Swin Transformer详解
继vit之后,进一步证明了Transformer可以在视觉领域广泛应用,并且可以应用到半监督以及自监督中。
Swin Transformer:Hierarchical Vision Transformer Using Shifted Windows
Swin Transformer:用了移动窗口的层级式的Transformer,Swin来自Shifted Windows。
他可以像CNN一样做到层级式提取,使提取到的特征有多尺度的概念
摘要
Vit出现后虽然让大家看到了Transformer在视觉领域的潜力,但并不确定Transformer可以做掉所有视觉任务。
Swin Transformer可以作为一个通用的骨干网络。
面对的挑战:1、多尺度。 2、高像素。
移动窗口提高效率,并通过Shifted操作变相达到全局建模能力。
层次结构:灵活,可以提供各个尺度特征信息,容易使用到下游任务中。
最后分层设计和移位窗口方法也被证明对所有mlp体系结构都是有益的。
引言

Vit虽然可以全局建模,但单一尺寸和低分辨率减弱了对多尺寸特征的把握,然而对密集预测型任务多尺寸特征非常重要。同时Vit是全局建模,复杂度与图像大小为平方关系。
由此,借鉴CNN的先验知识和设计理念,提出了Swin Transformer。
1、复杂度
在小窗口内计算自注意力从而使复杂度降到线性,这利用了CNN中局部性的先验知识:同一个物体的不同部分和语意相近部分大概率相邻。
2、多尺寸特征
卷积神经网络为什么有多尺度特征?因为池化操作,池化能增大每一个卷积核的感受野。因此这里也提出一个类似池化的patch merging,将相邻的小patch合成大patch,增大感受野和获取多尺寸特征信息。有了这些多尺寸特征图就可以扔给分割,检测,这使它可以作为一个骨干网络。

shift操作
假设窗口大小为M,shift操作就是向右向下分别平移M//2个patch,然后在新的特征图重新进行自注意力,这让相邻窗口有了交互的能力。估计看到这里会一头雾水,先不用搞清,具体原理稍后就说。
先说说为什么会能够具有交互能力,比如第四行第四列的patch,最初只能和最左上角的窗口内的其他patch进行自注意力,但shift之后就可以和第四行第五列的patch,第五行第四列的patch,第五行第五列的patch进行自注意力,而这三个patch分别来自其它三个窗口,这就使得不同窗口间有了交互能力。再加上patch merging就可以做到全局自注意力操作了。
网络结构
整体结构


patch partition
与Vit类似,使用一个卷积核大小为4*4,步长为4,通道数为48的卷积神经网络后维度为(H/4,W/4,48)
linear Embedding
将维度调整到C,并且它还包含一个layer norm
Swin Transformer Block
输入输出维度不变。首先一个Swin Transformer Blocks包含两个block,分别将原有的Multi-head attention(MSA)替换成窗口注意力(Window-MSA)和滑动窗口注意力(Shifted Window-MSA)
Patch Merging
类似于池化,对特征图进行下采样,同时通道数变为2倍,后面细讲。
具体实现
Patch Merging
| 1 | 2 | 1 | 2 |
| 3 | 4 | 3 | 4 |
| 1 | 2 | 1 | 2 |
| 3 | 4 | 3 | 4 |
| 1 | 1 |
| 1 | 1 |
| 2 | 2 |
| 2 | 2 |
| 3 | 3 |
| 3 | 3 |
| 4 | 4 |
| 4 | 4 |
这里的1,2,3,4代表的是序号,也就是说先将序号相同的patch汇聚到一起,这时候有四个(H/2,W/2,C)的张量,再在C的维度依次拼接这四个张量得到(H/2,W/2,4C)的张量,对他在4C维度上进行layer norm。因为卷积神经网络每次下采样后通道数会变成两倍,因此我们通过一个Linear将其维度转变为(H/2,W/2,2C) 。
W-MSA
目的:减少计算量
缺点:窗口之间无法进行信息交互。
做法:只对window之内的patch做self-attention。
以下是复杂度对比,推导见Swin-Transformer网络结构详解_swin transformer_太阳花的小绿豆的博客-CSDN博客
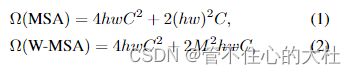
SW-MSA

再来仔细看这幅图:
将窗口向右向下分别平移M//2个patch,这时会出现9个窗口,并且每个窗口内的patch数不一样。
有两种解决方法,一种是对每个窗口进行补0,但这样就从一开始要计算的4个窗口变成了计算9个窗口,计算量大大增加。一种是通过masking方法来减少计算。
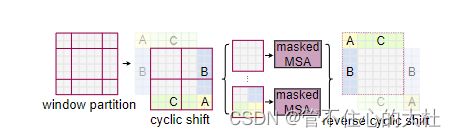
先将AC移到下方,再讲BA移到右方,被移动的和它现在相邻的在原本是没有关系的。比如原来C是天,最下面的是地,现在C被移到最下方,也不能说天在地下面。因此这些原本无关的patch就不能进行自注意力计算,因此我们需要使用masking。
现在我们已经得到了4*4的window,怎么进行mask呢?(如果看不懂强烈建议去学习朱导的精读,时间45:00。)

首先一个窗口有7*7个patch,那么向下向右平移7//2=3个单位。假设各部分按此编号。我们将窗口2展开,各个patch的来源应该是
3,3,3,3,3,3,3,
3,3,3,3,3,3,3,
3,3,3,3,3,3,3,
3,3,3,3,3,3,3,
6,6,6,6,6,6,6,
6,6,6,6,6,6,6,
6,6,6,6,6,6,6,
前28个来自3,后21个来自6。自注意力后得到

attention矩阵维度是49*49,左上角28*28的块是3号区域内的attention,右下角的21*21是6号区域内的attention,我们需要mask掉3号区域与6号区域的attention就可以。作者提到因为attention都是一个零点几的小数,所以我们直接给要mask掉的地方-100就可以做到softmax后其值为0.
类似的我们看看编号为12的窗口,它展开应该是这样的
1,1,1,1,2,2,2,
1,1,1,1,2,2,2,
1,1,1,1,2,2,2,
1,1,1,1,2,2,2
与刚才的方法类似,于是我们得到各个窗口的mask如下

最终我们还要把刚刚移动的移回去就大功告成。
相对位置偏移
因为本文仅供自己复习用,如果看不懂我写的强烈建议学习12.1 Swin-Transformer网络结构详解_哔哩哔哩_bilibili
时间37:00
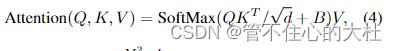
这里的B就是相对位置偏移 。首先,在Swin Transformer中使用绝对位置编码表现并不好,其次相对位置编码表现得很好,因此我们用相对位置编码。。。
1、相对位置索引
假如特征图如下
| a | b |
| c | d |
这时候a,b,c,d的绝对位置索引是
| 0,0 | 0,1 |
| 1,0 | 1,1 |
a,b,c,d与其他的相对位置矩阵分别为(自己的索引减去别人的索引)
| 0,0 | 0,-1 |
| -1,0 | -1,-1 |
| 0,1 | 0,0 |
| -1,1 | -1,0 |
| 1,0 | 1,-1 |
| 0,0 | 0,-1 |
| 1,1 | 1,0 |
| 0,1 | 0,0 |
将四个矩阵展平,拼接
| 0,0 | 0,-1 | -1,0 | -1,-1 |
| 0,1 | 0,0 | -1,1 | -1,0 |
| 1,0 | 1,-1 | 0,0 | 0,-1 |
| 1,1 | 1,0 | 0,1 | 0,0 |
然后再将二维坐标转换为一维坐标,如果直接将行列坐标相加,会发生之前索引不同而之后索引相同的情况,如(-1,0)和(0,-1)
于是我们先给行和列都加上M-1,在这个例子中M=2。
说白了其实就是消除负数
| 1,1 | 1,0 | 0,1 | 0,0 |
| 1,2 | 1,1 | 0,2 | 0,1 |
| 2,1 | 2,0 | 1,1 | 1,0 |
| 2,2 | 2,1 | 1,2 | 1,1 |
然后我们给行标乘2M-1再和列标相加
| 4 | 3 | 1 | 0 |
| 5 | 4 | 2 | 1 |
| 7 | 6 | 4 | 3 |
| 8 | 7 | 5 | 4 |
通过上述方法我们让刚刚索引相同的值仍然相同,索引不同但行标列标相加后相同的情况索引不再相同,比如刚刚的(0,-1)和(-1,0)
2、相对位置偏置
我们根据相对位置索引去相对位置偏置表中取需要的值,相对位置偏置表的元素个数为(2M-1)*(2M-1),他是一个可学习的参数,相对位置索引是固定的

最终得到相对位置偏置
| 0.1 | 0.8 | 0.2 | 0.1 |
| 0.6 | 0.1 | 0.3 |
0.2 |
| 0.4 | 0.4 | 0.1 | 3 |
| 0.7 | 0.4 | 0.6 | 0.1 |
模型配置参数

消融实验
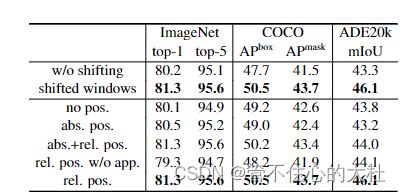
结论
复杂度同图像大小是线性关系。基于移动窗口的自注意力在密集预测型任务中非常有效。
最后,本文章仅供学习