小知识点:ARM 架构 Linux 大数据集群基础环境搭建(Hadoop、MySQL、Hive、Spark、Flink、ZK、Kafka、Nginx、Node)
换了 M2 芯片的 Mac,以前 x86 版本的 Linux 大数据集群基础环境搭建在 ARM 架构的虚拟机集群上有些用不了了,现在重新写一份基于 ARM 架构的,少数不兼容之外其他都差不多,相当于更新一版以前的
部分和 x86 的一样
x86 版:Linux 虚拟机:大数据集群基础环境搭建(Hadoop、Spark、Flink、Hive、Zookeeper、Kafka、Nginx)
目录
-
- 一、相关文件下载地址
- 二、基础环境配置
- 三、语言环境配置
-
- 3.1 Java 环境安装
- 3.2 Python 环境安装
- 3.3 Scala 环境安装
- 四、大数据组件安装
-
- 4.1 Hadoop 集群安装
- 4.2 Docker 安装
- 4.3 MySQL 安装
- 4.4 Hive 安装
- 4.5 Spark 安装
- 4.6 Flink 安装
- 4.7 Zookeeper 安装
- 4.8 Kafka 安装
- 4.9 Nginx 安装
- 4.10 Node 安装
- 4.11 Doris 安装
- 五、问题解决
-
- 5.1 环境配置错误,丢失命令
- 5.2 start-yarn.sh 无法启动 resourcemanager
- 5.3 mysql 远程连接报错 Public Key Retrieval is not allowed
- 5.4 Flink 提交任务报错 classloader.check-leaked-classloader
- 5.5 Kafka 启动报错 UseG1GC
- 5.6 Nginx 启动报错 Permission denied
- 5.7 Nginx 403 Forbidden
- 5.8 Node 报错 GLIBC_2.27 not found
一、相关文件下载地址
- ARM 架构的 Centos 7
- 参考:小知识点:Mac M1/M2 VMware Fusion 安装 Centos 7.9(ARM 64 版本)
- Java-1.8
- https://www.oracle.com/java/technologies/downloads/#java8
- 选择 ARM 64 版本的,网上搜一个 Oracle 账号就能下载
- https://www.oracle.com/java/technologies/downloads/#java8
- Python-3.9
- https://www.python.org/ftp/python/3.9.6/Python-3.9.6.tgz
- Scala-2.12
- https://www.scala-lang.org/download/2.12.12.html
- Hadoop-3.2.1
- http://archive.apache.org/dist/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
- Spark-3.1.2
- http://archive.apache.org/dist/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
- Flink-1.13.1
- http://archive.apache.org/dist/flink/flink-1.13.1/flink-1.13.1-bin-scala_2.12.tgz
- Hive-3.1.3
- http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
- Zookeeper-3.8.0
- http://archive.apache.org/dist/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
- Kafka-3.2.0
- http://archive.apache.org/dist/kafka/3.2.0/kafka_2.12-3.2.0.tgz
- Nginx-1.23.1
- https://nginx.org/download/nginx-1.23.1.tar.gz
- Node-18.14.1
- https://nodejs.org/dist/v17.9.1/node-v17.9.1-linux-arm64.tar.gz
- Doris-1.2.2
- https://mirrors.tuna.tsinghua.edu.cn/apache/doris/1.2/1.2.2-rc01/apache-doris-fe-1.2.2-bin-arm.tar.xz
- https://mirrors.tuna.tsinghua.edu.cn/apache/doris/1.2/1.2.2-rc01/apache-doris-be-1.2.2-bin-arm.tar.xz
- https://mirrors.tuna.tsinghua.edu.cn/apache/doris/1.2/1.2.2-rc01/apache-doris-dependencies-1.2.2-bin-arm.tar.xz
二、基础环境配置
- 创建的用户并添加 sudo 权限并免密
# root 下
useradd -m ac_cluster
passwd ac_cluster
# sudo 权限
sudo vi /etc/sudoers
# 添加下面两条
ac_cluster ALL=(ALL) ALL
ac_cluster ALL=(ALL) NOPASSWD: ALL
# 保存退出
:wq!
- 修改静态 IP
# 编辑该文件
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens160
# 修改参考如下,具体的在安装虚拟机的时候有展示,
BOOTPROTO=static
GATEWAY="192.168.104.2"
IPADDR="192.168.104.101"
NETMASK="255.255.255.0"
DNS1="8.8.8.8"
DNS2="114.114.114.114"
# 重启网络
sudo systemctl restart network
- 修改 yum 源
- 这里用的是阿里云的 yum 源
# 先下载 wget
sudo yum -y install wget
# 修改阿里云的配置
sudo wget http://mirrors.aliyun.com/repo/Centos-altarch-7.repo -O /etc/yum.repos.d/CentOS-Base.repo
# 清理软件源
yum clean all
# 元数据缓存
yum makecache
# 测试
sudo yum -y install vim
- 修改 hostname
# 根据实际修改
vim /etc/hostname
# 重启
reboot
- 关闭防火墙
sudo systemctl stop firewalld
sudo systemctl disable firewalld
- 修改域名映射
sudo vim /etc/hosts
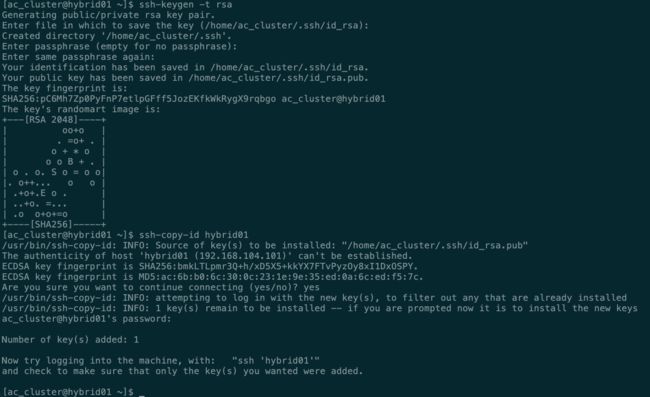
- 配置机器间免密登陆
# 输入后三次回车
ssh-keygen -t rsa
# 配置节点
ssh-copy-id hybrid01
- 配置时间同步
sudo yum -y install ntpdate
sudo ntpdate ntp1.aliyun.com
# 可选,也可以配置自动执行时间同步,根据自己需求来
crontab -e */1 * * * * sudo /usr/sbin/ntpdate ntp1.aliyun.com
三、语言环境配置
3.1 Java 环境安装
- 准备好 ARM 64 的 Java 包
# 使用 rz -be 上传文件,没有的先下载,或者使用其他工具上传
sudo yum -y install lrzsz
# 上传,选择本地下载好的位置
rz -be
# 解压 Java 包
tar -zxvf jdk-8u361-linux-aarch64.tar.gz -C ../program/
# 配置环境变量
vim ~/.bash_profile
# 添加下面两条
export JAVA_HOME=/xx/xx
export PATH=$JAVA_HOME/bin:$PATH
# 更新环境
source ~/.bash_profile
# 测试
java -version
# 传给其他节点并配置环境变量即可
scp -r jdk1.8.0_361/ ac_cluster@hybrid02:$PWD

3.2 Python 环境安装
- 下载好源码包,可以使用 wget 下载
# 下载 Python 源码包
wget https://www.python.org/ftp/python/3.9.6/Python-3.9.6.tgz
# 解压
tar -zxvf Python-3.9.6.tgz
# 安装依赖环境
sudo yum -y install unzip net-tools bzip2 zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel libpcap-devel xz-devel libglvnd-glx gcc gcc-c++ make
# 预配置
./configure --prefix=/home/ac_cluster/program/python3.9.6
# 编译安装
make && make install
# 配置环境变量或者软链接到 /usr/bin 中
sudo ln -s /home/ac_cluster/program/python3.9.6/bin/python3.9 /usr/bin/python3
sudo ln -s /home/ac_cluster/program/python3.9.6/bin/pip3.9 /usr/bin/pip3
# 测试
python3 --version
3.3 Scala 环境安装
- 下载好相关包
# 上传,也可以使用其他方式上传到虚拟机
rz -be
# 解压
tar -zxvf scala-2.12.10.tgz -C ../program/
# 配置环境
vim ~/.bash_profile
# 添加下面两条
export SCALA_HOME=/home/ac_cluster/program/scala-2.12.10
export PATH=$PATH:$SCALA_HOME/bin
# 更新环境
source ~/.bash_profile
# 测试
scala -version

四、大数据组件安装
4.1 Hadoop 集群安装
- 下载相关包并上传虚拟机
# 上传
rz -be
# 解压
tar -zxvf hadoop-3.2.1.tar.gz -C ../program/
# 进入配置目录
cd ../program/hadoop-3.2.1/etc/hadoop
# 修改 hadoop-env.sh,添加下面的内容
export JAVA_HOME=/home/ac_cluster/program/jdk1.8.0_361
- 修改 core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hybrid01:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/ac_cluster/runtime/hadoop_repovalue>
property>
configuration>
- 修改 hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hybrid01:50090value>
property>
configuration>
- 修改 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
- 修改 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hybrid02value>
property>
configuration>
- 修改 workers
- 添加相关 datanode 节点主机名
- 修改 hdfs、yarn 启动脚本
# start-dfs.sh、stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# start-yarn.sh、stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 环境配置
# 根据实际情况修改配置文件
vim ~/.bash_profile
# 添加下面的配置
export HADOOP_HOME=/home/ac_cluster/program/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
# 更新环境
source ~/.bash_profile
- 剩余操作
# 分发各节点,根据自己实际情况操作
scp -r hadoop-3.2.1/ ac_cluster@hybrid02:$PWD
scp -r hadoop-3.2.1/ ac_cluster@hybrid03:$PWD
# 格式化 namenode
hdfs namenode -format
# hdfs 启动
start-dfs.sh
# yarn 启动(进入部署 resourcemanager 的节点进行部署)
start-yarn.sh


4.2 Docker 安装
# 依赖安装
sudo yum -y install yum-utils device-mapper-persistent-data lvm2
# 配置 docker yum 源
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 下载 docker
sudo yum -y install docker-ce docker-ce-cli containerd.io
# 启动 docker
sudo service docker start
# 如果直接用不了,需要 sudo 的话可以直接去掉
sudo gpasswd -a ac_cluster(你的用户名) docker
newgrp docker
4.3 MySQL 安装
- MySQL 安装的是 5.7 版本,基于 docker 进行安装
- 目前看只有 8 以上支持 ARM 64
- 提前准备好挂载的目录 conf、data

# 拉取镜像
docker pull mysql:8
# 启动容器
docker run -d --name=mysql -p 3306:3306 --restart=always --privileged=true -v /home/ac_cluster/docker/mysql/data:/var/lib/mysql -v /home/ac_cluster/docker/mysql/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=123456 mysql:8 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
# 下载驱动留着备用
wget http://ftp.ntu.edu.tw/MySQL/Downloads/Connector-J/mysql-connector-java-8.0.26.tar.gz
4.4 Hive 安装
- 下载相关包并上传
# 上传
rz -be
# 解压
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C ../program/
# 进入配置目录
cd ../program/apache-hive-3.1.3-bin/conf/
# 修改 hive-env.sh
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
# 添加下面的内容
HADOOP_HOME=/home/ac_cluster/program/hadoop-3.2.1
export HIVE_CONF_DIR=/home/ac_cluster/program/apache-hive-3.1.3-bin/conf
# 修改 hive-site.xml
vim hive-site.xml
- hive-site.xml 配置
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://hybrid03:3306/hive?createDatabaseIfNotExist=true&useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.cj.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://hybrid03:9083value>
property>
configuration>
- 其他操作
# 进入 hive 目录
cd ~/program/apache-hive-3.1.3-bin
# 将 MySQL 启动复制一份到 lib 下
cp ~/package/mysql-connector-java-8.0.26/mysql-connector-java-8.0.26.jar ./lib/
# guava 包问题,将 Hadoop 下的 guava 包复制到 lib 下
cp ~/program/hadoop-3.2.1/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
# 备份
mv ./lib/guava-19.0.jar ./lib/guava-19.0.jar.bak
# 初始化数据库
bin/schematool -dbType mysql -initSchema
# 配置环境
vim ~/.bash_profile
# 添加下面的配置
export HIVE_HOME=/home/ac_cluster/program/apache-hive-3.1.3-bin
export PATH=$PATH:$HIVE_HOME/bin
# 刷新环境
source ~/.bash_profile
# 启动服务
nohup hive --service metastore &
# 启动交互
hive
4.5 Spark 安装
- 平常习惯 Spark 是基于 Yarn 跑任务,这里只是简单解压,不安装集群
# 上传
rz -be
# 解压
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz -C ../program/
# 配置环境
vim ~/.bash_profile
# 添加下面配置
export SPARK_HOME=/home/ac_cluster/program/spark-3.1.2-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin
# 刷新
source ~/.bash_profile
- 测试样例 yarn 提交
- 在 Hadoop Yarn 的 8088 端口页面中可以看到相关信息
# 进入样例 jar 包所在位置
cd ~/program/spark-3.1.2-bin-hadoop3.2/examples/jars
# 提交任务
spark-submit --master yarn --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.1.2.jar 100


- 配置 Hive 环境
- 将 Hive 的 hive-site.xml 放到 Spark 的 conf 下
- 将 MySQL 的驱动放到 Spark 的 jars 里
- 测试
- spark-shell
- spark.sql(“show databases”).show()

4.6 Flink 安装
- Flink 和 Spark 一样基于 Yarn 运行,不安装集群
- 下载相关包并上传
# 上传
rz -be
# 解压
tar -zxvf flink-1.13.1-bin-scala_2.12.tgz -C ../program/
# 配置环境
vim ~/.bash_profile
# 添加下面的配置
export FLINK_HOME=/home/ac_cluster/program/flink-1.13.1
export PATH=$PATH:$FLINK_HOME/bin
# 刷新环境
source ~/.bash_profile
- 测试样例 yarn 提交
- 在 Hadoop Yarn 的 8088 端口页面中可以看到相关信息
# 进入样例目录
cd ~/program/flink-1.13.1/examples/batch
# 提交任务
flink run -m yarn-cluster WordCount.jar


4.7 Zookeeper 安装
- 下载相应的包上传
# 上传
rz -be
# 解压
tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz -C ../program/
# 创建数据目录和日志目录(所有节点都要操作)
mkdir -p ~/runtime/zookeeper/data ~/runtime/zookeeper/logs
# 进入配置目录
cd ~/program/apache-zookeeper-3.8.0-bin/conf
# 修改 zoo.cfg
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
# 修改下面的配置
dataDir=/home/ac_cluster/runtime/zookeeper/data
dataLogDir=/home/ac_cluster/runtime/zookeeper/logs
server.1=hybrid01:2888:3888
server.2=hybrid02:2888:3888
server.3=hybrid03:2888:3888
# 分发节点
scp -r apache-zookeeper-3.8.0-bin/ ac_cluster@hybrid02:$PWD
# 在 dataDir 目录下添加 myid 并赋值,其他节点同样操作,不同 id
echo 1 > ~/runtime/zookeeper/data/myid
# 配置环境(三个节点都要配)
vim ~/.bash_profile
# 添加下面的配置
export ZOOKEEPER_HOME=/home/ac_cluster/program/apache-zookeeper-3.8.0-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# 刷新
source ~/.bash_profile
# 三个节点逐个启动
zkServer.sh start
# 查看状态
zkServer.sh status
4.8 Kafka 安装
- 下载相应的包并上传
# 上传
rz -be
# 解压
tar -zxvf kafka_2.12-3.2.0.tgz -C ../program/
# 创建 log 目录
mkdir -p ~/runtime/kafka/logs
# 进入 conf 目录修改 server.properties
cd ~/program/kafka_2.12-3.2.0/config/
vim server.properties
# 查看并修改下面的配置,id 必须唯一,传给其他节点需要修改
broker.id=0
log.dirs=/home/ac_cluster/runtime/kafka/logs
zookeeper.connect=hybrido1:2181,hybrid02:2181,hybrid03:2181
listeners=PLAINTEXT://192.168.104.101:9092
advertised.listeners=PLAINTEXT://192.168.104.101:9092
# 配置环境
vim ~/.bash_profile
# 添加下面的配置
export KAFKA_HOME=/home/ac_cluster/program/kafka_2.12-3.2.0
export PATH=$PATH:$KAFKA_HOME/bin
# 刷新
source ~/.bash_profile
# 分发节点,并修改相关配置,配置环境变量
scp -r kafka_2.12-3.2.0/ ac_cluster@hybrid02:$PWD
scp -r kafka_2.12-3.2.0/ ac_cluster@hybrid03:$PWD
# 逐个启动节点,如果有报错,查看下方解决方案
nohup kafka-server-start.sh $KAFKA_HOME/config/server.properties > ~/runtime/kafka/logs/nohup.log 2>&1 &
4.9 Nginx 安装
- 下载相应的包并上传,也可以使用 wget 下载
# 环境依赖安装
sudo yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel
# wget 下载包
wget https://nginx.org/download/nginx-1.22.1.tar.gz
# 解压
tar -zxvf nginx-1.22.1.tar.gz
# 创建配置目录
mkdir ~/program/nginx-1.22.1
# 预编译,一般只需要配置 --prefix,其他的可选安装
./configure --prefix=/home/ac_cluster/program/nginx-1.22.1 --with-http_stub_status_module --with-http_ssl_module --with-http_realip_module --with-stream --with-http_auth_request_module
# 编译安装
make && make install
# 配置环境
vim ~/.bash_profile
# 添加下面的配置
export NGINX_HOME=/home/ac_cluster/program/nginx-1.22.1
export PATH=$PATH:$NGINX_HOME/sbin
# 刷新
source ~/.bash_profile
# 启动,启动报错查看下方解决方案
nginx

4.10 Node 安装
- 下载相关包并上传
# 使用 wget 下载
wget https://nodejs.org/dist/v17.9.1/node-v17.9.1-linux-arm64.tar.gz
# 解压
tar -zxvf node-v17.9.1-linux-arm64.tar.gz -C ../program/
# 配置环境变量
vim ~/.bash_profile
# 添加下面的配置
export NODE_HOME=/home/ac_cluster/program/node-v17.9.1-linux-arm64
export PATH=$PATH:$NODE_HOME/bin
# 刷新
source ~/.bash_profile
# 查看版本
node -v
npm -v
# 安装淘宝镜像
npm install -g cnpm --registry=https://registry.npm.taobao.org
# 查看
cnpm -v
# 安装 vue-cli 脚手架
cnpm install -g vue-cli
# 查看
vue -V

4.11 Doris 安装
持续更新中~~~
五、问题解决
5.1 环境配置错误,丢失命令
- 添加临时命令
export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
5.2 start-yarn.sh 无法启动 resourcemanager
- 查看日志报错 java.net.BindException: Port in use: hybrid02:8088
- 解决:进入 resourcemanager 部署的节点进行启动
- start-yarn.sh
5.3 mysql 远程连接报错 Public Key Retrieval is not allowed
- 我使用的是 DBeaver,在驱动属性里面修改配置为 true 即可

5.4 Flink 提交任务报错 classloader.check-leaked-classloader
Exception in thread “Thread-5” java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration ‘classloader.check-leaked-classloader’.

- 解决
- 编辑在 flink 目录 conf 下的 flink-conf.yaml
- 添加:classloader.check-leaked-classloader: false
- 编辑在 flink 目录 conf 下的 flink-conf.yaml
5.5 Kafka 启动报错 UseG1GC
VM option ‘UseG1GC’ is experimental and must be enabled via -XX:+UnlockExperimentalVMOptions
![]()
- 解决
- 进入 Kafka 安装目录下的 bin 目录,修改 kafka-run-class.sh,删除下图中的配置,重新启动

5.6 Nginx 启动报错 Permission denied
nginx: [emerg] bind() to 0.0.0.0:80 failed (13: Permission denied)
sudo: nginx:找不到命令

- 普通用户启动 Nginx 没有权限启动 80 端口,sudo 后找不到命令
- 解决方案:直接去到目录下使用 sudo 启动
- sudo sbin/nginx
- 解决方案:直接去到目录下使用 sudo 启动
5.7 Nginx 403 Forbidden
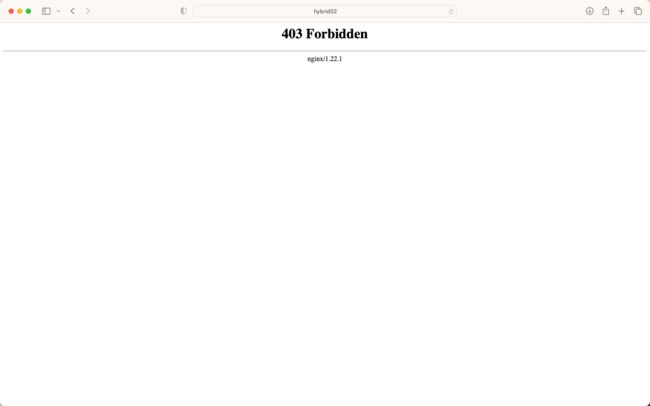 - 浏览器访问 nginx 的时候报 403
- 浏览器访问 nginx 的时候报 403
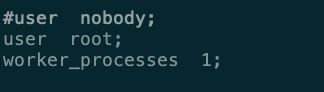
- 解决:修改 nginx.conf 配置文件,添加 user root 配置
- 保存后重新加载配置 sudo sbin/nginx -s reload
5.8 Node 报错 GLIBC_2.27 not found
node: /lib64/libm.so.6: version ‘GLIBC_2.27’ not found (required by node)
node: /lib64/libc.so.6: version ‘GLIBC_2.28’ not found (required by node)
…
- Node 18 版本之后 GLIBC 提高到了 2.28 or later
- 解决:降低 Node 版本或者提高 GLIBC 版本,推荐是降低 Node 版本到 17 版本,GLIBC 不好弄