lightGBM的介绍
一、lightGBM的介绍
1.lightGBM的演进过程

2.AdaBoost算法
AdaBoost(Adaptive Boosting)是一种集成学习算法,通过组合多个弱分类器来构建一个强分类器。它是由Freund和Schapire在1996年提出的,是集成学习中最早被广泛应用的算法之一。
AdaBoost的两个问题:
- 如何改变训练数据的权重或概率分布
- 提高前一轮被弱分类器错误分类的样本的权重,降低前一轮被分对的权重。
- 如何将弱分类器组合成一个强分类器,亦即,每个分类器,前面的权重如何设置
- 采取“多数表决”的方法。加大分类错误率小的弱分类器的权重,使其作用较大,而减小分类错误率大的弱分类器的权重,使其在表决中起作用小一点。
3.GBDT算法以及优缺点
GBDT和AdaBoost很类似,但又有所不同。
-
GBDT和其他Boosting算法一样,通过将表现一般的几个模型(通常是深度固定的决策树)组合在一起来集成一个表现较好的模型。
-
AdaBoost是通过提升错分数据点的权重来定位模型的不足,Gradien Boosting 通过负梯度来识别问题,通过计算负梯度来改进模型,即通过反复地选择一个指向负梯度方向的函数,该算法可以看作在函数空间里对目标函数进行优化。
GBDT的缺点:
GBDT–>预排序方法(pre-sorted)
- 空间消耗大
- 这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。
- 时间上也有很大的开销
- 在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
- 对内存(cache)优化不友好
- 在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征方法访问的顺序不一样,无法对cache进行优化
- 同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的内存损失(cache miss)
4.什么是lightGBM?
LightGBM(Light Gradient Boosting Machine)是一种基于梯度提升树(Gradient Boosting Decision Tree)的机器学习算法,它是由微软公司开发的一种高效、快速的梯度提升框架。
与传统的梯度提升树算法相比,LightGBM 在训练和预测的速度上具有较大的优势。这主要得益于以下几个方面的改进:
- 基于直方图的决策树算法:LightGBM 使用了基于直方图的决策树算法,将连续特征离散化成离散的直方图特征,从而减少了数据的存储空间和计算复杂度。这种离散化方法可以降低特征处理的复杂性,并且能够更好地处理高维稀疏数据。
- 垂直并行化训练算法:LightGBM 使用了一种称为 GOSS(Gradient-based One-Side Sampling)的采样方法和 EFB(Exclusive Feature Bundling)的特征捆绑方法,使得模型在训练过程中可以进行高效的垂直并行化计算。这样可以加快模型的训练速度,并且在处理大规模数据集时尤为有效。
- Leaf-wise生长策略:传统的梯度提升树算法是按层生长的,而 LightGBM 使用了一种称为 Leaf-wise 的生长策略。Leaf-wise 生长策略每次选择当前最优的叶子节点进行分裂,这样可以更快地找到损失函数减小最快的方向,从而加快了模型的训练速度。
- 内存优化:LightGBM 使用了特殊的数据结构和压缩技术,减少了内存的使用。它采用了按列存储的方式,可以减少内存访问的次数,提高数据读取的效率。此外,LightGBM 还支持将数据集加载到内存中的子样本中进行训练,以减少内存的占用。
总之,LightGBM 是一种高效、快速、可扩展的梯度提升树框架,适用于处理大规模数据集和高维稀疏数据。它在许多机器学习任务中表现出色,包括分类、回归、排序、推荐等。
5.lightGBM的优缺点
lightGBM是一种梯度提升决策树(Gradient Boosting Decision Tree)算法的改进版,具有以下优点和缺点:
优点:
- 高效性:lightGBM采用了基于直方图的决策树算法和leaf-wise生长策略,在训练速度上比传统的梯度提升算法(如XGBoost)更快。它通过对特征值进行离散化处理,减少了算法中的计算量。
- 低内存占用:lightGBM使用了特征压缩技术和直方图算法,可以减少内存的占用,尤其适用于处理高维稀疏数据。
- 高准确性:lightGBM在处理大规模数据集时,能够更准确地捕捉特征之间的细微差异和复杂的模式,从而提高了模型的预测性能。
- 可扩展性:lightGBM支持并行化训练和多线程处理,可以有效利用多核CPU的计算资源,加快训练速度。
- 可定制性:lightGBM提供了丰富的超参数调节选项和灵活的模型配置,使用户能够根据具体需求进行定制和优化。
缺点:
- 对噪声敏感:由于lightGBM使用了leaf-wise生长策略,它对噪声和异常值比传统算法更敏感,可能会导致过拟合的风险增加。
- 需要调参:虽然lightGBM提供了丰富的超参数选项,但是选择合适的超参数需要一定的经验和调参工作,这对于新手来说可能会有一定的挑战。
- 数据依赖性:lightGBM的性能在很大程度上依赖于数据的特征和分布情况。对于某些特定类型的数据集,可能不一定比传统算法表现更好。
总体来说,lightGBM是一种高效、准确且可扩展的机器学习算法,特别适用于处理大规模、高维稀疏数据集。它在处理效率和预测性能上具有优势,但在对噪声敏感和超参数调节上需要注意。
二、lightGBM的算法原理介绍
1.lightGBM的算法原理
LightGBM(Light Gradient Boosting Machine)是一种基于梯度提升树(Gradient Boosting Decision Tree)的机器学习算法。它的算法原理如下:
- 梯度提升树(Gradient Boosting Decision Tree):
- 梯度提升树是一种集成学习方法,通过将多个决策树集成起来进行预测。
- 每个决策树都是在前一棵决策树的残差基础上进行训练,逐步减小残差,从而逐步改进预测结果。
- 梯度提升树使用梯度下降的思想,通过最小化损失函数的负梯度来训练每棵树。
- LightGBM的优化:
- 基于直方图的决策树算法:LightGBM采用了基于直方图的决策树算法,将连续特征离散化成离散的直方图特征,从而降低了计算复杂度。
- lightGBM的直方图做差加速:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟节点的直方图做差得到。利用这个方法,lightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟的直方图,在速度上可以提升一倍。
- Leaf-wise生长策略:LightGBM采用了一种称为 Leaf-wise 的生长策略,每次选择当前最优的叶子节点进行分裂,加快了模型的训练速度。
- 直接支持类别特征:lightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1转化。并在决策树算法上增加了类别特征的决策规则。lightGBM是第一个直接支持类别特征的GBDT工具。
- 直接支持高效并行:ightGBM还具有支持高效并行的优点。lightGBM原生支持并行学习,目前支持特征并行和数据并行两种。
- 垂直并行化训练算法:LightGBM使用了一种称为 GOSS(Gradient-based One-Side Sampling)的采样方法和 EFB(Exclusive Feature Bundling)的特征捆绑方法,使得模型在训练过程中可以进行高效的垂直并行化计算。
- 损失函数的优化:
- LightGBM通过优化损失函数来使预测值与实际值之间的误差最小化。
- LightGBM的损失函数可以根据任务类型进行选择,例如回归任务可以使用平方误差损失函数(MSE),分类任务可以使用对数损失函数(Log Loss)等。
- LightGBM使用梯度下降的方法来最小化损失函数,每次迭代时计算负梯度并更新模型参数。
2.基于直方图的决策树算法
直方图算法的基本思想:
- 先把连续的浮点特征值离散化成 k 个整数,同时构造一个宽度为 k 的直方图。
- 在遍历数据的时候,根据离散化后的值作为索引在直方图中累计统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
举例:
有一些 (0, 0.3) 的连续浮点数据,将这些数据离散化成两个整数0和1,(0, 0.1)的数据离散化成0,(0.1, 0.3)的数据离散化成1.

使用直方图算法有很多优点。首先,最明显的就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果。而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了内存消耗可以降低为原来的1/8。

然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算 k 次,时间复杂度大大降低了。
不过直方图算法也是存在缺点的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但决策树本就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树地训练误差比精确分割的算法稍大,但在梯度提升的框架下没有太大的影响。
3.lightGBM的直方图做差加速
一个叶子的直方图可以由它的父亲节点的直方图与它兄弟节点的直方图做差得到。
通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需要遍历直方图的 k 个桶。
利用这个方法,lightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟的直方图,在速度上可以提升一倍。

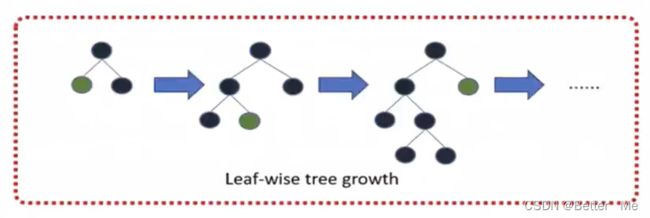
4.带深度限制的leaf-wise的叶子生长策略
Level-wise遍历一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。
- 但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。

Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。
- 因为同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。
- Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此lightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
5.直接支持类别特征
大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的0/1特征,降低了空间和时间的效率。
而类别特征的使用是在实践中很常用的。基于这个考虑,lightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1转化。并在决策树算法上增加了类别特征的决策规则。
lightGBM是第一个直接支持类别特征的GBDT工具。
6.直接支持高效并行
lightGBM还具有支持高效并行的优点。lightGBM原生支持并行学习,目前支持特征并行和数据并行两种。
- 特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
- 数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
lightGBM针对这两种并行方法都做了优化:
-
在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信:

-
在数据并行中使用分散规约(Reduce scatter)把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减小了一半的通信量。

-
**基于投票的数据并行(Voting Parallelization)**则进一步优化数据并行中的通信代价,使通信代价变为常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。

7.GOSS(Gradient-based One-Side Sampling)的采样方法
GOSS(Gradient-based One-Side Sampling)是LightGBM中一种用于样本采样的方法,用于提高梯度提升树的训练效率和模型性能。GOSS的采样方法主要基于梯度的大小来选择样本。
GOSS采样方法的步骤如下:
- 计算样本的梯度:
- 首先,使用当前模型的参数计算每个样本的梯度值。
- 选择重要样本:
- 对于梯度较大的样本,保留它们的全部样本。
- 对于梯度较小的样本,进行采样,只保留其中一部分样本。
- 保留梯度较大的样本:
- GOSS会保留一定比例的梯度较大的样本,这些样本对于模型的训练具有较大的贡献。
- 采样梯度较小的样本:
- GOSS会对梯度较小的样本进行采样,以减少样本数量,减轻计算负担。
- 采样方法通常是基于梯度的大小进行选择,梯度越小的样本被采样的概率越大。
GOSS采样方法的优势在于保留了梯度较大的重要样本,同时通过采样梯度较小的样本来减少样本数量,从而减少计算开销。这种样本选择策略可以加快模型的训练速度,并且在某些情况下可以提高模型的泛化性能。通过GOSS采样方法,LightGBM可以更高效地训练梯度提升树模型,并在大规模数据集和高维稀疏数据上取得良好的性能。
8.EFB(Exclusive Feature Bundling)的特征捆绑方法
Exclusive Feature Bundling(EFB)是LightGBM中一种特征捆绑方法,用于处理高维稀疏数据的特征选择和编码。EFB通过将稀疏特征进行捆绑,将多个特征合并为一个特征,从而减少模型的复杂度和计算开销。
EFB的特征捆绑方法包括以下步骤:
- 特征排序:
- 首先,根据特征的重要性或其他指标对所有特征进行排序。
- 特征分组:
- 将排在前面的特征作为初始捆绑特征组。
- 对于每个特征,计算其与捆绑特征组的相关性,选择相关性较高的特征加入到捆绑特征组中。
- 通过设置阈值或其他策略,控制特征的相关性程度,以控制捆绑特征组的大小和数量。
- 特征编码:
- 对于每个捆绑特征组,可以选择一种编码方式来表示该组内的特征。
- 常见的编码方式包括One-Hot编码、二进制编码等。
- 模型训练:
- 使用捆绑后的特征进行模型训练。
- 捆绑后的特征可以减少特征的维度,降低模型的复杂度,并且可能提高模型的泛化性能。
EFB的特征捆绑方法可以有效地处理高维稀疏数据,减少特征的数量和维度,提高模型训练的效率和性能。通过合并相关的特征,EFB可以更好地利用特征之间的信息,并且减少了稀疏特征的维度灾难问题。在LightGBM中,EFB可以作为一种特征预处理方法,在特征工程阶段对高维稀疏数据进行处理,从而改善模型的训练和预测效果。
三、lightGBM算法的API介绍
1.lightGBM的安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lightgbm
2.lightGBM参数介绍
Control Parameters
| Control Parameters | 含义 | 用法 |
|---|---|---|
| max_depth | 树的最大深度 | 当模型过拟合时,可以考虑首先降低max_depth |
| min_data_in_leaf | 叶子可能具有的最小记录数 | 默认值为20,过拟合时使用该参数 |
| feature_fraction | 例如为0.8时,意味着在每次迭代中随机选择80%的参数来建树 | boosting 为 random forest 时用 |
| bagging_fraction | 每次迭代时用的数据比例 | 用于加快训练速度和减小过拟合 |
| early_stopping_round | 如果一次验证数据的一个度量在最近的 early_stopping_round 回合中没有提高,模型将停止训练 | 加速分析,减少过多迭代 |
| lambda | 指定正则化 | 0~1 |
| min_gain_to_split | 描述分裂的最小 gain | 控制树的有用的分裂 |
| max_cat_group | 在 group 边界上找到分割点 | 当类别数量很多时,找分割点很容易过拟合 |
| n_estimators | 最大迭代次数 | 最大迭代次数不必设置过大,可以在进行一次迭代后,根据最佳迭代数设置 |
Core Parameters
| Core Parameters | 含义 | 用法 |
|---|---|---|
| Task | 数据的用途 | 选择 train 或者 predict |
| application | 模型的用途 | 选择 regression:回归时 选择 binary:二分类时 选择 multiclass:多分类时 |
| boosting | 要用的算法 | gbdt rf:random forest dart:Dropouts meet Multiple Additive Regression Trees goss:Gradient-based One-Side Sampling |
| num_boost_round | 迭代次数 | 通常100+ |
| learning_rate | 学习率 | 常用0.1,0.001,0.003… |
| num_leaves | 叶子数量 | 默认31 |
| device | cpu 或者 gpu | |
| metric | 模型评估的方法 | mae:平均绝对误差 mse:均方误差 binary_logloss:二元对数损失 multi_logloss:多类对数损失 |
IO Parameters
| IO Parameters | 含义 |
|---|---|
| max_bin | 表示 feature 将存入的 bin 的最大数量 |
| categorical_feature | 如果 categorical_feature = 0,1,2,则列0,1,2是 categorical 变量 |
| ignore_column | 与 categorical_feature 类似,只不过不是将特定的列视为 categorical,而是完全忽略 |
| save_binary | 这个参数为 true 时,则数据集被保存为二进制文件,下次读数据时速度会更快 |
3.调参建议
| IO Parameters | 含义 |
|---|---|
| num_leaves | 取值应<=2^(max_depth)超过此值会过拟合 |
| min_data_in_leaf | 将它设置为较大的值而以避免生长太深的树,但可能会导致欠拟合,在大型数据集中就设置为数百或者数千 |
| max_depth | 用来限制树的深度 |
下表对应了 Fasted Speed ,better accuracy ,over-fitting 三种目的时,可以调的参数
| Fasted Speed | better accuracy | 防止over-fitting |
|---|---|---|
| 将 max_bin 设置小一些 | 用较大的 max_bin | max_bin 小一些 |
| num_leaves 大一些 | num_leaves 小一些 | |
| 用 feature_fraction 来做 sub-sampling | 用 feature_fraction | |
| 用 bagging_fraction 和 bagging_freq | 设定 bagging_fraction 和 bagging_freq | |
| training data 多一些 | training data 多一些 | |
| 用 sava_binary 来加速数据加载 | 直接用 categorical feature | 用 gmin_data_in_leaf 和 min_sum_hessian_in_leaf |
| 用 parallel learning | 用 dart | 用 lambda_l1 , lambda_l2 , min_gain_to_split 做正则化 |
| num_iterations 大一些,learning_rate 小一些 | 用 max_depth 控制树的深度 |
四、lightGBM简单案例
通过鸢尾花数据集知道lightGBM算法对应API的使用
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
# 读取鸢尾花数据集
iris = load_iris()
# 确定特征值和目标值
data = iris.data
target = iris.target
# 划分数据集,训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data,target,test_size=0.2,random_state=20)
# 进行简单的模型训练
# 实例化GBM的模型,学习率为0.05,迭代次数为20次
model = lgb.LGBMRegressor(objective="regression",learning_rate=0.05,n_estimators=20,num_leaves=31)
# 进行模型训练,eval_set指的是进行测试的数据集,eval_metric指的是进行检测时用什么正则化,early_stopping_rounds指的是在验证数据的一个度量连着上涨4次则停止模型训练
model.fit(X_train,y_train,eval_metric="l1",eval_set=[(X_test,y_test)],early_stopping_rounds=4)
model.score(X_test,y_test)
# 通过网格搜索确定最佳的参数并进行模型训练
estimator = lgb.LGBMRegressor(num_leaves=31)
param_grid = {
"learning_rate":[0.1,0.01,0.001,1],
"n_estimators":[20,50,80,110]
}
# 进行网格搜素
gbm = GridSearchCV(estimator,param_grid,cv=5)
gbm.fit(X_test,y_test)
# 读取最佳的参数
gbm.best_params_
# 以最佳的参数建立lgb模型,并进行结果预测
lgb_model = lgb.LGBMRegressor(num_leaves=31,learning_rate=0.1,n_estimators=20)
lgb_model.fit(X_train,y_train,eval_metric="l1",eval_set=[(X_test,y_test)],early_stopping_rounds=4)
lgb_model.score(X_test,y_test)