豆瓣Top250电影爬虫
目录
摘要
1 引言 4
1.1 背景 4
1.2 意义 4
1.3 实现的功能 4
1.3.1 爬虫程序 4
1.3.2 可视化界面 4
2 系统结构 5
2.1 系统整体结构 5
2.2 使用的技术 5
2.2.1 Python 5
2.2.2 BeautifulSoup 5
2.2.3 正则表达式 5
2.2.4 SQLite 5
2.2.5 Flask框架 6
2.2.6 ECharts 6
2.3 相关的模块 6
2.3.1 爬虫模块 6
2.3.2 可视化模块 7
3 实现代码 7
3.1 爬虫模块 7
3.2 可视化模块 12
4 实验 16
5 总结和展望 17
1 引言
1.1 背景
在当今时代,随着各个国家为科研事业不断地投入精力与资源,很多科学技术不断的发展、突破以及日益完善。加之现代5G网络的发展,wifi6的应用,ipv6的普及,移动数据呈现爆炸式增长,互联网已经成为一个庞大的信息载体,这些对于人类的生活发展都有重大意义。
由此,为了满足需求,而有了网络检索功能。特别是搜索引擎的发展,人们的需求也在不断提高。现在有了python网络爬虫,极大的满足了人们的需求。本次就用python,开发一个爬取豆瓣Top250的资源,并可视化。
1.2 意义
互联网的发展促进了这个社会的发展,提高了人们的生活水平。网络爬虫的出现更是给人们带来了极大的方便。
开发这个程序,是为了加深学习python,学习爬取数据,处理数据,并将其可视化。也可提供给人们参考。
1.3 实现的功能
此作品分为两部分:
1.3.1 爬虫程序
通过爬虫技术在豆瓣网爬取Top250的电影信息。
1.3.2 可视化界面
界面显示250部今典电影,电影评分统计,上映时间分布和地区分布。
2 系统结构
2.1 系统整体结构
根据所需,此作品分为两部分,一部分为爬虫程序,另一部分为可视化。顶层业务流程图如下图所示:
2.2 使用的技术
2.2.1 Python
Python是一种跨平台的计算机程序设计语言。 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
2.2.2 BeautifulSoup
BeautifulSoup4是爬虫必学的技能。BeautifulSoup最主要的功能是从网页抓取数据,Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器。
2.2.3 正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
2.2.4 SQLite
SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它是D.RichardHipp建立的公有领域项目。它的设计目标是嵌入式的,而且已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。它能够支持Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,比如 Tcl、C#、PHP、Java等,还有ODBC接口,同样比起Mysql、PostgreSQL这两款开源的世界著名数据库管理系统来讲,它的处理速度比他们都快。。
2.2.5 Flask框架
Flask是一个轻量级的可定制框架,使用Python语言编写,较其他同类型框架更为灵活、轻便、安全且容易上手。它可以很好地结合MVC模式进行开发,开发人员分工合作,小型团队在短时间内就可以完成功能丰富的中小型网站或Web服务的实现。另外,Flask还有很强的定制性,用户可以根据自己的需求来添加相应的功能,在保持核心功能简单的同时实现功能的丰富与扩展,其强大的插件库可以让用户实现个性化的网站定制,开发出功能强大的网站。
2.2.6 ECharts
ECharts,缩写来自Enterprise Charts,商业级数据图表,一个纯Javascript的图表库,可以流畅的运行在PC和移动设备上,兼容当前绝大部分浏览器(IE6/7/8/9 /10/11,chrome,firefox,Safari等),底层依赖轻量级的Canvas类库ZRender,提供直观,生动,可交互,可高度个性化定制的数据可视化图表。创新的拖拽重计算、数据视图、值域漫游等特性大大增强了用户体验,赋予了用户对数据进行挖掘、整合的能力。
2.3 相关的模块
2.3.1 爬虫模块
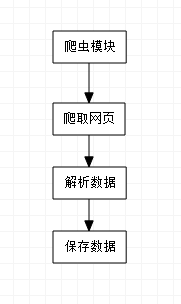
通过分析可得出爬虫模块是要从网页爬取信息,然后通过正则表达式筛选出自己想要的数据,并保存到数据库,如下图所示:
2.3.2 可视化模块
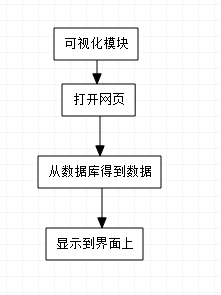
通过分析可得出可视化模块是根据爬虫模块的到的数据库信息,通过网页的方式显示出来,如下图所示:
3 实现代码
3.1 爬虫模块
首先导入需要的模块BeautifulSoup, re, urllib.request,urllib.error, xlwt, sqlite3
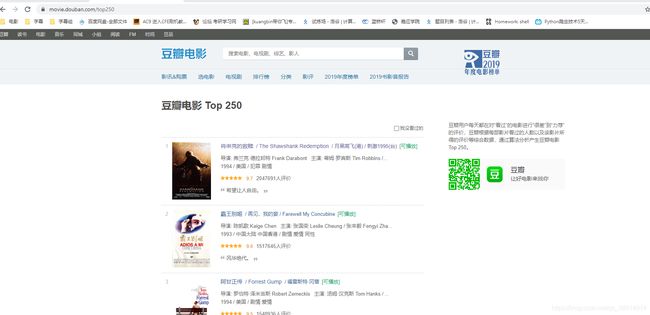
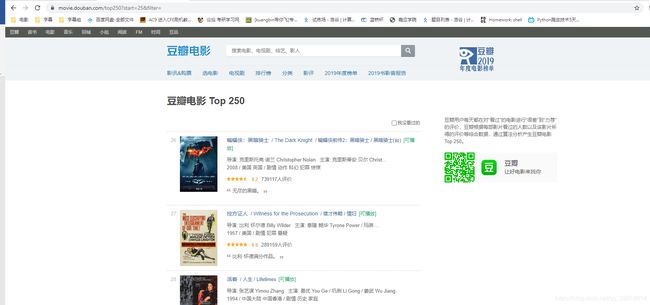
然后写主函数,这里需要从豆瓣网得到一个链接,根据图3、图4可以发现,豆瓣网Top250的页面有10页,每页有25部电影,而且链接形式为https://movie.douban.com/top250?start=+页面数
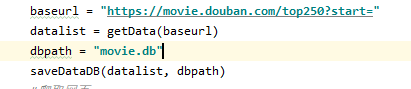
所以链接baseurl为https://movie.douban.com/top250?start=,保存的数据库地址为movie.db。之后由getData()和saveDataDB()两个函数负责爬取数据和保存数据,如图所示:
getData由两部分组成,一部分为爬取页面数据,由一个askURL()函数执行,通过urllib发送请求,最后返回整个页面的html,如图所示:

第二部分执行10次askURL得到十个页面,总共250电影的信息,并对返回的html数据通过BeautifulSoop解析,搜索对应位置的信息,并对其用正则表达式提取信息。
电脑用谷歌浏览器,按F12,打开开发者工具,如下图
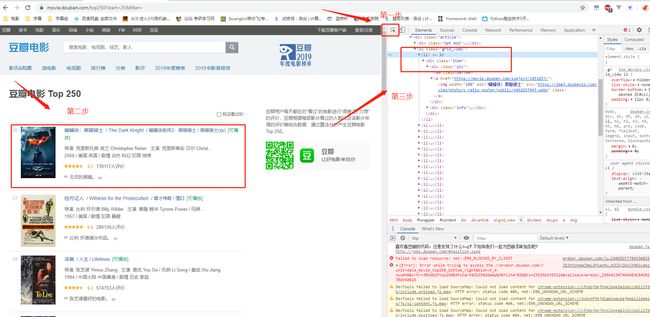
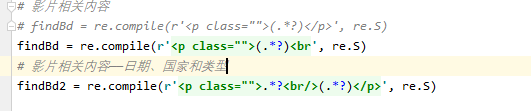
通过soup.find_all (‘div’, class_ = “item”)找到对应的内容,然后通过正则表达式提取相关内容,一个个append到datalist列表中,正则表达式如图所示:
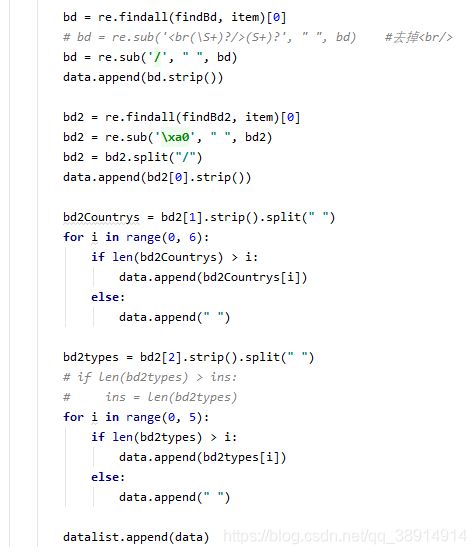
最后将datalist返回到主函数,传参给saveDataDB()保存到数据库,代码如图所示:
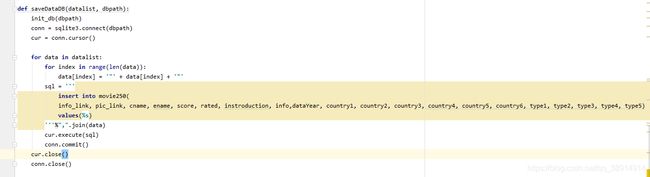
运行完就得到一个movie.db的文件,数据库文件如图所示:
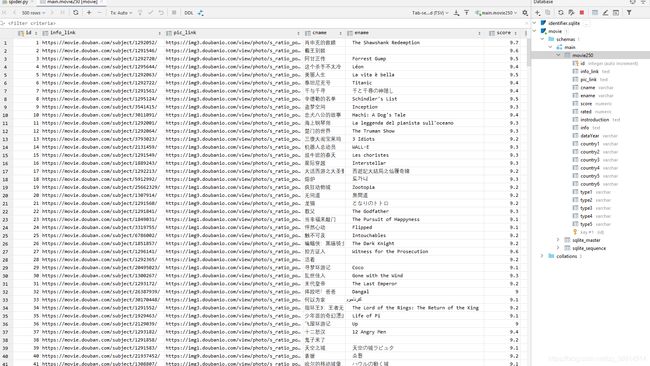
最后将movie.db文件复制到可视化的项目中。
3.2 可视化模块
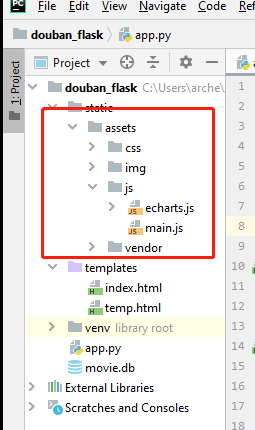
新建一个flack项目,并在模板之家找一个web模板,根据需求修改且页面。首先将下载的模板导入项目中,如图所示:
然后再app中设置好路由,用render_template()进入web页面,并再之后传入数据,代码如图所示:

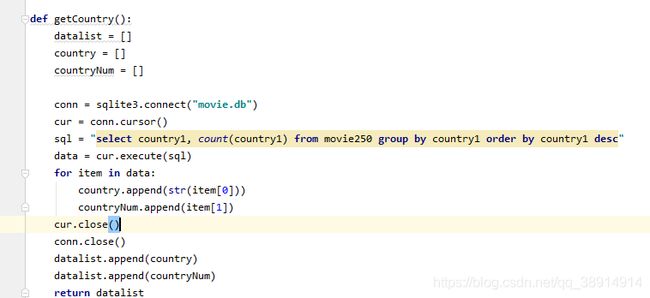
由于数据需要在app.py先进行处理,在传入到网页中显示,所以要有以下函数:getData(),getScore(),getCountry(),getCountry()[0].len(),getMovieDate()。这些函数分别是得到所有电影数据,得到评分数据,国家分布数据,国家数和电影上映日期,代码如图所示:
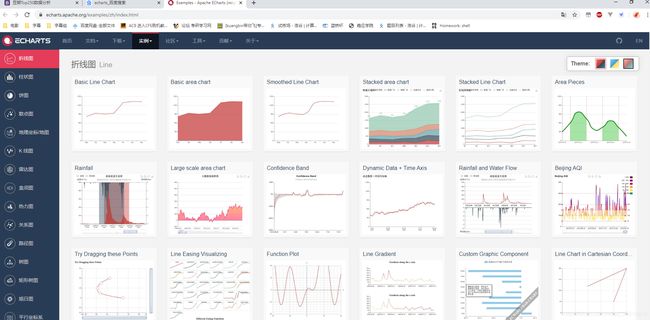
之后是修改html的代码,传过去的数据都用{{ }}两个大括号进行使用。页面此处选用echarts进行可视化数据,通过echarts官网可以下载安装模块,并在官网选择实例使用,如图可见:
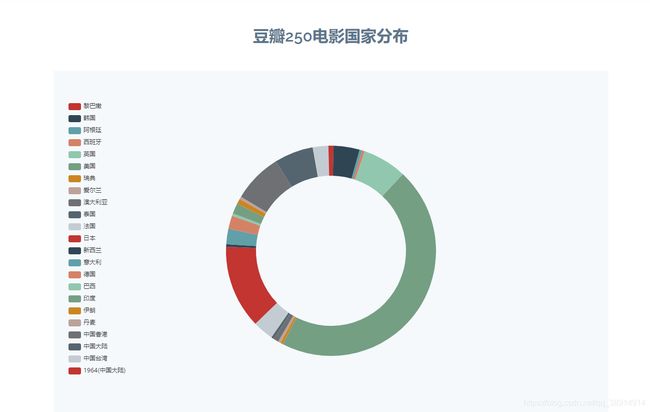
豆瓣Top250电影国家分布,选用echarts官网的Doughnut chart:示例如图:
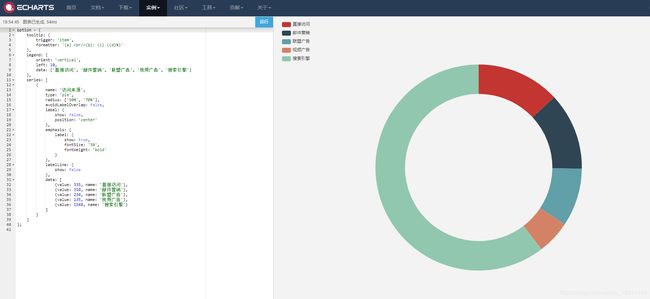
将参数country和coutryNum应用到实例中,使用{{ country[0]|tojson }}赋值,此处需要将countru[0]通过tojson转化为json格式才能正常显示,通过push将每个国家和对应的数的对象{value: countryNum[i], name: countrys[i]}添加到option.legend.data中,代码如图所示:

4 实验
运行douban项目得到数据库内容如图所示:
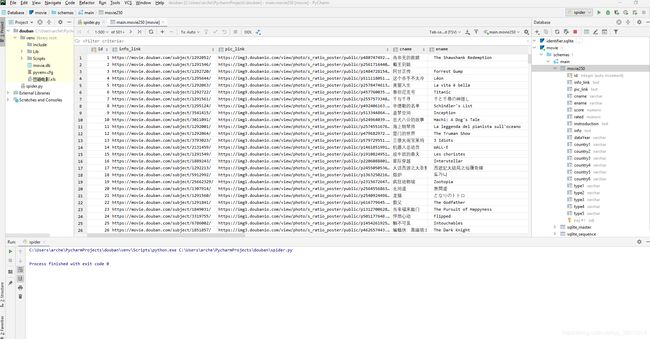
运行douban_flask项目,如图所示:
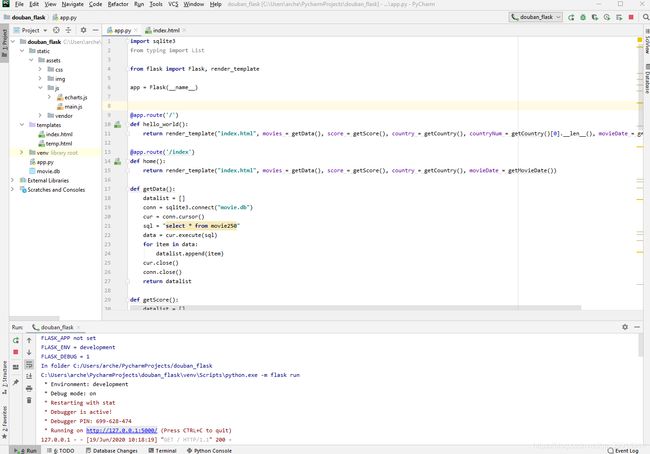
打开浏览器,访问http://127.0.0.1:5000,如图所示:
5 总结和展望
总结:学会了基础的网络爬虫,了解了BeautifulSoup的解析网页的方法,并熟悉了正则表达式的使用,以及urllib.request获取网页内容和数据库sqlite3的使用。
不足之处:没有将爬虫模块和可视化模块整合起来,普通用户无法看懂使用。