【Redis】主从、哨兵、集群架构
文章目录
- 主从架构
-
- 主从数据同步原理
- 主从集群优化
- 哨兵架构
-
- 服务状态监控
- 故障转移
- 优缺点
- 集群架构
主从架构
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
即一个主节点对外提供服务,其他从节点作为主节点的备份节点,充当一个数据备份的角色。
而如果主节点宕机了,那么运维可以从从节点中选择一台服务器重新变为主节点,并且让其他从节点变为该主节点的从节点。
而那台宕机的服务器即使重启之后也不会再次变为主节点,而是变为当前主节点的从节点。
这种调整可以由第三方软件、lua脚本或者运维人员来执行,当然,依旧比较麻烦,所以目前主要运用的是下面的两种模式。
主从数据同步原理
主从数据同步的实现原理如下:
首先主机与从机之间从机先发送一个请求数据同步的信号,主机收到之后判断是不是他们之间第一次进行数据同步,如果是的话,就同步主从之间的数据版本信息,然后从机保存这个版本信息,之后主机执行bgsave操作生成RDB,主机在RDB期间执行的所有命令会记录到repl_baklog文件中,之后将RDB文件发送给从机,从机收到RDB文件之后会清空本地数据,然后加载主机发送过来的RDB文件。
之后主机再将repl_baklog文件在发送给从机,从机再次执行该访问内的命令,那么此时从机就与主机完成了数据同步。

这里有一个很重要的概念就是master是如何判断slave是不是第一次来同步数据的呢?因此这里会用到两个很重要的概念:
- Replication ld:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,
slave则会继承master节点的replid,因此如果如果从机请求同步数据的时候没有发送replid,则说明从机是第一次向主机请求同步数据。 - offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset,
如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id和offset,master才可以判断到底需要同步哪些数据。
从机第一次向主机请求同步叫做全量同步,而之后的同步叫做增量同步。
增量同步的意思是主从之间需要进行数据同步,而主机的数据总是比从机快,因此主机和从机之间会有数据差,而这一个差距就体现在主机的offset和从机的offset之间的差距。
而他们之间的数据差距类似于一个环,只要master的数据没有覆盖掉slave的数据,那么就可以进行数据同步,但是如果master的数据已经超了slave一圈了,那要拷贝给从机的数据就已经被覆盖了,因此主从同步会失败。这个时候,就要进行全量同步。原因是因为repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,那么就无法基于该文件做增量同步,只能再次执行全量同步。

主从集群优化
可以从以下几个方面来优化Redis主从就集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力

哨兵架构
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。其结构如下:

对于一个小的主从架构,我们可以配置一些Redis实例作为哨兵节点,而这些哨兵节点会对主从节点中的每一个节点进行监听。
此时客户端如果要访问主从节点其实是通过哨兵来访问的,因为哨兵是知道主节点的信息的,所以此时哨兵会告诉客户端主节点的ip端口号等信息,然后客户端再向主节点发送请求。
服务状态监控
而哨兵由于监听了主节点,因此哨兵知道主节点是否宕机。
哨兵Sentinel基于心跳机制监测服务状态,每隔1s向集群的每个实例发送ping命令:
- 主观下线:如果sentinel节点发送某实例未在规定时间内响应,则认为该实例主观下线。
- 客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过sentinel实例数量的一般。
因此一旦发现master(主机)故障,sentinel需要在slave(从机)中选择一个新的master,选择依据如下:
- 首先判断slave节点与master节点断开的时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该节点。
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高
故障转移
当一个slave被选中为新的master后,故障转移步骤如下:
- sentinel给备选的slave节点发送slaveof no one命令,让该节点成为master
- sentinel给所有其它slave发送slave of ip(备选slave的ip) 命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
- 最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点
优缺点
优点在于无需运维人员手动切换主从节点。
在Redis3.0以前的版本要实现集群一般是借助哨兵sentinel根据来监控master节点的状态,如果master节点异常,则会做主从切换,将某一台slave作为master,哨兵的配置略微复杂,并且性能和高可用性等各方面表现一般,特别是在主从切换的瞬间存在访问瞬断的情况,而且哨兵模式只有一个主节点对外提供服务,没法支持很高的并发,且单个节点内存也不宜设置过大,否则会导致持久化文件过大,影响数据恢复或主从复制。
缺点即并发不够,主从切换较慢,容易出现访问瞬断问题。
同时由于所有数据存放在主节点,那么会导致主节点的RDB文件过大,对于数据备份不友好。
集群架构
在Redis3.0之后推出的集群架构,作为对主从和哨兵架构的改进。
主从和哨兵可以解决高可用、高并发读的问题。但是对于海量数据的存储以及高并发写的问题并没有解决。而使用集群架构就可以解决上述问题。
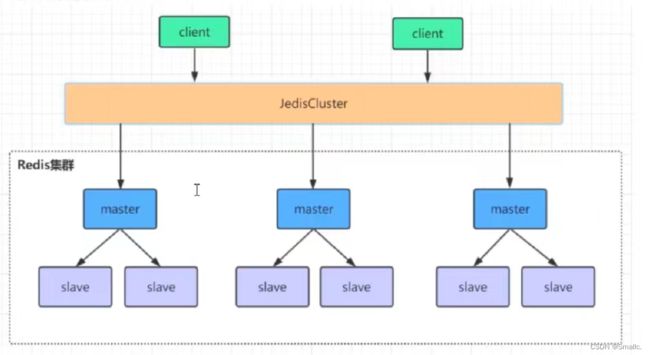
redis集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单。
首先从数据存储方面介绍集群架构。
例如存储10G数据,那么对于哨兵和主从架构,这10G数据需要全部存储在主节点,对于数据备份,数据恢复以及数据插入而言都不太友好。
而集群架构就不会把这10G数据拷贝到每一个主节点上,而是将这个10G数据进行分片存储,也就是所有的主节点合起来能凑出这10G数据,而主节点的从节点则备份其对应主节点的数据。因此如果我们的主从节点个数够多,那么我们就能将这10G数据以非常少的量存储在每一个节点上面,因此无论是高并发,数据备份还是数据恢复数据插入都解决了。
当然集群模式依旧会有瞬断问题,也就是访问数据的主节点挂掉了,虽然集群模式中的主从节点依旧会进行主从替换,但是依旧会产生瞬断问题,只不过访问其他节点上的数据的时候不会出现问题。
一般大型公司会选择使用集群架构,中小型公司使用哨兵或主从架构。