YOLOv5+DeepSort实现目标跟踪
本文将展示如何将YOLOv5和Deepsort相结合,实现目标跟踪计数等功能。由于水平有限,本文将更多着眼于如何实现,原理部分我会推荐几篇博客供大家学习参考。
原理介绍
推荐下面这篇博客,讲的很细致:
Yolov5_DeepSort_Pytorch代码学习与修改记录__helen_520的博客
YOLOv5具备目标检测的功能,把视频分解成多幅图像并逐帧执行时,如果视频帧中有多个目标,如何知道一帧中的目标和上一帧是同一个对象就是目标跟踪的工作。
DeepSort是实现目标跟踪的算法,从sort(simple online and realtime tracking)演变而来,使用卡尔曼滤波器预测所检测对象的运动轨迹,匈牙利算法将它们与新的检测目标相匹配。
两者相结合即可实现简单的目标跟踪功能。
准备工作
Deepsort源码下载
https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch.git
注意版本对应关系:
DeepSort v3.0 ~ YOLOv5 v5.0
DeepSort v4.0 ~ YOLOv5 v6.1
由于我之前演示用的代码是v5.0版本,所以应该下载DeepSort v3.0
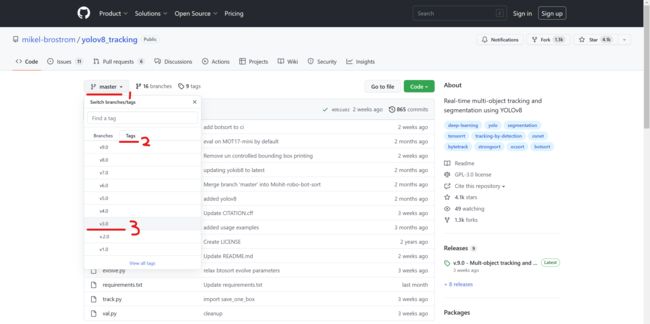
DeepSort v3.0
如果网不太好,可以用我分享的这个(一些必要的文件已经配好了):
链接:https://pan.baidu.com/s/1rZm1XgPDzpCAJc6JyY8PQQ
提取码:atld
环境配置
Deepsort所需要的环境和YOLOv5略有不同,因此更推荐大家用Anaconda新建一个环境,当然如果全部重新配置比较费时间,这里介绍一个偷懒的方法(环境配置大佬请跳过)。
打开Anaconda Prompt输入:
conda create -n XXX --clone yolo5这个操作是复制已有环境,XXX是复制得到的环境名称。不同的代码所需要库的版本有差异,为了避免冲突,可以通过这种方式得到一个镜像环境,对镜像环境进行删除库、安装库的操作就不会影响到之前的环境。

这是我复制得到的新环境
下面复习一下将环境导入pycharm的配置步骤,具体讲解可以看我之前写的一篇博客:
YOLOv5环境配置中的一些细节
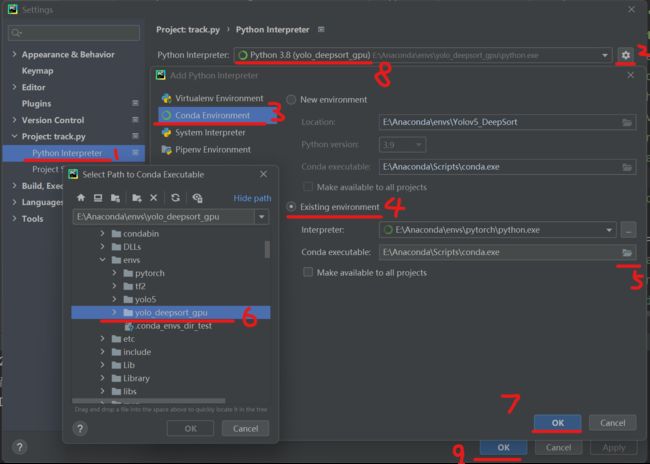
然后在终端输入下方命令,一键导入库即可。
pip install -r requirements.txt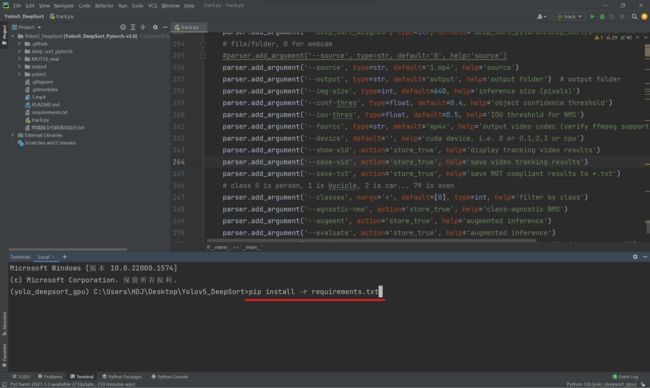
如果因为网络原因库安装失败,重复输入上述命令即可。当然在运行代码过程中,编译器也会提示有些库没有安装导致运行失败(No Module named XXX),在Anaconda Prompt中先激活环境,再把对应的库pip安装上即可。
放入目标检测工程
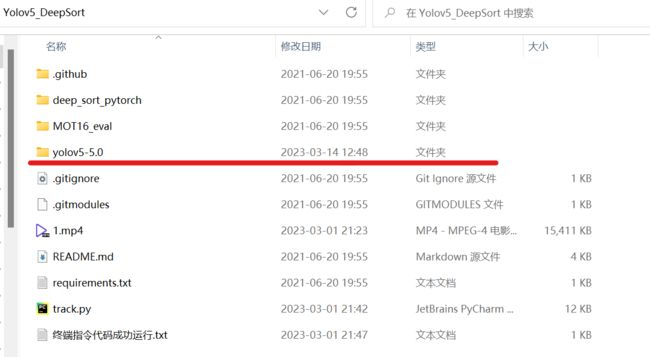
将之前的YOLOv5工程文件放入总工程文件夹中。为了贴合track.py中的源码,把yolo工程文件夹重命名一下,这样就不用在track.py中更改导入包的路径了(偷个懒)。

实现目标跟踪
更改参数路径
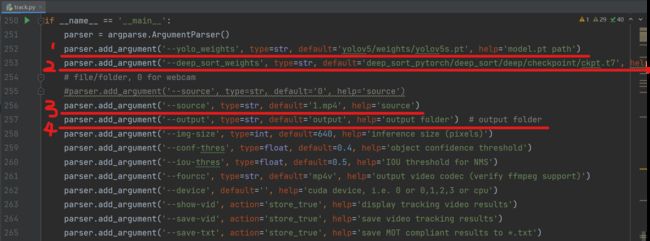
第一行是采用yolov5工程中的官方权重yolov5s.pt(注意,你的路径不一定和我一样,只要锁定到yolov5s.pt就行,当然可以把路径锁定到自己训练的权重)
第二行是调用deep_sort工程中的官方模型ckpt.t7(可以使用其他模型)
第三行是识别对象,这里识别视频1.mp4
第四行表示结果将会输出在output文件夹中
更改后track.py的参数设置如下
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--yolo_weights', type=str, default='yolov5/weights/yolov5s.pt', help='model.pt path')
parser.add_argument('--deep_sort_weights', type=str, default='deep_sort_pytorch/deep_sort/deep/checkpoint/ckpt.t7', help='ckpt.t7 path')
# file/folder, 0 for webcam
#parser.add_argument('--source', type=str, default='0', help='source')
parser.add_argument('--source', type=str, default='1.mp4', help='source')
parser.add_argument('--output', type=str, default='output', help='output folder') # output folder
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.4, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--fourcc', type=str, default='mp4v', help='output video codec (verify ffmpeg support)')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--show-vid', action='store_true', help='display tracking video results')
parser.add_argument('--save-vid', action='store_true', help='save video tracking results')
parser.add_argument('--save-txt', action='store_true', help='save MOT compliant results to *.txt')
# class 0 is person, 1 is bycicle, 2 is car... 79 is oven
parser.add_argument('--classes', nargs='+', default=[0], type=int, help='filter by class')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--evaluate', action='store_true', help='augmented inference')
parser.add_argument("--config_deepsort", type=str, default="deep_sort_pytorch/configs/deep_sort.yaml")
args = parser.parse_args()
args.img_size = check_img_size(args.img_size)
with torch.no_grad():
detect(args)运行
在终端中输入下方命令
python track.py --source 1.mp4 --save-vid --yolo_weights yolov5/weights/yolov5s.pt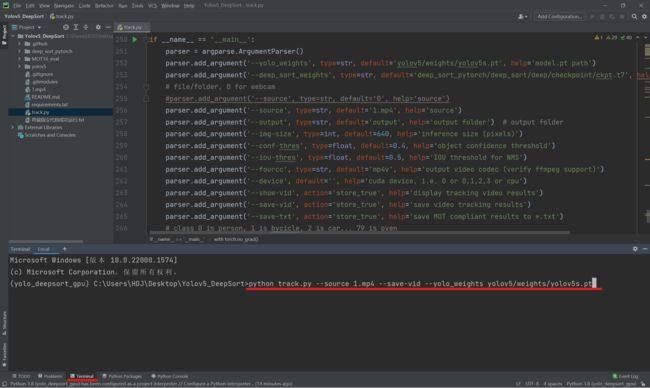
运行结束后会在track.py同级目录下生成output文件夹,里面是识别完成的视频。
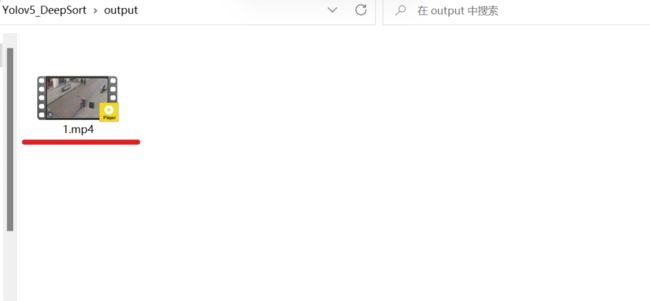
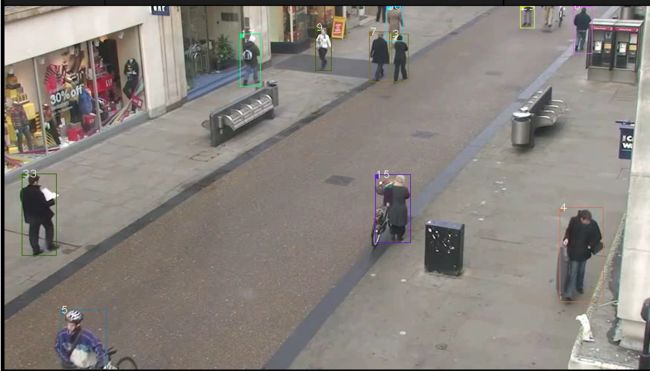
效果
也可以用下面的命令运行代码,这个命令会弹出窗口,显示识别标记的视频但运行会比较慢
python track.py --source 1.mp4 --show-vid --save-vid --yolo_weights yolov5/weights/yolov5s.pt调用摄像头进行实时目标追踪
运行下方命令即可,0表示电脑自带的摄像头。点击弹出的窗口,在英文小写状态下按键盘上的'q'即可保存检测视频,结果保存在output文件夹中。
python track.py --source 0 --show-vid --save-vid --yolo_weights yolov5/weights/yolov5s.pt也可以将“--source”的默认值换成其他数字调用连接的USB摄像头,或者换成局域网址调用IP摄像头。详细讲解可以看之前的博客:
使用YOLOv5实现多摄像头实时目标检测_yolov5多目标检测_Albert_yeager的博客
YOLOv5调用IP摄像头_Albert_yeager的博客
求学路上,你我共勉(๑•̀ㅂ•́)و✧