城市道路路面病害检测识别分析,以RDD赛事捷克-印度-日本集成融合数据集为例,基于yolov5m模型开发构建城市道路病害检测识别系统
城市道路病害检测是最近比较热门的一个任务领域,核心就是迁移深度学习目前已有的研究成果来实现实时城市道路路面病害的检测识别分析,在我之前的很多博文中都有做过类似桥梁、大坝、基建、隧道等水泥设施裂缝裂痕等目标检测相关的项目,除此之外还有开发过相关城市路面病害检测的实践项目,链接如下,感兴趣的话可以自行移步阅读即可。
《水泥路面、桥梁基建、隧道裂痕裂缝检测数据集》
《助力交通出行,基于目标检测模型实现路面裂痕缺陷智能识别》
《基于DeepLabV3实践路面、桥梁、基建裂缝裂痕分割》
《助力路面智能巡检养护,基于YOLOv5开发轻量级路面缺陷智能检测系统》
《python基于融合SPD-Conv改进yolov5与原生yolov5模型实践路面裂痕裂缝检测》
《融合注意力模块SE基于轻量级yolov5s实践路面坑洼目标检测系统》
《基于yolov5s+bifpn实践隧道裂缝裂痕检测》
《基于YOLOV7的桥梁基建裂缝检测》
《python基于DeeplabV3Plus开发构建裂缝分割识别系统,并实现裂缝宽度计算测量》
《基于yolov5开发构建道路路面病害检测识别系统——以捷克、印度、日本三国城市道路实况场景数据为例,开发对比分析模型并分析对应性能》
本文主要是前文《基于yolov5开发构建道路路面病害检测识别系统——以捷克、印度、日本三国城市道路实况场景数据为例,开发对比分析模型并分析对应性能》的后续文章,前文则是以捷克、印度、日本三国独立场景的道路路面数据集为基准开发了轻量级的yolov5s系列的模型,并对三者进行了详细的性能指标对比分析与可视化。
本文主要是将三国城市道路场景的数据集进行整合汇总解析处理,之后基于yolov5m模型来尝试开发构建更具识别检测能力的检测模型,首先来看下效果图:
数据集是与前文一致的,只不过在开发完前文的项目后我发现这批数据集有相当一部分的都是空图,这里为了加快模型的开发效率,这里我去除了相关的空图数据,简单看下数据集:


可以清楚看到:经过数据处理后生下来14569张图像数据可用于后续模型的开发训练。
原始VOC格式标注数据文件如下:

经过处理后得到的YOLO格式的标注数据文件如下:

前后相减可以分析知:大概去除了7000左右的数据量。
融合汇总的数据集类别清单如下所示:
['D00', 'D01', 'D10', 'D11', 'D20', 'D40', 'D43', 'D44', 'D50']本文使用到的是m系列的模型,相对前文使用的s系列的模型来说精度更高,模型文件如下所示:
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 9 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# Backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# Head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
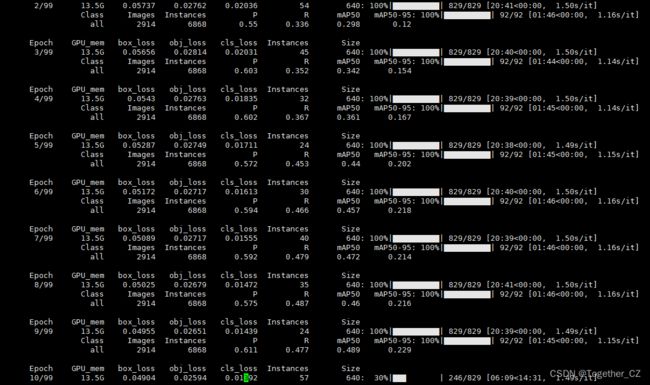
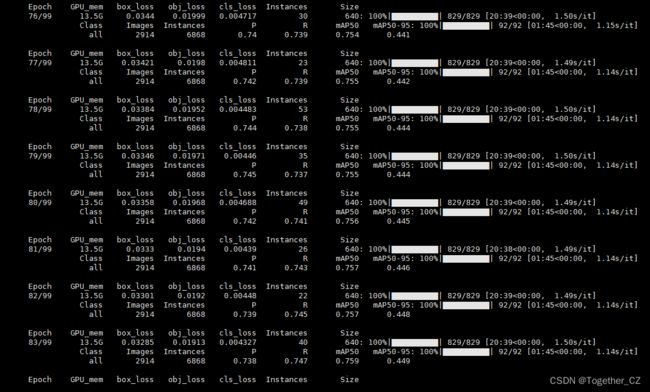
这里默认是100次的epoch训练计算,训练日志输出如下:

接下来看下结果详情数据:
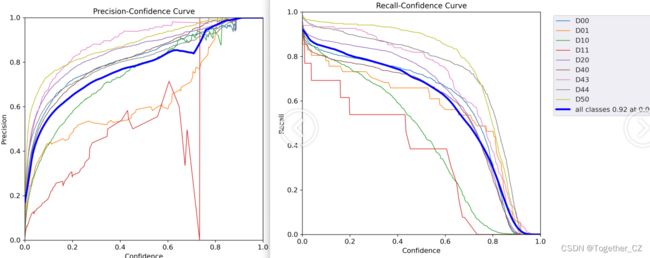
【精确率和召回率曲线】
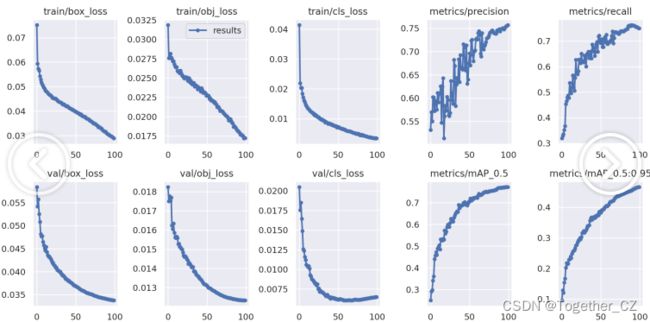
【训练可视化曲线】
【PR曲线和F1值曲线】

【类别标签可视化】
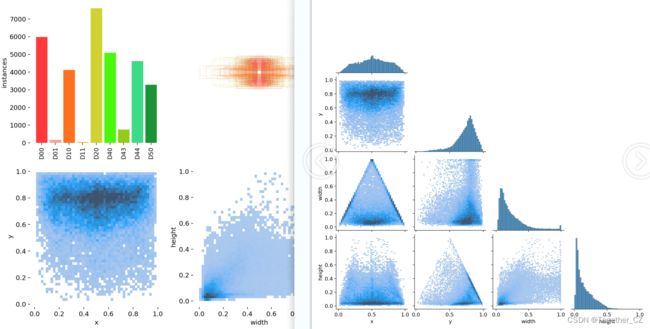
从上图的类别数据标签可视化中不难看出,其实这几个类别的数据是严重不均衡的。
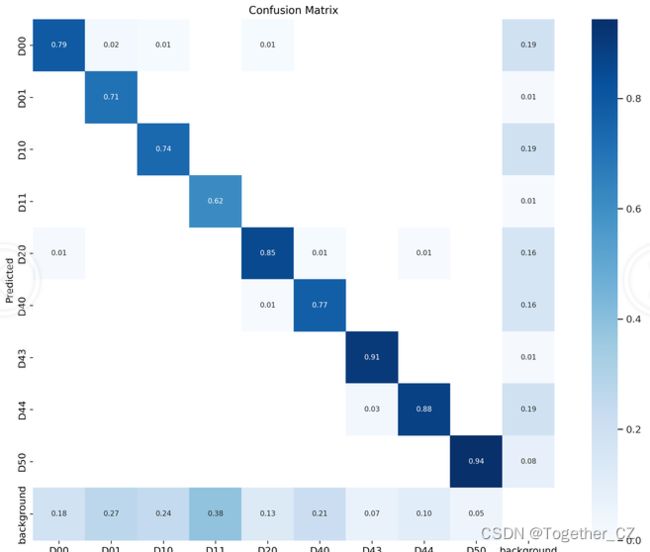
【混淆矩阵】
batch计算实例如下:

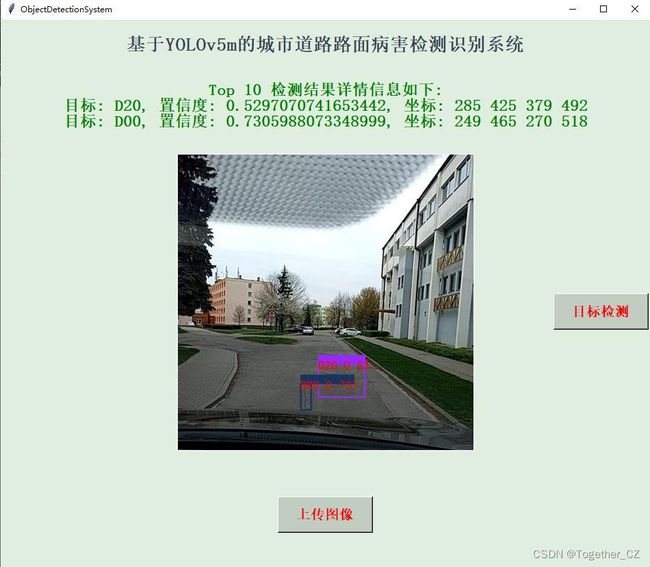
同样为了方便使用,这里依旧是实现了可视化推理应用,如下所示:
【捷克】
【印度阿三】
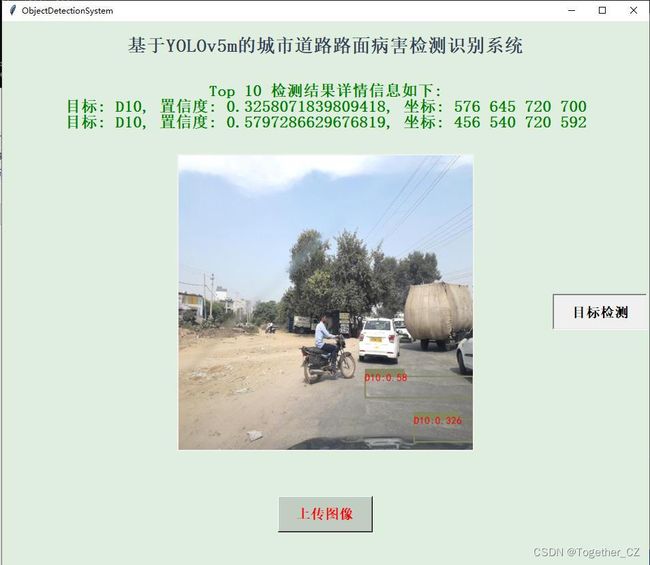
【小日子】

感兴趣的话也可以上手实操一下。