【基于PyTorch实现经典网络架构的花卉图像分类模型】
基于PyTorch实现经典网络架构的花卉图像分类模型,看完秒懂!
- 摘要
- 1.Flowers-102数据集解读
- 2.数据预处理工作
-
- 2.1 导入工具包
- 2.2 数据增强策略(Data Augmentation)
- 2.3 数据读入
-
- 2.3.1 训练集与验证集读入
- 2.3.2 json文件读入
- 3.模型的建立与训练
-
- 3.1 迁移学习
-
- 3.1.1 微调(fine-tuning)
- 3.2 转换为GPU调用模式
- 3.3 准备工作
- 3.4 训练模块
- 3.5 全训练模型
- 4. 展示预测结果
摘要
近年来,深度学习技术在图像分类领域得到了广泛应用。其中,卷积神经网络(CNN)是目前最常用的深度学习模型之一。在CNN的基础上,出现了很多经典的网络架构,如LeNet、AlexNet、VGG、ResNet等。这些网络架构在不同的任务中取得了很好的效果,成为了研究者和工程师们解决实际问题的有力工具。
花卉图像分类是一个常见的计算机视觉任务。在这个任务中,我们需要将不同种类的花卉图像分为不同的类别。为了解决这个问题,我们可以使用深度学习技术,尤其是CNN。本文将介绍如何基于PyTorch实现经典网络架构的花卉图像分类模型。我们将以ResNet网络为例,介绍如何搭建、训练和测试一个ResNet网络模型,以及如何在实际应用中使用该模型。
1.Flowers-102数据集解读
102花卉分类数据集是一个用于花卉图像分类的广泛使用的计算机视觉数据集,该数据集包含8189张花卉图像,分为train和valid两个文件夹,此外还有一个cat_to_name.json文件。
如下图,train文件夹包含了6552张用于训练的花卉图像,这些图像被分为102个不同的类别,每个类别都有相应的子文件夹。valid文件夹包含了818张花卉图像,同样分为102个类别,用于验证和评估模型的性能。(关注博主,私聊免费领取数据集和源代码!)

每张图像都以JPG格式存储,并且具有不同的分辨率和大小。

train和valid文件夹中的图像为模型的输入,图像所属子文件夹名称即为图像对应的标签。训练阶段,模型会读取train文件夹中的图像并根据标签进行训练。

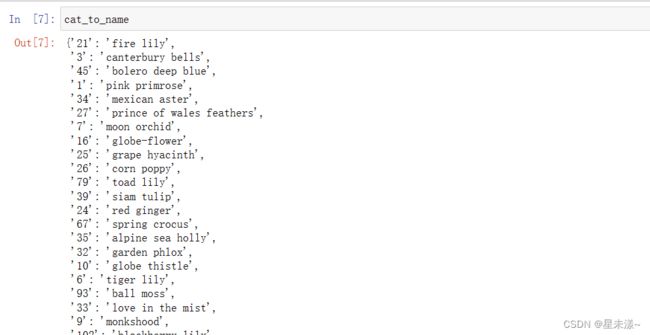
cat_to_name.json文件可以帮我们找到每个类别的名称和对应的索引值。该文件提供了一个字典结构,使得我们可以通过类别的索引值快速地查找到类别的名称。
2.数据预处理工作
2.1 导入工具包
我们需要导入下列工具包:
| 模块 | 作用 |
|---|---|
| torch | PyTorch深度学习框架的主要包 |
| transforms | 提供了一些常用的图像变换方法,例如缩放、裁剪、旋转、翻转、归一化 |
| datasets | 提供了常用的数据集 |
| models | 提供了一些常用的深度神经网络模型 |
| json | 处理JSON数据 |
| os | 提供了一些与操作系统交互的函数,例如文件夹的创建、删除、重命名、遍历等,以及文件的读写、权限设置、进程管理等 |
| copy | copy模块提供了一些对象复制的函数 |
| numpy | 科学计算的基础库 |
| pandas | 数据分析库 |
| matplotlib | 绘图库 |
| warnings | 忽略警告信息 |
代码如下:
# import tools
import torch
from torchvision import transforms,datasets,models
import torch.optim as optim
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
import warnings
warnings.filterwarnings('ignore')
import time
import json
import copy
2.2 数据增强策略(Data Augmentation)
处理时,发现102花卉数据集有个问题,即存在数据集较小和数据不平衡,对此采用数据增强策略
数据增强策略是指通过对现有数据集进行各种变换和扩充,生成新的、更加丰富的数据集的技术。数据增强技术在深度学习中被广泛应用,尤其是在数据集较小或数据不平衡的情况下,通过数据增强可以提高模型的性能和泛化能力。
数据增强策略有以下优点:
- 提高数据集的多样性:数据增强技术可以通过生成各种变换和扩充的图像,增加数据集的多样性。这将帮助深度学习模型更好地理解数据集中的花卉图像,并提高模型的性能和泛化能力。
- 预防过拟合:使用数据增强技术可以避免模型在训练过程中出现过拟合的问题。过拟合是指模型在训练集上表现良好,但在测试集上表现较差的情况。过拟合通常发生在训练集较小或训练集与测试集分布不一致的情况下,而使用数据增强技术可以通过扩充数据集,使训练数据更加丰富,从而预防过拟合。
- 提高模型的性能:使用数据增强技术可以通过扩充数据集,提高模型的性能。通常情况下,数据集越大,模型的性能越好,而使用数据增强技术可以增加数据集的大小和多样性,从而提高模型的性能。
- 帮助模型更好地适应实际场景:使用数据增强技术可以生成更加接近实际场景的图像。例如,在101花卉数据集中,通过对花朵图像进行旋转、翻转、缩放等操作,可以生成更加真实的花朵图像,从而帮助深度学习模型更好地适应实际场景。
定义了一个data_transform字典,对102花卉数据集进行图像旋转、缩放、剪裁、翻转、改变图片的亮度、标准化等操作。
注:旋转、剪裁、翻转等操作仅针对训练集,而对验证集仅保留缩放、ToTensor、标准化操作。代码如下:
# perprocessing
data_transform = {
'train':transforms.Compose([
# 将照片大小进行统一化处理
transforms.Resize([96,96]),
# 将图片进行随机旋转
transforms.RandomRotation(45),
# 将图片裁至指定大小
transforms.CenterCrop(64),
# 随机垂直或者水平旋转,p为概率值
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
# 改变图片的亮度、对比度、饱和度、色相
transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),
# 转换为Tensor格式
transforms.ToTensor(),
# 标准化
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差
]),
'valid':transforms.Compose([
transforms.Resize([64,64]),
# 无需对图片进行旋转、调亮度等操作
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
2.3 数据读入
2.3.1 训练集与验证集读入
首先创建一个数据集字典(image_datasets),其中包含了训练集和验证集。数据集采用了图像文件夹(ImageFolder)的形式,可以自动地将文件夹中的图片转换为Tensor,并且将文件夹名称作为图片的标签。其中,root参数指定了数据集的根目录,os.path.join()函数将根目录与训练集或验证集目录拼接成完整路径。transform参数指定了对图片进行的数据增强操作,通过data_transform[x]获取了’train’或’valid’对应的增强操作。最终,将训练集和验证集以字典的形式保存到了image_datasets中。
接着,通过torch.utils.data.DataLoader函数创建了一个包含训练集和验证集数据的dataloader字典,可以方便地用于训练模型。batch_size参数指定了每个batch中的样本数,shuffle参数表示在每个epoch中是否随机打乱数据集。
最后,通过len()函数获取了训练集和验证集的数据长度,classname则包含了训练集中所有类别的名称。
# 数据读入
batch_size = 128
image_datasets = {x: datasets.ImageFolder(root=os.path.join(data_dir,x),transform=data_transform[x]) for x in ['train','valid']}
# 创建dataloader字典,里面包含train和test
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size,shuffle=True) for x in ['train','valid']}
# 获得数据的长度与class信息
datasize = {x: len(image_datasets[x]) for x in ['train','valid']}
classname = image_datasets['train'].classes
其中,ImageFolder默认采用文件夹名作为label值
所得image_datasets 如图:

2.3.2 json文件读入
代码如下:
# cat to name
with open('cat_to_name.json','r') as f:
cat_to_name = json.load(f)
3.模型的建立与训练
3.1 迁移学习
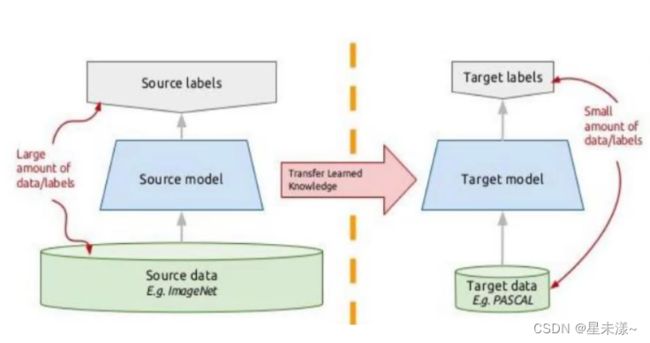
迁移学习是指通过将已经在一个任务上训练好的模型应用于另一个相关任务上,以提高模型在新任务上的性能。通常情况下,迁移学习是因为在新任务上没有足够的数据训练新模型,或者是新任务与已有模型的任务相似度较高,因此可以通过将已有模型中的一部分或全部参数进行微调来适应新任务的需求。
迁移学习的方式主要分为两种:一是基于 特征的迁移学习,二是 基于模型的迁移学习。基于特征的迁移学习是指使用已经在一个任务上训练好的模型提取出的特征来训练新模型,例如使用已经在ImageNet数据集上预训练好的模型来提取图片的特征,再将这些特征用于新任务的训练。而基于模型的迁移学习则是指直接使用已有模型在新任务上进行微调,例如只调整模型的最后几层来适应新任务的特征。
迁移学习的好处在于可以节省大量的时间和资源,因为使用预训练好的模型可以避免从零开始训练模型,从而大大缩短了模型的训练时间。此外,预训练模型通常已经学习到了较为通用的特征,因此可以帮助模型更好地适应新任务的需求,从而提高模型的准确率。因此,迁移学习已经成为了机器学习领域的一个重要研究方向,被广泛应用于图像识别、自然语言处理等领域。
3.1.1 微调(fine-tuning)
微调(fine-tuning)是迁移学习中的一种常见方法,它可以利用预训练模型已经学习到的通用特征来快速地训练出一个新的分类器。在微调中,我们通常会选择一些已经在大规模数据集上进行预训练的模型,比如本文所用ResNet18。然后,我们可以将这些模型中的前面各层的权重参数锁住,只改变全连接层的权重参数。由于预训练模型已经在大规模数据集上进行了训练,并且学到了对图像的有用的特征,因此我们可以把这些特征当做通用的特征提取器,然后用新的任务去训练全连接层。
微调的好处是可以利用预训练模型学习到的通用特征,快速地训练出一个新的分类器,而不需要从头开始训练一个新的深度神经网络。这样可以节省大量的时间和计算资源。此外,预训练模型还可以有效地缓解数据集较小的问题,因为它们已经在大规模数据集上进行了训练,并且学到了通用的图像特征,可以很好地泛化到新的数据集上。
还是一样,先看代码:
# Change to output layer of the pretraining model
def set_requires_grad(model,feature_extract):
if feature_extract:
for param in model.parameters():
param.requires_grad = False
- param.requires_grad = False的作用是将一个参数的 requires_grad 属性设置为 False,这意味着这个参数在反向传播时不会被更新梯度。
def revised_model(feature_extract,num_class,use_pretrained_model=True):
model_self = models.resnet18(pretrained=use_pretrained_model)
set_requires_grad(model_self,feature_extract)
num_in_feat = model_self.fc.in_features
model_self.fc = torch.nn.Linear(in_features=num_in_feat,out_features=num_class)
input_size = 64
return model_self,input_size
- 首先,我们获取预训练模型的最后一层全连接层的输入特征数量(即in_features)。然后,我们使用torch.nn.Linear函数,将最后一层的输入特征数量num_in_feat和我们想要的输出类别数num_class作为参数,创建一个新的全连接层,并替换掉原来的全连接层。这样,我们就可以将预训练模型用于新的分类任务,只需要训练最后一层的权重,而不需要改变其他层的权重。
3.2 转换为GPU调用模式
CPU/GPU模式转换见博客:https://blog.csdn.net/fly_ddaa/article/details/129999425
# Set the GPU conputing mode
train_on_GPU = torch.cuda.is_available()
if not train_on_GPU:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
3.3 准备工作
此外,还需对模型进行微调的准备工作,包括优化器设置、学习率衰减策略、损失值计算和保存文件。
# 优化器设置
optimizer_fit = optim.Adam(param_to_train,lr=1e-2)
# 学习率衰减策略
scheduler = optim.lr_scheduler.StepLR(optimizer_fit,step_size=10,gamma=0.1)
# 损失值计算
loss_of_model = torch.nn.CrossEntropyLoss()
# 保存文件
filename = 'best.pt'
代码中使用了Adam优化器,并设置了学习率为0.01,只对需要微调的参数进行优化。学习率衰减策略使用了StepLR方法,每10个epoch将学习率降低到原来的0.1倍。
损失值计算使用了交叉熵损失函数。
最后,代码设置了一个文件名,用于保存训练过程中表现最好的模型权重。
3.4 训练模块
定义一个训练神经网络模型的函数。输入神经网络模型、数据加载器、优化器、学习率调度器、损失函数、文件名和训练的轮数等参数。
- 函数首先将模型移动到GPU上,然后循环训练数据集,计算每个epoch的训练和验证损失和准确率,并保存最佳的模型和准确率。最后,函数返回训练后的模型和相关的训练数据和验证数据的历史记录,例如训练和验证损失、训练和验证准确率以及学习率等。
def train_model(model,dataloader,optimizer_fit,scheduler,loss_of_model,filename,num_epoch=25):
# to GPU
model.to(device)
since = time.time()
train_loss = []
valid_loss = []
val_acc_history = []
train_acc_history = []
best_accuracy = 0
best_model_dict = copy.deepcopy(model.state_dict())
LRs = [optimizer_fit.param_groups[0]['lr']]
for epoch in range(num_epoch):
print('epoch {}/{}'.format(epoch,num_epoch-1))
print('-'*10)
for stage in ['train','valid']:
if stage == 'train':
model.train()
elif stage == 'valid':
model.eval()
running_loss = 0.0
running_correct = 0
for inputs,labels in dataloaders[stage]:
# data to GPU
inputs = inputs.to(device)
labels = labels.to(device)
# 清零
optimizer_fit.zero_grad()
outputs = model(inputs)
loss = loss_of_model(outputs,labels)
_,pred = torch.max(outputs,1)
if stage == 'train':
loss.backward()
optimizer_fit.step()
running_loss = running_loss + loss.item()*inputs.size(0)
running_correct = running_correct + torch.sum( pred == labels.data)
epoch_loss = running_loss/len(dataloaders[stage].dataset)
epoch_accuracy = running_correct.double()/len(dataloaders[stage].dataset)
time_elapsed = time.time() - since#一个epoch我浪费了多少时间
print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Stage-{},Loss-{},Accuracy-{}'.format(stage,epoch_loss,epoch_accuracy))
if stage == 'valid' and epoch_accuracy > best_accuracy:
best_accuracy = epoch_accuracy
best_model_dict = copy.deepcopy(model.state_dict())
state = {
'state_dict':best_model_dict,
'best_accuracy':best_accuracy,
'optimizer':optimizer_fit.state_dict()
}
torch.save(state,filename)
if stage == 'valid':
val_acc_history.append(epoch_accuracy)
valid_loss.append(epoch_loss)
scheduler.step(epoch_loss)#学习率衰减
if stage == 'train':
train_acc_history.append(epoch_accuracy)
train_loss.append(epoch_loss)
print('Optimizer learning rate:{:.7f}'.format(optimizer_fit.param_groups[0]['lr']))
scheduler.step()
return model, val_acc_history, train_acc_history, valid_loss, train_loss, LRs
- 开始训练!
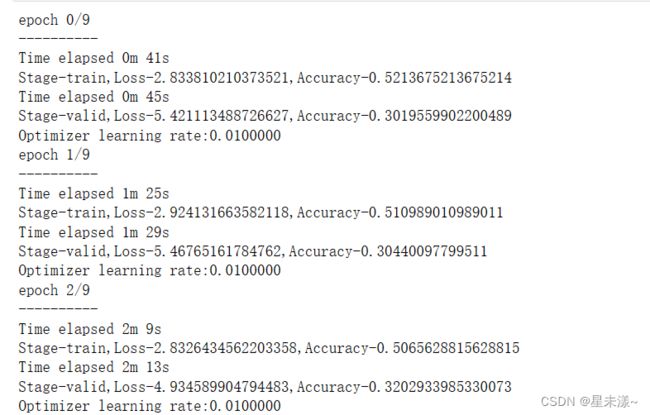
model, val_acc_history, train_acc_history, valid_loss, train_loss, LRs = train_model(model_resnet,dataloaders,optimizer_fit,scheduler,loss_of_model,filename,num_epoch=10)
部分输出结果如下:
3.5 全训练模型
当我们完成了模型的微调之后,我们会希望看到模型的准确率和损失值都有明显的提高。但是,有时候我们会发现微调后的模型并没有达到我们的期望,准确率和损失值仍然比较高,这时候我们就需要考虑进一步优化模型。
针对这种情况,我们可以尝试对模型的所有层进行训练,而不仅仅是微调最后几层。这个过程通常被称为“全模型训练”。
for param in model.parameters():
param.requires_grad == True
optimizer = optim.Adam(model.parameters(),lr=1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
loss_of_model = torch.nn.CrossEntropyLoss()
- 读取已训练最好一次epoch参数
checkpoint = torch.load(filename)
best_accuracy = checkpoint['best_accuracy']
model.load_state_dict(checkpoint['state_dict'])
- 继续训练
model, val_acc_history, train_acc_history, valid_loss, train_loss, LRs = train_model(model,dataloaders,optimizer,scheduler,loss_of_model,filename,num_epoch=10)
输出结果如下:
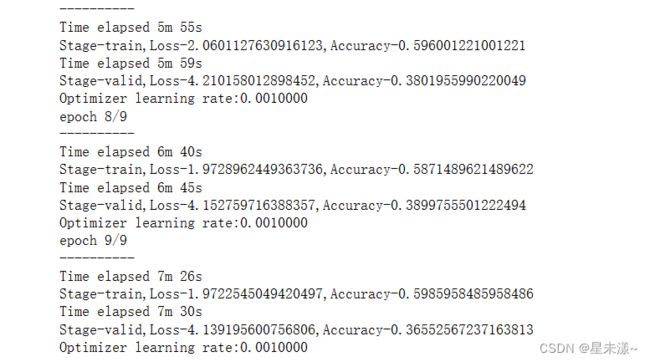
验证集上的准确率得到了提高!
4. 展示预测结果
定义一个将PyTorch张量转换为可视化图像的函数
def im_convert(tensor):
""" 展示数据"""
image = tensor.to("cpu").clone().detach()
image = image.numpy().squeeze()
image = image.transpose(1,2,0)
image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))
image = image.clip(0, 1)
return image
最后,来看下结果吧。

!!关注博主后,可私聊免费领取源代码和数据集哦!