论文笔记:NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction
文章目录
- idea概述
- SDF与渲染之间如何建立联系?
-
- 渲染的数学表述
- 为什么需要更精妙的加权函数?
- 为什么直接使用naive solution是不行的?
- 因此做了什么样的改进?
- 如何做离散化?
- 小结
- 训练
-
- 损失函数
- 分层采样
- 实验
-
- 实验设置
- 数据集
- baseline
- 实现细节
- 结果对比
- 分析
- 结论

论文名称: NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction
作者单位: 港大 & 马普所 & Texas A&M
发表年份: 2021
idea概述
如何连接SDF网络与NeRF,使其得到更好的重建效果?
我们不妨使用下式对物体表面进行数学表达:
S = { x ∈ R 3 ∣ f ( x ) = 0 } \mathcal{S}=\left\{\mathbf{x} \in \mathbb{R}^{3} \mid f(\mathbf{x})=0\right\} S={x∈R3∣f(x)=0}
其中, x \mathbf{x} x表示三维点, f ( x ) f(\mathbf{x}) f(x)表示从三维点到SDF值的映射关系。
为了能够在SDF网络的训练与volume rendering之间建立联系,首先引入一个概率密度函数: ϕ s ( f ( x ) ) \phi_{s}(f(\mathbf{x})) ϕs(f(x)),将其命名为S-density,且有:
ϕ s ( x ) = s e − s x / ( 1 + e − s x ) 2 \phi_{s}(x)=s e^{-s x} /\left(1+e^{-s x}\right)^{2} ϕs(x)=se−sx/(1+e−sx)2
实际上,这就是著名的逻辑斯蒂概率密度分布函数,同时也是sigmoid函数的导数形式:
Φ s ( x ) = ( 1 + e − s x ) − 1 , i.e., ϕ s ( x ) = Φ s ′ ( x ) \Phi_{s}(x)=\left(1+e^{-s x}\right)^{-1} \text {, i.e., } \phi_{s}(x)=\Phi_{s}^{\prime}(x) Φs(x)=(1+e−sx)−1, i.e., ϕs(x)=Φs′(x)
选择逻辑斯蒂概率密度分布函数的原因是:计算简单。
ϕ s \phi_{s} ϕs的标准差为 1 / s 1/s 1/s,我们不妨令其作为可训练的参数,那么根据梯度下降的原则来看,当 1 / s 1/s 1/s趋向于0的时候,网络的训练就会收敛,同时也意味着,pdf在射线上的某个空间点上达到了峰值。
因此,Neus最直观的idea就是:
- 借助S-density这一桥梁,可将体渲染用于SDF网络的训练(只使用2D图片进行监督)。
这里在额外给出来一个训练过程中, 1 / s 1/s 1/s变化的示意图:

SDF与渲染之间如何建立联系?
渲染的数学表述
为了学习神经SDF和颜色场的参数,我们提出了一种volume rendering机制,可以基于SDF表达进行渲染。
给定一个像素,我们表示从这个像素发出的射线为: { p ( t ) = o + t v ∣ t ≥ 0 } \{\mathbf{p}(t)=\mathbf{o}+t \mathbf{v} \mid t \geq 0\} {p(t)=o+tv∣t≥0}
,其中 o \mathbf{o} o是摄像机的中心, v \mathbf{v} v是射线的单位方向向量。
那么,沿着光线进行积分,即可得到颜色的数学表达:
C ( o , v ) = ∫ 0 + ∞ w ( t ) c ( p ( t ) , v ) d t C(\mathbf{o}, \mathbf{v})=\int_{0}^{+\infty} w(t) c(\mathbf{p}(t), \mathbf{v}) \mathrm{d} t C(o,v)=∫0+∞w(t)c(p(t),v)dt
其中, C ( o , v ) C(\mathbf{o}, \mathbf{v}) C(o,v)是该像素的颜色, w ( t ) w(t) w(t)为 p ( t ) \mathbf{p}(t) p(t)点的权重, c ( p ( t ) , v ) c(\mathbf{p}(t),\mathbf{v}) c(p(t),v)则对应了点 p \mathbf{p} p在方向 v \mathbf{v} v上的颜色值。
为什么需要更精妙的加权函数?
从一系列2D影像中学习得到精确SDF表达的关键是,如何建立起颜色值与SDF之间的合适联结?或者说,如何导出一个最最合适的加权函数 w ( t ) w(t) w(t)。
我们期望这个加权函数能够有以下的性质:
1. 无偏
2. 对遮挡有所感知
对于性质1,无偏来说,具体为:
给定一条射线 p ( t ) \mathbf{p}(t) p(t)时, w ( t ) w(t) w(t)能够在射线与物体表面交点位置 p ( t ∗ ) \mathbf{p}(t^*) p(t∗)处获得局部最大值。
问:这为什么叫做无偏?
答:可以这样理解,所谓的无偏,就是保证射线与表面交点处贡献是最大的。
对于性质2,即对遮挡有所感知,具体为:
给定任意的两个深度值 t 0 t_0 t0、 t 1 t_1 t1,且这两个深度值满足 f ( t 0 ) = f ( t 1 ) f(t_0) = f(t_1) f(t0)=f(t1), w ( t 0 ) > 0 w(t_0)>0 w(t0)>0, w ( t 1 ) > 0 w(t_1)>0 w(t1)>0, t 0 < t 1 t_0 < t_1 t0<t1, w ( t 0 ) > w ( t 1 ) w(t_0)>w(t_1) w(t0)>w(t1)。也就是说,当两个点有着相同的SDF数值时,距离观测视角更近的点,应当有着更大的贡献。换句话说,这也就保证了当射线穿越多个表面的时候,渲染过程应该尽可能地去使用射线所遇到的第一个表面交点所带来的颜色。
为什么直接使用naive solution是不行的?
什么是naive solution?
为了使得加权函数变得occlusion-aware,一种很自然的想法就是:基于NeRF中所提出的所谓的标准的volume rendering公式,即,将加权函数定义为:
w ( t ) = T ( t ) σ ( t ) w(t) = T(t)\sigma(t) w(t)=T(t)σ(t)
其中, σ ( t ) \sigma(t) σ(t)是所谓的volume density(传统体积渲染中的术语),而 T ( t ) T(t) T(t)则表示该射线上所累积的transmittance,具体有: T ( t ) = exp ( − ∫ 0 t σ ( u ) d u ) T(t) = \exp \left(-\int_{0}^{t} \sigma(u) \mathrm{d} u\right) T(t)=exp(−∫0tσ(u)du)。
为了能够使用标准的体密度公式,在此 σ ( t ) \sigma(t) σ(t)直接设置为与S-density相同,即:
σ ( t ) = ϕ s ( f ( p ( t ) ) ) \sigma(t) = \phi_s(f(\mathbf{p}(t))) σ(t)=ϕs(f(p(t)))
尽管说,此时的 w ( t ) w(t) w(t)是遮挡感知的,但是却是有偏的,其在重建表面上引入了内在的误差。如下图所示:

具体的推导可以参考原论文的补充材料。
再多补充个体渲染与表面渲染的效果示意图,来展现说为什么NeRF的体渲染标准公式是天生能够感知遮挡的,具体见下:

因此做了什么样的改进?
首先,考虑期望的无偏的性质,先将 w ( t ) w(t) w(t)构造为归一化的S-density的形式:
w ( t ) = ϕ s ( f ( p ( t ) ) ) ∫ 0 + ∞ ϕ s ( f ( p ( u ) ) ) d u w(t)=\frac{\phi_{s}(f(\mathbf{p}(t)))}{\int_{0}^{+\infty} \phi_{s}(f(\mathbf{p}(u))) \mathrm{d} u} w(t)=∫0+∞ϕs(f(p(u)))duϕs(f(p(t)))
接下来,我们需要再对其进行改造,使其能够满足occlusion-aware的性质。自然地,NeRF本身基本的公式就是occlusion-aware,文章还是采用了基本公式的逻辑,但是在其的基础上做了微小的改动,即自行定义了一个不透明的密度函数 ρ ( t ) \rho(t) ρ(t),对应着传统公式中的 σ \sigma σ,因此,加权函数变为了:
w ( t ) = T ( t ) ρ ( t ) , where T ( t ) = exp ( − ∫ 0 t ρ ( u ) d u ) w(t)=T(t) \rho(t), \text { where } T(t)=\exp \left(-\int_{0}^{t} \rho(u) \mathrm{d} u\right) w(t)=T(t)ρ(t), where T(t)=exp(−∫0tρ(u)du)
那么,现在的问题就变成了,我们应当如何推导出 ρ \rho ρ?
首先,我们考虑一种简单情况:即只有一个表面交点且表面是平面。在这种特殊情况下,我们很容易地知道sdf有以下的关系:
f ( p ( t ) ) = − ∣ c o s ( θ ) ∣ ⋅ ( t − t ∗ ) f(\mathbf{p(t)}) = -|cos(\theta)| \cdot (t - t^*) f(p(t))=−∣cos(θ)∣⋅(t−t∗)
且有 f ( p ( t ∗ ) ) = 0 f(\mathbf{p}(t^*)) = 0 f(p(t∗))=0。
其中, θ \theta θ是视角方向 v \mathbf{v} v与表面法向 n \mathbf{n} n之间的夹角。
由于我们假设表面是locally,所以 ∣ c o s ( θ ) ∣ |cos(\theta)| ∣cos(θ)∣是一个定值。
此时,有:
w ( t ) = ϕ s ( f ( p ( t ) ) ) ∫ − ∞ + ∞ ϕ s ( f ( p ( u ) ) ) d u = ϕ s ( f ( p ( t ) ) ) ∫ − ∞ + ∞ ϕ s ( − ∣ cos ( θ ) ∣ ⋅ ( u − t ∗ ) ) d u = ϕ s ( f ( p ( t ) ) ) ∣ cos ( θ ) ∣ − 1 ⋅ ∫ − ∞ + ∞ ϕ s ( u − t ∗ ) d u = ∣ cos ( θ ) ∣ ϕ s ( f ( p ( t ) ) ) . \begin{aligned} w(t) &=\frac{\phi_{s}(f(\mathbf{p}(t)))}{\int_{-\infty}^{+\infty} \phi_{s}(f(\mathbf{p}(u))) \mathrm{d} u} \\ &=\frac{\phi_{s}(f(\mathbf{p}(t)))}{\int_{-\infty}^{+\infty} \phi_{s}\left(-|\cos (\theta)| \cdot\left(u-t^{*}\right)\right) \mathrm{d} u} \\ &=\frac{\phi_{s}(f(\mathbf{p}(t)))}{|\cos (\theta)|^{-1} \cdot \int_{-\infty}^{+\infty} \phi_{s}\left(u-t^{*}\right) \mathrm{d} u} \\ &=|\cos (\theta)| \phi_{s}(f(\mathbf{p}(t))) . \end{aligned} w(t)=∫−∞+∞ϕs(f(p(u)))duϕs(f(p(t)))=∫−∞+∞ϕs(−∣cos(θ)∣⋅(u−t∗))duϕs(f(p(t)))=∣cos(θ)∣−1⋅∫−∞+∞ϕs(u−t∗)duϕs(f(p(t)))=∣cos(θ)∣ϕs(f(p(t))).
经由一系列推导(推导过程略,具体见原文),最终可以得到有:
ρ ( t ) = max ( − d Φ s d t ( f ( p ( t ) ) ) Φ s ( f ( p ( t ) ) ) , 0 ) \rho(t)=\max \left(\frac{-\frac{\mathrm{d} \Phi_{s}}{\mathrm{~d} t}(f(\mathbf{p}(t)))}{\Phi_{s}(f(\mathbf{p}(t)))}, 0\right) ρ(t)=max(Φs(f(p(t)))− dtdΦs(f(p(t))),0)
基于 ρ ( t ) \rho(t) ρ(t),我们可以带入至传统公式中,得到 w ( t ) w(t) w(t),其示意图为:

如何做离散化?
为了获得不透明度以及加权函数中的离散值,采用了和NeRF中类似的近似估计方式,即在射线上采样 n n n个点,进而对射线所对应的像素颜色进行估计:
C ^ = ∑ i = 1 n T i α i c i \hat{C}=\sum_{i=1}^{n} T_{i} \alpha_{i} c_{i} C^=i=1∑nTiαici
其中, T i T_i Ti就是离散的累加透光率:
T i = ∏ j = 1 i − 1 ( 1 − α j ) T_{i}=\prod_{j=1}^{i-1}\left(1-\alpha_{j}\right) Ti=j=1∏i−1(1−αj)
而离散的不透明值 α i \alpha_i αi则为:
α i = 1 − exp ( − ∫ t i t i + 1 ρ ( t ) d t ) \alpha_{i}=1-\exp \left(-\int_{t_{i}}^{t_{i+1}} \rho(t) \mathrm{d} t\right) αi=1−exp(−∫titi+1ρ(t)dt)
进一步地,可以写成:
α i = max ( Φ s ( f ( p ( t i ) ) ) − Φ s ( f ( p ( t i + 1 ) ) ) Φ s ( f ( p ( t i ) ) ) , 0 ) \alpha_{i}=\max \left(\frac{\Phi_{s}\left(f\left(\mathbf{p}\left(t_{i}\right)\right)\right)-\Phi_{s}\left(f\left(\mathbf{p}\left(t_{i+1}\right)\right)\right)}{\Phi_{s}\left(f\left(\mathbf{p}\left(t_{i}\right)\right)\right)}, 0\right) αi=max(Φs(f(p(ti)))Φs(f(p(ti)))−Φs(f(p(ti+1))),0)
在真正的实现过程中,实际上有两种采样方式,一种是直接采样射线上的点: q i = o + t i v \mathbf{q}_{i}=\mathbf{o}+t_{i} \mathbf{v} qi=o+tiv,而另外一种则是去采样射线上某一小段的中点: p i = o + t i + t i + 1 2 v \mathbf{p}_{i}=\mathbf{o}+\frac{t_{i}+t_{i+1}}{2} \mathbf{v} pi=o+2ti+ti+1v,这两种采样方式的示意图见下:

具体来说,当我们想去计算阿尔法值时,我们采用的是section points的方式,那么计算方式也就跟上面的公式是保持一致的,即: max ( Φ s ( f ( q i ) ) − Φ s ( f ( q i + 1 ) ) Φ s ( f ( q i ) ) , 0 ) \max \left(\frac{\Phi_{s}\left(f\left(\mathbf{q}_{i}\right)\right)-\Phi_{s}\left(f\left(\mathbf{q}_{i+1}\right)\right)}{\Phi_{s}\left(f\left(\mathbf{q}_{i}\right)\right)}, 0\right) max(Φs(f(qi))Φs(f(qi))−Φs(f(qi+1)),0)。
再多说一句,而对于颜色值的计算来说,我们则采用第2种方式,也就是中间点的方式。
小结
几个重要的公式:
- 概率密度函数: ϕ s ( f ( x ) ) \phi_{s}(f(\mathbf{x})) ϕs(f(x)),将其命名为
S-density,有:
ϕ s ( x ) = s e − s x / ( 1 + e − s x ) 2 \phi_{s}(x)=s e^{-s x} /\left(1+e^{-s x}\right)^{2} ϕs(x)=se−sx/(1+e−sx)2
同时也是sigmoid函数的导数形式:
Φ s ( x ) = ( 1 + e − s x ) − 1 , i.e., ϕ s ( x ) = Φ s ′ ( x ) \Phi_{s}(x)=\left(1+e^{-s x}\right)^{-1} \text {, i.e., } \phi_{s}(x)=\Phi_{s}^{\prime}(x) Φs(x)=(1+e−sx)−1, i.e., ϕs(x)=Φs′(x) - 定义了一个不透明的密度函数 ρ ( t ) \rho(t) ρ(t),对应着NeRF渲染公式中的 σ \sigma σ,因此,加权函数变为了:
w ( t ) = T ( t ) ρ ( t ) , where T ( t ) = exp ( − ∫ 0 t ρ ( u ) d u ) w(t)=T(t) \rho(t), \text { where } T(t)=\exp \left(-\int_{0}^{t} \rho(u) \mathrm{d} u\right) w(t)=T(t)ρ(t), where T(t)=exp(−∫0tρ(u)du)
且经过推导,有:
ρ ( t ) = max ( − d Φ s d t ( f ( p ( t ) ) ) Φ s ( f ( p ( t ) ) ) , 0 ) \rho(t)=\max \left(\frac{-\frac{\mathrm{d} \Phi_{s}}{\mathrm{~d} t}(f(\mathbf{p}(t)))}{\Phi_{s}(f(\mathbf{p}(t)))}, 0\right) ρ(t)=max(Φs(f(p(t)))− dtdΦs(f(p(t))),0) - 离散化后的不透明度为:
α i = max ( Φ s ( f ( p ( t i ) ) ) − Φ s ( f ( p ( t i + 1 ) ) ) Φ s ( f ( p ( t i ) ) ) , 0 ) \alpha_{i}=\max \left(\frac{\Phi_{s}\left(f\left(\mathbf{p}\left(t_{i}\right)\right)\right)-\Phi_{s}\left(f\left(\mathbf{p}\left(t_{i+1}\right)\right)\right)}{\Phi_{s}\left(f\left(\mathbf{p}\left(t_{i}\right)\right)\right)}, 0\right) αi=max(Φs(f(p(ti)))Φs(f(p(ti)))−Φs(f(p(ti+1))),0)
训练
损失函数
最小化渲染后颜色与参考真值颜色之间的差别,不引入任何的三维监督。
在颜色项的监督基础上,还可以利用mask信息进行监督(如果提供了mask的话)。
我们需要优化的参数有:神经网络的参数以及逆标准差 s s s。
关于 s s s在网络中具体的代码表达为:
class SingleVarianceNetwork(nn.Module):
def __init__(self, init_val):
super(SingleVarianceNetwork, self).__init__()
self.register_parameter('variance', nn.Parameter(torch.tensor(init_val)))
def forward(self, x):
return torch.ones([len(x), 1]) * torch.exp(self.variance * 10.0)
优化的方式是,随机采样一批像素,以及其对应的在世界坐标系下的射线,即:
P = { C k , M k , o k , v k } P=\left\{C_{k}, M_{k}, \mathbf{o}_{k}, \mathbf{v}_{k}\right\} P={Ck,Mk,ok,vk}
其中, C k C_k Ck是像素的颜色, M k ∈ ( 0 , 1 ) M_k \in {(0,1)} Mk∈(0,1)是可选的mask数值。
我们不妨假设采样的点数量为 n n n,采样像素点的数量为 m m m,那么损失函数可以定义为:
L = L color + λ L reg + β L mask \mathcal{L}=\mathcal{L}_{\text {color }}+\lambda \mathcal{L}_{\text {reg }}+\beta \mathcal{L}_{\text {mask }} L=Lcolor +λLreg +βLmask
| L c o l o r L_{color} Lcolor | L r e g L_{reg} Lreg | L m a s k L_{mask} Lmask |
|---|---|---|
| L color = 1 m ∑ k R ( C ^ k , C k ) \mathcal{L}_{\text {color }}=\frac{1}{m} \sum_{k} \mathcal{R}\left(\hat{C}_{k}, C_{k}\right) Lcolor =m1∑kR(C^k,Ck) | L r e g = 1 n m ∑ k , i ( ∣ ∇ f ( p ^ k , i ) ∣ 2 − 1 ) 2 \mathcal{L}_{r e g}=\frac{1}{n m} \sum_{k, i}\left(\left|\nabla f\left(\hat{\mathbf{p}}_{k, i}\right)\right|_{2}-1\right)^{2} Lreg=nm1∑k,i(∣∇f(p^k,i)∣2−1)2 | L m a s k = BCE ( M k , O ^ k ) \mathcal{L}_{m a s k}=\operatorname{BCE}\left(M_{k}, \hat{O}_{k}\right) Lmask=BCE(Mk,O^k) |
其中,针对 L m a s k L_{mask} Lmask来说,有:
O ^ k = ∑ i = 1 n T k , i α k \hat{O}_{k}=\sum_{i=1}^{n} T_{k, i} \alpha_{k} O^k=i=1∑nTk,iαk
即在相机射线上的权重求和,BCE则是二值交叉熵损失。
分层采样
分层采样的策略与NeRF非常接近。
首先,均匀地在射线上进行采样,然后迭代地在粗概率估计峰值处执行重要性采样。
与NeRF之间的区别在于,并非同时地优化一个粗网络和细网络,而是仅仅维护好一个网络,且在粗采样中,该概率是基于固定标准差数值S-density来计算的,而细网络则是使用学习得到的 s s s来计算的。
具体来说,我们首先沿着射线均匀的去采样64个点,然后我们再迭代的去进行重要性采样(k=4)。
这里简单回顾一下NeRF中所谓的重要性采样:

在第 i i i次迭代时的粗概率,固定地设定 s s s值为 32 × 2 i 32×2^i 32×2i。
此外在每一次迭代中,我们都额外的去多采样16个点。
因此我们总共采样的点数是128个点。对于不加mask的设定而言,我们在单位球外再多采样32个点。至于单位球外的采样点表示方法,则基于NeRF++进行实现。
具体地,当给定某一个某一个 1 s \frac{1}{s} s1时,采样的代码表现为:
def up_sample(self, rays_o, rays_d, z_vals, sdf, n_importance, inv_s):
"""
Up sampling give a fixed inv_s
"""
batch_size, n_samples = z_vals.shape
pts = rays_o[:, None, :] + rays_d[:, None, :] * z_vals[..., :, None] # n_rays, n_samples, 3
radius = torch.linalg.norm(pts, ord=2, dim=-1, keepdim=False)
inside_sphere = (radius[:, :-1] < 1.0) | (radius[:, 1:] < 1.0)
sdf = sdf.reshape(batch_size, n_samples)
prev_sdf, next_sdf = sdf[:, :-1], sdf[:, 1:]
prev_z_vals, next_z_vals = z_vals[:, :-1], z_vals[:, 1:]
mid_sdf = (prev_sdf + next_sdf) * 0.5
cos_val = (next_sdf - prev_sdf) / (next_z_vals - prev_z_vals + 1e-5)
# ----------------------------------------------------------------------------------------------------------
# Use min value of [ cos, prev_cos ]
# Though it makes the sampling (not rendering) a little bit biased, this strategy can make the sampling more
# robust when meeting situations like below:
#
# SDF
# ^
# |\ -----x----...
# | \ /
# | x x
# |---\----/-------------> 0 level
# | \ /
# | \/
# |
# ----------------------------------------------------------------------------------------------------------
prev_cos_val = torch.cat([torch.zeros([batch_size, 1]), cos_val[:, :-1]], dim=-1)
cos_val = torch.stack([prev_cos_val, cos_val], dim=-1)
cos_val, _ = torch.min(cos_val, dim=-1, keepdim=False)
cos_val = cos_val.clip(-1e3, 0.0) * inside_sphere
dist = (next_z_vals - prev_z_vals)
prev_esti_sdf = mid_sdf - cos_val * dist * 0.5
next_esti_sdf = mid_sdf + cos_val * dist * 0.5
prev_cdf = torch.sigmoid(prev_esti_sdf * inv_s)
next_cdf = torch.sigmoid(next_esti_sdf * inv_s)
alpha = (prev_cdf - next_cdf + 1e-5) / (prev_cdf + 1e-5)
weights = alpha * torch.cumprod(
torch.cat([torch.ones([batch_size, 1]), 1. - alpha + 1e-7], -1), -1)[:, :-1]
z_samples = sample_pdf(z_vals, weights, n_importance, det=True).detach()
return z_samples
而在pdf上进行采样的代码实现则为:
def sample_pdf(bins, weights, n_samples, det=False):
# This implementation is from NeRF
# Get pdf
weights = weights + 1e-5 # prevent nans
pdf = weights / torch.sum(weights, -1, keepdim=True)
cdf = torch.cumsum(pdf, -1)
cdf = torch.cat([torch.zeros_like(cdf[..., :1]), cdf], -1)
# Take uniform samples
if det:
u = torch.linspace(0. + 0.5 / n_samples, 1. - 0.5 / n_samples, steps=n_samples)
u = u.expand(list(cdf.shape[:-1]) + [n_samples])
else:
u = torch.rand(list(cdf.shape[:-1]) + [n_samples])
# Invert CDF
u = u.contiguous()
inds = torch.searchsorted(cdf, u, right=True)
below = torch.max(torch.zeros_like(inds - 1), inds - 1)
above = torch.min((cdf.shape[-1] - 1) * torch.ones_like(inds), inds)
inds_g = torch.stack([below, above], -1) # (batch, N_samples, 2)
matched_shape = [inds_g.shape[0], inds_g.shape[1], cdf.shape[-1]]
cdf_g = torch.gather(cdf.unsqueeze(1).expand(matched_shape), 2, inds_g)
bins_g = torch.gather(bins.unsqueeze(1).expand(matched_shape), 2, inds_g)
denom = (cdf_g[..., 1] - cdf_g[..., 0])
denom = torch.where(denom < 1e-5, torch.ones_like(denom), denom)
t = (u - cdf_g[..., 0]) / denom
samples = bins_g[..., 0] + t * (bins_g[..., 1] - bins_g[..., 0])
return samples
实验
实验设置
数据集
使用DTU数据集中的15个场景,每个场景都有49或者64张影像,影像分辨率为 1600 ∗ 1200 1600 * 1200 1600∗1200。
此外,还验证了BlendedMVS中的7个有挑战性的场景,每个场景包含了31 - 143张影像,影像分辨率为 768 ∗ 576 768 * 576 768∗576。
baseline
| IDR | IDR可以重建搞质量的物体,但是需要前景mask作为监督。 |
|---|---|
| 体渲染技术NeRF | 阈值为25,提取NeRF的密度场 |
| colmap | colmap输出的点云+screened泊松表面重建 |
| UNISURF | 结合表面渲染与体渲染的工作 |
实现细节
假定ROI在单位球体内。
每次batch采集512条ray。模型训练300k次迭代,2080Ti耗时约14小时。
网络结构和初始化的方式都与IDR高度相似。
因此仔细去阅读一下IDR,这篇论文是非常有必要的。
具体来说,网络进一步的包含了两个MLP网络,分别是用来对SDF和颜色进行编码。
用于给SDF编码的MLP,包含了8个隐藏层,且每一层都包含了256个隐藏神经元。此外,对于每一个隐藏层,都将原本的ReLU用softplus( β = 100 \beta = 100 β=100)进行了替换。在输入与第4层的输出之间使用了跳层连接。
至于用于给颜色进行编码的MLP,这使用了4层隐藏层,且包含了256个神经元。其不仅以空间位置作为输入,视角的方向、SDF的法向量、以及前面SDF MLP所输出的256维的特征向量,都作为了输入对于空间位置使用了6个频率的位置编码,而对于视角方向来说,使用了4个频率的位置编码。和IDR一样也使用了权值标准化,目的是稳定训练过程。
结果对比
在实验结果的对比过程中设定主要分为两种,一种是带mask监督的,再一种是不带 Mask监督的。
选取了Chamfer距离作为重建质量的指标,下表是该方法与其他方法的定量对比:
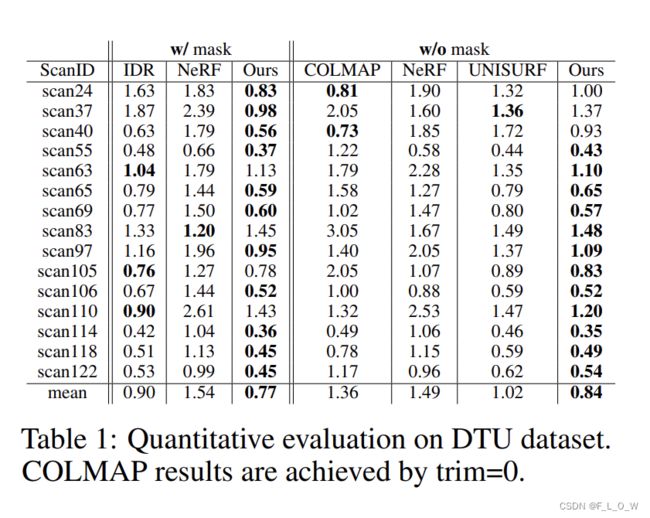
表中可见,在大多数的场景里面,文章所提出来的方法都超越了其他的baseline。
此外仍然在DTU的数据集以及blendedMVS的数据集上进行了定性的比较。同样是在有mask和无Mark的两种设定下,结果可见下图:
尽管在一些目视效果上,似乎文章所提的方法更有优势,在细节上的表现也更好,但是相比起传统的重建方法来说,似乎有纹理复制的现象,示意图见下:
分析
为了验证权值计算所带来的影响,是我们测试的三种截然不同的权值构造方式。具体来说第1种就是所谓naive的解法,第2种是如公式4所说的直接构造的方式,而第3种就是我们所提的构造方式。
所谓naive的方式是指:在标准体渲染公式中直接将体密度用S-density替代,虽然说这是能够感知遮挡的,但是会引入内在的偏差。换句话来说,这样形成的概率密度分布函数并不是无偏的。
这里再回顾一下公式4,也就是天然无偏却不能够处理遮挡的构造方式:
w ( t ) = ϕ s ( f ( p ( t ) ) ) ∫ 0 + ∞ ϕ s ( f ( p ( u ) ) ) d u w(t)=\frac{\phi_{s}(f(\mathbf{p}(t)))}{\int_{0}^{+\infty} \phi_{s}(f(\mathbf{p}(u))) \mathrm{d} u} w(t)=∫0+∞ϕs(f(p(u)))duϕs(f(p(t)))
回顾完之后,我们再来看一下这三种权值构造方式对最终重建效果的影响:

此外还探索了正则化以及几何初始化所带来的影响。当加入这两个技巧的时候,重建效果与文章所提出的权值构造方式,从Champer距离的角度上来看,所带来的效果是非常接近的。而从表中的第2行,也就是mae来看,不管是上述的哪一种方式,都不能够正确的输出SDF。
此外还针对两个thin structures的挑战场景进行了验证。
结果可以见下图:

此外和那些仅仅针对thin structure的高质量重建方法并不一样,文章所提出来的方法是既可以去处理这些thin structure,又可以去处理一些普通物品的重建。
结论
文章总体来说提供了一种不错的多视图重建方法,在很多有挑战性的场景上面,都取得了比传统方法或近年来相近方法更好的结果。然而虽然说这篇文章并不强烈的依赖于纹理特征的匹配,但是仍然会在一些纹理匮乏的区域损失一些效果。
此外对于所有的空间位置都采用了同一个方差。因此在将来的研究中会倾向于根据不同的空间位置去学习,最适应的标准差。