对比学习做了什么?
什么是对比学习?
对比学习貌似处于“无明确定义、有指导原则”的状态
什么是对比学习呢?(这个是微信链接)全文比较长,但是逻辑框架还是不错的。
如果想要更快速的了解什么是对比学习或者说对比学习是怎么做的,可以看SimCLR这个模型文章,该文章可以说介绍了比较“标准”的对比学习模型,这篇文章对SimCLR进行了图解,讲得很好。
那么对比学习的统一表示是什么呢,或者说对比学习的统一框架是什么呢?这篇文章做了很好的解释。
就目前来说,对比学习学习的框架可以总结为三种:
-
基于负例的:
- 主要以SimCLR为代表,虽然在SimCLR之前(2020年)已经提出很多对比学习模型,比如Moco V1,但是这篇SimCLR的效果相比于之前的模型,效果明显,而且采用了对称结构,整体相对比较清晰,容易说清楚。
-
基于非对称网络的
-
基于特征去相关(或者冗余消除损失函数方法)
前言
首先搬出论文的出处:
【文章一】ICML’20Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere
【文章二】CVPR’21 Understanding the Behaviour of Contrastive Loss
先说一下为什么要读这两篇论文呢?其实是来自一个偶然的机会,自己看到了对比学习(Contrastive Learning)这个东西,还是从ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer这篇文章入坑的(当然作为对比学习的入门,感觉还是SimCLR这个论文比较直白)。然后就想知道为什么对比学习有点形而上了,感觉是这么回事,但是觉得缺少了证明,为此无意中发现了这两篇文章。
感觉【文章二】是一定程度上Follow了【文章一】的工作,两篇文章都是从数学的角度上来证明为何Contrastive Learning 可以work。
背景
对比学习的思想说起来很简单,即拉近相似的样本,推开不相似的样本,一种常用的对比损失是基于批内负样本的交叉熵损失,假设我们有一个数据集 D = { ( x i , x i + ) } i = 1 m D = \{(x_i,x_i^+)\}^m_{i=1} D={(xi,xi+)}i=1m,其中 x i x_i xi和 x i + x_i^+ xi+是语义相关的,则在大小为N的mini batch内, ( x i , x i + ) (x_i, x_i^+) (xi,xi+)的训练目标为
ι i = l o g e s i m ( h i , h i + ) / τ ∑ j = 1 N e s i m ( h i , h j + ) / τ \iota_i = log\frac{e^{sim(h_i,h_i^+)/\tau}}{\sum^N_{j=1}e^{sim(h_i,h_j^+)/\tau}} ιi=log∑j=1Nesim(hi,hj+)/τesim(hi,hi+)/τ
但是对比学习中,最重要的就是要去构造Postive instances ( x i , x i + ) (x_i,x_i^+) (xi,xi+),对比学习最早起源于CV领域的原因之一就是图像是可以通过旋转、裁剪、扭曲等方式构造出不影响对图像语义理解的正样本 x i + x_i^+ xi+。近期也是有很多在NLP领域的数据增强的方法应用于产生正样本的方法。
Contrastive loss
【文章一】中说到,常见的contrastive loss如下图所示:

其中:
- p o s ( x , y ) pos(x,y) pos(x,y)表示一个正样本对;
- x i − x_i^- xi−表示 x i x_i xi的负样本;
- f ( x ) f(x) f(x)是一个trained encoder(以目前我的理解来看,我觉得就是神经网络);
有点抽象,那么我们看SimCLR和CoonSERT两篇论文中使用的Loss来进行对比,便于理解:
至于是怎么计算的,这篇博客一SimCLR为切入点来介绍了整个过程,在我看来,分子就是positive pair,也就是只考虑正样本对的距离,然而分母就是所有的距离了,包括正样本对和负样本对。
当然还有其他的对比学习中使用的Loss:


正文(文章一)
两个属性
首先【文章一】中确定了与对比损失有关的两个属性:
Alignment用来衡量正例对样本间的近似程度(紧密型或对齐性),即相似的样本具有相似的特征。Uniformity评估所有数据的向量均匀分布的程度,越均匀,保留的信息越多。
让特征分布在unit hypersphere的好处是?
-
固定范数的向量提升训练的稳定性;
-
如果一个类别的特征能被比较好的聚类,那么在整个特征空间上这个类别是更容易被线性可分的。
对于这个线性可分,文中做了实验:用AlexNet为模型框架,在CIFAR-10上,对比了三种实验方法:随机初始化、监督分类学习和无监督对比学习,可视化了表征效果(我感觉文中还是因为二维的可以更好地显示表达,因此才采取了二维圆的方式,尽管文中一直在说超球面这个概念,但是这个超球面的维度m一般也是大于2的):
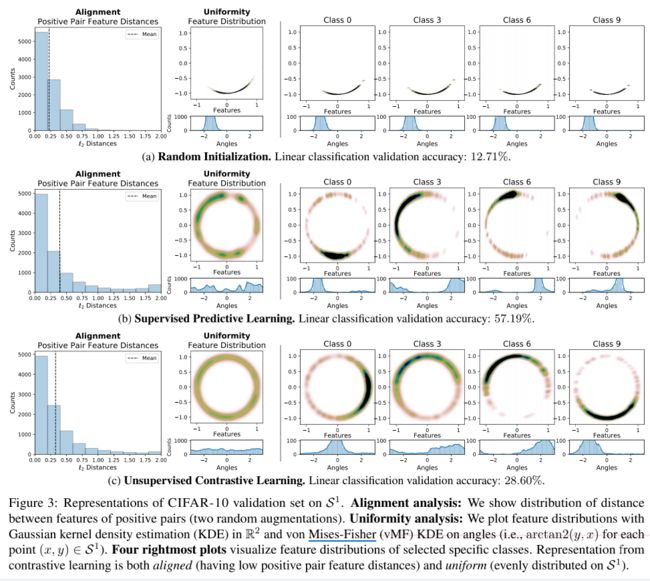
我们来简单的分析上图:
- 首先是Alignment这个柱状图,可以看出,正例样本对是都很相近的,效果也都还不错;
- 再看Uniformity这个图,三种方法中,最差劲的当然是随机初始化的了,这也侧面反映出为什么正例样本对为什么都很近——因为所有的样本都堆在一起了,那么根据Uniformity的定义可知,这样的特征信息不能均匀分布在Hyperspher上,因此信息机会保留不了。
- 我们再看最右边的四张图,可以发现,对比学习的不同类别的表征是分布在圆的不同位置上的(看圆形图下面的Angles分布图)。
- 相比于监督学习来说,对比学习的分布就更均匀,不会出现聚集的现象——虽然线性分割的效果,对比学习(28.60%)比监督学习(58.19%)来说差了很多,但是保留了更多的信息可以学习。
衡量两个属性
我们再回过头来看一下文中所说的Loss:
文中将 L c o n t r a s t i v e L_{contrastive} Lcontrastive进行了拆分,拆分成了两个部分(就是化简):

文中为了衡量Alignment和Uniformity这两个属性,将定义两个loss( L a l i g n 和 L u n i f o r m L_{align}和L_{uniform} Lalign和Luniform)分别对应这两个属性,如下(从形式上来看,就是将 f ( x i − ) T f ( x ) f(x_i^-)^Tf(x) f(xi−)Tf(x)变成了 ∣ ∣ f ( x ) − f ( y ) ∣ ∣ ||f(x)-f(y)|| ∣∣f(x)−f(y)∣∣):
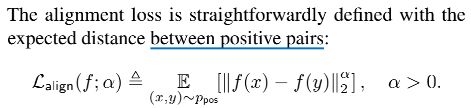

我感觉这样做的目的就是:证明对比学习的机制或者说效果好的原因就是因为Alignment和Uniformtiy这两属性,那么文章就干脆根据这两个属性的定义,构造了两个Loss,直接优化这两个Loss就可以得出效果是不是比 L c o n t r a s t i v e L_{contrastive} Lcontrastive更好。如果好,那么就证明了对比学习确实是因为这两个属性才使得效果变好的。
为什么这样写呢,文中是给出了详细的公式推理的,我这里截取了一点点给显示的说明一下等式关系:

实验证明
从下图可以明显看出,直接优化的Loss(在下图中就是小圆点)的acc更高
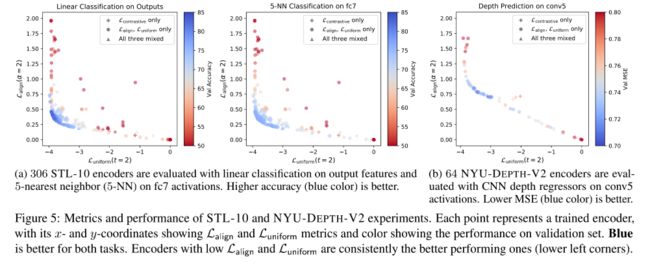
下面这张图也反应出了 L a l i g n 和 L u n i f o r m L_{align}和L_{uniform} Lalign和Luniform结合的重要性,不管是单独使用哪一个,效果都不好(我觉得下图的纵坐标只是代表数值,并非是某一个度量,也就是 L a l i g n 和 L u n i f o r m L_{align}和L_{uniform} Lalign和Luniform都应该越小越好)。
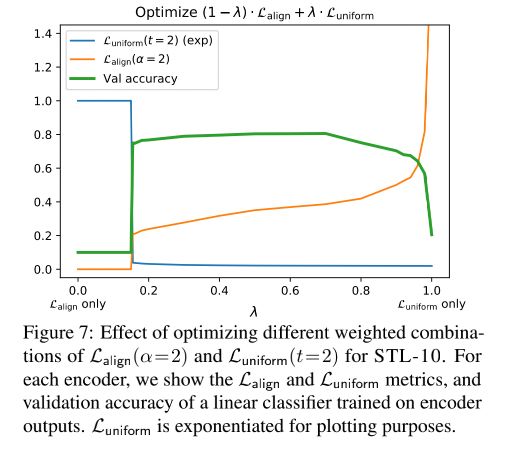
正文(文章二)
首先说明,对比学习中的negative sample应该是相对于anchor simple来说的,也就是说,对于样本 x i x_i xi来说,除了数据增加的 x i + x_i^+ xi+其余的都是负样本。
这也解释了为什么越推远负样本,反而潜在语义效果也差了,因为负样本中是包含同类样本的相似样本,比如在对比学习美短这种猫的同时,如果过分追求unifomty,就会导致推远银渐层这种猫的距离,这样也就破坏了相似样本的潜在语义。这是因为contrastive loss只是追求区分不同的instance(或者说sample),而没有关注语义关系。
摘要
这篇文章主要讨论了对比学习的Loss函数,并认为对比学习的Loss是一个hardness-aware loss function,温度参数 τ \tau τ能够控制对hard negative sample的惩罚程度(越小,惩罚越高,越容易使相似的负样本分开,使其变得均匀,即uniformity)。但是过分的追求uniformity的指标,会破坏相似样本(所谓的相似样本指的是与正样本相似度极高的负样本往往很可能是潜在的正样本)的空间分布,进一步会影响到下游任务。作者称这种现象为uniformity-tolerance dilemma,但是选择一个好的温度系数 τ \tau τ可以很好地平衡分离负样本和容忍相似样本的关系。
介绍
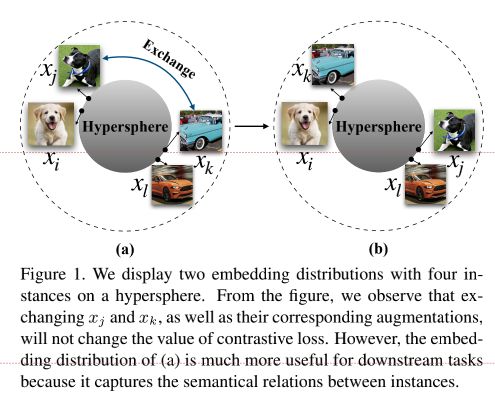
为了更好地理解作者提出的语义结构的影响,作者用下图作解释。对于(a)(b)两种embedding分布而言,我们将 x j 和 x k x_j和x_k xj和xk的embedding交换,虽然不会改变对比学习的loss,但是(a)的这种分布相比于(b)的这种分布在下游任务中表现更好,因为它能够体现出样本间潜在的语义结构。
其实这个图也从侧面表示出uniformity-tolerance的特点,(a)图表示出相似样本距离并非很远,但是(b)图的相似样本距离较远(虽然对于 x j x_j xj和 x k x_k xk来说不用样本的距离是一样的,那么loss也就一样),在下游任务中结果显示,(a)中这样的分布效果更好,也就是说明相似样本之间潜在语义得以保留。
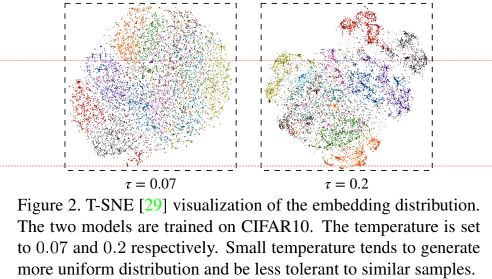
同时文章还探讨了温度对Contrastive loss的影响,发现对于越低的温度,contrsstive loss会更加惩罚最近的负样本,虽然分布的会更加均匀(拉近正样本对的距离,拉开负样本对的距离,这样的方法并不包含语义信息),但是同时也会导致相似样本的分离,作者用T-SNE可视化了不同温度下的embedding的分布情况:
整个文章做了三个工作:
- 分析了contrastive loss是一种hardness-aware loss,并且该属性对于contrastive loss意义重大;
- 从梯度的角度分析,温度参数是一个惩罚hard negative sample重要的参数;
- 表明了在对比学习中确实存在uniformity-tolerance delimma,一个 good choice of temperature可以平衡好uniformity(保证样本分布均匀)和toleartce(保持相似样本的距离)这两个属性。
分析Hardness-aware 属性
首先给出自监督学习广泛使用的对比损失(InfoNCE loss)的形式:

为了表示方便,作者用 P i , j P_{i,j} Pi,j进行了表示(含义为 x i x_i xi被认为是 x j x_j xj的概率):

从对比学习Loss的角度出发(要求第i个样本和它的另一个augmentation的副本(即正样本)之间的相似度 s i , i s_{i,i} si,i尽可能大,而与其他的实例(负样本)之间的相似度 s i , k s_{i,k} si,k尽可能小),作者定义了一个简单的Loss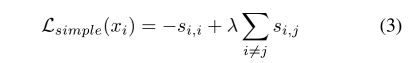
然而实际训练过程,采用 L s i m p l e L_{simple} Lsimple的方法效果是不如以softmax-based 的 contrastive loss。
这是因为 softmax-based contrastive loss 是 hardness-aware loss function,它能够自动关注negative sample,从而达到均匀分布的效果。
梯度分析
先来看看对于公式(1)的求导情况如下(针对正相似性和付相似性的求偏导数的结果):

根据上式可以得出下面的结论:
- 对于negative sample来说,其梯度是正比于 e x p ( s i , j / τ ) exp(s_{i,j}/\tau) exp(si,j/τ),这说明contrasive loss是一种hardness-aware loss function,这是不同于 ∂ L s i m p l e ∂ s i , j = λ \frac{\partial L_{simple}}{\partial s_{i,j}}=\lambda ∂si,j∂Lsimple=λ是呈现出常数比(也就是说对于所有的负样本,梯度都是一样的);
- 进一步思考,对于所有的负样本比例来说, P i , j P_{i,j} Pi,j的分母项是相同的,那么也就说 s i , j s_{i,j} si,j越大,则 P i , j P_{i,j} Pi,j的分子项就越大,那么梯度也就是越大-------> 也就是说,对比学习的loss是给予了更相似的负样本(hard negative sample)更大的梯度,那么就越远离正样本了。
- 仔细观察还可以发现一个有意思的地方,那就是正样本的梯度等于所有负样本梯度的和
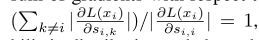
温度的作用
作者对 x j x_j xj这个负样本定义了一个叫做相对惩罚强度:
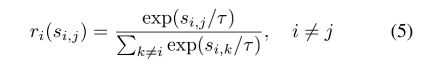
公式(5)满足满足玻耳兹曼分布,并且该分布的熵随着温度系数的增大严格增大(在论文的补充实验中会给予证明,这里就不阐述了)。
下图展示了负样本相对惩罚与温度和相似度的关系,可以发现,当温度很小的时候,比如0.07,对于距离越近的负样本惩罚越大,那么梯度也就越大,因此越能够远离,反之,随着温度的升高,所有负样本的惩罚呈现均匀性(即呈现出一视同仁的感觉)。
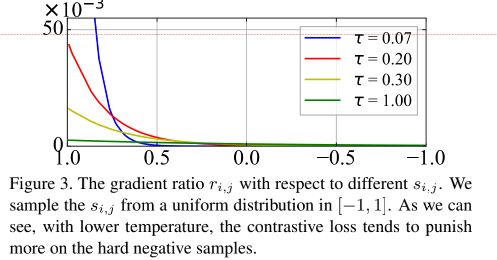
但是这样出现前面所说的问题,过于追求小的温度就会只会惩罚最近的一两个负样本,为此作者从公式的角度考虑了两个极端的例子,即温度趋向于0和无穷大这两种情况。
- 当温度系数趋向于0时,此时对比损失退化为只关注最困难的负样本的损失函数

-
当温度系数趋向于无穷大时,此时对比损失对所有负样本的权重都相同,对比损失失去了困难样本关注的特性

有趣的是,当温度系数趋向于无穷时,该损失便变成了之前介绍的简单损失 L s i m p l e L_{simple} Lsimple(公式(3))
Explicit Hard Negative Sampling
作者在文中引用了前人Zhuang 等人的工作成果——LocalAggregation。在计算对负样本的梯度的时候,指选择相思对大于某个阈值的负样本来计算Loss(比如选择Top K nearnest negative sample)。
这样的话,相当于放大了负样本的作用,使得当temperature变大时,模型最后形成的embedding分布会更均匀一点,而不会像Figure 4 (下图)那样随着temperature增大embedding分布变得更不均匀,而是和Figure 6的图像一样。
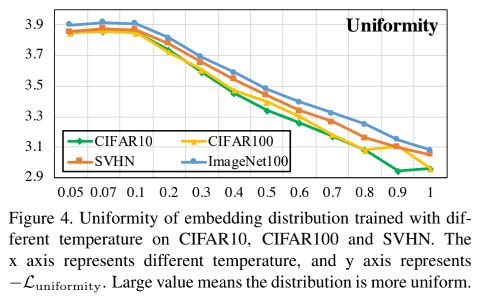
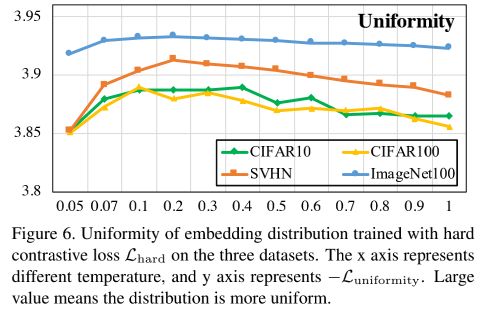
以此缓解Uniformity-Tolerance Dilemma中调节temperature对uniformity变化的影响。
Hard Contrastive Loss定义如下:
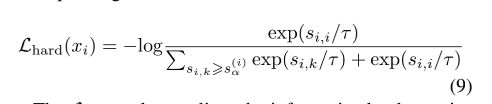
其中, s α ( i ) s_{\alpha}^{(i)} sα(i)是负样本与anchor x i x_{i} xi的一个相似度分界点,对于相似度在[ s α ( i ) s_{\alpha}^{(i)} sα(i),1.0]这个区间(informative interval)的负样本被看作是informative hard negative samples与anchor更相似,更难将他们分隔开),而对于相似度在 [-1.0 , s α ( i ) s_{\alpha}^{(i)} sα(i)]这个区间,则被称作uninformative interval。
在计算loss的时候, s i , j < s α ( i ) s_{i,j}
Uniformity-Tolerance Dilemma
Embedding Uniformity
作者分析了Uniformity和温度的关系,如下图所示:
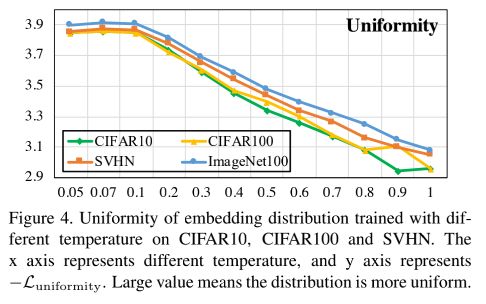
可以发现,温度越低的时候,contrastive loss往往会分开与anchor sample相近的positive samples这就会导致局部分布更加稀疏。
那我们来看看Hard contrastive loss的图像:
可以看出Hard contrastive loss对温度并不那么敏感了,而且效果也保持在一个较高的水平。
Tolerance to Potential Positive Samples
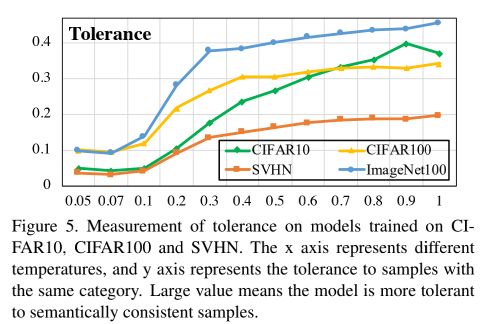
对比学习之后的效果可以用Fig1(a)来表示,但是我们知道随着温度的降低,会导致相近的负样本远离anchor样本,那么为了衡量这样的现象,提出Tolerance这个属性。
作者用下面的式子衡量属于同一类的tolerance:

所谓的同一类就是狗是同一类,但是不管是什么品种,汽车是一个类,也不管是什么品牌。
下图展示了温度对Tolerance的影响:
同样的,我们来看看 L h a r d L_{hard} Lhard的Tolerance的效果:
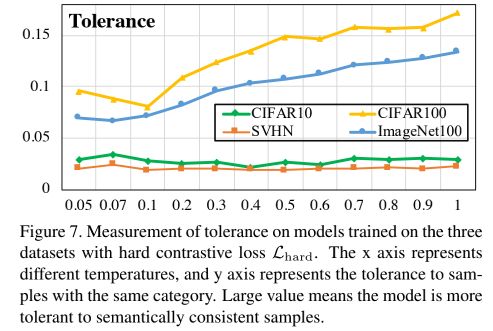
可以看出,效果还不如ordinary contrative loss,这是肯定的,因为 H h a r d H_{hard} Hhard的unifomity高了,导致相似性下降了。
但是将Figure 6和Figure 4相比可以发现,此时随着temperature增大,Uniformity保持较稳定不变。此时增大temperature便可以在保持uniformity不增大的情况下,增大Tolerance,即模型得到的embedding既保持均匀,又能局部聚集,从而保留一定潜在语义结构,破解上一节所说的Uniformity-Tolerance Dilemma问题。
实验验证
下图展示了在CIFAR100上的效果,结果证明,确实是随着温度的增加,正负样本难以分开(纵坐标代表距离):
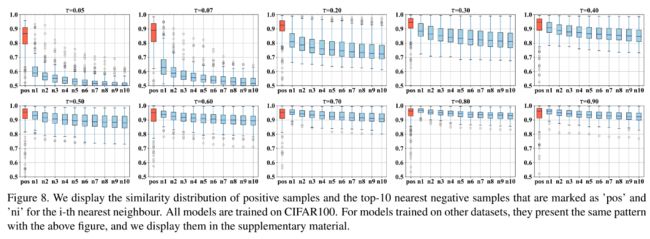
另一方面,作者也对不同的数据集的最优温度系数进行了验证,下图绿色的柱子为对比损失随着温度系数的性能表现。此外,作者也验证了采取显式困难样本发现的对比损失,采取了显示的困难样本挖掘算法后,性能表现与温度系数的关联弱化,当温度系数高于一个合适的值时,该损失产生的模型性能基本保持稳定。
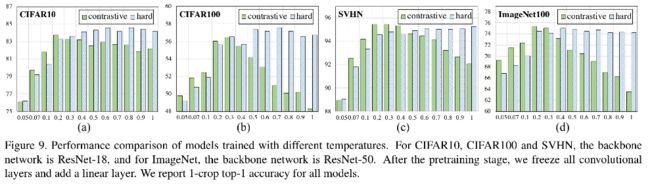
总结
文章对对比损失(Contrastive Loss)中的温度系数进行了研究,解释了温度系数的具体作用,借此探索了对比学习的学习机制。
总结下本文的发现:
- 对比损失函数是一个具备困难负样本自发现性质的损失函数,这一性质对于学习高质量的自监督表示是至关重要的,不具备这个性质的损失函数会大大恶化自监督学习的性能。关注困难样本的作用就是:对于那些已经远离的样本,不需要继续让其远离,而主要聚焦在如何使没有远离的那些的样本远离,从而使得到的表示空间更均匀(uniformity)。
- 温度系数的作用是调节对困难样本的关注程度:越小的温度系数越关注于将本样本和最相似的其他样本分开)。作者对温度系数进行了深入的分析和实验,并利用温度系数来解释对比学习是如何学到有用表征的。
- 对比损失存在一个均匀性-容忍性的Dilemma(Uniformity-Tolerance Dilemma)。小温度系数更关注于将与本样本相似的困难样本分开,因此往往可以得到更均匀的表示。然而困难样本往往是与本样本相似程度较高的,例如同一个类别的不同实例,即有很多困难负样本其实是潜在的正样本。过分强迫与困难样本分开会破坏学到的潜在语义结构。
参考:
https://zhuanlan.zhihu.com/p/357071960
https://zhuanlan.zhihu.com/p/406628964