TensorRT入门实战,TensorRT Plugin介绍以及TensorRT INT8加速
文章目录
- 一、TensorRT介绍,工作流程和优化策略
-
- TensorRT是什么
- TensorRT的工作流程
- TRT优化策略介绍
- 二、TensorRT的组成和基本使用流程
- 三、TensorRT的基本使用流程
- 四、TensorRT Demo代码 : SampleMNIST
-
- Caffe Parser方式构建
- 五. TensorRT Plugin
-
- 基本概念
- 工作流程
- API介绍
- Dynamic Shape Plugin API
- Static Shape官方Demo代码讲解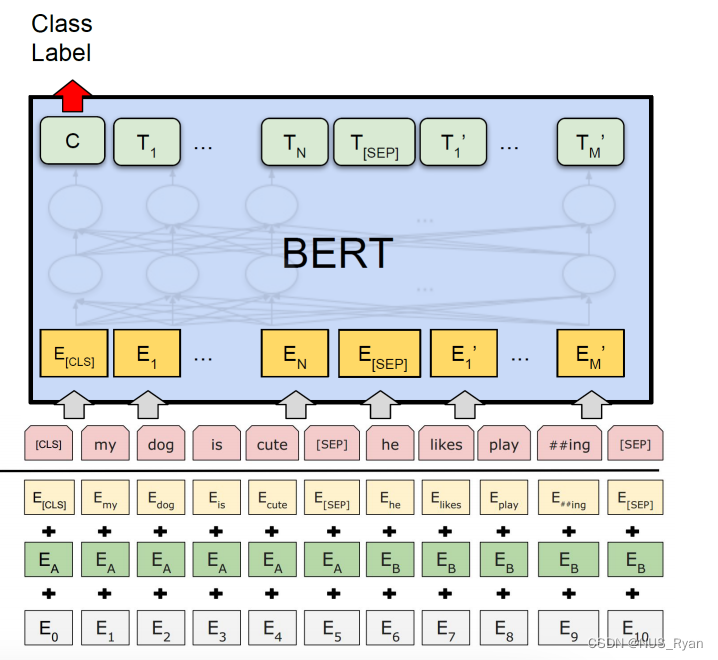
- TensorRT Plugin Creator
- TensorRT Plugin 如何进行debug
- 六. TensorRT INT8 加速
-
- FP16
- INT8
-
- 为什么INT8量化会快呢?
- 为什么INT8对于准确度的影响是有限的
- 动态对称量化算法
- 动态非对称量化算法
- 静态对称量化算法
- 进阶讨论:INT8量化算法的实际收益
- 进阶讨论:如何使用TensorRT进行大规模上线
- 总结和建议
一、TensorRT介绍,工作流程和优化策略
TensorRT是什么
首先,根据上图可知,TensorRT是一个适配NVIDIA GPU的深度学习的推理框架,其能实现高性能深度学习推理,优化器和加速库,能够实现低延迟和高吞吐量,可以部署到超大规模的数据中心,嵌入式(Jetson)或者汽车产品。
TensorRT的工作流程
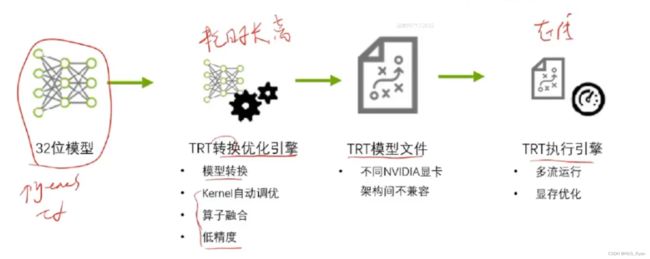
TRT优化策略介绍
- 低精度优化: 比如INT8加速和FP16精度
- Kernel自动调优: 比如在cublas中对于矩阵乘法有多种实现,如何采取合适的矩阵乘法方式就是kernel自动调优。
- 算子融合:
比如原算子如下: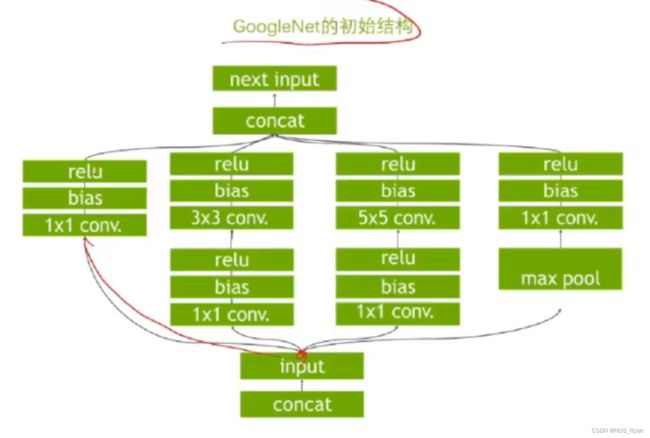
融合后的算子如下:

4. 多流运行
5 显存优化
二、TensorRT的组成和基本使用流程
TRT的核心部分是闭源的:

GIthub开源代码,比如模型解析器(caffe,onnx),代码例子和plugin例子:
三、TensorRT的基本使用流程

四、TensorRT Demo代码 : SampleMNIST
bool SampleMNIST::build(){
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger.getTRTLogger()));
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetwork());
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
auto parser = SampleUniquePtr<nvinfer1::ICaffeParser>(nvcaffeparser1::createCaffeParser());
constructNetwork(parser,network);
builder->setMaxBatchSize(mParams.batchSize); //kernel调优前要确认好
config->setMaxWorkspaceSize(16_MiB);
config->setFlag(BuilderFlag::kGPU_FALLBACK);
config->setFlag(BuilderFlag::kSTRICT_TYPES);
if(mParams.fp16){
config->setFlag(BuilderFlag::kFP16);
}
if(mParams.int8){
config->setFlag(BuilderFlag::kINT8);
}
mEngine=std::shared_ptr<nvinfer1::ICudaEngine>(
builder->buildEngineWithConfig(*network,*config),
samplesCommon::InferDeleter());
return true;
}
Caffe Parser方式构建
基于Parser的方式构建Network非常简洁

五. TensorRT Plugin
基本概念
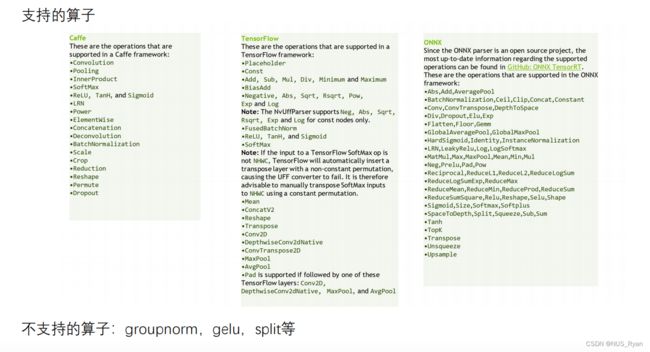
Plugin存在的意义是扩展TensorRT不支持的算子以及进行深度优化和合并已有的算子
- TensorRT支持和不支持的算子如下:
- 对于复杂的网络,合并算子是非常需要的,比如可以将下方的代码合并为一个plugin,从而有效提高性能:
其实官方也实现了很多TRT Plugin Demo

工作流程

API介绍
在TensorRT中,API可以大概分为两类,一类是Static Shape,即输入维度定死,另一类是Dynamic Shape,即输入维度是动态的。
在TensorRT中,Dynamic Shape允许模型接受不同尺寸的输入,而无需重新构建引擎。这对于处理可变大小的输入数据非常有用。下面是一个使用TensorRT C++ API构建具有动态输入形状的模型的简化示例:
#include 在这个例子中,我们首先使用kEXPLICIT_BATCH标志创建具有显式批处理支持的网络。然后,我们添加一个输入层,其形状为(-1, 3, -1, -1),其中-1表示维度是动态的。接下来,我们为输入创建一个优化配置文件,并设置最小、最优和最大尺寸。最后,我们使用这个配置文件构建引擎。
当使用这个引擎进行推理时,您可以为具有动态形状的输入设置不同尺寸的数据,而无需重新构建引擎。请注意,这个例子仅说明了构建具有动态输入形状的引擎的基本概念。实际上,您需要向网络中添加其他层,并根据您的需求调整其他参数。
Dynamic Shape Plugin API

Static Shape官方Demo代码讲解
下面我们实现一个EmbLayerNormPlugin Static Shape 的DemoEmbLayerNormPlugin 是 BERT 模型Embedding + Layernorm的合并,BERT 的 EmbLayerNormPlugin 层,主要有以下5个参数:
- 三个 Embedding 参数矩阵,分别是词语的 Embedding,位置的 Embedding, token type 的 Embedding。
- Embedding 操作除上面3个 embedding 做对应位置的求和,同时还要过一个 LayerNorm 操作,即对Embedding 方向的维度做一个归一化,所以还需要LayerNorm 的 beta 和 gamma 参数。
embLayerNormPlugin.h
/*
* Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#ifndef TRT_EMB_LAYER_NORM_PLUGIN_H
#define TRT_EMB_LAYER_NORM_PLUGIN_H
#include "NvInferPlugin.h"
#include embLayerNormPlugin.cu
/*
* Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#include "NvInfer.h"
#include "embLayerNormPlugin.h"
#include "logger.h"
#include "pluginKernels.h"
#include "pluginUtil.h"
#include TensorRT Plugin Creator

TensorRT Plugin 如何进行debug
TRT是闭源软件,API相对比较复杂
-
无论是使用APP还是parser构建网络,模型转换完后,结果误差很大要怎么办?
在通过parser转化完了网络之后,使用tensorflow的dump API接口查看网络结构是否正确 -
增加了自定义Plugin实现算子合并,结果对不上,怎么办?
使用了Plugin,同时也要写单元测试代码 -
使用FP16 或者 INT8优化策略之后,算法精确度掉了很多要怎么办?
(1)官方: 将可疑的层输出设置为network output(比较繁琐)
(2) 经验 : 增加一个debug的plugin,可以参考:
六. TensorRT INT8 加速
FP16
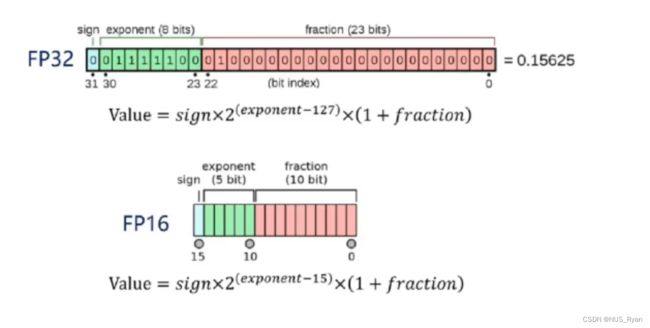
如何在Tensor RT中采用FP16进行优化?当然,首先要调用builder->platformHasFastFp16();查看显卡是否支持FP16.

INT8
INT8量化就是将基于浮点的模型转换成低精度的INT8数值进行计算,以加快推理速度。

为什么INT8量化会快呢?
(1)对于计算能力大于等于SM_61的显卡,如Tesla P4/P40 GPU,NVIDIA提供了新的INT8点乘运算的指令支持-DP4A。该计算过程可以获得理论上最大4倍的性能提升。
(2)Volta架构中引入了Tensor Core也能加速INT8运算
FP16 和 INT8能加速的本质:
通过指令 或者 硬件技术,在单位时钟周期内,FP16 和 INT8 类型的运算次数 大于 FP32 类型的运算次数。
为什么INT8对于准确度的影响是有限的
神经网络的特性:具有一定的鲁棒性。
原因:训练数据一般都是有噪声的,神经网络的训练过程就是从噪声中识别出有效的信息。
思路:可以将低精度计算造成的损失理解为另一种噪声。
同时,由于训练好的神经网络的权重分布是正态分布的,大多集中于均值附近,所以损失权重的一些边缘值不会影响权重分布的漂移。
动态对称量化算法

动态非对称量化算法
该
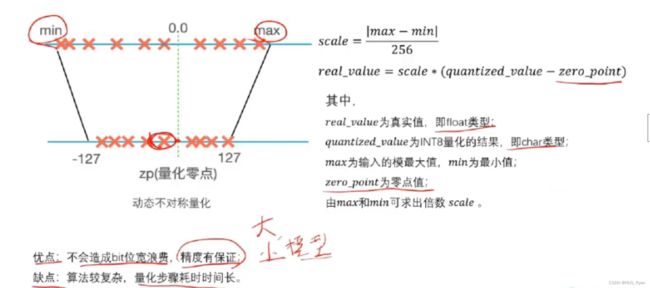 在并行运算环境下,该算法的实现非常复杂,如下图所示:
在并行运算环境下,该算法的实现非常复杂,如下图所示:

静态对称量化算法
静态对称量化算法的优点是算法简单,量化耗时较短,且精度也有所保证,缺点是构建量化网络比较麻烦

假设我们有一个预训练的简单卷积神经网络,包括一个卷积层、ReLU激活函数和一个全连接层。我们将使用TensorRT对这个网络进行INT8量化。
准备数据:为了进行量化,我们需要准备一组表示神经网络输入分布的校准数据。这些数据可以是训练数据集的一个子集或验证数据集。
创建校准表:创建一个继承自nvinfer1::IInt8EntropyCalibrator2的类。在这个类中,我们需要实现getBatch()、readCalibrationCache()和writeCalibrationCache()三个方法。getBatch()用于从校准数据集中获取一个批次的数据,readCalibrationCache()和writeCalibrationCache()分别用于从文件中读取和写入校准缓存。
创建TensorRT网络:加载预训练模型并创建一个对应的TensorRT网络。设置BuilderFlag::kINT8标志以启用INT8量化。
创建校准器:实例化我们在第2步创建的校准器类,并将其传递给TensorRT的IBuilder。在网络构建过程中,TensorRT将使用校准器来计算权重和激活值的缩放因子。
构建引擎:调用IBuilder::buildEngineWithConfig()构建量化后的神经网络引擎。TensorRT会将网络中的权重和激活值转换为INT8,并计算相应的缩放因子。
推理:使用构建好的量化引擎执行推理。输入数据需要根据计算出的缩放因子进行量化,输出数据需要根据缩放因子进行反量化。
#include 上述代码中最为核心的就是两句话:
1.config->setFlag(nvinfer1::BuilderFlag::kINT8);
2.config->setInt8Calibrator(&calibrator);
IInt8Calibrator主要负责输送Calibrator的数据:

进阶讨论:INT8量化算法的实际收益
在实际生产环境中,我们计FP32的运算时间为Tfp,INT8的运算时间为Tint8,量化和反量化的运算时间分别为Ta和Tb,则INT8量化算法带来的时间收益为:Tfp - Tint8 - Ta -Tb. 根据经验,权值越大,输入越小,加速比越大;输入越大,收益越小;甚至是负收益。
进阶讨论:如何使用TensorRT进行大规模上线
一种有效的方法是面向多种输入尺度的多Engine定制策略,具体如下:
- 面向Dynamic Shape输入:
在实际应用中,输入数据的形状可能是可变的。例如,图像分类和目标检测任务中的输入图像可能有不同的分辨率。为了处理可变形状的输入数据,TensorRT引入了Dynamic Shape输入的支持。Dynamic Shape允许用户为某些维度指定最小值、最大值和最优值,从而为不同形状的输入数据生成一个统一的引擎。
要实现Dynamic Shape输入,需要执行以下操作:
在创建TensorRT网络时,使用nvinfer1::INetworkDefinition::addInput()为输入张量指定最小值、最大值和最优值。
在创建nvinfer1::IBuilderConfig对象时,启用nvinfer1::BuilderFlag::kOPT_DYNAMIC_BATCH和/或nvinfer1::BuilderFlag::kOPT_DYNAMIC_SHAPE标志。
在执行推理时,使用nvinfer1::IExecutionContext::setBindingDimensions()为引擎指定当前的输入数据形状。
多Engine定制策略:
尽管Dynamic Shape输入可以处理可变形状的输入数据,但在某些情况下,为不同输入形状创建专门的引擎可能会带来更高的性能。多Engine定制策略允许为特定的输入形状创建专门优化的引擎,从而在推理时获得更高的性能。
- 多Engine定制策略的实现方法如下:
根据不同的输入形状,为每个输入形状创建一个单独的TensorRT引擎。在创建引擎时,使用nvinfer1::IBuilder::setMaxBatchSize()和nvinfer1::IBuilder::setOptimizationProfile()为引擎指定特定的输入形状。
在执行推理时,根据输入数据的实际形状选择合适的引擎。可以使用哈希表或其他数据结构来存储和查找不同输入形状对应的引擎。
总之,在大规模模型上线时,TensorRT提供了面向Dynamic Shape输入和多Engine定制策略等优化方法,以确保高效、灵活的推理。实际应用中,可以根据具体需求和性能要求选择合适的策略。
总结和建议
(1)对于深度神经网络的推理,TRT可以充分发挥GPU计算潜力,以及节省GPU存储单元空间。
(2)对于初学者,建议先从Sample入手,尝试替换掉已有模型,再深入利用网络定义API尝试搭建
网络。
(3)如果需要使用自定义组件,建议至少先了解CUDA基本架构以及常用属性。
(4)推荐使用FP16/INT8计算模式
• FP16只需定义很少变量,明显能提高速度,精度影响不大;
• Int8有更多的潜力,但是可能会导致精度下降。
(5)如果不是非常了解TRT,也可以尝试使用集成了TRT的框架,但是如果不支持的网络层太多,
会导致速度下降明显。
(6)在不同架构的GPU或者不同的软件版本的设备上,引擎不能通用,要重新生成一个。