Python多线程,多进程爬虫
Python多线程,多进程爬虫
爬虫中为什么要用多进程、多线程
python 的多线程与多进程问题在上一节 python–进程和线程实训我们已经详细的学习过了,对多进程与多线程有着一定的了解。 众所周知,一定程度上多进程与多线程会加快程序的运行速度。 在 python 程序中普通运行是串行,在进程数小于或等于 CPU 核心数下多进程是并行,而大于就会混有并发,而多线程就只是并发。 串行、并行与并发图解介绍:
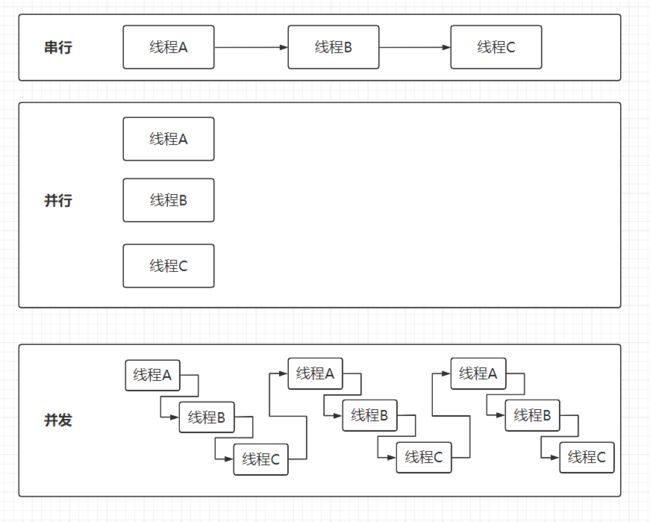
在爬虫中使用并行的多进程,可以同时下载数据,或者是边爬取下面的网页,边下载上一个网页的数据。 那为什么多线程可不可以变成并行呢? Python 解释器内部有个 GIL,影响着线程的调用。 GIL 的全称是Global Interpreter Lock(全局解释器锁),来源是python设计之初的考虑,为了数据安全所做的决定。 在单核 CPU 下的多线程其实都只是并发,不是并行,并发和并行从宏观上来讲都是同时处理多路请求的概念。但并发和并行又有区别,并行是指两个或者多个事件在同一时间点发生;而并发是指两个或多个事件在同一时间段内发生。
python多线程的执行方式:
- 获取 GIL
- 执行代码直到 sleep 或者是 Python 虚拟机将其挂起。
- 释放 GIL
可见,某个线程想要执行,必须先获取 GIL,GIL 会根据执行的字节码行数以及时间片释放,并且在遇到 io 操作的时候会主动释放。我们可以把 GIL 看作是“通行证”,并且在一个 python 进程中,GIL 只有一个。拿不到通行证的线程,就不允许进入 CPU 执行。 而每次释放 GIL 锁,线程进行锁竞争、切换线程,会消耗资源。并且由于 GIL 锁存在,python 里一个进程永远只能同时执行一个线程(拿到 GIL 的线程才能执行),这就是为什么在多核 CPU 上,python 的多线程效率并不高。 总的意思是说每个 CPU 在同一时间只能执行一个线程。
那岂不是 python 多线程没得用了? 那么 python 的多线程就要分情况讨论:
- CPU 密集型代码(各种循环处理、计数等等),在这种情况下,由于计算工作多,ticks 计数很快就会达到阈值,然后触发 GIL 的释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以 python 下的多线程对 CPU 密集型代码并不友好。
- IO 密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有 IO 操作会进行 IO 等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程 B ,可以不浪费 CPU 的资源,从而能提升程序执行效率)。
所以 python 的多线程对 IO 密集型代码比较友好。在爬虫中使用多线程可以在线程 A 往文件里保存数据时,切换至线程 B 去执行。 上一个实训也讲述了多进程与多线程的优缺点,对于爬虫来说多线程不一定就会比多进程慢。
爬虫中如何使用多进程与多线程
那么使用多进程、多线程爬去网页上的图片数据是如何操作的呢? 爬车桌面图片在之前的数据持久化(非数据库)的实训中有编写过。 如果改编成多进程、多线程的话就要将保存图片的步骤,封装成函数
import os
import requests
import threading
from lxml import etree
from multiprocessing import Pool
url = 'https://www.enterdesk.com/special/wmtp/'
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'
}
dir_path = './images'
image_genre = ['bmp', 'jpg', 'png', 'tif', 'gif']
if not os.path.exists(dir_path):
os.mkdir(dir_path)
def save_img(img_url):
# 筛选链接,只爬图片链接
if str(image_genre).find(img_url.split('.')[-1]) != -1:
name = img_url.split('/')[-1]
img_path = os.path.join(dir_path, name)
img = requests.get(img_url, headers)
# 保存图片
with open(img_path, 'wb')as file:
file.write(img.content)
r = requests.get(url, headers=headers)
r.encoding = 'utf-8'
html = r.text
tree = etree.HTML(html)
if __name__ == '__main__':
"""
多线程
"""
# thread = []
# 由于只需要爬取图片,不需要分类以及是否爬全,所以直接爬取所有有src链接
# for i in tree.xpath('//@src'):
# thread.append(threading.Thread(target=save_img, args=(i, )))
#
# for t in thread:
# t.start()
# for t in thread:
# t.join()
"""
多进程
"""
result = []
pool = Pool(4)
# 由于只需要爬取图片,不需要分类以及是否爬全,所以直接爬取所有有src链接
for i in tree.xpath('//@src'):
result.append(pool.apply_async(save_img, args=(i, )))
pool.close()
pool.join()