Storm超实用教程详解-附示例
一、理论基础
Storm 是一个免费并开源的分布式实时计算系统。利用 Storm 可以很容易做到可靠地处理无限的 数据流,像 Hadoop 批量处理大数据一样,Storm 可以实时处理数据。在Storm中,topology的构建是一个有向无环图。结点就是Spout或者Bolt,而边就是Spout和Bolt之间或者是Bolt和Bolt之间连接关系。它的一些基本概念如下:在传统的master/slave架构中,都是master节点负责任务的接受、分配、监控等管理任务,从节点负责任务的执行。

Spout发送单元,流的源头
它有两种实现方式BaseRichSpout和IRichSpout,建议实现前一种。通常Spout从外部数据源,如消息队列中读取元组数据并吐到拓扑里。Spout可以是可靠的(reliable)或者不可靠(unreliable)的。通过配置config的acker为0或emit方法不带msgId来实现,默认acker值为1。
Spout可以一次给多个流吐数据。此时需要通过OutputFieldsDeclarer的declareStream函数来声明多个流并在调用SpoutOutputCollector提供的emit方法时指定元组吐给哪个流。Storm框架会不断调用它去做元组的轮询。如果没有新的元组过来,就直接返回,否则把新元组吐到拓扑里。nextTuple必须是非阻塞的,因为Storm在同一个线程里执行Spout的函数。
Tuple:发送的数据流
是一个轻量级的数据格式,支持基本的类型,如果想实现自定义的类型,需要实现自己的序列化方式。在同一个流中,Tuple的数据格式应该都是一样的。不同流中的数据格式可能相同,也可能不同。这个对象必须是可序列化的。
Streams:核心抽象&&Stream Grouping:流分组
一个流由无限的元组序列组成,这些元组会被分布式并行地创建和处理。通过流中元组包含的字段名称来定义这个流。每个流声明时都被赋予了一个ID
- OutputFieldsDeclarer: 用来声明流和流的定义
- Serialization: Storm元组的动态类型转化,声明自定义的序列化方式
- ISerialization: 自定义的序列化必须实现这个接口
- CONFIG.TOPOLOGY_SERIALIZATIONS: 可以通过这个配置来注册自定义的序列化接口
Storm 中最重要的抽象,应该就是 Stream grouping 了,它能够控制 Spot/Bolt 对应的 Task 以什么样的方式来分发 Tuple,将 Tuple 发射到目的 Spot/Bolt 对应的 Task.定义拓扑的时候,一部分工作是指定每个Bolt应该消费哪些流。流分组定义了一个流在一个消费它的Bolt内的多个任务(task)之间如何分组。流分组跟计算机网络中的路由功能是类似的,决定了每个元组在拓扑中的处理路线。在Storm中有七个内置的流分组策略,你也可以通过实现CustomStreamGrouping接口来自定义一个流分组策略:
- shuffleGrouping:随机分配,元组到Bolt的某个任务上,这样保证同一个Bolt的每个任务都能够得到相同数量的元组。
- fieldsGrouping:字段分组, 按照指定的分组字段来进行流的分组。例如,流是用字段“user-id"来分组的,那有着相同“user-id"的元组就会分到同一个任务里,但是有不同“user-id"的元组就会分到不同的任务里。通过这种流分组方式,我们就可以做到让Storm产出的消息在这个"user-id"级别是严格有序的,这对一些对时序敏感的应用(例如,计费系统)是非常重要的。
- Partial Key grouping: 跟字段分组一样,流也是用指定的分组字段进行分组的,但是在多个下游Bolt之间是有负载均衡的,这样当输入数据有倾斜时可以更好的利用资源。
- allGrouping:广播发送,流会复制给Bolt的所有任务。小心使用这种分组方式。在拓扑中,如果希望某类元祖发送到所有的下游消费者,就可以使用这种All grouping的流分组策略。
- globalGrouping: 整个流会分配给Bolt的一个任务。具体一点,会分配给有最小ID的任务。全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
- Direct grouping:一种特殊的分组。对于这样分组的流,元组的生产者决定消费者的哪个任务会接收处理这个元组。只能在声明做直连的流(direct streams)上声明Direct groupings分组方式。只能通过使用emitDirect系列函数来吐元组给直连流。一个Bolt可以通过提供的TopologyContext来获得消费者的任务ID,也可以通过OutputCollector对象的emit函数(会返回元组被发送到的任务的ID)来跟踪消费者的任务ID。在ack的实现中,Spout有两个直连输入流,ack和ackFail,使用了这种直连分组的方式。
- Local or shuffle grouping:如果目标Bolt在同一个worker进程里有一个或多个任务,元组就会通过洗牌的方式分配到这些同一个进程内的任务里。否则,就跟普通的洗牌分组一样。这种方式的好处是可以提高拓扑的处理效率,因为worker内部通信就是进程内部通信了,相比拓扑间的进程间通信要高效的多。worker进程间通信是通过使用Netty来进行网络通信的。
- TopologyBuilder: 使用这个类来定义拓扑
- InputDeclarer: 当调用TopologyBuilder的setBolt函数时会返回这个对象,它用来声明一个Bolt的输入流并指定流的分组方式
- CoordinatedBolt: 这个Bolt对于分布式的RPC拓扑很有用,大量使用了直连流(direct streams)和直连分组(direct groupings)
Bolt:流水线上的处理单元
把数据的计算处理过程合理的拆分到多个Bolt、合理设置Bolt的task数量,能够提高Bolt的处理能力,提升流水线的并发度。它也有两种实现方式BaseRichBolt和IRichBolt,建议实现前一种。
Bolt可以给多个流吐出元组数据。此时需要使用OutputFieldsDeclarer的declareStream方法来声明多个流并在使用[OutputColletor]的emit方法时指定给哪个流吐数据。当你声明了一个Bolt的输入流,也就订阅了另外一个组件的某个特定的输出流。如果希望订阅另一个组件的所有流,需要单独挨个订阅。InputDeclarer有语法糖来订阅ID为默认值的流。例如declarer.shuffleGrouping("redBolt")订阅了redBolt组件上的默认流,跟declarer.shuffleGrouping("redBolt", DEFAULT_STREAM_ID)是相同的。
必须注意OutputCollector不是线程安全的,所以所有的吐数据(emit)、确认(ack)、通知失败(fail)必须发生在同一个线程里。
- IRichBolt: 这是Bolt的通用接口
- IBasicBolt: 很方便的Bolt接口,用于定义做过滤或者简单处理的Bolt
- OutputCollector: Bolt通过这个类的实例来吐元组给输出流
Topology
把spout和bolt连接起来,构建一张有向无图topy图,拓扑会一直运行下去直到被kill掉。一个拓扑就是一个复杂的多阶段的流计算。worker、executor、task的关系
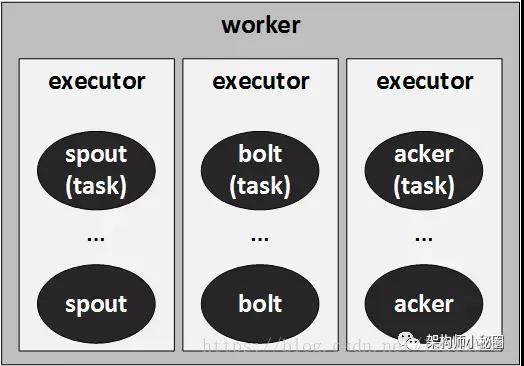
- worker是一个进程.1 个 worker 进程执行的是 1 个 topology 的子集(注:不会出现 1 个 worker 为多个 topology 服务)。1 个 worker 进程会启动 1 个或多个 executor 线程来执行 1 个 topology 的 component(spout 或 bolt)。因此,1 个运行中的 topology 就是由集群中多台物理机上的多个 worker 进程组成的。
- executor是一个线程,是运行tasks的物理容器.executor 是 1 个被 worker 进程启动的单独线程。每个 executor 只会运行 1 个 topology 的 1 个 component(spout 或 bolt)的 task(注:task 可以是 1 个或多个,storm 默认是 1 个 component 只生成 1 个 task,executor 线程里会在每次循环里顺序调用所有 task 实例)。
- task是对spout/bolt/acker等任务的逻辑抽象.是最终运行 spout 或 bolt 中代码的单元(注:1 个 task 即为 spout 或 bolt 的 1 个实例, executor 线程在执行期间会调用该 task 的 nextTuple 或 execute 方法)。topology 启动后,1 个 component(spout 或 bolt)的 task 数目是固定不变的,但该 component 使用的 executor 线 程数可以动态调整(例如:1 个 executor 线程可以执行该 component 的 1 个或多个 task 实 例)。这意味着,对于 1 个 component 存在这样的条件:#threads<=#tasks(即:线程数小于 等于 task 数目)。默认情况下 task 的数目等于 executor 线程数目,即 1 个 executor 线程只运 行 1 个 task。
二、常见配置
有很多topology级的配置可以设。 以”TOPOLOGY”打头的配置是topology级别的配置,可以覆盖全局级别的配置。下面是一些比较常见的:
1)Config.TOPOLOGY_WORKER设置: 这个设置用多少个工作进程来执行这个topology。比如,如果你把它设置成25, 那么集群里面一共会有25个java进程来执行这个topology的所有task。如果你的这个topology里面所有组件加起来一共有150的并行 度,那么每个进程里面会有6个线程(150 / 25 = 6)。
2)Config.TOPOLOGY_ACKERS: 这个配置设置acker线程的数目。Ackers是Storm的可靠性API的一部分。
3)Config.TOPOLOGY_MAX_SPOUT_PENDING: 这个设置一个spout task上面最多有多少个没有处理的tuple(没有ack/failed)回复, 我们推荐你设置这个配置,以防止tuple队列爆掉。
4)Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS: 这个配置storm的tuple的超时时间 – 超过这个时间的tuple被认为处理失败了。这个设置的默认设置是30秒,对于大多数的topology都已经足够了。
5)Config.TOPOLOGY_SERIALIZATIONS: 为了在你的tuple里面使用自定义类型,你可以用这个配置注册自定义serializer。
三、示例程序
示例1:BaseRichSpout
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.ConcurrentHashMap;
public class SentenceSpout extends BaseRichSpout {
private static final long serialVersionUID = 4608825077450573093L;
private ConcurrentHashMap pending;
private SpoutOutputCollector collector;
private String[] sentences = {
"connecting the dots",
"love and loss",
"keep looking",
"do not settle",
"stay hungry",
"stay foolish"
};
private int index;
/**
* Spout的构造函数,类初始化时被调用,一般会把读取数据源的操作放在此方法里。里面接收了三个参数,
* 第一个是创建Topology时的配置,
* 第二个是所有的Topology数据,可以设置一些变量
* 第三个是用来把Spout的数据发射给bolt,发布交给bolts处理的数据
* **/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.index = 0;
this.collector = collector;
//要处理的数据
this.pending = new ConcurrentHashMap();
}
/**
* 声明输出元组的字段信息
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
/**
* 这是Spout最主要的方法,在这里我们读取文本文件,并把它的每一行发射出去(给bolt)
* 这个方法会不断被调用,死循环。为了降低它对CPU的消耗,当任务完成时让它sleep一下
* /
@Override
public void nextTuple() {
Values value = new Values(sentences[index]);
UUID msgId = UUID.randomUUID();
this.pending.put(msgId, value);
//每行发布一个Tuple,后面必须带个消息ID,如果不带msgID则下游Blot处理失败时就不会调用ack方法
this.collector.emit(value,msgId);
index++;
if(index >= sentences.length){
index = 0;
}
// 休眠0.1毫秒
Utils.sleep(100);
}
/**
* 元组被正常处理后的操作
*/
@Override
public void ack(Object msgId){
this.pending.remove(msgId);
}
/**
* 如果元组未被正常处理就重发
*/
@Override
public void fail(Object msgId){
this.collector.emit(this.pending.get(msgId),msgId);
}
} 示例2:BaseRichBolt
/*把句子分割成为单词,然后传递到下游的Bolt*/
public class SplitSentenceBolt extends BaseRichBolt {
private static final long serialVersionUID = 2390867112177953110L;
private OutputCollector collector;
/**
* 在Storm中,这个方法相当于Bolt的构造函数,类初始化时被调用,
* 所以一般会把Bolt初始化操作放在这个方法里
*/
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* 声明输出元组的字段信息,发送给下一个Bolt
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
/**这是bolt中最重要的方法,每当接收到一个tuple时,此方法便被调用
* 这个方法的作用就是把文本文件中的每一行切分成一个个单词,并把这些单词发射出去(给下一个bolt处理)
* **/
@Override
public void execute(Tuple tuple) {
String sentence = tuple.getStringByField("sentence");//值可以按位置或名称读取
String[] words = sentence.split(" ");
for(String word:words){
word = word.trim();
// 将输出的tuple和输入的tuple锚定
this.collector.emit(tuple,new Values(word));
}
// 告诉Spout,这个元组已经被成功处理了
this.collector.ack(tuple);
}
}
--------------------------------------------------------------------------------
/*统计各个单词出现的次数,然后传递给下游的Bolt*/
public class WordCountBolt extends BaseRichBolt {
private static final long serialVersionUID = 360868701353402042L;
private OutputCollector collector;
private HashMap counters;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
counters = new HashMap();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Integer count = counters.get(word);
if(null == count){
count = 0;
}
count++;
this.counters.put(word, count);
// 将输出的tuple和输入的tuple锚定
this.collector.emit(tuple,new Values(word,count));
// 告诉上游Bolt,这个元组已经被成功处理了
this.collector.ack(tuple);
}
}
--------------------------------------------------------------------------------
/*拓扑运行结束时打印单词计数(这里只是演示而这样做的,生成环境中Storm会一直运行下去,除非你主动停止它)*/
public class ReportBolt extends BaseRichBolt {
private static final long serialVersionUID = -1884042962508663765L;
private HashMap counts;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector arg2) {
this.counts = new HashMap();
}
/**
* 这个Bolt什么也不输出
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Integer count = tuple.getIntegerByField("count");
this.counts.put(word, count);
}
/*Topology执行完毕的清理工作,比如关闭连接、释放资源等操作都会写在这里*/
@Override
public void cleanup(){
System.out.println("******count result******");
for (Map.Entry entry : counts.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
} 示例3:Topology
/*Topology中的各结点已经构造完毕,接下来要把它们连接起来,构成一张有向无环图*/
public class WordCountTopology {
private static final String CENTENER_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-toplogy";
public static void main(String[] args){
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(CENTENER_SPOUT_ID, spout);
//下面setBolt方法的并发度全是1,根据情况来设置
// SentenceSpout ---> SplitSentenceBolt。在spout和bolts之间通过shuffleGrouping(随机分配Bolt)方法连接
builder.setBolt(SPLIT_BOLT_ID, splitBolt).shuffleGrouping(CENTENER_SPOUT_ID);
// SplitSentenceBolt ---> WordCountBolt,把相同的单词发给同一个Bolt
builder.setBolt(COUNT_BOLT_ID, countBolt).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
// WordCountBolt ---> ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
Config config = new Config();
/*//在storm中可以用这种方式取出值来
config.put("wordsFile", "d:/text.txt");
config.get("wordsFile");
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
*/
//创建一个本地模式cluster
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
// 休眠10秒
Utils.sleep(10000);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}四、与Kafka集成
public class StormKafkaTopo {
public static void main(String[] args) {
BrokerHosts brokerHosts = new ZkHosts("192.168.1.216:2181/kafka");
SpoutConfig spoutConfig = new SpoutConfig(brokerHosts, "topic1", "/kafka", "kafkaspout");
Config conf = new Config();
Map map = new HashMap();
map.put("metadata.broker.list", "192.168.1.216:9092");
map.put("serializer.class", "kafka.serializer.StringEncoder");
conf.put("kafka.broker.properties", map);32 conf.put("topic", "topic2");
spoutConfig.scheme = new SchemeAsMultiScheme(new MessageScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new KafkaSpout(spoutConfig));
builder.setBolt("bolt", new SenqueceBolt()).shuffleGrouping("spout");
builder.setBolt("kafkabolt", new KafkaBolt()).shuffleGrouping("bolt");
if(args != null && args.length > 0) {
//提交到集群运行
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
} else {
//本地模式运行
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Topotest1121", conf, builder.createTopology());
Utils.sleep(1000000);
cluster.killTopology("Topotest1121");
cluster.shutdown();
}
}
}