hadoop-深入理解MapReduce(一)-Job提交流程
1.Job提交
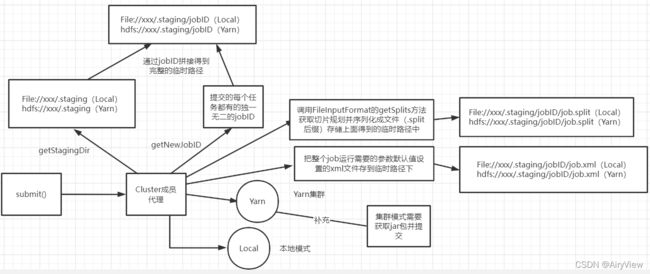
先图解大致流程,心里有大概框架。
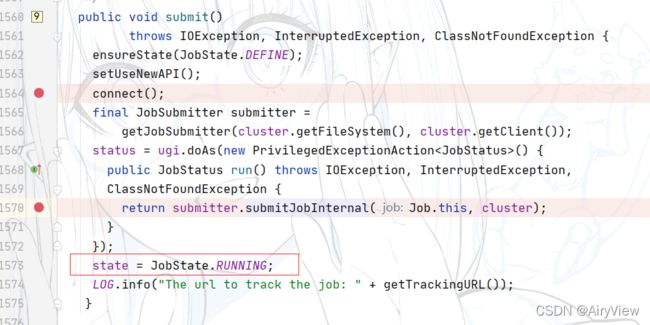
首先第一步进入waitForCompletion函数中的submit函数
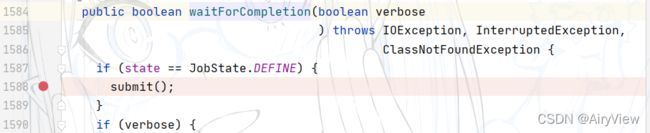
进入sumit函数,重点关注connect函数
 初始化
初始化

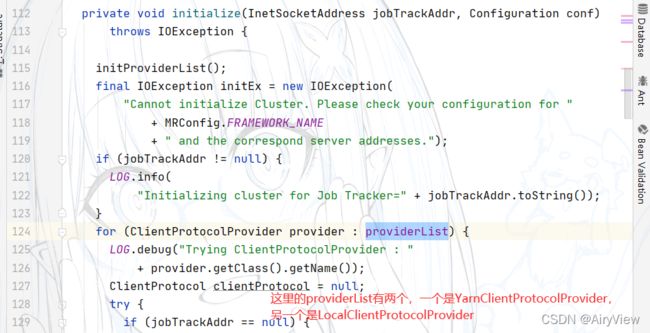
总结来说,上面过程就是建立连接,创建提交job的代理,判断是local还是yarn客户端
然后我们回到submit函数,继续看connect下面的部分
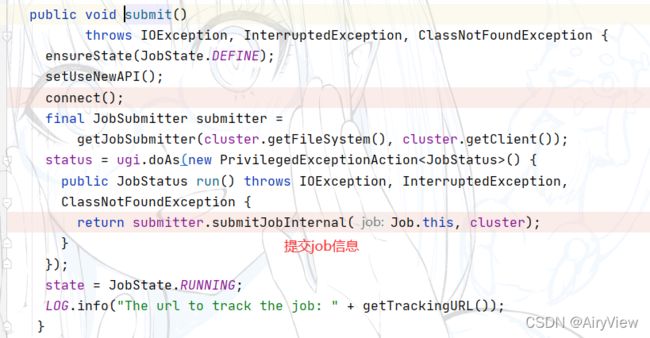
进入submitJobInternal函数 
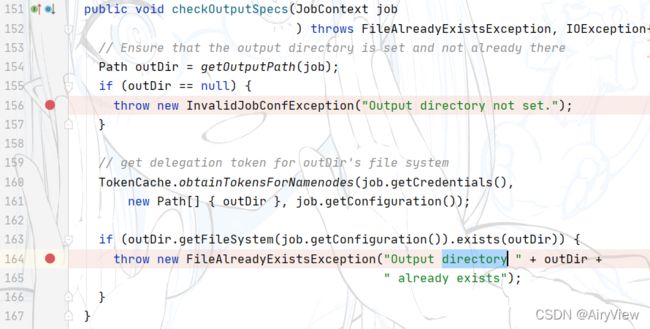
分析checkSpecs函数 ,检查输出路径是否有问题。

其中checkOutPutSecs函数是检查输出路径是否存在
接来下,我们就可以看到两个非常熟悉的异常,第一个就是输出没有设置,第二个是输出的目录已经存在了(hadoop不允许结果输出的文件夹存在)
分析完checkSpecs后,我们继续看getStagingDir函数
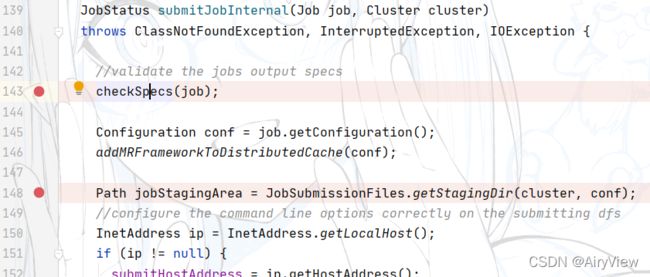
创建给集群提交数据的Stag临时路径,例如file:/tmp/hadoop/mapred/.staging,然后继续看getNewJobID

继续在上面提到的Stag临时路径下拼接上了jobId(假设为job_xxxxxx) ,也就是说现在的路径变成了file:/tmp/hadoop/mapred/.staging/job_xxxxxx。ps:但此时路径并没有真正创建出来,只是拼接好了。
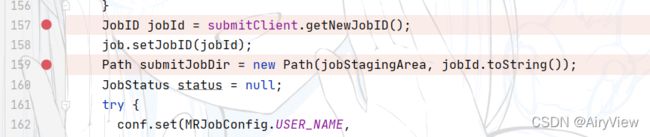
然后直接继续重点观察194行,中间30行对流程意义不大,先看copyAndConfigureFiles函数,从字面意思来看就拷贝和配置相关文件信息。

进入该函数,看到uploadResources函数,即上传一些信息,那么具体上传什么?
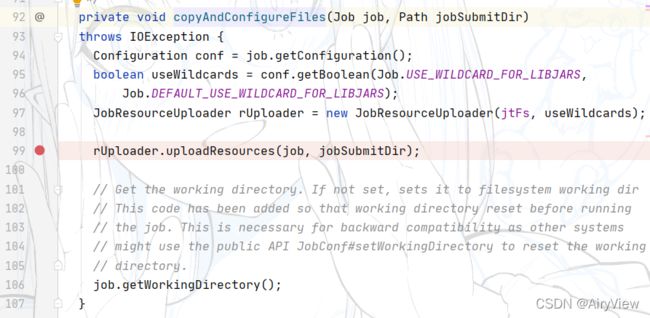
继续跟近uploadResourcesInternal函数

在uploadResourcesInternal函数中执行了下面mkdirs才表示我们所谓的file:/tmp/hadoop/mapred/.staging/job_xxxxxx路径被真正的创建了

继续往下看,关注upload前缀的函数

其中uploadJobJar函数表示在集群模式下当前代码jar包必须上传到集群,通过客户端提交给集群,如果是本地模式就不用该步骤提交jar了。
总结一下这个copyAndConfigurationFiles函数最主要的作用是创建了stag临时路径下拼接的jobid路径以及提交jar包(本地模式不需要提交jar包,集群模式会)

getJobConfPath函数就能顺理成章的得到路径了

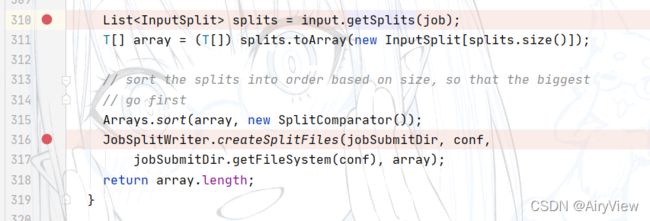
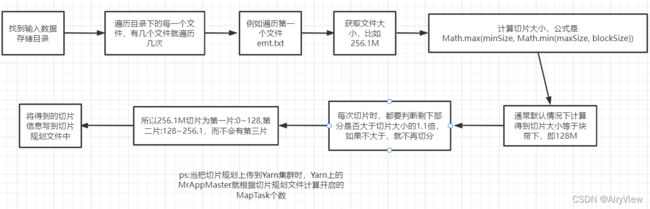
继续看到writeSplits函数(后面会单独重点分析该函数),切片,把切片得到的相关信息(主要是.split为后缀的文件和.crc循环冗余校验)存到临时路径file:/tmp/hadoop/mapred/.staging/job_xxxxxx下
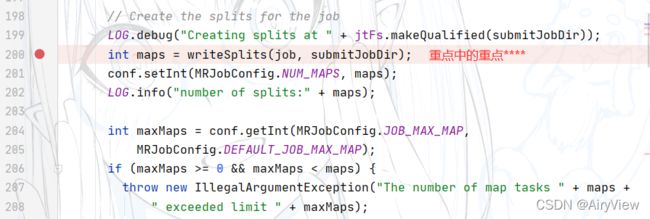
我们可以看到该函数得到的切片个数影响MapTask的个数。
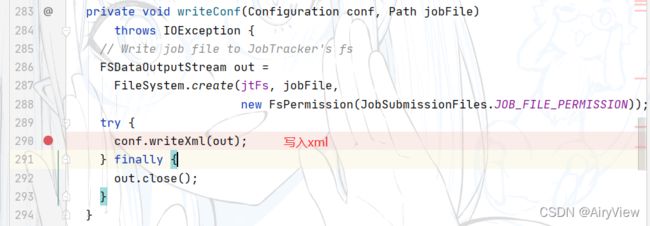
继续看writeConf函数, 把整个job运行需要的参数默认值设置的xml文件以及crc校验存在临时路径file:/tmp/hadoop/mapred/.staging/job_xxxxxx下

然后是客户端提交job信息 ,返回提交状态
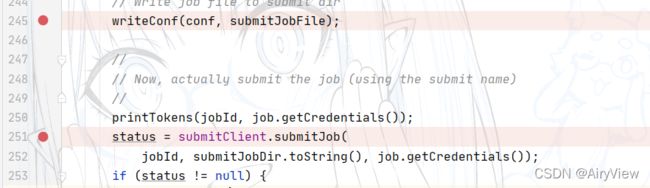
最后将状态从“DEFINE”置为RUNNING,结束submit函数。
1.1writeSplits
还是老规矩,先图解大致流程,心里有个底
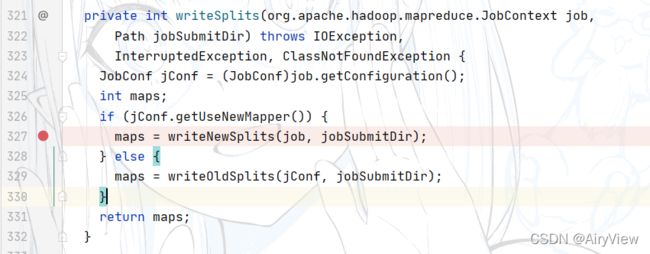
承接上文,进入writeSplits函数,很显然我们使用的是新api,所以是writeNewSplits函数
先重点深入getSplits函数
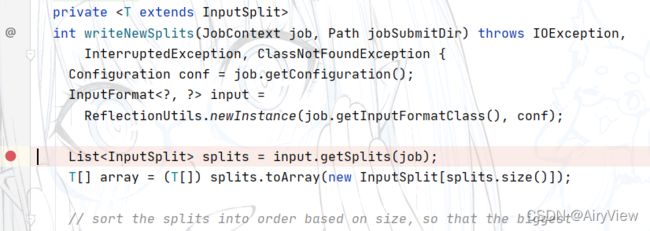
其实getSplits是InputFormat的抽象方法,InputFormat有许多子类

我们这里主要以FileInputFormat来分析源码。
先看下图红线标注的

首先要知道getFormatMinSplitSize()的结果是1

然后看getMinSplitSize函数

其中SPLIT_MINSIZE由如下配置决定,默认配置值是0

那么最后0和1取最大结果minSize为1
继续看maxSize

进入getMaxSplitSize函数

观察SPLIT_MAXSIZE由如下配置值决定
![]()
该参数没有默认配置,所以正常情况就找不到,就返回getMaxSplitSize函数就得到 Long.MAX_VALUE
继续遍历每个文件(这里也说明有多个文件时是按照每个文件单独切片,而不是总和加起来划分切片),我们这里分析源码的时候假设只有一个文件
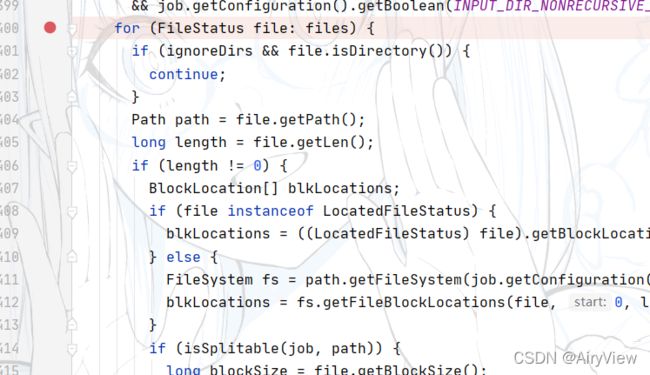
判断文件是否允许切片(比如一些压缩算法压缩的文件不允许切片),然后getBlockSize获取块大小,块大小在本地模式下是32M,集群模式、企业环境下对应的设置块大小可能都不同,有128M和256M的。
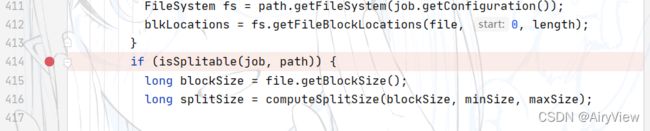
对于得到切片大小的computeSplitSize函数必须掌握,非常重要,如下:

对于这三个参数我们前面已经分析清楚了,minSize为1,maxSize为Long.MAX_VALUE,blockSize为块大小32M,所以先去Long.MAX_VALUE和32M的最小值得到32M,在取与1的最大值得到32M,此时得到的切片大小与块大小相等。由于块大小是不能随便改变的,那么如何改变切片大小呢?
①减小maxSize,比如设置成28,那么最后结果是28M,这样用于减小切片大小。
②扩大minSize,比如设置成64,那么最后结果是64M,这样用于扩大切片大小。
下面这一段是根据切片大小切片的核心逻辑,很重要
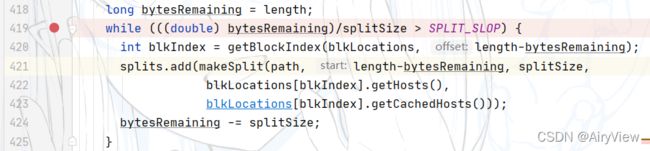
其中我们发现SPLIT_SLOP为1.1
![]()
也就是说当前剩余的量不大于切片大小的1.1陪,那么剩余部分就不切片了,直接按一片处理,即使该片可能比切片大小要大。就比如说切片大小32M,虽然32.1M大于32M,但是32.1M就没必要切成两片了。
以FileInputFormat为例分析完getSplits函数后,继续看什么时候把切片文件放入临时路径xxxx/.staging/job_xxxxxx中呢?即执行完createSplitFiles函数。