package名(非main包),或者是第一个源文件的文件名(main包)。
- go build 会忽略目录下以”_”或者”.”开头的go文件。
- 如果你的源代码针对不同的操作系统需要不同的处理,那么你可以根据不同的操作系统后缀来命名文件。
go build 用于编译我们指定的源码文件或代码包以及它们的依赖包。但是注意如果用来编译非命令源码文件,即库源码文件,go build 执行完是不会产生任何结果的。这种情况下,go build 命令只是检查库源码文件的有效性,只会做检查性的编译,而不会输出任何结果文件。
go build 编译命令源码文件,则会在该命令的执行目录中生成一个可执行文件,来个 例子也印证了这个过程。
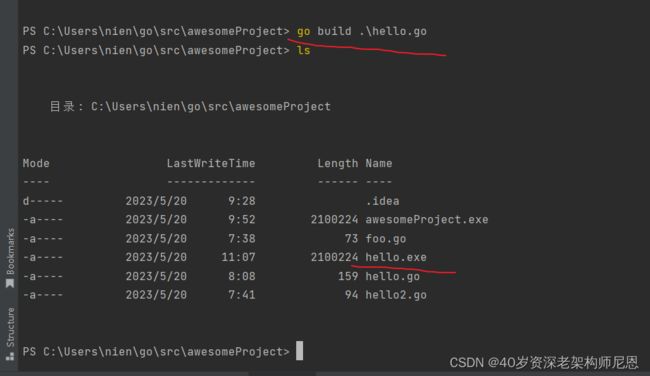
编译后,得到 exe 文件。
目录在哪儿呢? go build 后面不追加目录路径的话,它就把当前目录作为代码包并进行编译。
go build -o bin/hello.exe hello.go
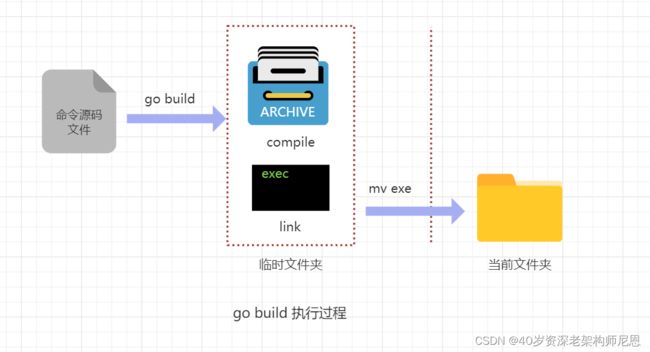
详解: go build 究竟干了些什么呢?
go build 命令究竟做了些什么呢?
go build 执行过程和 go run 大体相同,唯一不同的就是在最后一步,go run 是执行了可执行文件,但是 go build 命令,只是把库源码文件编译了一遍,然后把可执行文件移动到了当前目录的文件夹中。
总结一下如下图:
go build 命令参数
命令格式:go build [可选参数] 。
命令作用:编译指定的源文件、软件包和其他依赖,但是不会在编译后执行二进制文件。
特殊说明:go build 和 go run 在编译过程中其实是差不多的,不同之处是 go build 会生成编译好二进制文件并删掉编译过程产生的临时目录。若没有-o 指定文件名,则和当前目录名一致。
执行: go build -x main.go
输出:
...
...
mv $WORK/b001/exe/a.out main
// 多了这步
rm -r $WORK/b001/
常用参数:
| 参数名 | 格式 | 含义 |
|---|---|---|
| -o | -o file | 指定编译后二进制文件名 |
| -a | -a | 强制重新编译涉及的依赖 |
| -s | -s | 省略符号表并调试信息 |
| -w | -w | 省略 DWARF 符号表 |
| -p | -p | 指定编译过程中的并发数,默认为CPU数 |
| -work | -work | 设置该参数后不会在程序结束后删掉编译的临时文件,可用于参看编译生成的文件 |
| -n | -n | 加上该参数可以查看编译的过程,但不会继续执行编译后的二进制文件 |
| -x | -x | 加上该参数可以查看编译的过程,会继续执行编译后的二进制文件 |
3、go install 命令
go install 命令是用来编译并安装代码包或者源码文件的。
go install 命令在内部实际上分成了两步操作:
- 第一步是生成结果文件(可执行文件或者.a包),
- 第二步会把编译好的结果移到
$GOPATH/pkg或者$GOPATH/bin。
实际上,go install 命令只比 go build 命令多做了一件事,即:安装编译后的结果文件到指定目录。
什么时候生产 可执行文件? 什么时候生产.a应用包?
- 可执行文件: 一般是 go install 带main函数的go文件产生的,有函数入口,所有可以直接运行。
- .a应用包: 一般是 go install 不包含main函数的go文件产生的,没有函数入口,只能被调用。
go install 用于编译并安装指定的代码包及它们的依赖包。当指定的代码包的依赖包还没有被编译和安装时,该命令会先去处理依赖包。与 go build 命令一样,传给 go install 命令的代码包参数应该以导入路径的形式提供。并且,go build 命令的绝大多数标记也都可以用于
安装代码包会在当前工作区的 pkg 的平台相关目录下生成归档文件(即 .a 文件)。安装命令源码文件会在当前工作区的 bin 目录(如果 GOPATH 下有多个工作区,就会放在 GOBIN 目录下)生成可执行文件。
同样,go install 命令如果后面不追加任何参数,它会把当前目录作为代码包并安装。这和 go build 命令是完全一样的。
go install 命令后面如果跟了代码包导入路径作为参数,那么该代码包及其依赖都会被安装。
go install 命令后面如果跟了命令源码文件以及相关库源码文件作为参数的话,只有这些文件会被编译并安装。
当代码包中有且仅有一个命令源码文件的时候,在文件夹所在目录中执行 go build 命令,会在该目录下生成一个与目录同名的可执行文件。

执行 go install 之前,一般情况下,需要提前设置 GOBIN 环境变量:

在 GOBIN 下生成对应的可执行文件。

什么 是GOBIN ?
GOBIN 是一个环境变量,用于指定 go install 命令安装可执行文件的位置。
除了 GOBIN 之外, 可以使用 go env 看下其他的环境变量

当我们使用 go install 命令编译 Go 程序时,生成的可执行文件会被安装到 $GOBIN 目录下(如果没有设置 GOBIN,则默认为 $GOPATH/bin 目录下)。
在 Linux 或 macOS 中,可以通过以下命令设置 GOBIN:
$ export GOBIN=/path/to/go/bin
在 Windows 中,可以使用以下命令设置 GOBIN:
setx GOBIN "C:\path\to\go\bin"
eg:
setx GOBIN "C:\Users\nien\go\bin"
还有,如果要直接运行已安装的程序,需要注意的是: GOBIN 需要在系统的 PATH 环境变量中才能起作用。所以,可以将 $GOBIN 或者 $GOPATH/bin 添加到 PATH 环境变量中,以便在任何目录下都可以直接运行已安装的程序。
通常情况下,我们会将 $GOPATH/bin 添加到 PATH 中,这样安装的程序就可以直接在终端中使用了。
例如:
$ export PATH=$PATH:$GOPATH/bin
或者在 Windows 中:
> setx PATH "%PATH%;%GOPATH%\bin"
这样,在任何目录下都可以直接运行已安装的程序。
详解: go install 究竟干了些什么呢?
go install 命令究竟做了些什么呢?
go install 前面几步依旧和 go run 、go build 完全一致,只是最后一步的差别.
最后一步,go install 会把命令源码文件安装到当前工作区的 bin 目录(如果 GOPATH 下有多个工作区,就会放在 GOBIN 目录下)。如果是库源码文件,就会被安装到当前工作区的 pkg 的平台相关目录下。
总结一下如下图:

go install 命令参数
命令格式:go install [可选参数] 。
命令作用:编译并安装源文件、软件包,即把编译后的文件(可执行二进制文件、归档文件等)安装到指定的目录中。
特殊说明:将编译后的文件(可执行二进制文件、归档文件等)安装到指定的目录中。若设置了环境变量 GOBIN ,则把二进制可执行文件移到该目录。若禁用 Go modules 则放到 $GOPATH/pkg/$GOOS_$GOARCH下。
执行: go install -x main.go
输出:
...
mkdir -p /Users/ucwords/go/bin/
...
mv $WORK/b001/exe/a.out /Users/ucwords/go/bin/目标目录(go modules的目录名)
rm -r $WORK/b001/
常用参数:
| 参数名 | 格式 | 含义 |
|---|---|---|
| -o | -o file | 指定编译后二进制文件名 |
| -a | -a | 强制重新编译涉及的依赖 |
| -s | -s | 省略符号表并调试信息 |
| -w | -w | 省略 DWARF 符号表 |
| -p | -p | 指定编译过程中的并发数,默认为CPU数 |
| -work | -work | 设置该参数后不会在程序结束后删掉编译的临时文件,可用于参看编译生成的文件 |
| -n | -n | 加上该参数可以查看编译的过程,但不会继续执行编译后的二进制文件 |
| -x | -x | 加上该参数可以查看编译的过程,会继续执行编译后的二进制文件 |
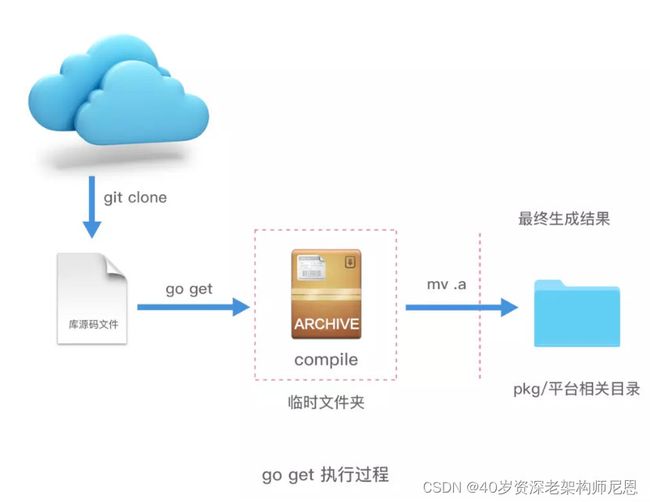
4、go get
go get 命令用于从远程代码仓库(比如 Github )上下载并安装代码包。
注意,go get 命令会把当前的代码包下载到 $GOPATH 中的第一个工作区的 src 目录中,并安装。
使用 go get 下载第三方包的时候,依旧会下载到 $GOPATH 的第一个工作空间,而非 vendor 目录。当前工作链中并没有真正意义上的包依赖管理,不过好在有不少第三方工具可选。
如果在 go get 下载过程中加入-d 标记,那么下载操作只会执行下载动作,而不执行安装动作。比如有些非常特殊的代码包在安装过程中需要有特殊的处理,所以我们需要先下载下来,所以就会用到-d 标记。
还有一个很有用的标记是-u标记,加上它可以利用网络来更新已有的代码包及其依赖包。如果已经下载过一个代码包,但是这个代码包又有更新了,那么这时候可以直接用-u标记来更新本地的对应的代码包。如果不加这个-u标记,执行 go get 一个已有的代码包,会发现命令什么都不执行。只有加了-u标记,命令会去执行 git pull 命令拉取最新的代码包的最新版本,下载并安装。
命令 go get 还有一个很值得称道的功能——智能下载。在使用它检出或更新代码包之后,它会寻找与本地已安装 Go 语言的版本号相对应的标签(tag)或分支(branch)。比如,本机安装 Go 语言的版本是1.x,那么 go get 命令会在该代码包的远程仓库中寻找名为 “go1” 的标签或者分支。如果找到指定的标签或者分支,则将本地代码包的版本切换到此标签或者分支。如果没有找到指定的标签或者分支,则将本地代码包的版本切换到主干的最新版本。
go get 常用的一些标记如下:
| 标记名称 | 标记描述 |
|---|---|
| -d | 让命令程序只执行下载动作,而不执行安装动作。 |
| -f | 仅在使用-u标记时才有效。该标记会让命令程序忽略掉对已下载代码包的导入路径的检查。如果下载并安装的代码包所属的项目是你从别人那里 Fork 过来的,那么这样做就尤为重要了。 |
| -fix | 让命令程序在下载代码包后先执行修正动作,而后再进行编译和安装。 |
| -insecure | 允许命令程序使用非安全的 scheme(如 HTTP )去下载指定的代码包。如果你用的代码仓库(如公司内部的 Gitlab )没有HTTPS 支持,可以添加此标记。请在确定安全的情况下使用它。 |
| -t | 让命令程序同时下载并安装指定的代码包中的测试源码文件中依赖的代码包。 |
| -u | 让命令利用网络来更新已有代码包及其依赖包。默认情况下,该命令只会从网络上下载本地不存在的代码包,而不会更新已有的代码包。 |
总结一下如下图:
5、其他命令
go clean
go clean 命令是用来移除当前源码包里面编译生成的文件,这些文件包括
- _obj/ 旧的object目录,由Makefiles遗留
- _test/ 旧的test目录,由Makefiles遗留
- _testmain.go 旧的gotest文件,由Makefiles遗留
- test.out 旧的test记录,由Makefiles遗留
- build.out 旧的test记录,由Makefiles遗留
- *.[568ao] object文件,由Makefiles遗留
- DIR(.exe) 由 go build 产生
- DIR.test(.exe) 由 go test -c 产生
- MAINFILE(.exe) 由 go build MAINFILE.go产生
go fmt
go fmt 命令主要是用来帮你格式化所写好的代码文件。
比如我们写了一个格式很糟糕的 test.go 文件,我们只需要使用 fmt go test.go 命令,就可以让go帮我们格式化我们的代码文件。
但是我们一般很少使用这个命令,因为我们的开发工具一般都带有保存时自动格式化功能,这个功能底层其实就是调用了 go fmt 命令而已。
使用go fmt命令,更多时候是用gofmt,而且需要参数-w,否则格式化结果不会写入文件。gofmt -w src,可以格式化整个项目。
go test 命令
go test 命令是 Go 语言自带的一个测试工具,用于执行程序中的单元测试和性能测试。
执行 go test 命令时,它会自动查找当前目录及其子目录下的所有以 _test.go 结尾的文件,并执行其中的测试函数。
go test 命令支持多种参数和选项,可以通过 go help test 查看完整的帮助文档。其中一些常用的参数和选项包括:
-v:输出详细的测试日志信息,包括测试用例的名称、运行时间、每个测试函数的输出结果等。
-run:指定需要运行的测试函数的名称或正则表达式。
-cover:生成代码覆盖率报告,报告中会显示哪些代码被测试覆盖到了,哪些没有被覆盖到。
-bench:执行性能测试,并输出测试结果。可以指定 -benchmem 选项来输出内存分配的情况。
例如,执行 go test -v ./… 命令将会递归地运行当前目录及其子目录下所有的测试函数,并输出详细的测试日志信息。
go doc 命令
作用:打印出程序实体说明文档。后可不跟参数或一个参数或两个参数
格式:go doc 标记 参数
标记和参数可以不填,
- go doc
在 main 包下,执行 go doc 默认是不打印的,除非加上 -cmd 标记,后面会讲
在非 main 包下,执行 go doc 打印当前代码包文档及其程序实体列表(程序实体:变量、常量、函数、结构体以及接口) - go doc 标记
标记有如下:
| 标记 | 含义 |
|---|---|
| -c | 区分后跟参数的大小写,比如:go doc -c packageOne(默认不写是不区分大小写 ) |
| -cmd | 加入此标记会使go doc命令同时打印出main包中的可导出的程序实体(其名称的首字母大写)的文档。默认下,这些文档是不会被打印的。 |
| -u | 加入此标记后会使go doc命令同时打印出不可导出的程序实体(其名称的首字母小写)的文档。默认下,这部分文档是不会被打印出来的。 |
- go doc 参数
go doc 参数, 比如:go doc http.Request 会输出 http 包下 Request 文档说明,也可以跟两个参数,见下
go doc 参数1 参数2,比如:go doc net/http Request ,需要说明的是第一个参数要写完整的导入路径,我个人理解就是在参数1 的范围下,打印出参数2的文档说明详情,其实此时 doc 和 参数之间还可以加入标记,相当于打印文档时又加入了条件判断。
go fix
用来修复以前老版本的代码到新版本,例如go1之前老版本的代码转化到go1
go version
查看go当前的版本
go env
查看当前go的环境变量
go list
列出当前全部安装的package
golang 代码规范
命名在所有的编程语言中都是有规则可寻的,也是需要遵守的,只有我们有了好的命名习惯才可以写出好的代码,例如我们在生活中对建筑的命名也是希望可以表达这个建筑的含义和作用。
在Go语言中也是一样的,Go语言的函数名,变量名,常量名,类型名和包的命名也是都遵循这一规则的:一个一个名字必须以一个字母(Unicode字母)或下划线开头,后面可以跟任意数量的字母、数字或下划线。
大写字母和小写字母是不同的:Car和car是两个不同的名字。
Go语言中也有类似java的关键字,且关键字不能用于自定义名字,只能在特定语法结构中使用.
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
除此之外Go语言中还有30多个预定义的名字,比如int和ture等
内建常量: true false iota nil
内建类型: int int8 int16 int32 int64 uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64 bool byte rune string error
内建函数: make len cap new append copy close delete complex real imag panic recover
通常我们在Go语言编程中推荐的命名方式是驼峰命名例如:ReadAll,不推荐下划线命名。
好的规范的价值
对于团队而言,好的规范虽一定程度降低开发自由度,但带来的好处是不可忽视的
- 可以减少 bug 的产生
- 降低 review 和接手成本,通过统一规范,每个人代码风格统一,理想情况看谁的代码就像自己写的一样
- 利于写一些片段脚本
- 提高代码可读性
下面总结了平时项目中必须遵守的规范,后续会不断更新,也可以来尼恩的 高并发社群《技术自由圈(原名:疯狂创客圈)》 中交流。
Import 规范
- 原则上遵循 goimports 规范,goimports 会自动把依赖按首字母排序,并对包进行分组管理,通过空行隔开,默认分为本地包(标准库、内部包)、第三方包。
- 标准包永远位于最上面的第一组
- 使用完整路径,不要使用相对路径
- 包名和 git 路径名不一致时,或者多个相同包名冲突时,使用别名代替
错误处理
- error 作为函数的值返回,必须对 error 进行处理,或将返回值赋值给明确忽略。
- error 作为函数的值返回且有多个返回值的时候,error 必须是最后一个参数。
// 不建议
func do() (error, int) {
}
// 建议
func do() (int, error) {
}
- 优先处理错误,能 return 尽早 return。理想情况代码逻辑是平铺的顺着读就能看懂,过多的嵌套会降低可读性
// 不建议
if err != nil {
// error handling
} else {
// normal code
}
// 建议
if err != nil {
// error handling
return // or continue, etc.
}
// normal code
- 错误返回优先独立判断,不与其他变量组合判断
// 不建议
x, y, err := f()
if err != nil || y == nil {
return err // 当y与err都为空时,函数的调用者会出现错误的调用逻辑
}
// 建议
x, y, err := f()
if err != nil {
return err
}
if y == nil {
return fmt.Errorf("some error")
}
panic
- 在业务逻辑处理中禁止使用 panic。
- 在 main 包中只有当完全不可运行的情况可使用 panic,例如:文件无法打开,数据库无法连接导致程序无法正常运行。
- 对于其它的包,可导出的接口不能有 panic,只能在包内使用。
- 建议在 main 包中使用 log.Fatal 来记录错误,这样就可以由 log 来结束程序,或者将 panic 抛出的异常记录到日志文件中,方便排查问题。
- panic 捕获只能到 goroutine 最顶层,每个自行启动的 goroutine,必须在入口处捕获 panic,并打印详细堆栈信息或进行其它处理。
recover
- recover 用于捕获 runtime 的异常,禁止滥用 recover。
- 必须在 defer 中使用,一般用来捕获程序运行期间发生异常抛出的 panic 或程序主动抛出的 panic。
单元测试
- 单元测试文件名命名规范为 example_test.go。
- 测试用例的函数名称必须以 Test 开头,例如 TestExample。
- 如果存在 func Foo,单测函数可以带下划线,为 func Test_Foo。如果存在 func (b *Bar) Foo,单测函数可以为 func TestBar_Foo。下划线不能出现在前面描述情况以外的位置。
- 每个重要的可导出函数都要首先编写测试用例,测试用例和正规代码一起提交方便进行回归测试。
类型断言失败处理
type assertion 的单个返回值形式针对不正确的类型将产生 panic。
因此,请始终使用 “comma ok” 的惯用法。
// 不建议
t := i.(string)
// 建议
t, ok := i.(string)
if !ok {
// 优雅地处理错误
}
注释
- 在编码阶段同步写好变量、函数、包注释,注释可以通过 godoc 导出生成文档。
- 程序中每一个被导出的(大写的)名字,都应该有一个文档注释。
- 所有注释掉的代码在提交 code review 前都应该被删除,除非添加注释讲解为什么不删除, 并且标明后续处理建议(比如删除计划)。
命名规范
- 文件名应该采用小写,并且使用下划线分割各个单词,文件名尽量采用有意义简短的文件
- 结构体,接口,变量,常量,函数均采用驼峰命名
命名规范设计变量、常量、全局函数、结构、方法等等的命名。
Go语言从语法层面进行了以下限定:任何需要对外暴露的名字必须以大写字母开头,不需要对外暴露的则以小写字母开头。
当一个命名以一个大写字母开头,如GetUserName,那么使用这种形式的标识符的对象就可以被外部包的代码使用(客户端程序需要先导入这个包),这被称为导出(如面向对象语言中的public);命名如果以小写字母开头,则对包外是不可兼得,但是他们在整个包的内部是可见的并且可用的(如面向对象语言中的private)
包命名
保持package的名字和目录保持一致,尽量采用有意义的包名,简短、有意义且尽量和标准库不要冲突。
包命应该为小写单词,不要使用下划线或者混合大小写。
package psych
package service
文件命名
尽量采用有意义且简短的文件名,应为小写单词,使用下划线分隔各个单词
customer_dao.go
结构体命名
采用驼峰命名法,首字母根据访问控制大小写
struct 声明和初始化格式采用多行,例:
type CustomerOrder struct{
Name string
Address string
}
order := CustomerOder{"psych","四川成都"}
接口命名
命名规则基本上与上面结构体类似
单个函数的结构名以“er”作为后缀,例如Reader,Writer
type Reader interface{
Read(p []byte)(n int,err error)
}
首字母访问控制规则
在 Golang 中,如果一个标识符(如变量、函数名等)的首字母大写,表示它是可导出的(exported),即可以被外部包访问和使用;如果首字母小写,则表示它是不可导出的(unexported),只能在当前包内部使用。
这是因为 Golang 的访问控制是基于标识符的命名规则来实现的,首字母大小写的不同决定了该标识符的可见性。具体来说,对于一个标识符,如果它的首字母大写,那么它就是公开(public)的,可以被其他包导入后直接使用;如果首字母小写,那么它就是私有(private)的,只能在当前包内部使用,对于其他包来说是不可见的。
举个例子,假设我们有一个包叫做"example",其中定义了一个变量"Name":
package example
var Name string = "hello"
由于变量"Name"的首字母大写,所以它是可导出的,可以被其他包导入后直接使用:
package main
import (
"fmt"
"example"
)
func main() {
fmt.Println(example.Name) // 输出:hello
}
但如果把"Name"的首字母改为小写,那么它就是不可导出的,外部包无法访问和使用它:
package example
var name string = "hello"
package main
import (
"fmt"
"example"
)
func main() {
fmt.Println(example.name) // 编译错误:name undefined (cannot refer to unexported name example.name)
}
因此,在 Golang 中,通过标识符的命名规则来实现访问控制,可以有效地保障代码的封装性和安全性。
方法命名
Golang 中的方法命名遵循一般的命名规则,遵守首字母大小访问控制规则,同时,也建议采用驼峰式命名法(camel case)。
在 Golang 中,方法通常是与某个类型(结构体、接口等)关联的函数。方法名应该简洁明了,描述清楚该方法的作用和功能,通常使用动词加上一定的描述或说明来命名。
以下是一些常见的方法命名规范:
- GetXxx:表示获取某个属性或值,例如 GetName 表示获取名称。
- SetXxx:表示设置某个属性或值,例如 SetAge 表示设置年龄。
- AddXxx:表示添加某个元素或对象,例如 AddItem 表示添加一个元素。
- RemoveXxx:表示移除某个元素或对象,例如 RemoveItem 表示移除一个元素。
- DoXxx:表示执行某个操作,例如 DoSomething 表示执行某个操作。
- XxxWithYyy:表示使用 Yyy 作为参数执行 Xxx 操作,例如 WriteWithTimeout 表示使用超时参数执行写操作。
需要注意的是,方法名应该尽量避免使用缩写或缩略语,除非是广泛使用的常见缩写,否则容易引起歧义和误解。同时,方法名也应该尽量避免冗长,以保持代码的简洁性和可读性。
举个例子,假设我们有一个结构体叫做"Person",它有一个方法"SayHello":
type Person struct {
Name string
Age int
}
func (p *Person) SayHello() {
fmt.Printf("Hello, my name is %s and I am %d years old.\n", p.Name, p.Age)
}
在上面的例子中,我们使用了驼峰式命名法来命名方法"SayHello",同时结合动词和名词来描述该方法的作用。这样做可以使代码更易读、易懂。
变量命名
和结构体类似,一般遵循驼峰命名法,首字母根据访问控制大小写,但遇到特有名词时,需要遵循以下规则:
如果变量为私有,且特有名词为首个单词,则使用小写,如 appService;
若变量为bool类型,则名称应以has、is、can或allow开头
var isExist bool
var hasConflict bool
var canManage bool
var allowGitHook bool
常量命名
常量需使用全部大写字母组成,并使用下划线分词
const APP_URL = "https://www.baidu.com"
如果是枚举类型的常量,需要先创建对应类型
type Scheme string
const{
HTTP Scheme = "http"
HTTPS Scheme = "https"
}
单元测试命名
在 Golang 中,单元测试采用的是内置的 testing 包,我们需要遵循一定的命名规范来编写测试函数的名称。Golang 的测试函数命名规则是:
- 测试函数必须以 Test 开头,例如 TestAdd。
- 测试函数参数列表中必须有一个类型为 *testing.T 的参数,例如 func TestAdd(t *testing.T)。
- 测试函数的参数列表中不应该包含任何其他参数。
- 测试函数的名称应该具有描述性,可以使用驼峰式命名法,例如 TestAddTwoNumbers。
另外,对于某个包下的所有测试函数,我们可以将它们组织成一个表格测试(Table-Driven Tests)的形式,这样可以使测试代码更加简洁、清晰和易于维护。表格测试的命名规则如下:
- 表格测试函数必须以 Test 开头,例如 TestAddTable。
- 表格测试函数参数列表中必须有一个类型为 *testing.T 的参数,例如 func TestAddTable(t *testing.T)。
- 表格测试函数的参数列表中不应该包含任何其他参数。
- 表格测试函数应该包含一个结构体切片或映射作为输入参数,同时也需要定义一个期望输出结果的切片或映射,例如:
func TestAddTable(t *testing.T) {
tests := []struct {
a, b int
want int
}{
{1, 2, 3},
{0, 0, 0},
{-1, -1, -2},
}
for _, tt := range tests {
got := Add(tt.a, tt.b)
if got != tt.want {
t.Errorf("Add(%d, %d) = %d; want %d", tt.a, tt.b, got, tt.want)
}
}
}
在这个例子中,我们使用了表格测试的形式来测试 Add 函数的功能和正确性。其中,tests 切片包含了多组输入参数和期望输出结果,每次循环都会进行一次测试,并将实际输出结果与期望输出结果进行比较,如果不一致则使用 t.Errorf 输出错误信息和相关参数。
需要注意的是,单元测试应该覆盖代码中的所有核心功能和可能出现的异常情况,以保证代码的质量和可靠性。同时,测试代码也需要遵循相应的编程规范和最佳实践,提高测试代码的可读性和可维护性。
控制结构
- if 语句
// 不建议,变量优先在左
if nil != err {
}
// 建议这种
if err != nil {
}
// 不建议,bool类型变量直接进行
if has == true {
}
// 建议
if has {
}
- switch 语句,必须有 default 哪怕什么都不做
- 业务代码禁止使用 goto,其他框架或底层源码推荐尽量不用。
函数
函数返回相同类型的两个或三个参数,或者如果从上下文中不清楚结果的含义,使用命名返回,其它情况不建议使用命名返回。
func (n *Node) Parent1() *Node
func (n *Node) Parent2() (*Node, error)
func (f *Foo) Location() (lat, long float64, err error)
Defer
- 当存在资源管理时,应紧跟 defer 函数进行资源的释放。
- 判断是否有错误发生之后,再 defer 释放资源。
resp, err := http.Get(url)
if err != nil {
return err
}
// defer 放到错误处理之后,不然可能导致panic
defer resp.Body.Close()
- 禁止在循环中的延迟函数中使用 defer,因为 defer 的执行需要外层函数的结束才会释放,未来会有很多坑
// 不要这样使用
func filterSomething(values []string) {
for _, v := range values {
fields, err := db.Query(xxx)
if err != nil {
}
defer fields.Close()
// xxx
}
}
// 但是可以使用这种方式
func filterSomething(values []string) {
for _, v := range values {
func() {
fields, err := db.Query(xxx)
if err != nil {
// xxx
}
defer fields.Close()
//x xxx
}()
}
}
魔法数字
如果魔法数字出现超过 2 次,则禁止使用。
func getArea(r float64) float64 {
return 3.14 * r * r
}
func getLength(r float64) float64 {
return 3.14 * 2 * r
}
// 建议定义一个常量代替魔法数字
// PI xxx
const PI = 3.14
代码规范性常用工具
上面提到了很过规范, go 语言本身在代码规范性这方面也做了很多努力,很多限制都是强制语法要求,例如左大括号不换行,引用的包或者定义的变量不使用会报错,此外 go 还是提供了很多好用的工具帮助我们进行代码的规范,
gofmt
大部分的格式问题可以通过gofmt解决, gofmt 自动格式化代码,保证所有的 go 代码与官方推荐的格式保持一致,于是所有格式有关问题,都以 gofmt 的结果为准。
goimport
我们强烈建议使用 goimport ,该工具在 gofmt 的基础上增加了自动删除和引入包.
go get golang.org/x/tools/cmd/goimports
go vet
vet工具可以帮我们静态分析我们的源码存在的各种问题,例如多余的代码,提前return的逻辑,struct的tag是否符合标准等。
go get golang.org/x/tools/cmd/vet
使用如下:
go vet .
包和文件
每个 Go 程序都是由包构成的。程序从 main 包开始运行。
本程序通过导入路径 "fmt" 和 "math/rand" 来使用这两个包。
import (
"fmt"
"math/rand"
)
func main() {
fmt.Println("Hello, World!")
var input string
fmt.Scanln(&input)
fmt.Println("你的输入是:%s", input)
fmt.Println("My favorite number is", rand.Intn(10))
}
按照约定,包名与导入路径的最后一个元素一致。
例如,"math/rand" 包中的源码均以 package rand 语句开始。
注意: 此程序的运行环境是固定的,因此 rand.Intn 总是会返回相同的数字。
要得到不同的数字,需为生成器提供不同的种子数,参见 rand.Seed。
包的价值: 进行模块的隔离
Go语言中的包和其他语言的库或模块的概念类似,目的都是为了支持模块化、封装、单独编译和代码重 用。
一个包的源代码保存在一个或多个以.go为文件后缀名的源文件中. 在Go语言中包还可以让我们通过控制哪些名字是外部可见的来隐藏内部实现信息。
在Go语言中,一个简单的规则 是:如果一个名字是大写字母开头的,那么该名字是导出的。类似于Java 中的public
如果包中含有多个.go源文件,它们将按照发给编译器的顺序进行初始化,Go语言的构建工具首先会 将.go文件根据文件名排序,然后依次调用编译器编译。
对于在包级别声明的变量,如果有初始化表达式则用表达式初始化,还有一些没有初始化表达式的,例 如某些表格数据初始化并不是一个简单的赋值过程。
包的init 初始化函数
在这种情况下,我们可以用一个特殊的init初始化 函数来简化初始化工作。每个文件都可以包含多个init初始化函数
func init() { }
这样的init初始化函数除了不能被调用或引用外,其他行为和普通函数类似。
在每个文件中的init初始 化函数,在程序开始执行时按照它们声明的顺序被自动调用。
每个包在解决依赖的前提下,以导入声明的顺序初始化,每个包只会被初始化一次。
因此,如果一个p包 导入了m包,那么在p包初始化的时候可以认为m包必然已经初始化过了。
初始化工作是自下而上进行的, main包最后被初始化。
以这种方式,可以确保在main函数执行之前,所有依然的包都已经完成初始化工 作了。
包的导入
import导入包的用法:
import "github.com/tidwall/gjson" //通过包名gjson调用导出接口
import json "github.com/tidwall/gjson" //通过别名json调用gjson
import . "github.com/tidwall/gjson" //.符号表示,对包gjson的导出接口的调用直接省略包名
import _ "github.com/tidwall/gjson" //_ 仅仅会初始化gjson,如初始化全局变量,调用init函数
当然你也可以编写多个导入语句,例如:
import "fmt"
import "math"
此代码用圆括号组合了导入,这是“分组”形式的导入语句。不过使用分组导入语句是更好的形式。
imports.go
import (
"fmt"
"math/rand"
)
func main() {
fmt.Println("Hello, World!")
var input string
fmt.Scanln(&input)
fmt.Println("你的输入是:%s", input)
fmt.Println("My favorite number is", rand.Intn(10))
}
作用域
一个声明语句将程序中的实体和一个名字关联,比如一个函数或一个变量。
声明语句的作用域是指源代 码中可以有效使用这个名字的范围。
不要将作用域和生命周期混为一谈。
声明语句的作用域对应的是一个源代码的文本区域;它是一个编译 时的属性。
一个变量的生命周期是指程序运行时变量存在的有效时间段,在此时间区域内它可以被程序 的其他部分引用;是一个运行时的概念。
语法块是由花括弧所包含的一系列语句,就像函数体或循环体花括弧对应的语法块那样。语法块内部声 明的名字是无法被外部语法块访问的。
语法决定了内部声明的名字的作用域范围。我们可以这样理解, 语法块可以包含其他类似组批量声明等没有用花括弧包含的代码,我们称之为语法块。
有一个语法块为 整个源代码,称为全局语法块;然后是每个包的包语法决;每个for、if和switch语句的语法决;每个 switch或select的分支也有独立的语法决;当然也包括显式书写的语法块(花括弧包含的语句)。
声明语句对应的词法域决定了作用域范围的大小。对于内置的类型、函数和常量,比如int、len和true 等是在全局作用域的,因此可以在整个程序中直接使用。
任何在在函数外部(也就是包级语法域)声明 的名字可以在同一个包的任何源文件中访问的。
对于导入的包,例如tempconv导入的fmt包,则是对应源 文件级的作用域,因此只能在当前的文件中访问导入的fmt包,当前包的其它源文件无法访问在当前源文 件导入的包
在包级别,声明的顺序并不会影响作用域范围,因此一个先声明的可以引用它自身或者是引用后面的一 个声明,这可以让我们定义一些相互嵌套或递归的类型或函数。
但是如果一个变量或常量递归引用了自 身,则会产生编译错误。
if f, err := os.Open(fname); err != nil { // compile error: unused: f
return err
}
f.ReadByte() // compile error: undefined f
f.Close() // compile error: undefined f
变量f的作用域只有在if语句内,因此后面的语句将无法引入它,这将导致编译错误。
你可能会收到一个 局部变量f没有声明的错误提示,具体错误信息依赖编译器的实现。
文件命名
- golang的命名需要使用驼峰命名法,且不能出现下划线
- golang中根据首字母的大小写来确定可以访问的权限。
无论是方法名、常量、变量名还是结构体的名称,如果首字母大写,则可以被其他的包访问;
如果首字母小写,则只能在本包中使用,可以简单的理解成,首字母大写是公有的,首字母小写是私有的 - 结构体中属性名的大写
如果属性名小写则在数据解析(如json解析,或将结构体作为请求或访问参数)时无法解析
在golang源代码中,经常看到各种文件名,比如: bolt_windows.go。
下面对文件名命令规则的说明:
- 平台区分
文件名_平台。
例: file_windows.go, file_unix.go
可选为windows, unix, posix, plan9, darwin, bsd, linux, freebsd, nacl, netbsd, openbsd, solaris, dragonfly, bsd, notbsd, android,stubs - 测试单远
文件名test.go或者 文件名平台_test.go。
例: path_test.go, path_windows_test.go - 版本区分(猜测)
文件名_版本号等。
例:trap_windows_1.4.go - CPU类型区分, 汇编用的多
文件名_(平台:可选)_CPU类型.
例:vdso_linux_amd64.go
可选为amd64, none, 386, arm, arm64, mips64, s390,mips64x,ppc64x, nonppc64x, s390x, x86,amd64p32
函数
函数可以没有参数或接受多个参数。
在本例中,add 接受两个 int 类型的参数。
注意, go和java不同,函数的返回类型,在函数名 之后。
Functions.go
package basic
import "fmt"
func Add(a, b int) int {
var ret = a + b
fmt.Printf("The sum of %d and %d is: %d\n", a, b, ret)
return ret
}
func Callback(y int, f func(int, int) int) {
f(y, 5) // this becomes Add(1, 5)
}
func DoCallback(y int) {
Callback(y, Add) // this becomes Add(1, 5)
}
当连续两个或多个函数的已命名形参类型相同时,除最后一个类型以外,其它都可以省略。
在本例中,
func Add(a int, b int) int {
....
}
其中的两个参数
a int, b int
被缩写为
a, b int
函数定义:
函数构成代码执行的逻辑结构。
在Go语言中,函数的基本组成为:关键字 func 、函数名、参数列表、返回值、函数体和返回语句。
除了main()、init()函数外,其它所有类型的函数都可以有参数与返回值。
函数参数、返回值以及它们的类型被统称为函数签名。
func function_name( [parameter list] ) [return_types] {
body(函数体)
}
函数定义:
- func:函数由 func 开始声明
- function_name:函数名称,函数名和参数列表一起构成了函数签名。
- parameter list:参数列表,参数就像一个占位符,当函数被调用时,你可以将值传递给参数,这个值被称为实际参数。参数列表指定的是参数类型、顺序、及参数个数。参数是可选的,也就是说函数也可以不包含参数。
- return_types:返回类型,函数返回一列值。return_types 是该列值的数据类型。有些功能不需要返回值,这种情况下 return_types 不是必须的。
- body(函数体):函数定义的代码集合。
形式参数列表描述了函数的参数名以及参数类型。
这些参数作为局部变量,其值由参数调用者提供。返回值列表描述了函数返回值的变量名以及类型。
如果函数返回一个无名变量或者没有返回值,返回值列表的括号是可以省略的。
如果一个函数声明不包括返回值列表,那么函数体执行完毕后,不会返回任何值。
// 这个函数计算两个int型输入数据的和,并返回int型的和
func Add(a int, b int) int {
// Go需要使用return语句显式地返回值
return a + b
}
fmt.Println(Add(3,4)) //函数的调用
在Add函数中a和b是形参名3和4是调用时的传入的实数,函数返回了一个int类型的值。
返回值也可以像形式参数一样被命名。
在这种情况下,每个返回值被声明成一个局部变量,并根据该返回值的类型,将其初始化为0。
如果一个函数在声明时,包含返回值列表,该函数必须以 return语句结尾,除非函数明显无法运行到结尾处。
例如函数在结尾时调用了panic异常或函数中存在无限循环。
函数如何调用
那么函数在使用的时候如何被调用呢?
package.Function(arg1, arg2, …, argn)
Function 是 package包里面的一个函数,括号里的是被调用函数的实参(argument):这些值被传递给被调用函数的形参(parameter)。
函数被调用的时候,这些实参将被复制然后传递给被调用函数。
函数一般是在其他函数里面被调用的,这个其他函数被称为调用函数(calling function)。
函数能多次调用其他函数,这些被调用函数按顺序行,理论上,函数调用其他函数的次数是无穷的(直到函数调用栈被耗尽)。
函数的变长参数
在函数中有的时候可能也会遇到你要传递的参数的类型是多个(传递变长参数)如这样的函数:
func patent(a,b,c ...int)
参数是采用 …type 的形式传递,这样的函数称为变参函数.
只有声明没有body的函数
你可能会偶尔遇到没有函数体的函数声明,这表示该函数不是以Go实现的。
这样的声明定义了函数标识符。
package math
func Sin(x float64) float //implemented in assembly language
返回多值的函数
函数可以返回任意数量的返回值。
swap 函数返回了两个字符串。
//函数定义
func Swap(x, y string) (string, string) {
return y, x
}
//函数调用
func main() {
basic.BasicTypeDemo()
basic.BasicTypeDemo()
basic.DoCallback(1)
basic.Callback(1, basic.Add)
a, b := basic.Swap("hello", "world")
fmt.Println(a, b)
}
命名返回值
Go 的返回值可被命名,它们会被视作定义在函数顶部的变量。
返回值的名称应当具有一定的意义,它可以作为文档使用。
没有参数的 return 语句,返回已命名的返回值。也就是 直接 返回。
func Split(sum int) (x, y int) {
x = sum * 4 / 9
y = sum - x
return
}
函数的使用
x, y := basic.Split(40)
fmt.Println(x, y)
直接返回语句应当仅用在上面这样的短函数中。在长的函数中它们会影响代码的可读性。
匿名返回值
函数签名中命名返回值变量,只指定返回值类型。由return 指定返回值。
// 匿名返回值
func Split02(sum int) (int, int) {
var x = sum * 4 / 9
var y = sum - x
return x, y
}
任何一个非命名返回值(使用非命名返回值是很糟的编程习惯)在 return 语句里面都要明确指出包含返回值的变量或是一个可计算的值(就像上面警告所指出的那样)
建议:尽量使用命名返回值:会使代码更清晰、更简短,同时更加容易读懂。
将函数作为参数传递
在 Go 语言中,函数是一等公民,也就是说,函数可以像值一样传递和使用。
因此,可以将函数作为参数传递给其他函数,实现更加灵活的编程方式。
func Add(a, b int) int {
var ret = a + b
fmt.Printf("The sum of %d and %d is: %d\n", a, b, ret)
return ret
}
func Callback(y int, f func(int, int) int) {
f(y, 5) // this becomes Add(1, 5)
}
func DoCallback(y int) {
Callback(y, Add) // this becomes Add(1, 5)
}
调用方法
basic.DoCallback(1)
basic.Callback(1, basic.Add)
输出结果为:
The sum of 1 and 5 is: 6
The sum of 1 and 5 is: 6
内置函数
Go语言拥有一些不需要进行导入操作就可以使用的内置函数。
它们有时可以针对不同的类型进行操作,例如:len、cap 和 append,或必须用于系统级的操作,例如:panic。因而,它们需要直接获得编译器的支持。
| 名称 | 说明 |
|---|---|
| close | 用于关闭管道通信channel |
| len、cap | len 用于返回某个类型的长度或数量(字符串、数组、切片、map 和管道);cap 是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map) |
| new、make | new 和 make 均是用于分配内存:new 用于值类型和用户定义的类型,如自定义结构,内建函数new分配了零值填充的元素类型的内存空间,并且返回其地址,一个指针类型的值。make 用于内置引用类型(切片、map 和管道)创建一个指定元素类型、长度和容量的slice。容量部分可以省略,在这种情况下,容量将等于长度。。它们的用法就像是函数,但是将类型作为参数:new(type)、make(type)。new(T) 分配类型 T 的零值并返回其地址,也就是指向类型 T 的指针)。它也可以被用于基本类型:v := new(int)。make(T) 返回类型 T 的初始化之后的值,因此它比 new 进行更多的工作,new() 是一个函数,不要忘记它的括号 |
| copy、append | copy函数用于复制,copy返回拷贝的长度,会自动取最短的长度进行拷贝(min(len(src), len(dst))),append函数用于向slice追加元素 |
| panic、recover | 两者均用于错误处理机制,使用panic抛出异常,抛出异常后将立即停止当前函数的执行并运行所有被defer的函数,然后将panic抛向上一层,直至程序carsh。recover的作用是捕获并返回panic提交的错误对象、调用panic抛出一个值、该值可以通过调用recover函数进行捕获。主要的区别是,即使当前goroutine处于panic状态,或当前goroutine中存在活动紧急情况,恢复调用仍可能无法检索这些活动紧急情况抛出的值。 |
| print、println | 底层打印函数 |
| complex、real imag | 用于创建和操作复数,imag返回complex的实部,real返回complex的虚部 |
| delete | 从map中删除key对应的value |
内置接口:
type error interface {
//只要实现了Error()函数,返回值为String的都实现了err接口
Error() String
}
递归函数
当一个函数在其函数体内调用自身,则称之为递归。
递归是一种强有力的技术特别是在处理数据结构的过程中.
// 递归函数定义
func Processing(n int) (res int) {
if n <= 1 {
res = 1
} else {
res = Processing(n-1) + Processing(n-2)
}
return
}
//调用
result := 0
for i := 0; i <= 10; i++ {
result = basic.Processing(i)
fmt.Printf("processing(%d) is: %d\n", i, result)
}
输出结果:
processing(0) is: 1
processing(1) is: 1
processing(2) is: 2
processing(3) is: 3
processing(4) is: 5
processing(5) is: 8
processing(6) is: 13
processing(7) is: 21
processing(8) is: 34
processing(9) is: 55
processing(10) is: 89
在使用递归函数时经常会遇到的一个重要问题就是栈溢出:一般出现在大量的递归调用导致的程序栈内存分配耗尽。
这个问题可以通过一个名为懒惰求值的技术解决,在 Go 语言中,我们可以使用管道(channel)和 goroutine也会通过这个方案来优化斐波那契数列的生成问题。
这样许多问题都可以使用优雅的递归来解决,比如说著名的快速排序算法。
匿名函数
在 Go 中,匿名函数是一种没有名字的函数,通常用于简单的逻辑处理或者作为其他函数的参数。它们可以像普通函数一样使用,并且不需要提前声明或定义。
当我们不希望给函数起名字的时候,可以使用匿名函数。
匿名函数由一个不带函数名的函数声明和函数体组成. 通常是一次性函数,不希望再次使用
匿名函数结构:
func() {
//func body
}() //花括号后加()表示函数调用,此处声明时为指定参数列表
例子
//如:
fun(a,b int) {
fmt.Println(a+b)
}(1,2)
表示参数列表的第一对括号必须紧挨着关键字 func,因为匿名函数没有名称。
花括号 {} 涵盖着函数体,最后的一对括号表示对该匿名函数的调用。
除了可以直接对匿名函数进行调用:func(x, y int) int { return x + y } (3, 4),之外,可以被赋值于某个变量,即保存函数的地址到变量中:fn := func(x, y int) int { return x + y },然后通过变量名对函数进行调用:fn(1,2)。
总之:
在使用匿名函数时,我们可以将其直接作为函数参数传递给其他函数,或者将其赋值给变量,从而实现更加灵活的编程方式。同时,匿名函数也常用于实现简单的闭包,从而在程序中保留某些状态或者上下文信息。
闭包函数
在谈到匿名函数我们在补充下闭包函数,闭包是函数式语言中的概念,没有研究过函数式语言的用户可能很难理解闭包的强大。
Go语言是支持闭包的,这里只是简单地讲一下在Go语言中闭包是如何实现的。
匿名函数是无需定义标示符(函数名)的函数;而闭包是指能够访问自由变量的函数。
换句话说,定义在闭包中的函数可以”记忆”它被创建时候的环境。闭包函数=匿名函数+环境变量。
总的来说: 在 Go 中,闭包函数是一种特殊的匿名函数,可以访问其外部作用域中的变量,并在函数内部持久化存储它们。这使得闭包函数非常有用,可以实现很多高级编程技巧。
以下是一个使用闭包函数的示例:
func Counter() func() int {
i := 0
return func() int {
i++
return i
}
}
闭包使用
c1 := basic.Counter()
fmt.Println(c1())
fmt.Println(c1())
c2 := basic.Counter()
fmt.Println(c2())
fmt.Println(c2())
运行的结果:
1
2
1
2
在该示例中,我们定义了一个名为 counter 的函数,它返回一个闭包函数。闭包函数内部定义了一个整数类型的变量 i,并返回一个无参数的匿名函数。这个匿名函数在每次被调用时会将 i 的值加1,并返回这个新值。由于闭包函数可以访问其外部作用域中的变量,因此它可以持久化存储变量 i 的状态。
在 main 函数中,我们首先通过 counter 函数创建了一个闭包函数 c1。我们连续调用 c1() 两次,并打印其结果到控制台上。这将输出 “1” 和 “2”,表示闭包函数成功地持久化存储了变量 i 的状态。
接下来,我们再次调用 counter 函数创建了一个新的闭包函数 c2。我们同样连续调用 c2() 两次,并打印其结果到控制台上。这将输出 “1” 和 “2”,但是与 c1 的结果完全独立,因为每个闭包函数都有自己的变量状态。
通过使用闭包函数,我们可以轻松地实现很多高级编程技巧,例如延迟计算、惰性求值、缓存等。需要注意的是,在使用闭包函数时,我们需要特别注意变量的生命周期和作用域,以避免出现内存泄漏和其他错误。
defer延迟函数
Go语言的defer算是一个语言的新特性,至少对比当今主流编程语言如此.
A "defer" statement invokes a function whose execution is deferred to the moment the surrounding function returns, either because the surrounding function executed a return statement, reached the end of its function body, or because the corresponding goroutine is panicking. defer语句调用一个函数,这个函数执行会推迟,直到外围的函数返回,或者外围函数运行到最后,或者相应的goroutine panic
defer语句经常被用于处理成对的操作,如打开、关闭、连接、断开连接、加锁、释放锁。
通过defer机制,不论函数逻辑多复杂,都能保证在任何执行路径下,资源被释放。
释放资源的defer应该直接跟在请求资源的语句后。
f,err := os.Open(filename)
if err != nil {
panic(err)
}
defer f.Close()
如果有多个defer表达式,调用顺序类似于栈,越后面的defer表达式越先被调用。
在处理其他资源时,也可以采用defer机制,比如对文件的操作:
package ioutil
func ReadFile(filename string) ([]byte, error) {
f, err := os.Open(filename)
if err != nil {
return nil, err
}
defer f.Close()
return ReadAll(f)
}
也可以处理互斥锁:
var mu sync.Mutex
var m = make(map[string]int)
func lookup(key string) int {
mu.Lock()
defer mu.Unlock()
return m[key]
}
调试复杂程序时,defer机制也常被用于记录何时进入和退出函数。
此外在使用defer函数的时候也会遇到些意外的情况,那就是defer使用时需要注意的坑: 先来看看几个例子。例1:
func f() (result int) {
defer func() {
result++
}()
return 0
}
例2:
func f() (r int) {
t := 5
defer func() {
t = t + 5
}()
return t
}
例3:
func f() (r int) {
defer func(r int) {
r = r + 5
}(r)
return 1
}
自己可以先跑下看看这三个例子是不是和自己想的不一样的呢!结果确实是的例1的正确答案不是0,例2的正确答案不是10,如果例3的正确答案不是6……
defer是在return之前执行的。这个在 官方文档中是明确说明了的。
要使用defer时不踩坑,最重要的一点就是要明白,return A这一条语句并不是一条原子指令!
返回值 = A
调用defer函数
空的return
接着我们看下例1,它可以改写成这样:
func f() (result int) {
result = 0 //return语句不是一条原子调用,return xxx其实是赋值+ret指令
func() { //defer被插入到return之前执行,也就是赋返回值和ret指令之间
result++
}()
return
}
所以例子1的这个返回值是1。
再看例2,它可以改写成这样:
func f() (r int) {
t := 5
r = t //赋值指令
func() { //defer被插入到赋值与返回之间执行,这个例子中返回值r没被修改过
t = t + 5
}
return //空的return指令
}
所以这个的结果是5。
最后看例3,它改写后变成:
func f() (r int) {
r = 1 //给返回值赋值
func(r int) { //这里改的r是传值传进去的r,不会改变要返回的那个r值
r = r + 5
}(r)
return //空的return
}
所以这个例子3的结果是1
defer确实是在return之前调用的。但表现形式上却可能不像。本质原因是return A语句并不是一条原子指令,defer被插入到了赋值 与ret之间,因此可能有机会改变最终的返回值。
变量
var 语句用于声明一个变量列表。var` 语句可以出现在包或函数级别。
变量的声明的语法一般是:
var 变量名字 类型 = 表达式
通常情况下“类型”或“= 表达式”两个部分可以省略其中的一个。
例子:
// 声明并初始化一个整数类型变量 x
var x int = 10
跟函数的参数列表一样,类型在最后
在 Go 中,变量是程序中存储数据的基本单元。每个变量都有一个类型和一个值,并且可以被赋值、传递和修改。
以下是一些基本的变量定义和使用方式:
package main
import "fmt"
func main() {
// 声明并初始化一个整数类型变量 x
var x int = 10
// 声明并初始化一个字符串类型变量 s
var s string = "hello"
// 声明一个布尔类型变量 b,不需要显式初始化,默认为 false
var b bool
// 打印变量的值
fmt.Println(x)
fmt.Println(s)
fmt.Println(b)
// 修改变量的值
x = 20
s = "world"
b = true
// 再次打印变量的值
fmt.Println(x)
fmt.Println(s)
fmt.Println(b)
// 短变量声明语法
y := 30
z, w := "foo", true
// 打印新的变量
fmt.Println(y)
fmt.Println(z)
fmt.Println(w)
// 类型推导
m := 40
n := "bar"
// 打印新的变量
fmt.Println(m)
fmt.Println(n)
}
在该示例中,我们首先使用 var 关键字声明和初始化了三个变量:x、s 和 b。
其中,x 是一个整数类型变量,初始化为 10;s 是一个字符串类型变量,初始化为 “hello”;b 是一个布尔类型变量,没有显式初始化,因此默认值为 false。
我们通过 fmt.Println 函数打印了这三个变量的值,并修改了它们的值。
示例接下来,演示了 Go 中的短变量声明语法和类型推导方式。
使用短变量声明语法可以更简洁地定义和初始化变量,而类型推导则可以让编译器自动推断变量类型,避免冗长的类型声明。
需要注意的是,在使用变量时,我们需要特别注意变量的作用域和生命周期,并尽可能地遵循最佳实践,以确保代码的正确性和可读性。
变量的初始化
变量声明可以包含初始值,每个变量对应一个。
如果初始化值已存在,则可以省略类型;变量会从初始值中获得类型。
var i, j int = 1, 2
func Func() {
var c, python, java = true, false, "no!"
fmt.Println(i, j, c, python, java)
}
短变量声明
在函数中,简洁赋值语句 := 可在类型明确的地方代替 var 声明。
函数外的每个语句都必须以关键字开始(var, func 等等),因此 := 结构不能在函数外使用。
import "fmt"
func Func() {
var i, j int = 1, 2
k := 3
c, python, java := true, false, "no!"
fmt.Println(i, j, k, c, python, java)
}
零值
没有明确初始值的变量声明会被赋予它们的 零值。
零值是:
- 数值类型为
0, - 布尔类型为
false, - 字符串为
""(空字符串)。
func Func() {
var i int
var f float64
var b bool
var s string
fmt.Printf("%v %v %v %q\n", i, f, b, s)
}
常量
在 Go 中,常量是一种固定不变的值,其值在编译时就已经确定,不能被修改。常量通常用于存储程序中不可变的值,例如数学常数、密码等。
以下是一些基本的常量定义和使用方式:
package main
import "fmt"
func main() {
// 声明一个整数类型常量
const x int = 10
// 声明一个字符串类型常量
const s string = "hello"
// 打印常量的值
fmt.Println(x)
fmt.Println(s)
// 尝试修改常量的值,会导致编译错误
// x = 20
// s = "world"
}
在该示例中,我们使用 const 关键字定义了两个常量:x 和 s。其中,x 是一个整数类型常量,初始化为 10;s 是一个字符串类型常量,初始化为 “hello”。我们通过 fmt.Println 函数打印了这两个常量的值,并尝试修改它们的值,结果会导致编译错误。
需要注意的是,在使用常量时,我们需要特别注意常量的作用域和生命周期,并尽可能地遵循最佳实践,以确保代码的正确性和可读性。
数值常量
数值常量是高精度的 值。一个未指定类型的常量由上下文来决定其类型。
在 Go 中,数值常量是一种固定不变的数值,其值在编译时就已经确定,不能被修改。数值常量可以使用各种进制和精度表示。
以下是一些基本的数值常量定义和使用方式:
package main
import "fmt"
func main() {
// 十进制表示整数常量
const x int = 10
// 八进制表示整数常量
const y int = 012
// 十六进制表示整数常量
const z int = 0x1a
// 浮点数常量
const a float64 = 3.14
// 复数常量
const b complex128 = 1 + 2i
// 打印常量的值
fmt.Println(x)
fmt.Println(y)
fmt.Println(z)
fmt.Println(a)
fmt.Println(b)
// 尝试修改常量的值,会导致编译错误
// x = 20
// y = 0123
// z = 0x1b
// a = 3.15
// b = 2 + 1i
}
在该示例中,我们使用不同的进制和精度表示了各种类型的数值常量,包括整数常量、浮点数常量和复数常量。我们通过 fmt.Println 函数打印了这些常量的值,并尝试修改它们的值,结果会导致编译错误。
需要注意的是,在使用数值常量时,我们需要特别注意常量的精度和范围,并尽可能地遵循最佳实践,以确保代码的正确性和可读性。
GO数据基本类型
Go 的数据类型分四大类:
- 基本类型: 数字 number,字符串 string 和布尔型 boolean。
- 聚合类型: 数组 array 和构造体 struct。
- 援用类型: 指针 pointer,切片 slice,字典 map,函数 func 和通道 channel。
- 接口类型: 接口 interface。
其中,基本类型又分为:
- 整型: int8、uint8、byte、int16、uint16、int32、uint32、int64、uint64、int、uint、uintptr。
- 浮点型: float32,float64。
- 复数类型: complex64、complex128。
- 布尔型: bool。
- 字符串: string。
- 字符型: rune。
常用的 Go 的基本类型有
bool
string
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
byte // uint8 的别名
rune // int32 的别名
// 表示一个 Unicode 码点
float32 float64
complex64 complex128
本例展示了几种类型的变量。
同导入语句一样,变量声明也可以“分组”成一个语法块。
int, uint 和 uintptr 在 32 位系统上通常为 32 位宽,在 64 位系统上则为 64 位宽。 当你需要一个整数值时应使用 int 类型,除非你有特殊的理由使用固定大小或无符号的整数类型。
basic-types.go
package basic
import (
"fmt"
"math/cmplx"
)
var (
ToBe bool = false
MaxInt uint64 = 1<<64 - 1
z complex128 = cmplx.Sqrt(-5 + 12i)
)
func BasicTypeDemo() {
fmt.Printf("Type: %T Value: %v\n", ToBe, ToBe)
fmt.Printf("Type: %T Value: %v\n", MaxInt, MaxInt)
fmt.Printf("Type: %T Value: %v\n", z, z)
}
类型转换
表达式 T(v) 将值 v 转换为类型 T。
一些关于数值的转换:
var i int = 42
var f float64 = float64(i)
var u uint = uint(f)
或者,更加简单的形式:
i := 42
f := float64(i)
u := uint(f)
与 C 不同的是,Go 在不同类型的项之间赋值时需要显式转换。试着移除例子中 float64 或 uint 的转换看看会发生什么。
类型推导
在声明一个变量而不指定其类型时(即使用不带类型的 := 语法或 var = 表达式语法),变量的类型由右值推导得出。
当右值声明了类型时,新变量的类型与其相同:
var i int
j := i // j 也是一个 int
不过当右边包含未指明类型的数值常量时,新变量的类型就可能是 int, float64 或 complex128 了,这取决于常量的精度:
i := 42 // int
f := 3.142 // float64
g := 0.867 + 0.5i // complex128
尝试修改示例代码中 v 的初始值,并观察它是如何影响类型的。
整型
Go语言同时提供了有符号和无符号类型的整数运算。
有符号整形数类型:
int8,长度:1字节, 取值范围:(-128 ~ 127)
int16,长度:2字节,取值范围:(-32768 ~ 32767)
int32,长度:4字节,取值范围:(-2,147,483,648 ~ 2,147,483,647)
int64.长度:8字节,取值范围:(-9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807)
无符号整形数类型:
uint8,长度:1字节, 取值范围:(0 ~ 255)
uint16,长度:2字节,取值范围:(0 ~ 65535)
uint32,长度:4字节,取值范围:(0 ~ 4,294,967,295)
uint64.长度:8字节,取值范围:(0 ~ 18,446,744,073,709,551,615)
byte是uint8类型的等价类型,byte类型一般用于强调数值是一个原始的数据而不是 一个小的整数。
uintptr 是一种无符号的整数类型,没有指定具体的bit大小但是足以容纳指针。
uintptr类型只有在底层编程是才需要,特别是Go语言和C语言函数库或操作系统接口相交互的地方。
此外在这里还需要了解下进制的转换方便以后学习和使用:
十进制整数: 使用0-9的数字表示且不以0开头。// 100 123455
八进制整数: 以0开头,0-7的数字表示。 // 0100 0600
十六进制整数: 以0X或者是0x开头,0-9|A-F|a-f组成 //0xff 0xFF12
浮点型
浮点型。float32 精确到小数点后 7 位,float64 精确到小数点后 15 位。
由于精确度的缘故,你在使用 == 或者 != 来比较浮点数时应当非常小心。
浮点型(IEEE-754 标准):
float32:(+- 1e-45 -> +- 3.4 * 1e38)32位浮点类型
float64:(+- 5 1e-324 -> 107 1e308)64位浮点类型
浮点型中指数部分由”E”或”e”以及带正负号的10进制整数表示。例:3.9E-2表示浮点数0.039。3.9E+1表示浮点数39。 有时候浮点数类型值也可以被简化。比如39.0可以被简化为39。0.039可以被简化为.039。在Golang中浮点数的相关部分只能由10进制表示法表示。
复数
复数类型:
complex64: 由两个float32类型的值分别表示复数的实数部分和虚数部分
complex128: 由两个float64类型的值表示复数的实数部分和虚数部分
复数类型的值一般由浮点数表示的实数部分、加号”+”、浮点数表示的虚数部分以及小写字母”i”组成,
例如:
var x complex128 = complex(1,2) //1+2i
对于一个复数 c = complex(x, y) ,可以通过Go语言内置函数 real(z) 获得该复数的实 部,也就是 x ,通过 imag© 获得该复数的虚部,也就是 y 。
布尔型
在Go语言中,布尔值的类型为 bool,值是 true 或 false,布尔可以做3种逻辑运算,&&(逻辑且),||(逻辑或),!(逻辑非),布尔类型的值不支持其他类型的转换.
布尔值可以和&&(AND)和||(OR)操作符结合,并且可能会有短路行为:如果运算符左边值已经可以确定整个布尔表达式的值,那么运算符右边的值将不在被求值,因此下面的表达式总是安全的:
s != "" && s[0] == 'x'
其中s[0]操作如果应用于空字符串将会导致panic异常。
rune类型
字符是 UTF-8 编码的 Unicode 字符,Unicode 为每一个字符而非字形定义唯一的码值(即一个整数),
例如 字符a 在 unicode 字符表是第 97 个字符,所以其对应的数值就是 97,
也就是说对于Go语言处理字符时,97 和 a 都是指的是字符a,而 Go 语言将使用数值指代字符时,将这样的数值称呼为 rune 类型。
rune类型是 Unicode 字符类型,和 int32 类型等价,通常用于表示一个 Unicode 码点。
rune 和 int32 可以互换使用。 一个Unicode代码点通常由”U+”和一个以十六进制表示法表示的整数表示,例如英文字母’A’的Unicode代码点为”U+0041”。
在 Go 中,rune 类型是用于表示 Unicode 码点的类型。Unicode 是一种标准,用于为世界上各种语言和符号分配唯一的数字编码,以便它们可以在计算机中存储和处理。
在 Go 中,rune 类型实际上是一个 int32 类型的别名。它可以用于表示任何 Unicode 码点,并提供了一些有用的函数和方法,用于处理字符串和 Unicode 编码。
以下是一些基本的 rune 类型使用方式:
func RuneDemo() {
// 使用单引号表示一个 rune 类型值
var r rune = '你'
// 打印这个 rune 类型值
fmt.Println(r)
// 将 rune 类型转换为字符串类型
s := string(r)
fmt.Println(s)
// 遍历一个字符串并打印每个字符的 Unicode 码点
for i, c := range "hello 世界" {
fmt.Printf("字符 %d: %U\n", i, c)
}
}
在该示例中:
- 我们首先使用单引号表示了一个 rune 类型值,即 Unicode 码点 “你”。我们通过
fmt.Println函数打印了这个 rune 类型值,并将其转换为字符串类型。 - 接下来,我们遍历了一个字符串,并通过
%U格式化符号打印了每个字符的 Unicode 码点。
输出的结果如下:
20320
你
字符 0: U+0068
字符 1: U+0065
字符 2: U+006C
字符 3: U+006C
字符 4: U+006F
字符 5: U+0020
字符 6: U+4E16
字符 9: U+754C
需要注意的是,在处理字符串和 Unicode 编码时,我们需要特别注意编码和解码的方式,以避免出现错误或者不正确的结果。同时,我们也要了解各种字符集和编码标准之间的差异,以便在处理多语言和多文化环境下的应用程序时保持最佳实践。
此外rune类型的值需要由单引号”‘“包裹,不过我们还可以用另外几种方式表示:
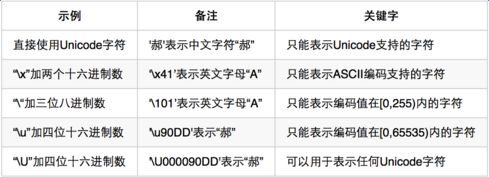
rune类型值的表示中支持几种特殊的字符序列,即:转义符。
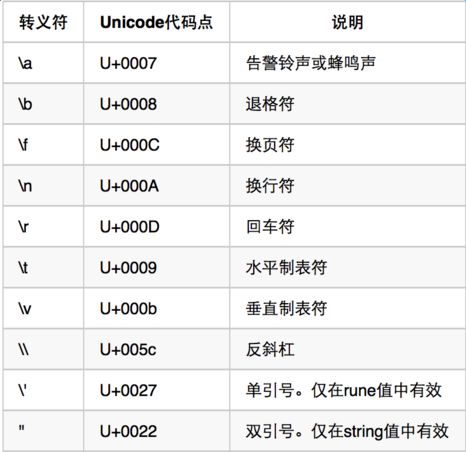
字符串
在Go语言中,组成字符串的最小单位是字符,存储的最小单位是字节,字符串本身不支持修改。
字节是数据存储的最小单元,每个字节的数据都可以用整数表示,例如一个字节储存的字符a,实际存储的是97而非字符的字形,将这个实际存储的内容用数字表示的类型,称之为byte。
字符串是不可变的字节序列,它可以包含任意数据,包括0值字节,但是主要还是为了人可读的文本。内置的 len()函数返回字符串的字节数。
字符串的表示法有两种,即:原生表示法和解释型表示法。原生表示法,需用用反引号”`”把字符序列包起来,如果用解释型表示法,则需要用双引号”””包裹字符序列。
var str1 string = "keke"
var str2 string = `keke`
这两种表示的区别是,前者表示的是所见即所得的(除了回车符)。后者所表示的值中转义符会起作用。字符串值是不可变的,如果我们创建了一个此类型的值,就不可能再对它本身做任何修改。
var str string // 声明一个字符串变量
str = "hai keke" // 字符串赋值
ch := str[0] // 取字符串的第一个字符
整型运算
在整型运算中,算术运算、逻辑运算和比较运算,运算符优先级从上到下递减顺序排列:
* / % << >> & &^
+ - | ^
== != < <= > >=
&&
||
在同一个优先级,使用左优先结合规则,但是使用括号可以明确优先顺序。
bit位操作运算符:
| 符号 | 操作 | 操作数是否区分符号 |
|---|---|---|
| & | 位运算 AND | No |
| ^ | 位运算 XOR | No |
| &^ | 位清空 (AND NOT) | No |
| << | 左移 | Yes |
| >> | 右移 | Yes |
复合数据类型
复合数据类型主要有:
- 数组
- Slice
- Map
- 结构体
- JSON
数组和结构体都是有固定内存大小的数据结构。
在复合数据类型中数组是由同构的元素组成——每个数组元素都是完全相同的类型——结构体则是由异构的元素组成的。
相比之下,slice和map则是动态的数据结构,它们将根据需要动态增长。
数组
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。
在 Go 中,数组是一种固定长度、类型相同的数据结构。数组可以包含任何类型的元素,但是它们的长度在定义时就必须确定,并且无法动态改变。
一个数组的案例
以下是一个基本的数组定义和使用方式:
package main
import "fmt"
func ArrayDemo() {
// 定义一个包含五个整数的数组
var a [5]int
// 打印数组的值
fmt.Println(a)
// 修改数组中的元素
a[2] = 3
fmt.Println(a)
fmt.Println(a[2])
// 定义并初始化一个数组
b := [3]string{"hello", "world", "!"}
fmt.Println(b)
// 遍历数组并打印每个元素
for i, x := range b {
fmt.Printf("b[%d]: %s\n", i, x)
}
}
执行结果如下:
[0 0 0 0 0]
[0 0 3 0 0]
3
[hello world !]
b[0]: hello
b[1]: world
b[2]: !
在该示例中,我们首先使用 var 关键字定义了一个包含五个整数的数组 a。由于没有显式初始化数组中的元素,因此它们都被自动初始化为零值。
我们通过 fmt.Println 函数打印了这个数组的值,并修改了其中的一个元素,并再次打印了这个数组的值和一个特定的元素。
接下来,我们使用短变量声明语法定义了一个包含三个字符串的数组 b,并通过花括号进行了初始化。我们遍历了数组 b 并通过 fmt.Printf 函数打印了每个元素的索引和值。
需要注意的是,在使用数组时,我们需要特别注意数组的长度和元素类型,并尽可能地遵循最佳实践,以确保代码的正确性和可读性。同时,我们也要注意数组在内存中的分布和访问方式,以便在处理大型数据集和高性能应用程序时保持最佳性能。
数组的定义
数组的每个元素都被初始化为元素类型对应的零值,对于数字类型来说就是0。
var m [3]int = [3]int{1, 2, 3}
var n [3]int = [3]int{1, 2}
fmt.Println(n[2]) // "0"
在数组字面值中,如果在数组的长度位置出现的是“…”省略号,则表示数组的长度是根据初始化值的 个数来计算。
m := [...]int{1, 2, 3}
fmt.Printf("%T\n", m) // "[3]int"
数组的长度是数组类型的一个组成部分,因此[3]int和[4]int是两种不同的数组类型。数组的长度必须是常量表达式,因为数组的长度需要在编译阶段确定。
数组可以直接进行比较,当数组内的元素都一样的时候表示两个数组相等。
arr1 := [3]int{1, 2, 3}
arr2 := [3]int{1, 2, 3}
arr3 := [3]int{1, 2, 4}
fmt.Println(arr1 == arr2, arr1 == arr3) //true,false
元素的访问
数组的每个元素可以通过索引下标来访问,索引下标的范围是从0开始到数组长度减1的位置。内置的len函数将返回数组中元素的个数。
数组作为参数
数组可以作为函数的参数传入,但由于数组在作为参数的时候,其实是进行了拷贝,这样在函数内部改变数组的值,是不影响到外面的数组的值。
func ArrIsArgs(arr [4]int) {
arr[0] = 120
}
m := [...]int{1, 2, 3, 4}
ArrIsArgs(m)
如果想要改变外部数组的值,就只能使用指针,
使用指针,在函数内部改变的数组的值,也会改变外面的数组的值:
func ArrIsArgs(arr *[4]int) {
arr[0] = 20
}
m:= [...]int{1, 2, 3, 4}
ArrIsArgs(&m)
这里的* 和&的区别:
- & 是取地址符号 , 即取得某个变量的地址 , 如 ; &a
- *是指针类型变量定义 , 可以表示一个变量是指针类型 , 也可以表示一个指针变量所指向的存储单元 , 也就是这个地址所存储的值.
通常这样的情况下都是用切片来解决,而不是用数组。
由于数组的长度是固定的,因而在使用的时候我们用的最多的是slice(切片),它是可以增长和收缩动态序列,slice功能也更灵活。
Slice
Slice(切片)代表变长的序列,序列中每个元素都有相同的类型。一个slice类型一般写作[]T,其中T代表slice中元素的类型;slice的语法和数组很像,只是没有固定长度而已。
数组和slice关系非常密切,一个slice可以访问数组的部分或者全部数据,而且slice的底层本身就是对数组的引用。
从数组或切片生成新的切片
切片默认指向一段连续内存区域,可以是数组,也可以是切片本身。从连续内存区域生成切片是常见的操作,格式如下:
// slice:表示目标切片对象
// 开始位置:对应目标切片对象的索引
// 结束位置:对应目标切片的结束索引
slice [开始位置 : 结束位置]
一个Slice由三部分组成:指针,长度和容量。
- 内置的len和cap函数可以分别返回slice的长度和容量。
- 指针指向第一个slice元素对应的底层数组元素的地址,要注意的是slice的第一个元素并不一定就是数组的第一个元素。
- 长度对应slice中元素的数目;长度不能超过容量,容量一般是从slice的开始位置到底层数据的结尾位置。内置的len和cap函数分别返回slice的长度和容量。
一个Slice的案例
在 Go 中,切片是一种动态长度的、可变长数组数据结构。它基于数组实现,但是可以动态增加或减少其长度,并且支持各种强大的操作和函数。
以下是一个基本的切片定义和使用方式:
func SliceDemo() {
// 定义一个包含五个整数的数组
a := [5]int{1, 2, 3, 4, 5}
// 声明一个从数组 a 中获取的切片
s := a[1:4]
// 打印切片的值和长度
fmt.Println(s)
fmt.Println(len(s))
// 修改切片中的元素
s[1] = 10
fmt.Println(s)
fmt.Println(a)
// 使用 make 函数创建一个新的切片
b := make([]int, 3)
fmt.Println(b)
// 向切片中添加新的元素
b = append(b, 4, 5, 6)
fmt.Println(b)
// 遍历切片并打印每个元素
for i, x := range b {
fmt.Printf("b[%d]: %d\n", i, x)
}
}
执行结果
[2 3 4]
3
[2 10 4]
[1 2 10 4 5]
[0 0 0]
[0 0 0 4 5 6]
b[0]: 0
b[1]: 0
b[2]: 0
b[3]: 4
b[4]: 5
b[5]: 6
在该示例中,我们首先定义了一个包含五个整数的数组 a,并通过 [1:4] 的方式声明了一个从数组 a 中获取的切片 s。我们通过 fmt.Println 函数打印了这个切片的值和长度,并修改了其中的一个元素,查看了其对原数组的影响。
接下来,我们使用 make 函数创建了一个新的切片 b,并通过 append 函数向其中添加了三个新元素。我们遍历了切片 b 并通过 fmt.Printf 函数打印了每个元素的索引和值。
需要注意的是,在使用切片时,我们需要特别注意其底层数组和长度,并尽可能地遵循最佳实践,以确保代码的正确性和可读性。
同时,我们也要掌握切片的内存分配和释放方式,以便在处理大型数据集和高性能应用程序时保持最佳性能。
从指定范围中生成切片
切片有点像C语言里的指针,指针可以做运算,但代价是内存操作越界,
切片在指针的基础上增加了大小,约束了切片对应的内存区域,切片使用中无法对切片内部的地址和大小进行手动调整,因此切片比指针更安全、强大。
切片和数组密不可分,如果将数组理解为一栋办公楼,那么切片就是把不同的连续楼层出租给使用者,出租的过程需要选择开始楼层和结束楼层,这个过程就会生成切片,表示原有的切片
生成切片的格式中,当开始和结束位置都被忽略时,生成的切片将表示和原切片一致的切片,并且生成的切片与原切片在数据内容上也是一致的,代码如下:
a := []int{1, 2, 3}
fmt.Println(a[:])
a 是一个拥有 3 个元素的切片,将 a 切片使用 a[:] 进行操作后,得到的切片与 a 切片一致,代码输出如下:
[1 2 3]
从数组生成切片,代码如下:
var a = [3]int{1, 2, 3}
fmt.Println(a, a[1:2])
其中 a 是一个拥有 3 个整型元素的数组,被初始化为数值 1 到 3,使用 a[1:2] 可以生成一个新的切片,代码运行结果如下:
[1 2 3] [2]
其中 [2] 就是 a[1:2] 切片操作的结果。
从数组或切片生成新的切片拥有如下特性:
- 取出的元素数量为:结束位置 - 开始位置;
- 取出元素不包含结束位置对应的索引,切片最后一个元素使用
slice[len(slice)]获取; - 当缺少开始位置时,表示从连续区域开头到结束位置;
- 当缺少结束位置时,表示从开始位置到整个连续区域末尾;
- 两者同时缺少时,与切片本身等效;
- 两者同时为 0 时,等效于空切片,一般用于切片复位。
根据索引位置取切片 slice 元素值时,取值范围是(0~len(slice)-1),超界会报运行时错误,生成切片时,结束位置可以填写 len(slice) 但不会报错。下面通过实例来熟悉切片的特性:
重置切片,清空拥有的元素
把切片的开始和结束位置都设为 0 时,生成的切片将变空,代码如下:
a := []int{1, 2, 3}
fmt.Println(a[0:0])
代码输出如下:
[]
直接声明新的切片
除了可以从原有的数组或者切片中生成切片外,也可以声明一个新的切片,每一种类型都可以拥有其切片类型,表示多个相同类型元素的连续集合,因此切片类型也可以被声明,切片类型声明格式如下:
// 其中 name 表示切片的变量名
// Type 表示切片对应的元素类型
var name []Type
下面代码展示了切片声明的使用过程:
// 声明字符串切片
// 声明一个字符串切片,切片中拥有多个字符串
var strList []string
// 声明整型切片
// 声明一个整型切片,切片中拥有多个整型数值
var numList []int
// 声明一个空切片
// 将 numListEmpty 声明为一个整型切片
// 本来会在{}中填充切片的初始化元素,这里没有填充,所以切片是空的,但是此时的 numListEmpty 已经被分配了内存,只是还没有元素
var numListEmpty = []int{}
// 输出3个切片
// 切片均没有任何元素,3 个切片输出元素内容均为空
fmt.Println(strList, numList, numListEmpty)
// 输出3个切片大小
// 没有对切片进行任何操作,strList 和 numList 没有指向任何数组或者其他切片
fmt.Println(len(strList), len(numList), len(numListEmpty))
// 切片判定空的结果
//声明但未使用的切片的默认值是 nil,strList 和 numList 也是 nil,所以和 nil 比较的结果是 true
// numListEmpty 已经被分配到了内存,但没有元素,因此和 nil 比较时是 false
fmt.Println(strList == nil)
fmt.Println(numList == nil)
fmt.Println(numListEmpty == nil)
代码输出结果:
[] [] []
0 0 0
true
true
false
共享底层的数据
多个slice之间可以共享底层的数据,并且引用的数组部分区间可能重叠。
下面有一个月份的数组:
months := [...]string{1: "January", /* ... */, 12: "December"}
一月份是months[1],十二月份是months[12]。
通常,数组的第一个元素从索引0开始,但是月份一般是从1开始的,因此我们声明数组时直接跳过第0个元素,第0个元素会被自动初始化为空字符串。
下图显示了表示一 年中每个月份名字的字符串数组,还有重叠引用了该数组的两个slice。数组这样定义.
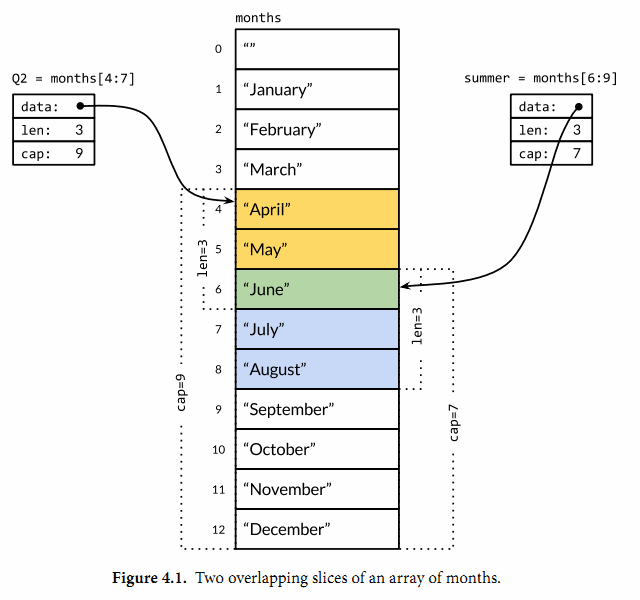
slice的切片操作s[i:j],其中0 ≤ i≤ j≤ cap(s),用于创建一个新的slice,引用s的从第i个元素开始到第j-1个元素的子序列。
新的slice将只有j-i个元素。如果i位置的索引被省略的话将使用0代替,如果j位置的索引被省略的话将使用len(s)代替。
如果切片操作超出cap(s)的上限将导致一个panic异常,但是超出len(s)则是意味着扩展了lice,因为新slice的长度会变大.
切片Slice的长度len与容量cap
切片拥有长度和容量。
len长度是它所包含的元素个数。
cap容量是从它的第一个元素开始数,到其底层数组元素末尾的个数。
切片 s 的长度和容量可通过表达式 len(s) 和 cap(s) 来获取。
package main
import "fmt"
func main() {
s := []int{2, 3, 5, 7, 11, 13}
printSlice(s)
// 截取切片使其长度为 0
s = s[:0]
printSlice(s)
// 拓展其长度
s = s[:4]
printSlice(s)
// 舍弃前两个值
s = s[2:]
printSlice(s)
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s)
}
运行结果
len=6 cap=6 [2 3 5 7 11 13]
len=0 cap=6 []
len=4 cap=6 [2 3 5 7]
len=2 cap=4 [5 7]
slice创建方式
slice创建方式主要有两种:1.基于数组创建。2.直接创建
- 基于数组创建:
arrVar := [4]int{1, 2, 3,4}
sliceVar := arrVar[1:3]
数组arrVar和sliceVar里面的地址其实是一样的,因而如果你改变sliceVar里面的变量,那么arrVar里面的变量也会随之改变。
- 直接创建
内建函数new分配了零值填充的元素类型的内存空间,并且返回其地址,一个指针类型的值。
var p *[]int = new([]int) //分配slice结构内存
var m []int = make([]int,100) //m指向一个新分配的有100个整数的数组
new 分配;make 初始化,, 因此:
new(T) 返回 *T 指向一个零值 T
make(T) 返回初始化后的 T
注意: make仅适用于 map,slice 和 channel,并且返回的不是指针。应当用 new 获得特定的指针。
内置的make函数创建一个指定元素类型、长度和容量的slice。容量部分可以省略,在这种情况下,容量将等于长度。
使用内置的make()函数来创建。事实上还是会创建一个匿名的数组,只是不需要我们来定义
使用 make() 函数构造切片
如果需要动态地创建一个切片,可以使用 make() 内建函数,格式如下:
// 其中 Type 是指切片的元素类型
// size 指的是为这个类型分配多少个元素
// cap 为预分配的元素数量,这个值设定后不影响 size,只是能提前分配空间,降低多次分配空间造成的性能问题
make( []Type, size, cap )
示例如下:
a := make([]int, 2)
b := make([]int, 2, 10)
fmt.Println(a, b)
fmt.Println(len(a), len(b))
代码输出如下:
[0 0] [0 0]
2 2
其中 a 和 b 均是预分配 2 个元素的切片,只是 b 的内部存储空间已经分配了 10 个,但实际使用了 2 个元素。
容量不会影响当前的元素个数,因此 a 和 b 取 len 都是 2。
温馨提示:使用 make() 函数生成的切片一定发生了内存分配操作,但给定开始与结束位置(包括切片复位)的切片只是将新的切片结构指向已经分配好的内存区域,设定开始与结束位置,不会发生内存分配操作。
append()为切片添加元素
Go语言的内建函数 append() 可以为切片动态添加元素,代码如下所示:
var a []int
a = append(a, 1) // 追加1个元素
a = append(a, 1, 2, 3) // 追加多个元素, 手写解包方式
a = append(a, []int{1,2,3}...) // 追加一个切片, 切片需要解包
不过需要注意的是,在使用 append() 函数为切片动态添加元素时,如果空间不足以容纳足够多的元素,切片就会进行“扩容”,此时新切片的长度会发生改变。
切片在扩容时,容量的扩展规律是按容量的 2 倍数进行扩充,例如 1、2、4、8、16……,代码如下:
// 声明一个整型切片
var numbers []int
// 循环向 numbers 切片中添加 10 个数
for i := 0; i < 10; i++ {
numbers = append(numbers, i)
// 打印输出切片的长度、容量和指针变化,使用函数 len() 查看切片拥有的元素个数,使用函数 cap() 查看切片的容量情况
fmt.Printf("len: %d cap: %d pointer: %p\n", len(numbers), cap(numbers), numbers)
}
代码输出如下:
len: 1 cap: 1 pointer: 0xc0420080e8
len: 2 cap: 2 pointer: 0xc042008150
len: 3 cap: 4 pointer: 0xc04200e320
len: 4 cap: 4 pointer: 0xc04200e320
len: 5 cap: 8 pointer: 0xc04200c200
len: 6 cap: 8 pointer: 0xc04200c200
len: 7 cap: 8 pointer: 0xc04200c200
len: 8 cap: 8 pointer: 0xc04200c200
len: 9 cap: 16 pointer: 0xc042074000
len: 10 cap: 16 pointer: 0xc042074000
通过查看代码输出,可以发现一个有意思的规律:切片长度 len 并不等于切片的容量 cap。
往一个切片中不断添加元素的过程,类似于公司搬家,公司发展初期,资金紧张,人员很少,所以只需要很小的房间即可容纳所有的员工,随着业务的拓展和收入的增加就需要扩充工位,但是办公地的大小是固定的,无法改变,因此公司只能选择搬家,每次搬家就需要将所有的人员转移到新的办公点。
- 员工和工位就是切片中的元素。
- 办公地就是分配好的内存。
- 搬家就是重新分配内存。
- 无论搬多少次家,公司名称始终不会变,代表外部使用切片的变量名不会修改。
- 由于搬家后地址发生变化,因此内存“地址”也会有修改。
除了在切片的尾部追加,我们还可以在切片的开头添加元素:
var a = []int{1,2,3}
a = append([]int{0}, a...) // 在开头添加1个元素
a = append([]int{-3,-2,-1}, a...) // 在开头添加1个切片
在切片开头添加元素一般都会导致内存的重新分配,而且会导致已有元素全部被复制 1 次,因此,从切片的开头添加元素的性能要比从尾部追加元素的性能差很多。
因为 append 函数返回新切片的特性,所以切片也支持链式操作,我们可以将多个 append 操作组合起来,实现在切片中间插入元素:
var a []int
a = append(a[:i], append([]int{x}, a[i:]...)...) // 在第i个位置插入x
a = append(a[:i], append([]int{1,2,3}, a[i:]...)...) // 在第i个位置插入切片
每个添加操作中的第二个 append 调用都会创建一个临时切片,并将 a[i:] 的内容复制到新创建的切片中,然后将临时创建的切片再追加到 a[:i] 中。
切片复制(切片拷贝)
Go语言的内置函数 copy() 可以将一个数组切片复制到另一个数组切片中,如果加入的两个数组切片不一样大,就会按照其中较小的那个数组切片的元素个数进行复制。copy() 函数的使用格式如下:
// 其中 srcSlice 为数据来源切片
// destSlice 为复制的目标(也就是将 srcSlice 复制到 destSlice)
// 目标切片必须分配过空间且足够承载复制的元素个数,并且来源和目标的类型必须一致
// copy() 函数的返回值表示实际发生复制的元素个数。
copy( destSlice, srcSlice []T) int
下面的代码展示了使用 copy() 函数将一个切片复制到另一个切片的过程:
slice1 := []int{1, 2, 3, 4, 5}
slice2 := []int{5, 4, 3}
copy(slice2, slice1) // 只会复制slice1的前3个元素到slice2中
copy(slice1, slice2) // 只会复制slice2的3个元素到slice1的前3个位置
虽然通过循环复制切片元素更直接,不过内置的 copy() 函数使用起来更加方便,copy() 函数的第一个参数是要复制的目标 slice,第二个参数是源 slice,两个 slice 可以共享同一个底层数组,甚至有重叠也没有问题。
下面通过代码演示对切片的引用和复制操作后对切片元素的影响:
package main
import "fmt"
func main() {
// 设置元素数量为1000
const elementCount = 1000
// 预分配足够多的元素切片
// 预分配拥有 1000 个元素的整型切片,这个切片将作为原始数据
srcData := make([]int, elementCount)
// 将切片赋值
// 将 srcData 填充 0~999 的整型值
for i := 0; i < elementCount; i++ {
srcData[i] = i
}
// 引用切片数据
// 将 refData 引用 srcData,切片不会因为等号操作进行元素的复制
refData := srcData
// 预分配足够多的元素切片
// 预分配与 srcData 等大(大小相等)、同类型的切片 copyData
copyData := make([]int, elementCount)
// 将数据复制到新的切片空间中
// 使用 copy() 函数将原始数据复制到 copyData 切片空间中
copy(copyData, srcData)
// 修改原始数据的第一个元素
// 修改原始数据的第一个元素为 999
srcData[0] = 999
// 打印引用切片的第一个元素
// 引用数据的第一个元素将会发生变化
fmt.Println(refData[0])
// 打印复制切片的第一个和最后一个元素
// 打印复制数据的首位数据,由于数据是复制的,因此不会发生变化
fmt.Println(copyData[0], copyData[elementCount-1])
// 复制原始数据从4到6(不包含)
// 将 srcData 的局部数据复制到 copyData 中
copy(copyData, srcData[4:6])
// 打印复制局部数据后的 copyData 元素
for i := 0; i < 5; i++ {
fmt.Printf("%d ", copyData[i])
}
}
Go语言从切片中删除元素
Go语言并没有对删除切片元素提供专用的语法或者接口,需要使用切片本身的特性来删除元素,根据要删除元素的位置有三种情况,分别是从开头位置删除、从中间位置删除和从尾部删除,其中删除切片尾部的元素速度最快。
从开头位置删除
删除开头的元素可以直接移动数据指针:
a = []int{1, 2, 3}
a = a[1:] // 删除开头1个元素
a = a[N:] // 删除开头N个元素
也可以不移动数据指针,但是将后面的数据向开头移动,可以用 append 原地完成(所谓原地完成是指在原有的切片数据对应的内存区间内完成,不会导致内存空间结构的变化):
a = []int{1, 2, 3}
a = append(a[:0], a[1:]...) // 删除开头1个元素
a = append(a[:0], a[N:]...) // 删除开头N个元素
还可以用 copy() 函数来删除开头的元素:
a = []int{1, 2, 3}
a = a[:copy(a, a[1:])] // 删除开头1个元素
a = a[:copy(a, a[N:])] // 删除开头N个元素
从中间位置删除
对于删除中间的元素,需要对剩余的元素进行一次整体挪动,同样可以用 append 或 copy 原地完成:
a = []int{1, 2, 3, ...}
a = append(a[:i], a[i+1:]...) // 删除中间1个元素
a = append(a[:i], a[i+N:]...) // 删除中间N个元素
a = a[:i+copy(a[i:], a[i+1:])] // 删除中间1个元素
a = a[:i+copy(a[i:], a[i+N:])] // 删除中间N个元素
从尾部删除
a = []int{1, 2, 3}
a = a[:len(a)-1] // 删除尾部1个元素
a = a[:len(a)-N] // 删除尾部N个元素
删除开头的元素和删除尾部的元素都可以认为是删除中间元素操作的特殊情况,下面来看一个示例:删除切片指定位置的元素,
package main
import "fmt"
func main() {
// 声明一个整型切片,保存含有从 a 到 e 的字符串
seq := []string{"a", "b", "c", "d", "e"}
// 指定删除位置
// 为了演示和讲解方便,使用 index 变量保存需要删除的元素位置
index := 2
// 查看删除位置之前的元素和之后的元素
// seq[:index] 表示的就是被删除元素的前半部分,值为 [1 2]
// seq[index+1:] 表示的是被删除元素的后半部分,值为 [4 5]
fmt.Println(seq[:index], seq[index+1:])
// 将删除点前后的元素连接起来
// 使用 append() 函数将两个切片连接起来
seq = append(seq[:index], seq[index+1:]...)
// 输出连接好的新切片,此时,索引为 2 的元素已经被删除
fmt.Println(seq)
}
代码输出结果:
[a b] [d e]
[a b d e]
提示:连续容器的元素删除无论在任何语言中,都要将删除点前后的元素移动到新的位置,随着元素的增加,这个过程将会变得极为耗时,因此,当业务需要大量、频繁地从一个切片中删除元素时,如果对性能要求较高的话,就需要考虑更换其他的容器了(如双链表等能快速从删除点删除元素)。
range循环迭代切片
通过前面的学习我们了解到切片其实就是多个相同类型元素的连续集合,既然切片是一个集合,那么我们就可以迭代其中的元素,Go语言有个特殊的关键字 range,它可以配合关键字 for 来迭代切片里的每一个元素,如下所示:
// 创建一个整型切片,并赋值
slice := []int{10, 20, 30, 40}
// 迭代每一个元素,并显示其值
// index 和 value 分别用来接收 range 关键字返回的切片中每个元素的索引和值
// 这里的 index 和 value 不是固定的,读者也可以定义成其它的名字
for index, value := range slice {
fmt.Printf("Index: %d Value: %d\n", index, value)
}
上面代码的输出结果为:
Index: 0 Value: 10
Index: 1 Value: 20
Index: 2 Value: 30
Index: 3 Value: 40
当迭代切片时,关键字 range 会返回两个值,第一个值是当前迭代到的索引位置,第二个值是该位置对应元素值的一份副本,需要强调的是,range 返回的是每个元素的副本,而不是直接返回对该元素的引用
range 提供了每个元素的副本
// 创建一个整型切片,并赋值
slice := []int{10, 20, 30, 40}
// 迭代每个元素,并显示值和地址
for index, value := range slice {
fmt.Printf("Value: %d Value-Addr: %X ElemAddr: %X\n", value, &value, &slice[index])
}
输出结果为:
Value: 10 Value-Addr: 10500168 ElemAddr: 1052E100
Value: 20 Value-Addr: 10500168 ElemAddr: 1052E104
Value: 30 Value-Addr: 10500168 ElemAddr: 1052E108
Value: 40 Value-Addr: 10500168 ElemAddr: 1052E10C
因为迭代返回的变量是一个在迭代过程中根据切片依次赋值的新变量,所以 value 的地址总是相同的,要想获取每个元素的地址,需要使用切片变量和索引值(例如上面代码中的 &slice[index])。
如果不需要索引值,也可以使用下划线_来忽略这个值,代码如下所示:
// 创建一个整型切片,并赋值
slice := []int{10, 20, 30, 40}
// 迭代每个元素,并显示其值
for _, value := range slice {
fmt.Printf("Value: %d\n", value)
}
使用空白标识符(下划线)来忽略索引值
// 创建一个整型切片,并赋值
slice := []int{10, 20, 30, 40}
// 迭代每个元素,并显示其值
for _, value := range slice {
fmt.Printf("Value: %d\n", value)
}
输出结果为:
Value: 10
Value: 20
Value: 30
Value: 40
关键字 range 总是会从切片头部开始迭代。如果想对迭代做更多的控制,则可以使用传统的 for 循环,代码如下所示。:
使用传统的 for 循环对切片进行迭代
// 创建一个整型切片,并赋值
slice := []int{10, 20, 30, 40}
// 从第三个元素开始迭代每个元素
for index := 2; index < len(slice); index++ {
fmt.Printf("Index: %d Value: %d\n", index, slice[index])
}
输出结果为:
Index: 2 Value: 30
Index: 3 Value: 40
在前面的学习中我们了解了两个特殊的内置函数 len() 和 cap(),可以用于处理数组、切片和通道,对于切片,函数 len() 可以返回切片的长度,函数 cap() 可以返回切片的容量,在上面的示例中,使用到了函数 len() 来控制循环迭代的次数。
当然,range 关键字不仅仅可以用来遍历切片,它还可以用来遍历数组、字符串、map 或者通道等。
映射Map
映射Map是一个存储键值对的无序集合,映射Map是一种巧妙并且实用的数据结构。
它是一个无序的key/value对的集合,其中所有的key都是不同的,然后通过给定的key可以在常数时间复杂度内检索、更新或删除对应的value。
在Go语言中,一个map就是一个映射Map的引用,map类型可以写为map[K]V,其中K和V分别对应key和value。
map中所有的key都有相同的类型,所有的value也有着相同的类型,但是key和value之间可以是不同的数据类型。
其中K对应的key必须是支持==比较运算符的数据类型,所以map可以通过测试key是否相等来判断是否已经存在。
map的申明和创建
- Map的声明
var m map[string] string
m是声明的变量名,sting是对应的Key的类型,string是value的类型。
- 创建
Go内置的make函数可以创建map:
m := make(map[string]int)
我们也可以用map字面值的语法创建map,同时还可以指定一些最初的key/value:
m := map[string]int{
"keke": 001,
"jame": 002,
}
这个等价于:
m := make(map[string]int)
m["keke"] = 001
m["jame"] = 002
另外一种创建map的方式是map[string]int{}。
3.元素的删除
Map可以使用内置的delete函数可以删除元素:
delete(ages, "jame") //可以删除m["jame"]
map的使用案例
在 Go 中,map 是一种无序的键值对数据结构。它可以用于存储和访问任意类型的数据,并提供了各种强大的操作和函数。
以下是一个基本的 map 定义和使用方式:
func MapDemo() {
// 声明并初始化一个空的 map
var m map[string]int = make(map[string]int)
// 设置 map 中的键值对
m["apple"] = 10
m["banana"] = 20
m["orange"] = 30
// 打印 map 中的值
fmt.Println(m)
// 获取 map 中的一个值
fmt.Println(m["banana"])
// 删除 map 中的一个键值对
delete(m, "orange")
fmt.Println(m)
// 检查 map 中是否包含某个键
if v, ok := m["apple"]; ok {
fmt.Printf("m[\"apple\"] = %d\n", v)
}
// 遍历 map 并打印每个键值对
for k, v := range m {
fmt.Printf("%s: %d\n", k, v)
}
}
在该示例中,我们首先使用 make 函数声明并初始化了一个空的 map m。
我们通过 m["key"] = value 的方式向 map 中添加了三个键值对,并通过 fmt.Println 函数打印了这个 map 的值。
接下来,我们演示了如何获取、删除和检查 map 中的键值对,并通过 for range 循环遍历了整个 map 并打印了每个键值对的值。
需要注意的是,在使用 map 时,我们需要特别注意其键类型和值类型,并尽可能地遵循最佳实践,以确保代码的正确性和可读性。同时,我们也要了解 map 的底层实现方式,以便在处理大型数据集和高性能应用程序时保持最佳性能。
禁止对map元素取址
map中的元素并不是一个变量,因此我们不能对map的元素进行取址操作:
_ = &ages["keke"] // compile error: cannot take address of map element
禁止对map元素取址的原因是:map可能随着元素数量的增长而重新分配更大的内存空间,从而可能导致之前的地址无效。
要想遍历map中全部的key/value对的话,可以使用range风格的for循环实现,和之前的slice遍历语法类似。下面的迭代语句将在每次迭代时设置name和age变量,它们对应下一个键/值对:
for k, v := range m {
fmt.Printf("%s\t%d\n", k, v)
}
Map的迭代顺序是不确定的,并且不同的哈希函数实现可能导致不同的遍历顺序。
在实践中,遍历的顺序是随机的,每一次遍历的顺序都不相同。这是故意的,每次都使用随机的遍历顺序可以强制要求程序不会依赖具体的哈希函数实现。
如果要按顺序遍历key/value对,我们必须显式地对key进行排序,可以使用sort包的Strings函数对字符串slice进行排序。常见的处理方式:
import "sort"
var names []string
for name := range ages {
names = append(names, name)
}
sort.Strings(names)
for _, name := range names {
fmt.Printf("%s\t%d\n", name, ages[name])
}
map类型的零值是nil,也就是没有引用任何映射Map。
var ages map[string]int
fmt.Println(ages == nil) // "true"
fmt.Println(len(ages) == 0) // "true"
结构体
Go提供的结构体就是把使用各种数据类型定义的不同变量组合起来的高级数据类型。
type Rectangle struct {
width float64
length float64
}
通过type定义一个新的数据类型,然后是新的数据类型名称rectangle,最后是struct关键字,表示这个高级数据类型是结构体类型。
一个结构体的例子
在 Go 中,结构体是一种自定义的数据类型,用于组合不同类型的字段以表示复杂的实体或概念。
结构体可以包含任何类型的字段,包括基本类型、数组、切片、map、函数等。
以下是一个基本的结构体定义和使用方式:
// 定义一个结构体类型
type person struct {
name string
age int
}
func StructDemo() {
// 使用结构体类型创建两个变量
p1 := person{"Alice", 18}
p2 := person{name: "Bob", age: 20}
// 打印结构体变量的值
fmt.Println(p1)
fmt.Println(p2)
// 修改结构体中的字段
p1.age = 19
p2.name = "Charlie"
fmt.Println(p1)
fmt.Println(p2)
}
输出如下:
{Alice 18}
{Bob 20}
{Alice 19}
{Charlie 20}
在该示例中,我们首先通过 type 关键字定义了一个名为 person 的结构体类型,并声明了两个字段 name 和 age。接着,我们使用该结构体类型创建了两个变量 p1 和 p2,并通过花括号进行了初始化。
我们通过 fmt.Println 函数打印了这两个结构体变量的值,并分别修改了其中的一个字段,并再次打印了它们的值。
需要注意的是,在使用结构体时,我们需要特别注意字段名称和类型,并尽可能地遵循最佳实践,以确保代码的正确性和可读性。
同时,我们也要掌握结构体与方法、嵌套结构体、指针等高级特性,以便在处理复杂的数据结构和面向对象编程时保持最佳性能和代码质量。
其实构体类型和基础数据类型使用方式差不多,唯一的区别就是结构体类型可以通过.来访问内部的成员。包括给内部成员赋值和读取内部成员值。
如果你知道结构体成员定义的顺序,也可以不使用key:value的方式赋值,直接按照结构体成员定义的顺序给它们赋值。
type Rectangle struct {
width float64
length float64
}
func main() {
var r = Rectangle{100, 200}
fmt.Println("Width:", r.width, "* Length:",r.length, "= Area:", r.width*r.length)
}
输出结果为:
Width: 100 * Length: 200 = Area: 20000
结构体参数传递方式
Go函数的参数传递方式是值传递,这句话对结构体也是适用的。
package main
import (
"fmt"
)
type Rectangle struct {
width float64
length float64
}
func double_area(r Rectangle) float64 {
r.width *= 2
r.length *= 2
return r.width * r.length
}
func main() {
var r = Rectangle{100, 200}
fmt.Println(double_area(r))
fmt.Println("Width:", r.width, "Length:", r.length)
}
输出为:
80000
Width: 100 Length: 200
虽然在double_area函数里面我们将结构体的宽度和长度都加倍,但仍然没有影响main函数里面的rect变量的宽度和长度。
要想改变函数输出的长方形的值,我们使用指针可以做到。
指针的主要作用就是在函数内部改变传递进来变量的值。
package main
import (
"fmt"
)
type Rectangle struct {
width float64
length float64
}
func (r *Rectangle) area() float64 {
return r.width * r.length
}
func main() {
var r = new(Rectangle)
r.width = 100
r.length = 200
fmt.Println("Width:", r.width, "Length:", r.length,"Area:", r.area())
}
使用了new函数来创建一个结构体指针Rectangle,也就是说r的类型是Rectangle,结构体遇到指针的时候,你不需要使用去访问结构体的成员,直接使用.引用就可以了。
所以上面的例子中我们直接使用r.width=100 和r.length=200来设置结构体成员值。
因为这个时候r是结构体指针,所以我们定义area()函数的时候结构体限定类型为*Rectangle。
结构体组合函数
上面我们在main函数中计算了矩形的面积,但是我们觉得矩形的面积如果能够作为矩形结构体的“内部函数”提供会更好。
这样我们就可以直接说这个矩形面积是多少,而不用另外去取宽度和长度去计算。现在我们看看结构体“内部函数”定义方法:
package main
import (
"fmt"
)
type Rect struct {
width, length float64
}
func (rect Rect) area() float64 {
return rect.width * rect.length
}
func main() {
var rect = Rect{100, 200}
fmt.Println("Width:", rect.width, "Length:", rect.length,
"Area:", rect.area())
}
咦?这个是什么“内部方法”,根本没有定义在Rect数据类型的内部啊?
确实如此,我们看到,虽然main函数中的rect变量可以直接调用函数area()来获取矩形面积,但是area()函数确实没有定义在Rect结构体内部,这点和C语言的有很大不同。
Go使用组合函数的方式,来为结构体定义结构体方法。
我们仔细看一下上面的area()函数定义。
首先是关键字func表示这是一个函数,第二个参数是结构体类型和实例变量,第三个是函数名称,第四个是函数返回值。
这里我们可以看出area()函数和普通函数定义的区别就在于area()函数多了一个结构体类型限定。这样一来Go就知道了这是一个为结构体定义的方法。
这里需要注意一点就是定义在结构体上面的函数(function)一般叫做方法(method)。
这是为何呢?
我们看到,虽然main函数中的rect变量可以直接调用函数area()来获取矩形面积,但是area()函数确实没有定义在Rect结构体内部,这点和C语言的有很大不同。
结构体特性
如果结构体成员名字是以大写字母开头的,那么该成员就是导出的;这是Go语言导出规则决定的。
一个结构体可能同时包含导出和未导出的成员. 直白的讲就是首字母大写的结构体字段可以被导出,也就是说,在其他包中可以进行读写。结构体字段名以小写字母开头是当前包的私有的,函数定义也是类似的。
如果结构体没有任何成员的话就是空结构体,写作struct{}。它的大小为0,也不包含任何信息,但是有时候依然是有价值的。
有些Go开发者用map模拟set数据结构时,用它来代替map中布尔类型的value,只是强调key的重要性,但是因为节约的空间有限,而且语法比较复杂,所有我们通常避免避免这样的用法。
一个命名为S的结构体类型将不能再包含S类型的成员:因为一个聚合的值不能包含它自身(该限制同样适应于数组)。但是S类型的结构体可以包含*S指针类型的成员,这可以让我们创建递归的数据结构,比如链表和树结构等。
type tree struct {
value int
left, right *tree
}
结构体嵌入和匿名成员
type Point struct {
X, Y int
}
type Circle struct {
Center Point
Radius int
}
type Wheel struct {
Circle Circle
Spokes int
}
访问每个成员:
var w Wheel
w.Circle.Center.X = 8
w.Circle.Center.Y = 8
w.Circle.Radius = 5
w.Spokes = 20
Go语言有一个特性让我们只声明一个成员对应的数据类型,而不指名成员的名字,这类成员就叫匿名成员。
匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针。
下面的代码中,Circle和Wheel各自都有一个匿名成员。我们可以说Point类型被嵌入到了Circle结构体,同时Circle类型被嵌入到了Wheel结构体。
type Circle struct {
Point // 匿名字段,struct
Radius int
}
type Wheel struct {
Circle // 匿名字段,struct
Spokes int
}
得意于匿名嵌入的特性,我们可以直接访问叶子属性而不需要给出完整的路径:
var w Wheel
w.X = 8 // equivalent to w.Circle.Point.X = 8
w.Y = 8 // equivalent to w.Circle.Point.Y = 8
w.Radius = 5 // equivalent to w.Circle.Radius = 5
w.Spokes = 20
在右边的注释中给出的显式形式访问这些叶子成员的语法依然有效,因此匿名成员并不是真的无法访问了。其中匿名成员Circle和Point都有自己的名字——就是命名的类型名字——但是这些名字在点操作符中是可选的。
我们在访问子成员的时候可以忽略任何匿名成员部分。
结构体字面值并没有简短表示匿名成员的语法,因此下面的语句都不能编译通过:
w = Wheel{8, 8, 5, 20} // compile error: unknown fields
w = Wheel{X: 8, Y: 8, Radius: 5, Spokes: 20} // compile error: unknown fields
结构体字面值必须遵循形状类型声明时的结构,所以我们只能用下面的两种语法,它们彼此是等价的.
通过这个我们看出来struct不仅仅能够将struct作为匿名字段,自定义类型、内置类型都可以作为匿名字段,而且可以在相应的字段上面进行函数操作。
结构体tag
在Golang中结构体和数据库表的映射关系的建立是通过struct Tag来实现的。
package main
import (
"fmt"
"reflect" // 这里引入reflect模块
)
type User struct {
Name string `json:"name"` //这引号里面的就是tag
Passwd int `json:"passwd"`
}
func main() {
user := &User{"keke", 123456}
s := reflect.TypeOf(user).Elem() //通过反射获取type定义
for i := 0; i < s.NumField(); i++ {
fmt.Println(s.Field(i).Tag.Get("json")) //将tag输出出来
}
}
运行 :
name
passwd
结构体的成员Tag可以是任意的字符串面值,但是通常是一系列用空格分隔的key:”value”键值对序列;因为值中含义双引号字符,因此成员Tag一般用原生字符串面值的形式书写。
这里有必要解释下指针这块,在Golang中很多时候都是需要用指针结合结构体开发的。
通常指针是存储一个变量的内存地址的变量。
在Golang中,指针不参与计算但是可以用来获取地址的,例如变量a的内存地址为&a,这里的&就是获取a的地址。如果一个指针,它的值是在别的地方的地址,而且我们想要获取这个地址的值,可以使用*符号。*符号是为取值符。例如上面的&a是一个地址,那么这个地址里存储的值为*&a。
& 和 *符号的区别
注意:这里的 & 和 *符号的区别,& 运算符,用来获取指针地址,而*运算符是用来获取地址里存储的值。
此外指针的值和指针的地址是不同的概念,指针的值: 指的是一个地址,是别的内存地址。指针的地址: 指的是存储指针内存块的地址。
通常 & 运算符是对变量取地址,如:变量a的地址是&a, *符号运算符对指针取值,如:*&a,就是a变量所在地址的值,也就是a的值.此外 &和 * 以互相抵消,同时注意,*&可以抵消掉,但&*是不可以抵消的, a和 *&a是一样的,都是a的值,因为* & 互相抵消掉了,同理a和*&*&*&*&a是一样的 (因为4个*&互相抵消掉了)。
var a = 2
var b *int = &a
所以a和*&a和*b是一样的,都是a的值,值为2 (把b当做&a看)
应用示例:
package main
import (
"fmt"
)
func main(){
b := 200
a := &b
fmt.Println("the address of b:",a)
fmt.Println("the value of b:",*a)
var p *int //p的类型是[int型的指针]
p = &b //p的值为 [b的地址]
fmt.Printf("b=%d,p=%d,*p=%d \n",b,p,*p)
*p = 5 // *p的值为[[b的地址]的指针] (其实就是b),这行代码也就等价于b= 5
fmt.Printf("b=%d,p=%d,*p=%d\n",b,p,*p)
}
运行:
the address of b: 0xc4200180b8
the value of b: 200
b=200,p=842350559416,*p=200
b=5,p=842350559416,*p=5
通常我们传一个参数值到被调用函数里面时,实际上是传了这个值的一份copy,当在被调用函数中修改参数值的时候,调用函数中相应实参不会发生任何变化,因为数值变化只作用在copy上。
传指针比较轻量级 (*bytes),只是传内存地址,我们可以用指针传递体积大的结构体。如果用参数值传递的话,在每次copy上面就会花费相对较多的系统开销(内存和时间)。所以当你要传递大的结构体的时候,用指针是一个明智的选择。
Golang中string,slice,map这三种类型的实现机制类似指针,所以可以直接传递,而不用取地址后传递指针。
注意:若函数需改变slice的长度,则仍需要取地址传递指针。
如果要访问指针 p 指向的结构体中某个元素 x,不需要显式地使用 * 运算,可以直接 p.x;
JSON
JavaScript对象表示法(JSON)是一种用于发送和接收结构化信息的标准协议。
在类似的协议中,JSON并不是唯一的一个标准协议。
XML、ASN.1和Google的Protocol Buffers都是类似的协议,并且有各自的特色,但是由于简洁性、可读性和流行程度等原因,JSON是应用最广泛的一个。
JSON是对JavaScript中各种类型的值——字符串、数字、布尔值和对象——Unicode本文编码。
基本的JSON类型有数字(十进制或科学记数法)、布尔值(true或false)、字符串,
其中字符串是以双引号包含的Unicode字符序列,支持和Go语言类似的反斜杠转义特性,
不过JSON使用的是\Uhhhh转义数字来表示一个UTF-16编码(译注:UTF-16和UTF-8一样是一种变长的编码,有些Unicode码点较大的字符需要用4个字节表示;而且UTF-16还有大端和小端的问题),而不是Go语言的rune类型。
这些基础类型可以通过JSON的数组和对象类型进行递归组合。
一个JSON数组是一个有序的值序列,写在一个方括号中并以逗号分隔;一个JSON数组可以用于编码Go语言的数组和slice。
一个JSON对象是一个字符串到值的映射,写成以系列的name:value对形式,用花括号包含并以逗号分隔;JSON的对象类型可以用于编码Go语言的map类型(key类型是字符串)和结构体。
解析JSON
数据结构 --> 指定格式 = 序列化 或 编码(传输之前)
指定格式 --> 数据格式 = 反序列化 或 解码(传输之后)
序列化是在内存中把数据转换成指定格式(data -> string),反之亦然(string -> data structure)。
编码也是一样的,只是输出一个数据流(实现了 io.Writer 接口);解码是从一个数据流(实现了 io.Reader)输出到一个数据结构。
json字符串:
{"servers":[{"serverName":"Shanghai","serverIP":"127.0.0.1"},{"serverName":"Beijing","serverIP":"127.0.0.2"}]}
反序列化:json解析到结构体
在Go中我们经常需要做数据结构的转换,Go中提供的处理json的标准包是 encoding/json,主要使用的是以下两个方法:
// 序列化 结构体=> json
func Marshal(v interface{}) ([]byte, error)
// 反序列化 json=>结构体
func Unmarshal(data []byte, v interface{}) error
序列化前后的数据结构有以下的对应关系:
bool for JSON booleans
float64 for JSON numbers
string for JSON strings
[]interface{} for JSON arrays
map[string]interface{} for JSON objects
nil for JSON null
如果我们有一段json要转换成结构体就需要用到(Unmarshal)样的函数:
func Unmarshal(data []byte, v interface{}) error
通过这个函数我们就可以实现解析:
package main
import (
"encoding/json"
"fmt"
)
type Server struct {
ServerName string
ServerIP string
}
type Serverslice struct {
Servers []Server
}
func main() {
var s Serverslice
str := `{"servers":[{"serverName":"Shanghai","serverIP":"127.0.0.1"}, {"serverName":"Beijing","serverIP":"127.0.0.2"}]}`
json.Unmarshal([]byte(str), &s)
fmt.Println(s)
}
我们首先定义了与json数据对应的结构体,数组对应slice,字段名对应JSON里面的KEY,在解析的时候,如何将json数据与struct字段相匹配呢?例如JSON的key是Foo,那么怎么找对应的字段呢?这就用到了我们上面结构体说的tag。
同时能够被赋值的字段必须是可导出字段(即首字母大写)。同时JSON解析的时候只会解析能找得到的字段,找不到的字段会被忽略,这样的一个好处是:当你接收到一个很大的JSON数据结构而你却只想获取其中的部分数据的时候,你只需将你想要的数据对应的字段名大写,即可轻松解决这个问题。
序列化:结构体转json
结构体转json就需要用到JSON包里面通过Marshal函数来处理:
func Marshal(v interface{}) ([]byte, error)
假设我们还是需要生成上面的服务器列表信息,那么如何来处理呢?
package main
import (
"encoding/json"
"fmt"
)
type Server struct {
ServerName string
ServerIP string
}
type Serverslice struct {
Servers []Server
}
func main() {
var s Serverslice
s.Servers = append(s.Servers, Server{ServerName: "Shanghai", ServerIP: "127.0.0.1"})
s.Servers = append(s.Servers, Server{ServerName: "Beijing", ServerIP: "127.0.0.2"})
b, err := json.Marshal(s)
if err != nil {
fmt.Println("json err:", err)
}
fmt.Println(string(b))
}
输出结果:
{"Servers":[{"ServerName":"Shanghai","ServerIP":"127.0.0.1"},{"ServerName":"Beijing","ServerIP":"127.0.0.2"}]}
我们看到上面的输出字段名的首字母都是大写的,如果你想用小写的首字母怎么办呢?
把结构体的字段名改成首字母小写的?
JSON输出的时候必须注意,只有导出的字段才会被输出,如果修改字段名,那么就会发现什么都不会输出,所以必须通过struct tag定义来实现:
type Server struct {
ServerName string `json:"serverName"`
ServerIP string `json:"serverIP"`
}
type Serverslice struct {
Servers []Server `json:"servers"`
}
针对JSON的输出,我们在定义struct tag的时候需要注意的几点是:
- 字段的tag是”-“,那么这个字段不会输出到JSON
- tag中带有自定义名称,那么这个自定义名称会出现在JSON的字段名中,例如上面例子中serverName
- tag中如果带有”omitempty”选项,那么如果该字段值为空,就不会输出到JSON串中
- 如果字段类型是bool, string, int, int64等,而tag中带有”,string”选项,那么这个字段在输出到JSON的时候会把该字段对应的值转换成JSON字符串
type Server struct {
// ID 不会导出到JSON中
ID int `json:"-"`
// ServerName2 的值会进行二次JSON编码
ServerName string `json:"serverName"`
ServerName2 string `json:"serverName2,string"`
// 如果 ServerIP 为空,则不输出到JSON串中
ServerIP string `json:"serverIP,omitempty"`
}
s := Server {
ID: 1,
ServerName: `Go "1.0" `,
ServerName2: `Go "1.10" `,
ServerIP: ``,
}
b, _ := json.Marshal(s)
os.Stdout.Write(b)
输出内容:
{"serverName":"Go \"1.0\" ","serverName2":"\"Go \\\"1.10\\\" \""}
Marshal函数只有在转换成功的时候才会返回数据,但是我们应该注意下:
- JSON对象只支持string作为key,所以要编码一个map,那么必须是map[string]T这种类型(T是Go语言中任意的类型)
- Channel, complex和function是不能被编码成JSON的
- 嵌套的数据是不能编码的,不然会让JSON编码进入死循环
- 指针在编码的时候会输出指针指向的内容,而空指针会输出null
- 解析到interface
在Go中Interface{}可以用来存储任意数据类型的对象,这种数据结构正好用于存储解析的未知结构的json数据的结果。JSON包中采用map[string]interface{}和[]interface{}结构来存储任意的JSON对象和数组。Go类型和JSON类型的对应关系如下:
- bool 代表 JSON booleans,
- loat64 代表 JSON numbers,
- string 代表 JSON strings,
- nil 代表 JSON null.
通常情况下我们会拿到一段json数据:
b := []byte(`{"Name":"Ande","Age":10,"Hobby":"Football"
现在开始解析到接口中:
var f interface{}
err := json.Unmarshal(b, &f)
在这个接口f里面存储了一个map类型,他们的key是string,值存储在空的interface{}里
f = map[string]interface{}{
"Name": "Ande",
"Age": ,
"Hobby":"Football"
}
通过断言的方式我们把结构体强制转换数据类型:
m := f.(map[string]interface{})
通过断言之后,我们就可以通过来访问里面的数据:
for k, v := range m {
switch vv := v.(type) {
case string:
fmt.Println(k, "is string", vv)
case int:
fmt.Println(k, "is int", vv)
case float64:
fmt.Println(k,"is float64",vv)
case []interface{}:
fmt.Println(k, "is an array:")
for i, u := range vv {
fmt.Println(i, u)
}
default:
fmt.Println(k, "is of a type I don't know how to handle")
}
}
通过interface{}与type assert的配合,我们就可以解析未知结构的JSON数了。
其实很多时候我们通过类型断言,操作起来不是很方便,我们可以使用一个叫做simplejson的包,在处理未知结构体的JSON数据:
data,err := NewJson([]byte(`{
"test": {
"array": [1, "2", 3, 4, 5]
"int": 10,
"float": 5.150,
"bignum": 9223372036854775807,
"string": "simplejson",
"bool": true
}
}`))
arr, _ := js.Get("test").Get("array").Array()
i, _ := js.Get("test").Get("int").Int()
ms := js.Get("test").Get("string").MustString()
这个库用起来还是很方便也很简单。
json中的Encoder和Decoder
通常情况下,我们可能会从 Request 之类的输入流中直接读取 json 进行解析或将编码(encode)的 json 直接输出,为了方便,标准库为我们提供了 Decoder 和 Encoder 类型。它们分别通过一个 io.Reader 和 io.Writer 实例化,并从中读取数据或写数据。
#Decoder 从 r io.Reader 中读取数据,`Decode(v interface{})` 方法把数据转换成对应的数据结构
func NewDecoder(r io.Reader) *Decoder
#Encoder 的 `Encode(v interface{})` 把数据结构转换成对应的 JSON 数据,然后写入到 w io.Writer 中
func NewEncoder(w io.Writer) *Encoder
查看源码可以发现,Encoder.Encode/Decoder.Decode 和 Marshal/Unmarshal 实现大体是一样。 但是也有一些不同点:Decoder 有一个方法 UseNumber,它的作用是,在默认情况下,json 的 number 会映射为 Go 中的 float64,有时候,这会有些问题,比如:
b := []byte(`{"Name":"keke","Age":25,"Money":200.3}`)
var person = make(map[string]interface{})
err := json.Unmarshal(b, &person)
if err != nil {
log.Fatalln("json unmarshal error:", err)
}
age := person["Age"]
log.Println(age.(int))
运行:
> interface conversion: interface is float64, not int. #age是int,结果 panic 了
然后我们改用Decoder.Decode(用上 UseNumber):
b := []byte(`{"Name":"keke","Age":25,"Money":200.3}`)
var person = make(map[string]interface{})
decoder := json.NewDecoder(bytes.NewReader(b))
decoder.UseNumber()
err := decoder.Decode(&person)
if err != nil {
log.Fatalln("json unmarshal error:", err)
}
age := person["Age"]
log.Println(age.(json.Number).Int64())
- json.RawMessage能够延迟对 json进行解码
此外我们在解析的时候,还可以把某部分先保留为 JSON 数据不要解析,等到后面得到更多信息的时候再去解析。
流程控制语句:for、if、else、switch 和 defer
for语句
Go 只有一种循环结构:for 循环。
基本的 for 循环由三部分组成,它们用分号隔开:
- 初始化语句:在第一次迭代前执行
- 条件表达式:在每次迭代前求值
- 后置语句:在每次迭代的结尾执行
初始化语句通常为一句短变量声明,该变量声明仅在for语句的作用域中可见。
一旦条件表达式的布尔值为false,循环迭代就会终止。
注意:
和 C、Java、JavaScript 之类的语言不同,Go 的 for 语句后面的三个构成部分外没有小括号, 大括号 { } 则是必须的。
for 使用案例
在 Go 中,for 语句用于循环执行代码块多次,直到满足某个条件为止。Go 提供了三种形式的 for 循环:基本循环、条件循环和 range 循环。
以下是一个基本的 for 循环示例:
package main
import "fmt"
func main() {
// 基本循环
for i := 0; i < 5; i++ {
fmt.Println(i)
}
// 条件循环
j := 0
for j < 5 {
fmt.Println(j)
j++
}
// range 循环
s := []string{"foo", "bar", "baz"}
for i, v := range s {
fmt.Printf("s[%d]: %s\n", i, v)
}
}
在该示例中,我们首先使用基本循环形式 for init; condition; post { } 循环输出 0 ~ 4 的整数。接着,我们使用条件循环形式 for condition { } 实现同样的效果,并输出相同的结果。
最后,我们使用 range 循环形式 for index, value := range array { } 遍历了切片 s 并打印了其中每个元素的下标和值。
需要注意的是,在使用 for 循环时,我们需要特别注意循环条件和计数器的初始化和更新方式,并尽可能地遵循最佳实践,以确保代码的正确性和可读性。同时,我们也要了解 for 循环与 break、continue、goto 等语句的配合使用,以便实现更复杂的控制流程和算法逻辑。
for 是 Go 中的 “while”
此时你可以去掉分号,因为 C 的 while 在 Go 中叫做 for。
package main
import "fmt"
func main() {
sum := 1
for sum < 1000 {
sum += sum
}
fmt.Println(sum)
}
无限循环
如果省略循环条件,该循环就不会结束,因此无限循环可以写得很紧凑。
package main
func main() {
for {
}
}
if语句
Go 的 if 语句与 for 循环类似,表达式外无需小括号 ( ) ,而大括号 { } 则是必须的。
在 Go 中,if 语句用于根据条件执行不同的代码块。Go 还提供了 else、else if 和嵌套 if 等语法来实现更复杂的逻辑判断和控制流程。
以下是一个基本的 if 语句示例:
package main
import "fmt"
func main() {
// 基本 if 语句
x := 10
if x > 5 {
fmt.Println("x is greater than 5")
}
// if else 语句
y := 3
if y > 5 {
fmt.Println("y is greater than 5")
} else {
fmt.Println("y is less than or equal to 5")
}
// if else if 语句
z := 0
if z > 0 {
fmt.Println("z is positive")
} else if z < 0 {
fmt.Println("z is negative")
} else {
fmt.Println("z is zero")
}
}
在该示例中,我们首先使用基本 if 语句形式 if condition { } 判断变量 x 是否大于 5,并输出相应的结果。接着,我们使用 if else 形式 if condition { } else { } 判断变量 y 是否大于 5,并输出相应的结果。
最后,我们使用 if else if 形式 if condition1 { } else if condition2 { } else { } 对变量 z 进行了三重判断,并输出相应的结果。
需要注意的是,在使用 if 语句时,我们需要特别注意条件表达式和花括号的位置,并尽可能地遵循最佳实践,以确保代码的正确性和可读性。同时,我们也要了解 if 语句与布尔运算符、短变量声明、类型断言等语法的配合使用,以便在处理更复杂的逻辑和算法时保持最佳性能和代码质量。
if 后的简短语句
同 for 一样, if 语句可以在if后面,条件表达式前执行一个简单的语句。该语句声明的变量作用域仅在 if 之内。
func PowIf(x, n, lim float64) float64 {
if v := math.Pow(x, n); v < lim {
return v
}
return lim
}
在最后的 return 语句处使用 v 看看。 是不可见的。
switch 语句
switch 是编写一连串 if - else 语句的简便方法。
switch 匹配逻辑是:匹配第一个值等于条件表达式的 case 语句。
Go 的 switch 语句类似于 C、C++、Java、JavaScript 和 PHP 中的,不过 Go 只运行选定的 case,而非之后所有的 case。
实际上,Go 自动提供了在这些语言中每个 case 后面所需的 break 语句。 除非以 fallthrough 语句结束,否则分支会自动终止。
Go 的另一点重要的不同在于 switch 的 case 无需为常量,且取值不必为整数。
switch 的例子
func SwitchDemo() {
fmt.Print("Go runs on ")
switch os := runtime.GOOS; os {
case "darwin":
fmt.Println("OS X.")
case "linux":
fmt.Println("Linux.")
default:
// freebsd, openbsd,
// plan9, windows...
fmt.Printf("%s.\n", os)
}
}
switch 的求值顺序
switch 的 case 语句从上到下顺次执行,直到匹配成功时停止。
例如,
switch i {
case 0:
case f():
}
在 i==0 时 f 不会被调用。
没有条件的 switch
没有条件的 switch 同 switch true 一样。这种形式能将一长串 if-then-else 写得更加清晰。
func main() {
t := time.Now()
switch {
case t.Hour() < 12:
fmt.Println("Good morning!")
case t.Hour() < 17:
fmt.Println("Good afternoon.")
default:
fmt.Println("Good evening.")
}
}
defer语句
defer 语句会将函数推迟到外层函数返回之后执行。
推迟调用的函数其参数会立即求值,但直到外层函数返回前该函数都不会被调用。
func DeferDemo() {
defer fmt.Println("world")
fmt.Println("hello")
}
执行结果:
hello
world
defer 栈
推迟的函数调用会被压入一个栈中。当外层函数返回时,被推迟的函数会按照后进先出的顺序调用。
func DeferDemo2() {
fmt.Println("counting")
for i := 0; i < 10; i++ {
defer fmt.Println(i)
}
fmt.Println("done")
}
执行结果
counting
done
9
8
7
6
5
4
3
2
1
panic异常
在 Go 中,panic 是一种用于在程序出现严重错误时引发异常的机制。当程序遇到无法处理的错误或不可恢复的情况时,可以使用 panic 函数来立即停止程序并输出相应的异常信息。
panic 使用示例
以下是一个简单的 panic 示例:
package main
import "fmt"
func main() {
// 引发 panic 异常
panic("a problem occurred")
// 下面的代码将不会被执行
fmt.Println("Hello, World!")
}
在该示例中,我们使用 panic 函数引发了一个名为 “a problem occurred” 的异常,并停止了程序的执行。由于 panic 函数立即停止程序,因此下面的 fmt.Println 语句将不会被执行。
需要注意的是,在使用 panic 机制时,我们需要特别注意异常类型和异常信息的准确性和清晰度,并尽可能地遵循最佳实践,以确保代码的可读性和可维护性。同时,我们也要了解 recover 函数的使用方法和场景,以便在必要时恢复程序的执行并处理异常情况。
错误和异常
错误和异常这两个是不同的概念,非常容易混淆。
很多人习惯将一切非正常情况都看做错误,而不区分错误和异常,即使程序中可能有异常抛出,也将异常及时捕获并转换成错误。
错误指的是可能出现问题的地方出现了问题,比如压缩一个文件时失败,这种情况在人们可以意料之中的事情;但是异常指的是不应该出现问题的地方出现了问题,比如引用了空指针,这种情况在人们的意料之外。
因而,错误是业务过程的一部分,而异常不是。
在 Go 中,error 是一种用于描述程序执行过程中可能出现的错误状态的类型。当程序遇到某个异常情况时,可以通过返回一个 error 类型值来通知调用者并进行相应的处理。
Golang中引入error接口类型作为错误处理的标准模式,如果函数要返回错误,则返回值类型列表中肯定包含error。
error处理过程类似于C语言中的错误码,可逐层返回,直到被处理。
以下是一个简单的 error 示例:
package main
import (
"fmt"
"errors"
)
func divide(x, y float64) (float64, error) {
if y == 0 {
return 0, errors.New("division by zero")
}
return x / y, nil
}
func main() {
// 调用函数并检查是否有错误发生
result, err := divide(10.0, 2.0)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(result)
// 再次调用函数并检查是否有错误发生
result, err = divide(5.0, 0.0)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(result)
}
在该示例中,我们定义了一个名为 divide 的函数,用于计算两个浮点数的商,并返回相应的结果和错误信息。当除数为零时,我们使用 errors.New 函数创建了一个新的 error 类型值并将其返回。在 main 函数中,我们分别调用 divide 函数并检查是否有错误发生,如果有则打印相应的错误信息。
需要注意的是,在使用 error 机制时,我们需要特别注意错误类型和错误信息的准确性和清晰度,并尽可能地遵循最佳实践,以确保代码的可读性和可维护性。同时,我们也要了解 defer 函数的使用方法和场景,以便在必要时释放资源并处理异常情况。
异常处理流程
Golang中引入两个内置函数panic和recover来触发和终止异常处理流程,同时引入关键字defer来延迟执行defer后面的函数。
一直等到包含defer语句的函数执行完毕时,延迟函数(defer后的函数)才会被执行,而不管包含defer语句的函数是通过return的正常结束,还是由于panic导致的异常结束。你可以在一个函数中执行多条defer语句,它们的执行顺序与声明顺序相反。
当程序运行时候,如果遇到引用空指针、下标越界或显式调用panic函数等情况,则会先触发panic函数的执行,然后调用延迟函数。
调用者继续传递panic,因此该过程一直在调用栈中重复发生:函数停止执行,调用延迟执行函数等。
如果一路在defer延迟函数中没有recover函数的调用,则会到达协程的起点,该协程结束,然后终止其他所有协程,包括主协程.
错误和异常从Golang机制上讲,就是error和panic的区别。
很多其他语言也一样,比如C++/Java,没有error但有errno,没有panic但有throw。
一般而言,当panic异常发生时,程序会中断运行,并立即执行在该goroutine中被延迟的函数(defer 机制)。随后,程序崩溃并输出日志信 息。
日志信息包括panic value和函数调用的堆栈跟踪信息。panic value通常是某种错误信息。对于每个goroutine,日志信息中都会有与之相对的,发生panic时的函数调用堆栈跟踪信息。
通常,我们不需要再次运行程序去定位问题,日志信息已经提供了足够的诊断依据。因此,在我们填写问题报告时,一般会将panic异常和日志信息一并记录。
func panic(interface{})
虽然Go的panic机制,非常类似于其他语言的异常,但panic的适用场景有一些不同。
由于panic会引起程序的崩溃,因此panic一般用于严重错误,如程序内部的逻辑不一致。
通常认为任何崩溃都表明代码中存在漏洞,所以对于大部分漏洞,我们应该使用Go提供的错误机制,而不是panic,尽量避免程序的崩溃。
在健壮的程序中,任何可以预料到的错误,如不正确的输入、错误的配置或是失败的I/O操作都应该被优雅的处理,最好的处理方式,就是使用Go的错误机制。
recover捕获异常
通常来说,不应该对panic异常做任何处理,但有时,也许我们可以从异常中恢复,至少我们可以在程序崩溃前,做一些操作。
如果在deferred函数中调用了内置函数recover,并且定义该defer语句的函数发生了panic异常,recover会使程序从panic中恢复,并返回panic value。导致panic异常的函数不会继续运行,但能正常返回。
在未发生panic时调用recover,recover会返回nil。
func recover() interface{}
recover 函数用来获取 panic 函数的参数信息,只能在延时调用 defer 语句调用的函数中直接调用才能生效,如果在 defer 语句中也调用 panic 函数,则只有最后一个被调用的 panic 函数的参数会被 recover 函数获取到。
如果 goroutine 没有 panic,那调用 recover 函数会返回 nil。
以语言解析器为例,说明recover的使用场景。
考虑到语言解析器的复杂性,即使某个语言解析器目前工作正常,也无法肯定它没有漏洞。
因此,当某个异常出现时,我们不会选择让解析器崩溃,而是会将panic异常当作普通的解析错误,并附加额外信息提醒用户报告此错误。
func Parse(input string) (s *Syntax, err error) {
defer func() {
if p := recover(); p != nil {
err = fmt.Errorf("internal error: %v", p)
}
}()
// ...parser...
}
从中可以看到defer函数帮助Parse从panic中恢复。
在defer函数内部,panic value被附加到错误信息中;并用err变量接收错误信息,返回给调用者。
我们也可以通过调用runtime.Stack往错误信息中添加完整的堆栈调用信息。
但是如果不加区分的恢复所有的panic异常,不是可取的做法;因为在panic之后,无法保证包级变量的状态仍然和我们预期一致。
比如,对数据结构的一次重要更新没有被完整完成、文件或者网络连接没有被关闭、获得的锁没有被释放。此外,如果写日志时产生的panic被不加区分的恢复,可能会导致漏洞被忽略。
虽然把对panic的处理都集中在一个包下,有助于简化对复杂和不可以预料问题的处理,但作为被广泛遵守的规范,你不应该试图去恢复其他包引起的panic。
公有的API应该将函数的运行失败作为error返回,而不是panic。同样的,你也不应该恢复一个由他人开发的函数引起的panic,比如说调用者传入的回调函数,因为你无法确保这样做是安全的。
因此安全的做法是有选择性的recover。换句话说,只恢复应该被恢复的panic异常,此外,这些异常所占的比例应该尽可能的低。
为了标识某个panic是否应该被恢复,我们可以将panic value设置成特殊类型。在recover时对panic value进行检查,如果发现panic value是特殊类型,就将这个panic作为errror处理,如果不是,则按照正常的panic进行处理.
还有 5W字待发布
本文,仅仅是《Golang 圣经》 的第一部分。
《Golang 圣经》后面的内容 更加精彩,涉及到高并发、分布式微服务架构、 WEB开发架构,具体请关注进展,请关注《技术自由圈》 公众号。
如果需要领取 《Golang 圣经》, 请关注《技术自由圈》 公众号,发送暗号 “领电子书” 。
最后,如果学习过程中遇到问题,可以来尼恩的 万人高并发社群中交流。
参考文献:
清华大学出版社《Java高并发核心编程 卷2 加强版》PDF
《尼恩Java面试宝典专题33:BST、AVL、RBT红黑树、三大核心数据结构(卷王专供+ 史上最全 + 2023面试必备》PDF
技术自由的实现路径 PDF:
实现你的 架构自由:
《吃透8图1模板,人人可以做架构》
《10Wqps评论中台,如何架构?B站是这么做的!!!》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《100亿级订单怎么调度,来一个大厂的极品方案》
《2个大厂 100亿级 超大流量 红包 架构方案》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
《响应式圣经:10W字,实现Spring响应式编程自由》
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
《Linux命令大全:2W多字,一次实现Linux自由》
实现你的 网络 自由:
《TCP协议详解 (史上最全)》
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
4000页《尼恩Java面试宝典 》 40个专题
以上尼恩 架构笔记、面试题 的PDF文件更新,请到下面《技术自由圈》公号取↓↓↓