基于Anaconda的pandas学习
基于Anaconda的pandas学习
-
- Pandas安装
- 创建对象
-
- 创建Series对象
- 创建DataFrame对象
- 创建date_range
- 查看数据
- 获取数据
-
- 直接获取
- 索引获取
- 增删改数据
-
- 索引及缺失值操作
- 运算
- 字符串操作
Pandas安装
第一步:找到开始桌面下的anaconda下面的anaconda prompt!
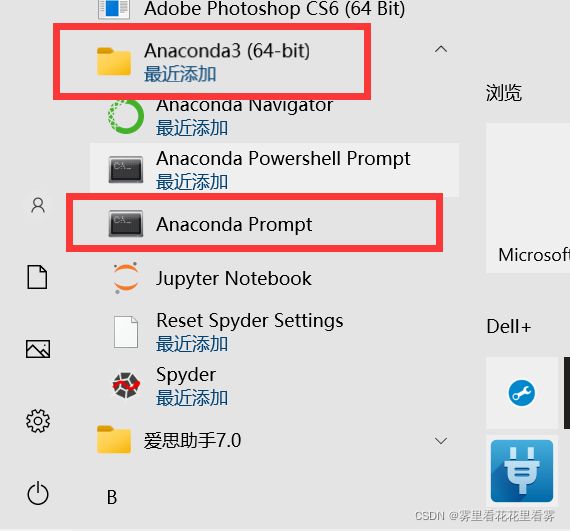
第二步:输入如下命令,如果提示你更新,那就去更新。
conda install pandas

创建对象
创建Series对象
import pandas as pd
# pandas基于numpy 故需要导入numpy
import numpy as np
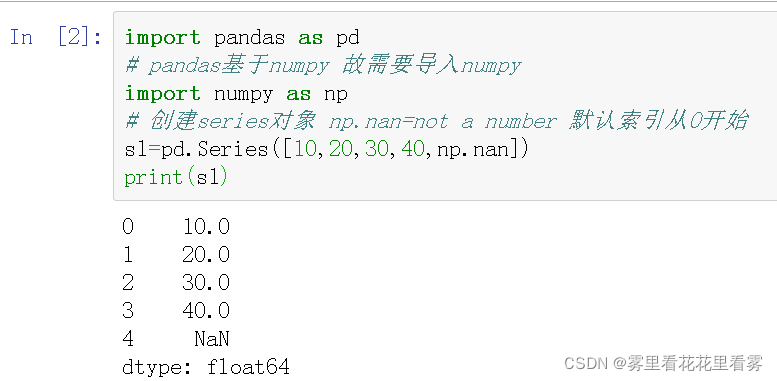
# 创建series对象 np.nan=not a number 默认索引从0开始
s1=pd.Series([10,20,30,40,np.nan])
print(s1)
查看相关数据:

当然也可以自己指定索引!在Series函数中传入参数index=list(‘abcde’)试试!


创建DataFrame对象
方法一:传入数据
# series是一维 dataframe是二维
df1=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]])
print(df1)


方法二:传入数据和参数
# series是一维 dataframe是二维
df1=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],index=list('abc'),columns=list('ABC'))
print(df1)


方法三:用字典方式创建(其为列索引奥)
# series是一维 dataframe是二维
df1=pd.DataFrame({'a':[1,2,3],'b':[2,4,6],'c':[3,6,9]})
print(df1)


如果想要改变行索引,则传入相应参数即可!
# series是一维 dataframe是二维
df1=pd.DataFrame({'a':[1,2,3],'b':[2,4,6],'c':[3,6,9]},index=list('ABC'))
print(df1)


创建date_range
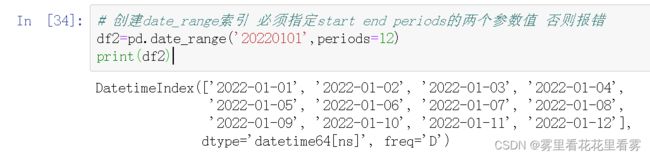
# 创建date_range索引 必须指定start end periods的两个参数值 否则报错
df2=pd.date_range('20220101',periods=12)
print(df2)
加入频率:D表示天 M表示月
# 创建date_range索引 必须指定start end periods的两个参数值 否则报错
df2=pd.date_range('20220101',periods=12,freq='3D')
print(df2)

查看数据
df3=pd.DataFrame(np.random.randint(1,20,(12,5)),index=df2,columns=['小白菜','竹笋','鱼籽烧','紫薯球','鸡翅'])
# 如果直接print可能对不齐 这里使用display自带表格
display(df3)

如果数据太多,查看相关数据的方法!
# 查看头部数据 默认5条
df3.head()

# 查看尾部的数据 默认5条 可以传递参数
df3.tail(3)

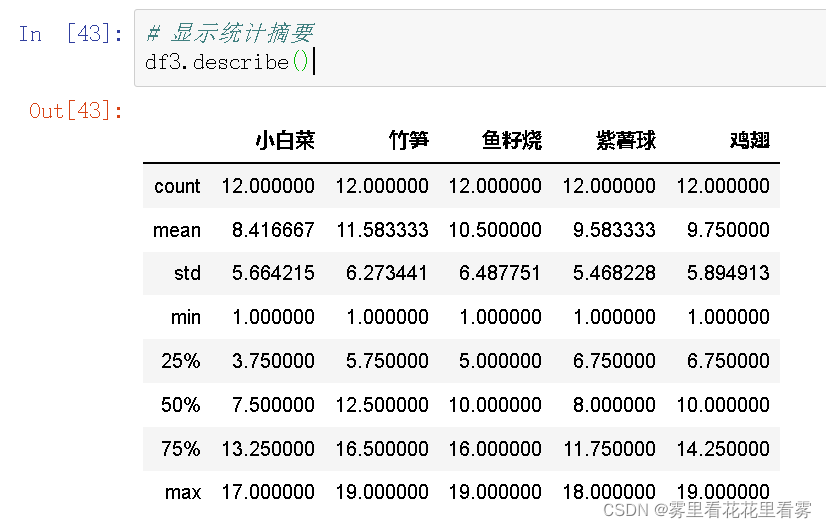
# 显示统计摘要
df3.describe()
# 插入数据 第一个参数是插入的列索引
df3.insert(len(df3.columns),'测试',list('abcdefghijkl'))

索引排序:
# sort_index(axis=0, ascending=True, inplace=False, by=None)
# axis:0按照行索引排序;1按照列索引排序
# ascending:默认True升序排列;False降序排列
# inplace:默认False,否则排序之后的数据直接替换原来的数据集
# by:按照某一列或几列数据进行排序,但是by参数官方不建议使用
# 案例:
df5 = pd.DataFrame({'b': [1, 2, 2, 3], 'a': [4, 3, 2, 1], 'c': [1, 3, 8, 2]}, index=[2, 0, 1, 3])
print(df5)
print('* ' * 30)
df6 = df5.sort_index()
# 默认axis=0, 行变列不变, 默认根据行索引升序
print(df6)

值排序:
# DataFrame.sort_values(by, axis=0, ascending=True, inplace=False)
# by参数:如果axis=0,by="列名"。如果axis=1,那么by="行名"。如果行或列的名称类型是数字则 by=数字
# 案例:
# df7 = df5.sort_values(by='c')
# 默认:ascending=True, axis=0
print(df5)
print('-'*20)
df7 = df5.sort_values(by=2, axis=1)
print(df7)

获取数据
直接获取
我们比较推荐最优化的pandas对数据进行处理,而不是python或者numpy。
例如.at, .iat, .loc, .iloc and .ix。
首先构造数据!
import pandas as pd
import numpy as np
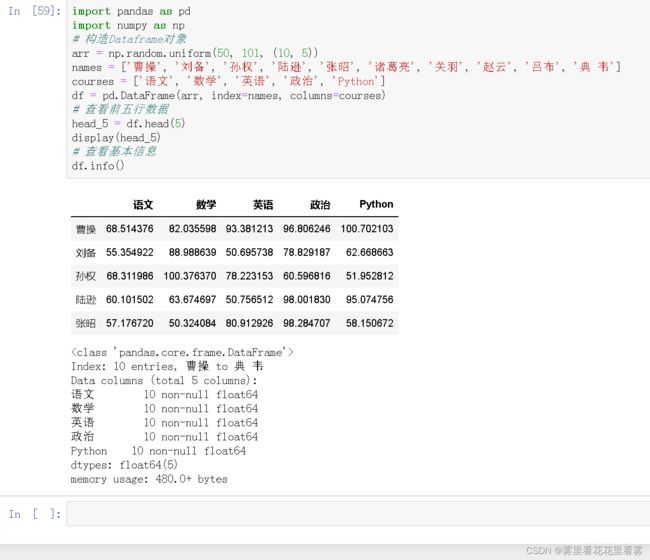
# 构造Dataframe对象
arr = np.random.uniform(50, 101, (10, 5))
names = ['曹操', '刘备', '孙权', '陆逊', '张昭', '诸葛亮', '关羽', '赵云', '吕布', '典 韦']
courses = ['语文', '数学', '英语', '政治', 'Python']
df = pd.DataFrame(arr, index=names, columns=courses)
# 查看前五行数据
head_5 = df.head(5)
display(head_5)
# 查看基本信息
df.info()
获取列数据:
# 查看df中某一列的数据
lang = df.语文
# 等同于df['语文']
print(type(lang))
#
print(lang)
# 可以通过df[['语文', '数学']]查看多列数据

获取行数据(切片):
# 查看一行或者连续多行数据 切片左包含右不包含
line = df[0: 1]
print(line)
print('*' * 30)
lines = df[1:3]
print(lines)

同时获取行列:
# 同时获取行和列
rows_cols = df[0:2][['语文', '数学', '英语']]
print(rows_cols)

索引获取
loc名称索引:使用索引名称作为参数来获取数据,有两个输入参数:
第一个参数指定行名,第二个指定列名。当只有一个参数时,默认是行名(即抽取整行),所有列都选中。(包含最后一个的)
行和列均是既可以用切片,又可以用列表(数组)。
# 1. df.loc[参数]获取一行,参数是index或者column的名称
line = df.loc['曹操']
print(type(line)) # print(line)
# 1.1 df.loc[参数]获取多行
lines = df.loc[['曹操', '吕布']]
print(lines)
# 1.2 df.loc[参数]获取多列,所有行的数据
lines = df.loc[:, ['语文', '英语']]
print(lines)
# 1.3 df.loc[参数]获取多列,多行的数据
lines = df.loc['曹操': '关羽', '数学': '政治': 2]
print(lines)
# loc的切片操作, 包含结束
# 1.4 df.loc[参数]获取多列,所有行的数据
lines = df.loc['曹操': '关羽', ::2]
print(lines)

iloc位置索引:使用位置索引(注意区分前面的名称索引)来获取!
iloc的切片操作, 不包含结束!!(试一下就知道啦!
# 2.df.iloc[参数]获取一行,参数是行或列索引的序号(数字)
line = df.iloc[0]
display(line)
# 2.1 df.iloc[参数]获取多行
lines = df.iloc[[0, -2]]
display(lines)
# 2.2 df.iloc[参数]获取多列,所有行的数据
lines = df.iloc[:, [0, 2]]
display(lines)
# 2.3 df.iloc[参数]获取多列,所有行的数据
lines = df.iloc[0: -3, 1: -1: 2]
display(lines)
# iloc的切片操作, 不包含结束

布尔索引:
# 一个条件
bools = df['Python'] > 70
print(bools)
df2 = df[bools]
# 布尔索引
print(df2)
df2 = df.loc[bools]
print(df2)
# 多个条件
# bools2 = (df['Python'] > 70) & (df['Python'] <= 85)
bools2 = (df['Python'] > 70) & (df['政治'] > 70)
print(bools2)
print(df[bools2])
# 满足条件后赋值
df.loc[df['Python'] > 70, 'Python'] = 85
print(df)
# 过滤数据 # 判断Python列的值是否包含[50, 51, 52]中任意一个
bools3 = df['Python'].isin([50, 51, 52])
print(bools3)
df2 = df.loc[bools3]
print(df2)

增删改数据
由于不断增删改,为了避免自己忘记了,可以动态获取行列索引值!
# 插入一列, 可以使arr, list, Series等。
arr = np.random.randint(50, 100, (10,))
# 列的索引位置:len(df.columns), 列名称:'Java', 列值:arr
df.insert(len(df.columns), 'Java', arr)
# 功能同下
# df['Java'] = arr
# 插入一行
df3 = pd.DataFrame(np.random.randint(50, 100, (1, 6)), columns=df.columns, index=['张飞'])
print(df3)
print('--' * 30)
df2 = df.append(df3)
print(df2)
# 删除指定的列
# df3 = df.drop('语文', axis=1)
# 删除列('语文')的时候需设置axis=1
df3 = df.drop(['Java', '语文'], axis=1)
# 删除多列
print(df3)
# 删除指定的行
df3 = df3.drop('曹操', axis=0)
# 删除行的时候需设置axis=0
print(df3)

索引及缺失值操作
reindex()方法用于创建一个符合新索引的新对象!
# 对于Series类型,调用reindex()会将数据按照新的索引进行排列,如果某个索引值之前不存在, 则引入缺失值
s1=pd.Series([1,7,3,9],index=['d','c','a','f'])
print(s1)
s2=s1.reindex(['a','b','c','d','e','f'])
print(s2)

# 对于DataFrame中,reindex()可以改变行索引和列索引
df = pd.DataFrame(np.arange(9).reshape((3, 3)), index=['a', 'c', 'd'], columns=['Ohio', 'Texas', 'California'])
print(df)
# 默认重建行索引
df2 = df.reindex(['a', 'b', 'c', 'd'])
print(df2)
# 可以使用columns关键字重建列索引
states = ['Texas', 'Utah', 'California']
df2.reindex(columns=states)

set_index()可以设置单索引和复合索引,调用这个函数会生成一个新的DataFrame, 新的df使用一个列或多个列作为索引。
df3=pd.DataFrame([['BAR','ONE','Z',1],['BAR','TWO','Y',2],['FOO','ONE','X',3],['FOO','TWO','W',3]],columns=list('abcd'))
display(df3)
# c这一列作为索引 如果不想原来的c删除 则添加drop参数
df4=df3.set_index('c',drop=False)
display(df4)

# 设置多列索引
df4 = df3.set_index(['a', 'b'])
print(df4)

reset_index(),它是set_index()的反操作,调用它分层索引的索引层级会被还原到列中。
df4.reset_index()

缺失值处理:缺失值占整体不太多,可以直接删除,如果很多,那就需要填充!
df = pd.DataFrame(np.arange(9).reshape((3, 3)), index=['a', 'c', 'd'], columns=['Ohio', 'Texas', 'California'])
df.iloc[-1] = np.nan
print(df)

注意在numpy和pandas中axis规则不同!
# 删除nan axis=0是删除行 axis=1是删除列
df4 = df.dropna(axis=0, how='all') # any:包含一个nan就删除了,all是所有值都是nan才删除
display(df4)

# 填充nan 一般填充不是随便填充 这里仅作演示
df.fillna(10, inplace=True) # inplace=True直接修改df3的值

运算
运算,一般不包括缺失值奥!

value_counts非常重要!
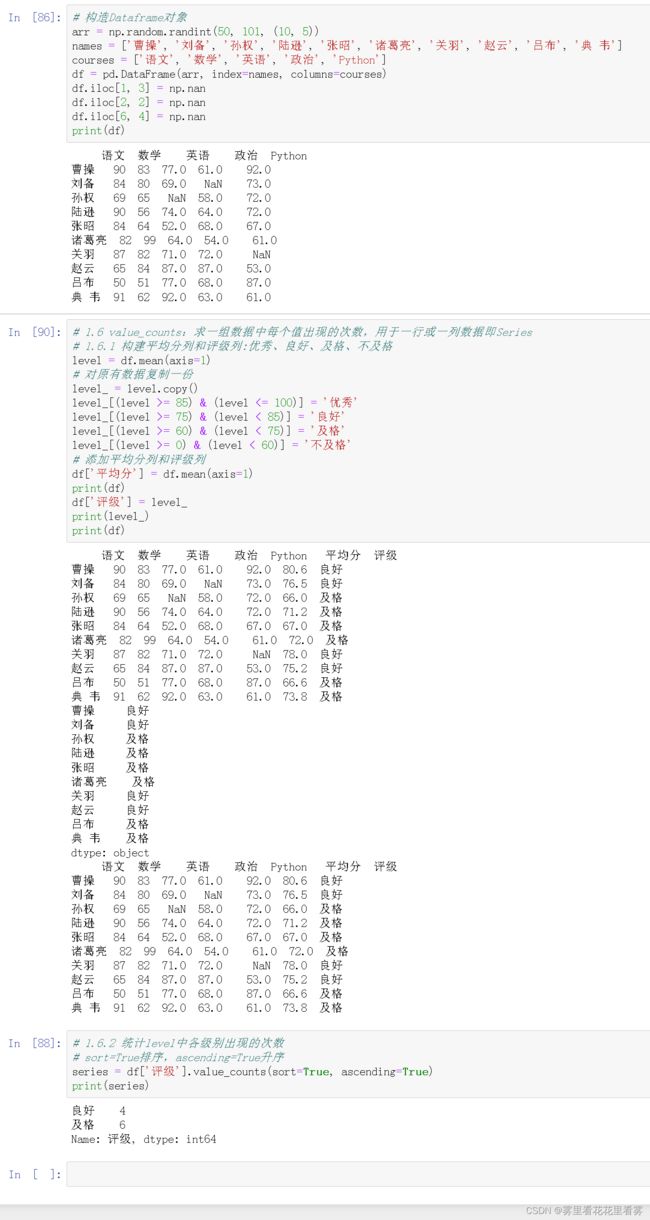
# 构造Dataframe对象
arr = np.random.randint(50, 101, (10, 5))
names = ['曹操', '刘备', '孙权', '陆逊', '张昭', '诸葛亮', '关羽', '赵云', '吕布', '典 韦']
courses = ['语文', '数学', '英语', '政治', 'Python']
df = pd.DataFrame(arr, index=names, columns=courses)
df.iloc[1, 3] = np.nan
df.iloc[2, 2] = np.nan
df.iloc[6, 4] = np.nan
print(df)
# 1.6 value_counts:求一组数据中每个值出现的次数,用于一行或一列数据即Series
# 1.6.1 构建平均分列和评级列:优秀、良好、及格、不及格
level = df.mean(axis=1)
# 对原有数据复制一份
level_ = level.copy()
level_[(level >= 85) & (level <= 100)] = '优秀'
level_[(level >= 75) & (level < 85)] = '良好'
level_[(level >= 60) & (level < 75)] = '及格'
level_[(level >= 0) & (level < 60)] = '不及格'
# 添加平均分列和评级列
df['平均分'] = df.mean(axis=1)
print(df)
df['评级'] = level_
print(level_)
print(df)
# 1.6.2 统计level中各级别出现的次数
# sort=True排序,ascending=True升序
series = df['评级'].value_counts(sort=True, ascending=True)
print(series)
字符串操作
df = pd.DataFrame({'movie_names': [' 复仇者联盟4:终局之战 \n\r', '\n\r阿凡达 Avatar', '泰坦尼克号 Titanic '], 'director': ['导演: 安东尼·罗素 / 乔·罗素', '詹姆斯·卡梅隆', '詹姆 斯·卡梅隆'], 'actor': ['小罗伯特·唐尼 / 克里斯·埃文斯 / 马克·鲁弗洛', '萨姆·沃辛 顿 / 佐伊·索尔达娜 / 西格妮·韦弗', '莱昂纳多·迪卡普里奥 / 凯特·温丝莱特 / 比利·赞恩'], 'type': ['剧情 / 动作 / 科幻 / 奇幻 / 冒险', '动作 / 科幻 / 冒险', '剧情 / 爱情 / 灾难']})
display(df)
print('*' * 40)

# 1. replace替换字符串
s = df['movie_names'].str.replace(r'\s+', '', regex=True)
# r'\s+'是否为正则表达式
df['movie_names'] = s
display(df)

# 2. split拆分字符串
s = df['type'].str.split('/')
display(s)

小测试:统计上述各类型出现次数!
types=[j for i in list(s) for j in i]
pd.Series(types).value_counts()
