【Python】librosa音频处理教程
Librosa简介
Librosa是一个 Python 模块,用于分析一般的音频信号,是一个非常强大的python语音信号处理的第三方库,根据网络资料以及官方教程,本文主要总结了一些重要且常用的功能。
# 安装
!pip install librosaLooking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: librosa in f:\programdata\anaconda3\envs\tf\lib\site-packages (0.8.1)
Requirement already satisfied: scikit-learn!=0.19.0,>=0.14.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (0.24.2)
Requirement already satisfied: joblib>=0.14 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (1.1.0)
Requirement already satisfied: packaging>=20.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (21.3)
Requirement already satisfied: numpy>=1.15.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (1.19.5)
Requirement already satisfied: pooch>=1.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (1.5.2)
Requirement already satisfied: decorator>=3.0.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (4.4.2)
Requirement already satisfied: audioread>=2.0.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (2.1.9)
Requirement already satisfied: resampy>=0.2.2 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (0.2.2)
Requirement already satisfied: scipy>=1.0.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (1.5.4)
Requirement already satisfied: soundfile>=0.10.2 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (0.10.3.post1)
Requirement already satisfied: numba>=0.43.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from librosa) (0.53.1)
Requirement already satisfied: setuptools in f:\programdata\anaconda3\envs\tf\lib\site-packages (from numba>=0.43.0->librosa) (58.0.4)
Requirement already satisfied: llvmlite<0.37,>=0.36.0rc1 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from numba>=0.43.0->librosa) (0.36.0)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from packaging>=20.0->librosa) (3.0.6)
Requirement already satisfied: appdirs in f:\programdata\anaconda3\envs\tf\lib\site-packages (from pooch>=1.0->librosa) (1.4.4)
Requirement already satisfied: requests in f:\programdata\anaconda3\envs\tf\lib\site-packages (from pooch>=1.0->librosa) (2.26.0)
Requirement already satisfied: six>=1.3 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from resampy>=0.2.2->librosa) (1.15.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from scikit-learn!=0.19.0,>=0.14.0->librosa) (3.0.0)
Requirement already satisfied: cffi>=1.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from soundfile>=0.10.2->librosa) (1.15.0)
Requirement already satisfied: pycparser in f:\programdata\anaconda3\envs\tf\lib\site-packages (from cffi>=1.0->soundfile>=0.10.2->librosa) (2.21)
Requirement already satisfied: certifi>=2017.4.17 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from requests->pooch>=1.0->librosa) (2021.5.30)
Requirement already satisfied: charset-normalizer~=2.0.0 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from requests->pooch>=1.0->librosa) (2.0.7)
Requirement already satisfied: idna<4,>=2.5 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from requests->pooch>=1.0->librosa) (3.3)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in f:\programdata\anaconda3\envs\tf\lib\site-packages (from requests->pooch>=1.0->librosa) (1.26.7)import numpy as np
import pandas as pd
import os
import IPython.display as ipd加载音频文件
import librosa
audio_data = 'data/Data_MGTV/angry/audio_1027.wav'
x , sr = librosa.load(audio_data)
print(x.shape, sr)(45159,) 22050xarray([-0.11979394, -0.10811259, -0.04991762, ..., 0.00769441,
0.00752225, 0. ], dtype=float32)print('x:', x, '\n')
print('x shape:', np.shape(x), '\n')
print('Sample Rate (KHz):', sr, '\n')
print('Check Len of Audio:', np.shape(x)[0]/sr)x: [-0.11979394 -0.10811259 -0.04991762 ... 0.00769441 0.00752225
0. ]
x shape: (45159,)
Sample Rate (KHz): 22050
Check Len of Audio: 2.048027210884354读取时长
d = librosa.get_duration(y=x, sr=22050, S=None, n_fft=2048, hop_length=512, center=True, filename=None)
d2.048027210884354采样率
sr = librosa.get_samplerate(audio_data)
sr16000去除两端沉默
audio_file, _ = librosa.effects.trim(x)
print('Audio File:', audio_file, '\n')
print('Audio File shape:', np.shape(audio_file))Audio File: [-0.11979394 -0.10811259 -0.04991762 ... 0.00769441 0.00752225
0. ]
Audio File shape: (45159,)播放音频
IPython.display.Audio 可以让我们直接在 jupyter notebook 中播放音频,比如下面包房一段音频
ipd.Audio(audio_data)波形图
在这里,我们绘制了一个简单的音频波形图。波图让我们知道给定时间的音频响度。
%matplotlib inlineimport sklearn
import matplotlib.pyplot as plt
import librosa.display
plt.figure(figsize=(20, 5))
librosa.display.waveplot(y, sr=sr)
plt.show()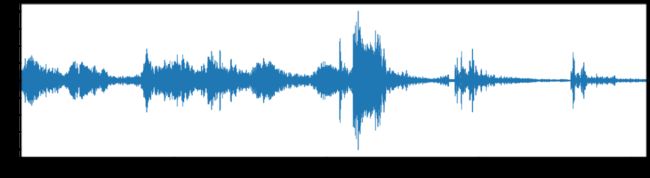
Spectogram
频谱图(Spectogram)是声音频率随时间变化的频谱的可视化表示,是给定音频信号的频率随时间变化的表示。'.stft' 将数据转换为短期傅里叶变换。STFT转换信号,以便我们可以知道给定时间给定频率的幅度。使用 STFT,我们可以确定音频信号在给定时间播放的各种频率的幅度。
Spectrogram特征是目前在语音识别和环境声音识别中很常用的一个特征,由于CNN在处理图像上展现了强大的能力,使得音频信号的频谱图特征的使用愈加广泛,甚至比MFCC使用的更多。
X = librosa.stft(x)
Xdb = librosa.amplitude_to_db(abs(X))
plt.figure(figsize=(20, 5))
librosa.display.specshow(Xdb, sr=sr, x_axis='time', y_axis='hz')
plt.colorbar()
plt.show()
librosa.display.specshow(Xdb, sr=sr, x_axis='time', y_axis='log')
plt.colorbar()
梅尔频率倒谱系数(MFCC)
信号的梅尔频率倒谱系数 (MFCC) 是一小组特征(通常约为 10-20),它们简明地描述了频谱包络的整体形状。在 MIR 中,它经常被用来描述音色。
#mcc
mfccs = librosa.feature.mfcc(y=x, sr=sr)mfccsarray([[-1.47507828e+02, -1.39587173e+02, -1.63085953e+02, ...,
-3.51147095e+02, -3.62041565e+02, -3.64722260e+02],
[ 1.39314545e+02, 1.28688156e+02, 1.26540642e+02, ...,
1.31368317e+02, 1.23287079e+02, 1.06071014e+02],
[-5.88899651e+01, -7.76861572e+01, -8.52756119e+01, ...,
-3.08440018e+01, -3.50476532e+01, -3.22384949e+01],
...,
[ 1.24901953e+01, 2.48859482e+01, 3.59340363e+01, ...,
-3.30873656e+00, -5.68462515e+00, -5.88594961e+00],
[-6.10755301e+00, -8.72181129e+00, -3.69202137e+00, ...,
-2.46745777e+00, -7.76338100e+00, -8.60360718e+00],
[-1.22752495e+01, -8.53678513e+00, -2.76085877e+00, ...,
6.47896719e+00, 9.00872326e+00, -3.04730564e-01]], dtype=float32)mfccs.shape(20, 89)在这个例子中,mfcc 在 89 帧中计算了 20 个 MFCC。
第一个 MFCC,第 0 个系数,不传达与频谱整体形状相关的信息。它只传达一个恒定的偏移量,即向整个频谱添加一个恒定值。因此,很多情况我们可以在进行分类时会丢弃第一个MFCC。
librosa.display.specshow(mfccs, sr=sr, x_axis='time')
过零率
过零率(zero-crossing rate,ZCR)是指一个信号的符号变化的比率,例如信号从正数变成负数,或反过来。这个特征已在语音识别和音乐信息检索领域得到广泛使用,是分类敲击声的关键特征。为真时为1,否则为0。在一些应用场景下,只统计“正向”或“负向”的变化,而不是所有的方向。
n0 = 7000
n1 = 7025
plt.figure(figsize=(14, 5))
plt.plot(x[n0:n1])
plt.show()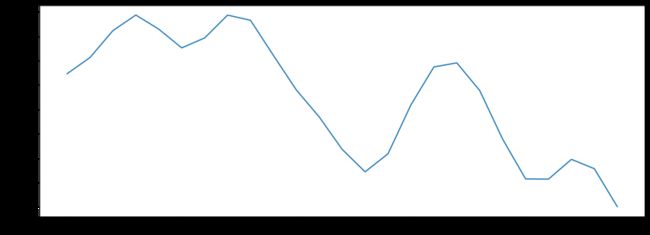
zero_crossings = librosa.zero_crossings(x[n0:n1], pad=False)zero_crossings.shape(25,)zero_crossings.sum()2可以使用整个音频来遍历这个并推断出整个数据的过零。
zcrs = librosa.feature.zero_crossing_rate(x)
print(zcrs.shape)(1, 89)plt.figure(figsize=(14, 5))
plt.plot(zcrs[0])[] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pakxb1Os-1651758177390)(https://mmbiz.qlogo.cn/mmbiz_png/1FD1x61uYVdHWBWhQKLKptH3N9aicoJkXTUxeNaFAgV1cWuKOZpkrWPNQYgZk6ibOXm0AE60DkOvCibLtEI0by0cQ/0)]
频谱质心:Spectral Centroid
频谱质心(维基百科)表示频谱能量集中在哪个频率上。这就像一个加权平均值:
其中 S(k) 是频段 k 处的频谱幅度,f(k) 是频段 k 处的频率。
spectral_centroids = librosa.feature.spectral_centroid(x, sr=sr)[0]
spectral_centroids.shape(89,)frames = range(len(spectral_centroids))
t = librosa.frames_to_time(frames)import sklearn
def normalize(x, axis=0):
return sklearn.preprocessing.minmax_scale(x, axis=axis)librosa.display.waveplot(x, sr=sr, alpha=0.4)
plt.plot(t, normalize(spectral_centroids), color='r')[] 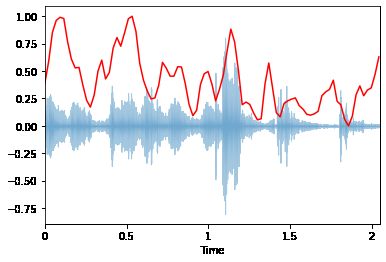
频谱带宽:Spectral Bandwidth
librosa.feature.spectral_bandwidth 可以用来计算p-order频谱带宽:
其中 S(k) 是频段 k 处的频谱幅度,f(k) 是频段 k 处的频率,fc 是频谱质心。当 p=2 时,这就像一个加权标准差。
spectral_bandwidth_2 = librosa.feature.spectral_bandwidth(x+0.01, sr=sr)[0]
spectral_bandwidth_3 = librosa.feature.spectral_bandwidth(x+0.01, sr=sr, p=3)[0]
spectral_bandwidth_4 = librosa.feature.spectral_bandwidth(x+0.01, sr=sr, p=4)[0]
librosa.display.waveplot(x, sr=sr, alpha=0.4)
plt.plot(t, normalize(spectral_bandwidth_2), color='r')
plt.plot(t, normalize(spectral_bandwidth_3), color='g')
plt.plot(t, normalize(spectral_bandwidth_4), color='y')
plt.legend(('p = 2', 'p = 3', 'p = 4'))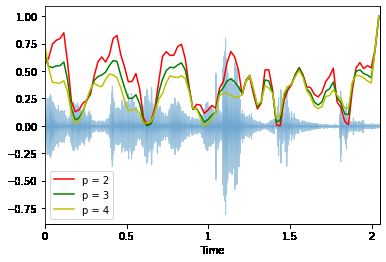
频谱滚降
频谱衰减是总频谱能量的特定百分比所在的频率。
spectral_rolloff = librosa.feature.spectral_rolloff(x+0.01, sr=sr)[0]
librosa.display.waveplot(x, sr=sr, alpha=0.4)
plt.plot(t, normalize(spectral_rolloff), color='r')[] 
色度特征:Chroma Feature
色度向量 (Wikipedia) 是一个典型的 12 元素特征向量,指示每个音高类别{C, C#, D, D#, E, ..., B}的能量是多少存在于信号中。
chromagram = librosa.feature.chroma_stft(x, sr=sr, hop_length=512)
plt.figure(figsize=(15, 5))
librosa.display.specshow(chromagram, x_axis='time', y_axis='chroma', hop_length=512, cmap='coolwarm')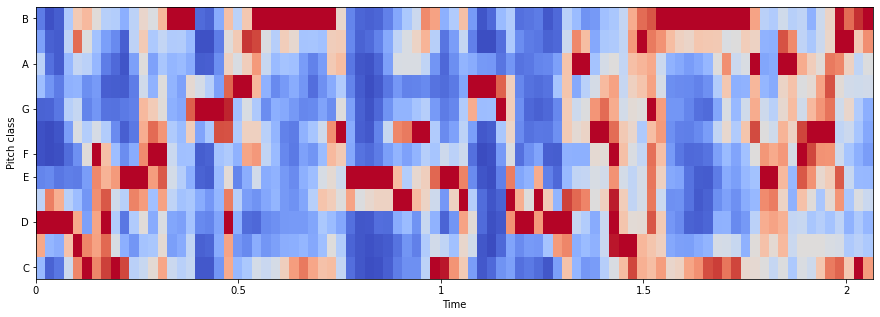
间距和幅度
音高是声音的感知属性,在与频率相关的尺度上排序,或者更常见的是,音高是可以判断声音在与音乐旋律相关的意义上“更高”和“更低”的质量。
pitches, magnitudes = librosa.piptrack(y=x, sr=sr)
print(pitches)[[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]]参考资料
librosa语音信号处理
语音信号处理库 ——Librosa
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码: