论文笔记--Training language models to follow instructions with human feedback
论文笔记--Training language models to follow instructions with human feedback
- 1. 文章简介
- 2. 文章导读
-
- 2.1 概括
- 2.2 文章重点技术
-
- 2.2.1 Supervised Fine-Tune(SFT)
- 2.2.2 Reward Model(RM)
- 2.2.3 Reinforcement Learning(RL)
- 3. 文章亮点
- 4. 原文传送门
- 5. References
1. 文章简介
- 标题:Training language models to follow instructions with human feedback
- 作者:Ouyang L, Wu J, Jiang X, et al.
- 日期:2022
- 期刊:NIPS
2. 文章导读
2.1 概括
文章给出了一种基于人类指令对大语言模型进行调整的方法。在人类标注的数据上对GPT-3进行微调,并通过人类打分的数据对上述模型进行强化学习,从而得到一个满足人类偏好的语言模型。文章的整体架构是ChatGPT的前身,相较于GPT-3,回答真实性更高,且危害信息更少。
文章的整体架构如下
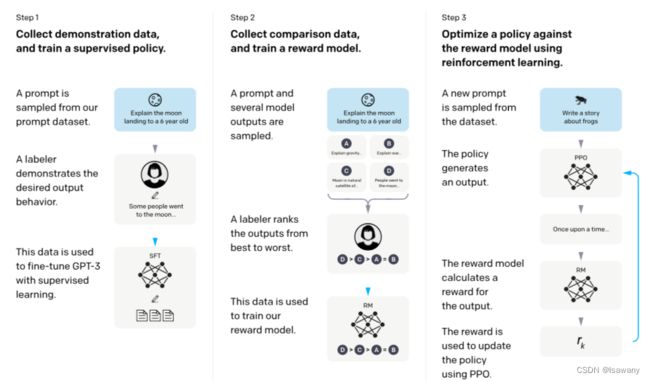
2.2 文章重点技术
2.2.1 Supervised Fine-Tune(SFT)
文章架构中的第一部分Step1采用了SFT方法。为此,文章首先雇用了一些标记员对prompt数据进行回答,称为labeler demonstrations,然后在demonstrations上面对GPT-3进行有监督的微调。微调后的模型我们记作SFT。
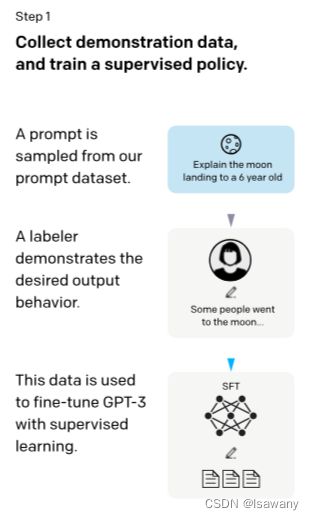
Prompt数据集通过如下方式构建:从OpenAI的Playground API(非生产环境)上面获取用户提交的prompt,其中保证使用每个用户的prompt数量不超过200条,并过滤敏感信息和重复信息(通过长的公共前缀过滤),然后按照user ID划分train, test, val。另外由于API的prompts的多样性较为单一,我们让我们的标记员自己写一些如下类别的prompts以初始化模型:
- Plain: 标记员写任意任务的prompts,保证任务的多样性
- Few-shot:标记员提出一个指令和该指令的多个问答对(Few-shot learning中的prompt)
- User-based:标记员根据OpenAI的API的waitlist(用户希望OpenAI未来的突破)上面的用例提出合适的prompts,从而将用户期望的功能放入prompts。
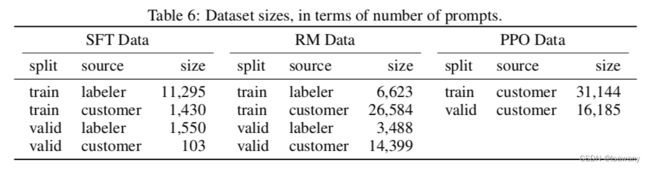
prompts 数据在不同阶段的训练配比如下表所示。当前的SFT阶段大部分数据为labeler自己写的prompts。
2.2.2 Reward Model(RM)
接下来我们训练一个RM打分模型,为此首先需要一个评分的数据集。OpenAI 构建了一个用户打分的UI,如下图所示。首先上述的SFT模型会对每个prompt生成 K K K个候选答案( 4 ≤ K ≤ 9 4\le K \le 9 4≤K≤9),用户会对每个答案打分,并对所有答案进行排序。页面的示例如下图所示。为了避免模型overfit且保证训练效率,模型训练时按照prompt对数据集划分,即保证每个prompt的所有 ( K 2 ) \tbinom K2 (2K)答案对在同一个batch。
RM模型根据上述打分数据进行训练,具体训练方案如下图。损失函数为 l o s s ( θ ) = − 1 ( K 2 ) E ( x , y w , y l ) ∼ D [ log ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ] loss(\theta) = -\frac 1{\tbinom K2} E_{(x, y_w, y_l)\sim D} [\log (\sigma (r_{\theta} (x, y_w) - r_{\theta} (x, y_l) )] loss(θ)=−(2K)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl))],其中 r θ ( x , y ) r_{\theta} (x, y) rθ(x,y)为当前训练的RM模型的输出, x , y x, y x,y分别为prompt及其对应的回答, y w y_w yw为 y w , y l y_w, y_l yw,yl中更受用户喜爱的回答(ranking更高的)。训练的目的为使得loss尽可能小,即另每个 ( r θ ( x , y w ) − r θ ( x , y l ) ) (r_{\theta} (x, y_w) - r_{\theta} (x, y_l) ) (rθ(x,yw)−rθ(x,yl))尽可能大,即保证模型对 y w y_w yw打分高于 y l y_l yl越多越好。

2.2.3 Reinforcement Learning(RL)
接下来,我们用SFT模型预测每个prompt,并用RW预测人类偏好(rankings),再通过RL方法更新SFT的参数。文章在Stiennon[1]的工作基础上增加了PPO梯度,从而保证模型不损失原始GPT-3的回归性能。具体的目标函数为 o b j e c t i v e ( ϕ ) = E ( x , y ) ∈ D π ϕ [ r θ ( x , y ) − β log ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) ] + γ E x ∼ D p r e t r a i n [ log ( π ϕ R L ( x ) ) ] objective(\phi) = E_{(x, y) \in D_{\pi_\phi}}[r_{\theta}(x, y) - \beta\log(\pi_\phi^{RL}(y|x)/\pi^{SFT}(y|x))] + \gamma E_{x\sim D_{pretrain}} [\log (\pi_\phi^{RL}(x))] objective(ϕ)=E(x,y)∈Dπϕ[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain[log(πϕRL(x))],其中 π ϕ R L \pi_\phi^{RL} πϕRL为当前学习的RL策略的输出, π S F T \pi^{SFT} πSFT为SFT模型的输出, D p r e t r a i n D_{pretrain} Dpretrain为预训练模型GPT-3的分布, β \beta β表示KL奖励系数用于控制KL惩罚项, γ \gamma γ表示预训练模型损失系数用于控制预训练模型的梯度更新。RL训练的具体方案如下图
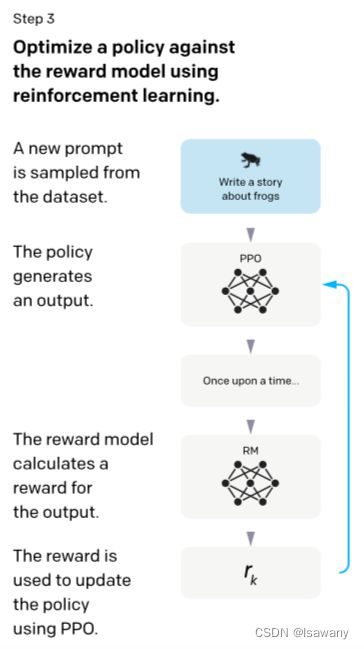
3. 文章亮点
文章在GPT-3的基础上,通过有监督的微调SFT和基于人类反馈的模型训练RM,得到了一个更符合人类偏好的大语言模型。文章的重点突破为采用RL方法增强了模型的可信度,降低模型输出危害回答的概率。InstructGPT是ChatGPT的前身,是Chat GPT面世必不可少的一步。
4. 原文传送门
Training language models to follow instructions with human feedback
5. References
[1] Learning to summarize from human feedback
[2] GPT-3原文:Language Models are Few-Shot Learners
[3] GPT-3论文笔记