视觉大模型DINOv2:自我监督学习的新领域
如果你对自监督学习感兴趣,可能听说过Facebook人工智能的DINO(无标签知识蒸馏)。我们在以前的文章中也介绍过它。DINOv2不仅是一个新版本而且带来了新的改进,并为判别性自监督学习设定了更高的标准。当然公司的名字也从Facebook变为了Meta。
本文将介绍DINOv2是如何改进的,以及这些进步可能对整个领域有什么影响。

DINO回顾
如果你对DINO不了解,我们首先回顾以下它的信息。它是 Facebook AI 的发布的视觉理解领域自监督学习的解决方案。DINO 架构的核心是不使用标签的知识提炼,distillation with no labels。通俗地说,它训练了一个学生网络来模仿一个更强大的教师网络的行为,所有这些都不需要在训练数据中有明确的标签。
DINO 的底层是 Vision Transformer (ViT) 架构,该设计从自然语言处理 (NLP) 中的转换器模型中汲取灵感,并将其应用于视觉数据。DINO 使用对比学习方法,模型学习从图像检索任务中有用的数据中识别相似和不同的例子。但是DINO 放弃了负采样的通常做法,而是选择了全局自注意力机制。这使它能够捕获更全面的数据视图。
在性能方面,DINO 优于其他自监督学习方法,甚至可以与一些监督方法相媲美。它的多功能性在其成功应用于各种任务中是显而易见的,包括图像分类、对象检测,甚至实例分割。
DINOv2:增强版DINO
DINOv2保留了DINO的好处,并增加了一些增强功能,可以实现更好的性能。下面是一些关键的改进:
FlashAttention机制:这个新的自注意力层,它1提高了内存使用效率和速度,这对于管理大模型至关重要。每个头部维数是64的倍数,整个嵌入维数是256的倍数时,它的效果最好。
Self-Attention 中的嵌套张量:在同一前向传播中运行全局裁剪和局部裁剪(具有不同数量的补丁令牌),可以显着提高计算效率。
Efficient Stochastic Depth:这个版本跳过了残差下降计算,节省了内存和计算能力。
Fully-Shared Data Parallel (FSDP):模型跨 GPU 拆分,模型大小不受单个 GPU 内存的限制,而是受所有计算节点上 GPU 显存的总和限制。
模型蒸馏:对于较小的模型,DINOv2利用最大模型ViT-g的知识蒸馏,而不是从头开始训练,从而提高了性能。这个过程包括将知识从更大、更复杂的模型(教师)转移到更小的模型(学生)。学生模型被训练来模仿教师的输出,从而继承其优越的能力。这个过程提高了小型模型的性能,使它们更有效率。
数据集和训练
论文使用了经过整理和未经整理的数据的12亿张图像,这些数据是由多个高质量来源组成,包括ImageNet-22k、ImageNet-1k的训练分割、Google Landmarks和各种细粒度数据集。这些精心策划的图像提供了广泛的定义良好的视觉数据,有助于模型的学习。
未经整理的数据集来源于公开可用的网络抓取数据。为了保证这些图像的质量和安全,还使用了多种过滤技术,例如PCA删除重复内容,NSFW过滤内容适当性,人脸模糊处理以确保隐私。
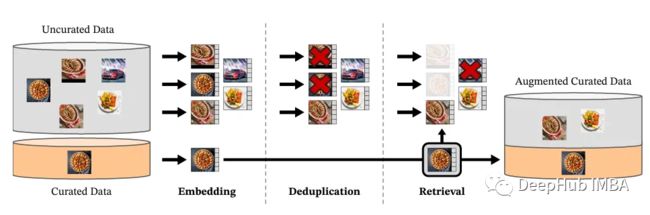
这些图像无论是经过整理的还是未经整理的,都先映射到嵌入中。在与经过整理的图像匹配之前,未整理的图像要经过额外的重复数据删除步骤。
LVD-142M是由1.42亿张图像组成的大型数据集,Meta通过在高性能计算集群上分布执行整理步骤创建了该数据集。该计算集群由20个节点组成,配备8个V100-32GB gpu,创建时间不到2天。也就是说光数据准备就用了8个V100的2天时间。在模型训练方面,使用了A100-40GB的GPU,花了22k GPU小时来训练dinov2g模型。
这对于我们个人研究来说,是不可能复现的,所以我们这里使用它们发布的预训练模型来进行推理和研究:
git clone https://github.com/facebookresearch/dinov2.git
cd dinov2 && pip install -r requirements.txt
我们使用下面这4张图
import os
import torch
import torchvision.transforms as T
import hubconf
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# Load the largest dino model
dino = hubconf.dinov2_vitg14()
dino = dino.cuda()
# Load the images
img_dir = '/path/to/your/image/folder'
image_files = os.listdir(img_dir)
images = []
for image in image_files:
img = Image.open(os.path.join(img_dir, image))
img_array = np.array(img)
images.append(img_array)

让我们看看DINOv2如何寻找这4张图像的相似之处
# Preprocess & convert to tensor
transform = T.Compose([
T.Resize(560, interpolation=T.InterpolationMode.BICUBIC),
T.CenterCrop(560),
T.ToTensor(),
T.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
# Use image tensor to load in a batch of images
batch_size = 4
imgs_tensor = torch.zeros(batch_size, 3, 560, 560)
for i, img in enumerate(images):
imgs_tensor[i] = transform(img)[:3]
# Inference
with torch.no_grad():
features_dict = dino.forward_features(imgs_tensor.cuda())
features = features_dict['x_norm_patchtokens']
print(features.shape)
输出为torch.Size([4, 1600, 1536]),因为ViTg14模型的特征维度是1536。我们使用了4张图像来运行这个推理,如果您的目录中有超过4个图像,则需要相应地调整它。
使用PCA分析:
# Compute PCA between the patches of the image
features = features.reshape(4*1600, 1536)
features = features.cpu()
pca = PCA(n_components=3)
pca.fit(features)
pca_features = pca.transform(features)
# Visualize the first PCA component
for i in range(4):
plt.subplot(1, 4, i+1)
plt.imshow(pca_features[i * 1600: (i+1) * 1600, 0].reshape(40, 40))
plt.show()
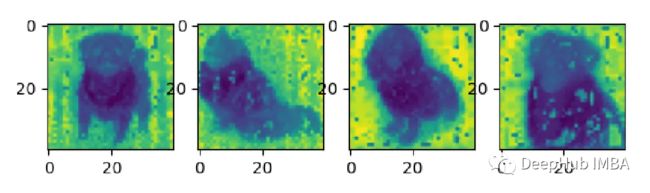
第一个 PCA 分量对应于高维空间中数据变化最大的方向。在像 DINOv2 这样的模型学习的特征的上下文中,这应该是对应于模型已经学会识别的最重要的视觉特征。例如,它可能对应于高级特征(例如某些对象的存在)或低级特征(例如边缘、颜色或纹理)。
我们移除背景并可视化前 PCA 分量,以查看这 4 个图像中的特征如何匹配。
# Remove background
forground = pca_features[:, 0] < 1 #Adjust threshold accordingly
background= ~forground
# Fit PCA
pca.fit(features[forground])
features_forground = pca.transform(features[forground])
# Transform and visualize the first 3 PCA components
for i in range(3):
features_forground[:, i] = (features_forground[:, i] - features_forground[:, i].min()) / (features_forground[:, i].max() - features_forground[:, i].min())
rgb = pca_features.copy()
rgb[background] = 0
rgb[forground] = features_forground
rgb = rgb.reshape(4, 40, 40, 3)
for i in range(4):
plt.subplot(1, 4, i+1)
plt.imshow(rgb[i][..., ::-1])
plt.show()
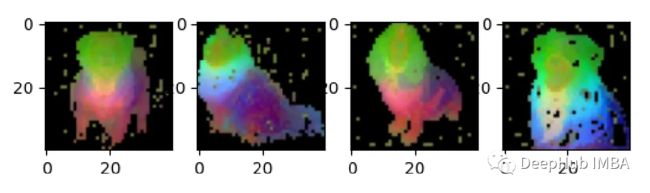
可以看到,尽管类型、姿势和图像风格发生了变化,但狗的相同部位在图像中是匹配的。这种特征提取方法适用于无数的用例,可以为理解和解释复杂的高维数据提供了一个健壮的框架。
DINOv2应用
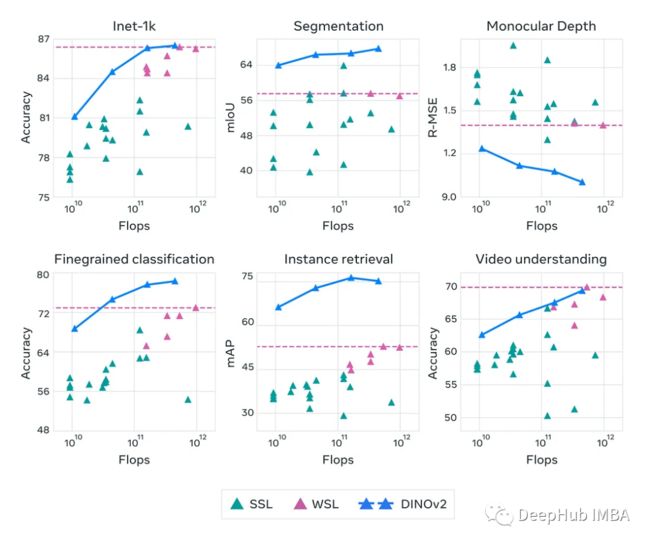
实例检索:使用非参数方法,DINOv2能够在各种数据集(如Paris、Oxford、Met和amsterdam)上优于自监督和弱监督模型。它在不同任务粒度上表现良好的能力证明了它强大的特征学习能力。
语义分割:该模型在所有数据集上都表现出强大的性能,使用更简单的预测器也是如此。并且当使用boosted recipe进行评估时,它几乎与 Pascal VOC 上的最新技术水平相匹配。通过冻结主干并调整适配器和头部的权重,模型在 ADE20k 数据集上取得了接近现有技术水平的结果。
深度估计:DINOv2在单目深度估计任务上表现出很好的结果,超过了自监督模型和弱监督模型。SUN-RGBd数据集突出了它在域外的泛化能力,其中一个在纽约大学室内场景上训练的模块可以泛化到了室外场景。
总结
DINOv2令人印象深刻的能力和广泛的适用性预示着自我监督学习领域的光明前景。DINOv2 的发布是在 Segment Anything 项目之后发布的,可以说DINOv2 补充了 Segment Anything。SAM 是一个可以通过提示专注于对不同分割任务的零样本泛化系统,而 DINOv2 使用简单的线性分类器可以在分割以外的任务中取得很好的结果。如果能够将这两个模型合在一起将是计算机视觉领域的重大飞跃。
DINOV2的Demo网站:https://avoid.overfit.cn/post/d70e30fcf8024fc1b6e4a8a841048c13
作者:Ashwanth Ravi