yolov5 6.1 关于 tensorrt 加速的使用以及问题说明
文章目录
- 1. 参考连接
- 2. 使用说明
-
- 2.1 导出加速模型
- 2.1 使用加速模型
- 2.2 加速参数对比
- 3. 问题说明
-
- 3.1 在 Tensorrt 8.4.1.5 版本上使用 export.py 导出失败的问题
- 3.2 把模型文件由 best.pt 更换成加速后的 best.engine 后,执行推理时标注的类别名不正确的问题
- 3.3 导出加速模型和使用加速模型推理时 batch_size 不一致的问题
-
- 3.3.1 为啥使用 PyTorch 的 pt 模型不需要匹配 batch_size,而使用 Tensorrt 的 engine 模型需要呢(代码层面)?
- 3.3.2 为什么 pt 模型不需要检测,而 engine 模型需要检测张量形状匹配呢?(原理层面)
- 3.4 导出过程中出现了 Some tactics do not have sufficient workspace memory to run. Increasing workspace size will enable more tactics, please check verbose output for requested sizes 提示信息的问题
- 3.5 高版本 tensorrt 导出的模型文件移植到低版本上报出属性错误 'NoneType' object has no attribute 'num_bindings' 的问题
- 3.6 初次在 7.1.3.0 Tensorrt 上运行导出加速模型时提示 onnx not found and is required by YOLOv5, attempting auto-update 并报错 Failed building wheel for onnx 的问题
- 3.7 推理时指定的长方形图片输入尺寸在使用 pt 模型时正常而使用 engine 加速模型时报出输入尺寸和模型尺寸不匹配的问题(不建议“导出”与“训练”指定不同的图片尺寸,该问题旨在进一步熟悉来龙去脉)
- 4 相关说明
-
- 4.1 stride 说明
1. 参考连接
- 【目标检测】YOLOv5多进程/多线程推理加速实验
- 【目标检测】YOLOv5推理加速实验:TensorRT加速
- 【目标检测】使用TensorRT加速YOLOv5
2. 使用说明
2.1 导出加速模型
python3 export.py --weights best.pt --data dataset/dataset.yaml --include engine --device 0
| 参数 | 说明 |
|---|---|
| –weights best.pt | 指定使用的待加速的模型文件为 best.pt |
| –data dataset/dataset.yaml | 指定的数据集配置文件的路径和名称 |
| –include engine | 指定要导出的模型格式为 “engine”,即使用 TensorRT 引擎 |
| –device 0 | 指定脚本要在第 0 号设备上运行,通常表示第一个可用的 GPU,默认是 cpu |
运行命令后,需等待一段时间,如果运行无误,将在本目录下生成 best.engine 的加速模型
以下是启用 --half 和 --int8 参数来推导加速模型,过程长达 2000 秒
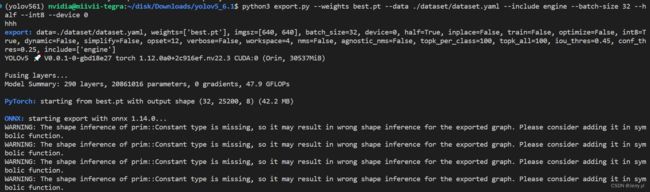
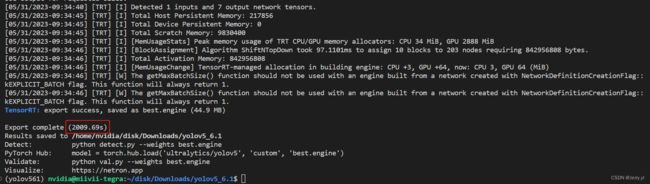
2.1 使用加速模型
使用很简单,就把原先推理时使用的 best.pt 模型替换成 best.engine 即可,以及用命令参数指定数据集配置文件,如下:
python3 detect.py --weights best.engine --data dataset/dataset.yaml --source picture_path
2.2 加速参数对比
以下是做的一些简单测试,加速模型的提速效果还是很不错的。
| export.py 参数 | detect.py 参数 | detect 时间 |
|---|---|---|
| - | –weights best.pt | Speed: 1.7ms pre-process, 37.3ms inference, 3.0ms NMS per image at shape (1, 3, 640, 640) |
| - | –weights best.pt --half | Speed: 1.6ms pre-process, 36.0ms inference, 3.3ms NMS per image at shape (1, 3, 640, 640) |
| - | –weights best.engine | Speed: 1.6ms pre-process, 19.6ms inference, 3.0ms NMS per image at shape (1, 3, 640, 640) |
| –half --int8 | –weights best.engine --half | Speed: 1.9ms pre-process, 16.8ms inference, 4.0ms NMS per image at shape (1, 3, 640, 640) |
| –half --int8 --imgsz 384 640 | –weights best.engine --half --imgsz 384 640 | Speed: 1.7ms pre-process, 14.5ms inference, 3.4ms NMS per image at shape (1, 3, 384, 640) |
| –half --int8 --imgsz 320 640 | –weights best.engine --half --imgsz 320 640 | Speed: 1.9ms pre-process, 13.0ms inference, 3.7ms NMS per image at shape (1, 3, 320, 640) |
| –half --int8 --imgsz 320 320 | –weights best.engine --half --imgsz 320 320 | Speed: 1.5ms pre-process, 6.9ms inference, 3.3ms NMS per image at shape (1, 3, 320, 320) |
说明一下:
- export.py 参数:导出 tensorrt 加速模型时使用的参数,- 横杠表示没有相关参数
- detect.py 参数:推理时使用的参数,- 横杠表示没有相关参数
3. 问题说明
3.1 在 Tensorrt 8.4.1.5 版本上使用 export.py 导出失败的问题
按照如下命令导出加速模型:
python3 export.py --weights best.pt --data dataset/dataset.yaml --include engine --device 0
运行结果如下:
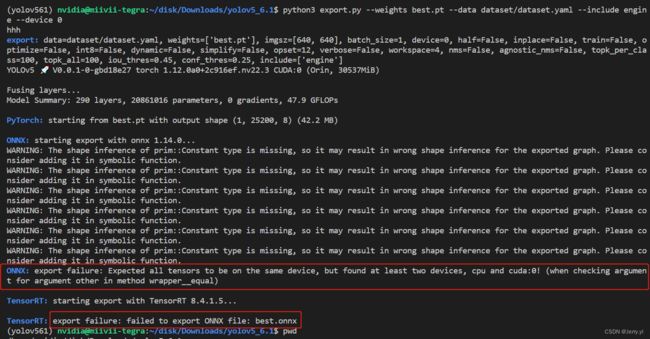
报错信息如下:
- ONNX: export failure: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument other in method wrapper__equal)(导出失败,期望所有计算都在同一个设备上,但发现计算存在于 cpu 和 gpu 上)
- TensorRT: export failure: failed to export ONNX file: best.onnx(导出 best.onnx 文件失败)
ONNX:ONNX(Open Neural Network Exchange)是一个开放的跨平台的深度学习模型交换格式,允许在不同的深度学习框架之间无缝转换和部署模型。
根据以上错误信息的提示,可以先不指定 GPU ,使用 CPU 运行生成 best.onnx,但同时会在生成 best.engine 时报错终止,因为 Tensorrt 必须使用 GPU
python3 export.py --weights best.pt --data dataset/dataset.yaml --include engine
运行结果如下:
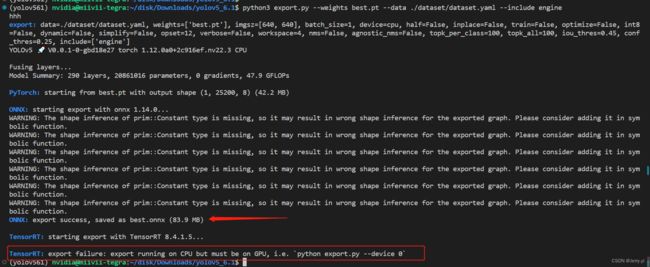
根据以上提示说明导出 best.engine 必须在 GPU 上才行,再次执行如下命令:
python3 export.py --weights best.pt --data dataset/dataset.yaml --include engine --device 0
运行结果如下:
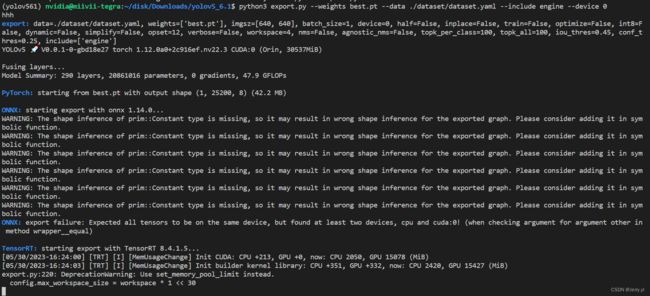
虽然还是会报出导出 best.onnx 文件失败,但由于之前使用 cpu 已成功导出该文件,所以后续 best.onnx 文件转换成 best.engine 文件的处理得以继续进行。
最终运行结果如下:
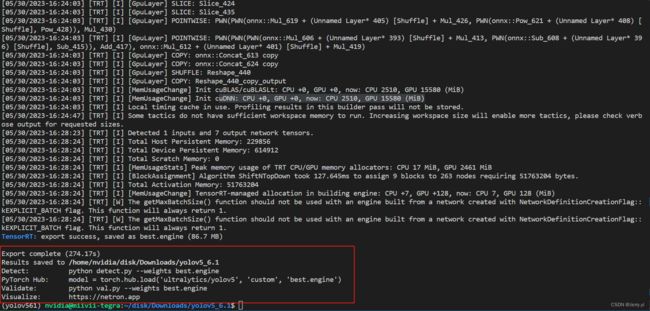
导出成功,解决了一开始执行导出指令总是失败的问题,终端还显示了转换所需时间,以及使用示例。其实只要详细查看报错信息,对于问题的解决还是有很大帮助的。
但是在另外一台 tensorrt 7.1.3.0 版本的设备上却没有出现以上问题,暂不知道原因所在
3.2 把模型文件由 best.pt 更换成加速后的 best.engine 后,执行推理时标注的类别名不正确的问题
这是因为 .pt 模型文件中包含了完整的模型定义,包括类别信息和权重。而使用 TensorRT 加速模型(.engine文件)进行推理时,文件中并不包含类别信息,因此需要提供数据集配置文件来指定类别信息。
所以在使用加速模型文件 best.engine 时,需要在 detect.py 文件中把默认的 coco128.yaml 数据集配置文件更换成自己的配置文件,或者在调用 detect.py 时使用 --data 参数指定数据集配置文件
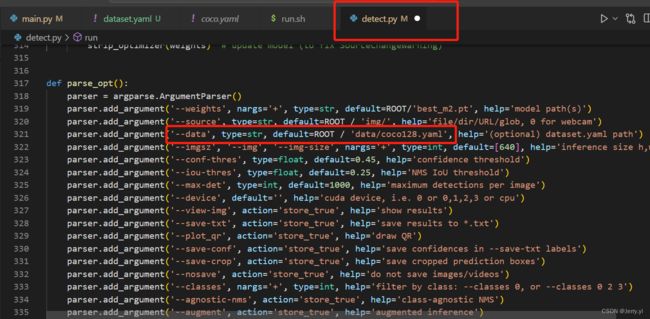
3.3 导出加速模型和使用加速模型推理时 batch_size 不一致的问题
不断尝试以不同参数导出加速模型时,结果出现了如下报错:
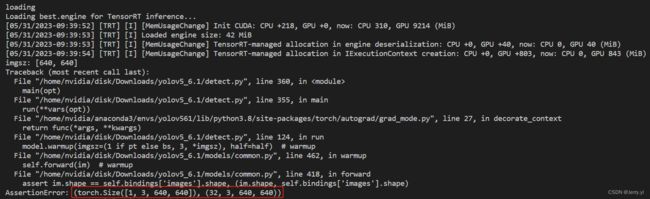
从报错情况来看,是 batch_size 不一致问题,回顾发现是本次导出加速模型时,指定了 --batch_size 为 32 了,在导出加速模型时不使用 --batch_size 重新导出即可,因为默认就是 1
3.3.1 为啥使用 PyTorch 的 pt 模型不需要匹配 batch_size,而使用 Tensorrt 的 engine 模型需要呢(代码层面)?
从以上图片报错信息跳转到 common.py 文件的 418 行来寻找初步的答案
def forward(self, im, augment=False, visualize=False, val=False):
# YOLOv5 MultiBackend inference
b, ch, h, w = im.shape # batch, channel, height, width
if self.pt or self.jit: # PyTorch
y = self.model(im) if self.jit else self.model(im, augment=augment, visualize=visualize)
return y if val else y[0]
......
# 此处省略一部分代码
......
elif self.engine: # TensorRT
# 与上面的 PyTorch 模型增加了如下 assert 语句,即检测张量形状是否相等,不相等则抛出异常
assert im.shape == self.bindings['images'].shape, (im.shape, self.bindings['images'].shape)
self.binding_addrs['images'] = int(im.data_ptr())
self.context.execute_v2(list(self.binding_addrs.values()))
y = self.bindings['output'].data
......
# 此处省略一部分代码
......
3.3.2 为什么 pt 模型不需要检测,而 engine 模型需要检测张量形状匹配呢?(原理层面)
使用 TensorRT 加速模型的主要目的是提高推理性能,以获得更快的推理速度和更高的吞吐量。TensorRT 通过对模型进行优化和运行时的高效计算,实现了对推理过程的加速。
当使用 TensorRT 加速模型时,需要将模型转换为 TensorRT 的 engine 格式,这个 engine 是针对特定硬件和指定的输入尺寸进行了优化。在转换为 engine 时,需要指定输入的 batch_size,这是因为 TensorRT 在进行网络结构优化和内存分配时会基于指定的 batch_size 进行操作。
而在使用原始的 pt 模型进行推理时,模型会直接在 PyTorch 框架下执行。在这种情况下,会根据实际的推理需求,使用不同的 batch_size 进行推理,而不需要与训练时使用的 batch_size 匹配。因为 PyTorch 框架允许在推理过程中灵活地调整 batch_size,模型的网络结构和内存分配会根据实际的 batch_size 进行动态调整。
不仅仅张量中的 batch_size 要匹配,其他参数诸如图片通道数、图片尺寸都需要匹配才能够正确加载和执行推理。
3.4 导出过程中出现了 Some tactics do not have sufficient workspace memory to run. Increasing workspace size will enable more tactics, please check verbose output for requested sizes 提示信息的问题
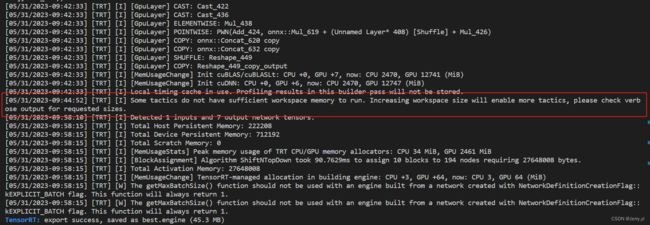
通常是由 TensorRT 库的工作空间内存不足引起的,TensorRT 在编译和优化模型时使用工作空间内存,以支持不同的优化策略和算法。如果工作空间内存不足,可能无法运行某些优化策略,从而报出该警告信息
查看 export.py 的 parse_opt 函数得知:
parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
由此看来默认的 4GB 少了,可通过 --workspace 参数来增加工作空间
GPU 机器有 32 GB 内存,没有指定该参数时,一半内存都没有使用到。
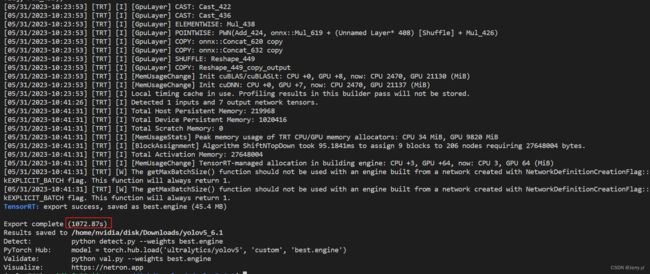
一开始使用 --workspace 8,可仍旧报出警告,最终改成 --workspace 16
python3 export.py --weights best.pt --data ./dataset/dataset.yaml --include engine --half --int8 --device 0 --workspace 16
使用 jtop 指令查看,内存使用量上来了。
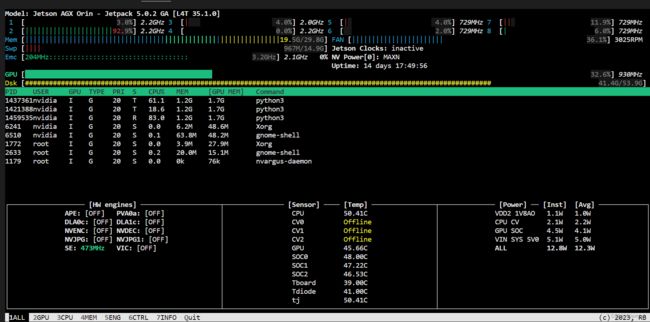
最终生成的结果如下,导出时间也有所下降:
3.5 高版本 tensorrt 导出的模型文件移植到低版本上报出属性错误 ‘NoneType’ object has no attribute ‘num_bindings’ 的问题
博主有两台不同型号和系统的 GPU 机器,博主把在 8.4.1.5 版本的 tensorrt 上导出的加速模型直接拷贝到 7.1.3.0 版本的 tensorrt 上运行推理,结果报错如下:
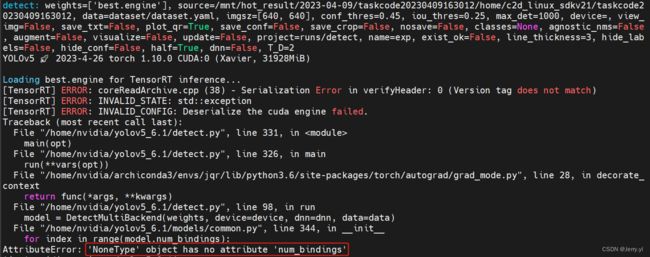
出现该问题由于版本不兼容导致的, 而且 tensorrt 依赖软硬件环境,最好不要拷贝 engine 加速模型在不同机器上使用,遵循谁使用谁导出的原则
tensorrt 版本查询语句如下:
python -c "import tensorrt;print(tensorrt.__version__)"
![]()
![]()
3.6 初次在 7.1.3.0 Tensorrt 上运行导出加速模型时提示 onnx not found and is required by YOLOv5, attempting auto-update 并报错 Failed building wheel for onnx 的问题
衔接上一个问题,在旧版本 tensorrt 机器上重新运行 tensorrt 加速模型的导出
python3 export.py --weights best.pt --data ./dataset/dataset.yaml --include engine --half --int8 --device 0 --workspace 16
运行后提示 onnx not found and is required by YOLOv5, attempting auto-update… 后就报如下错误:
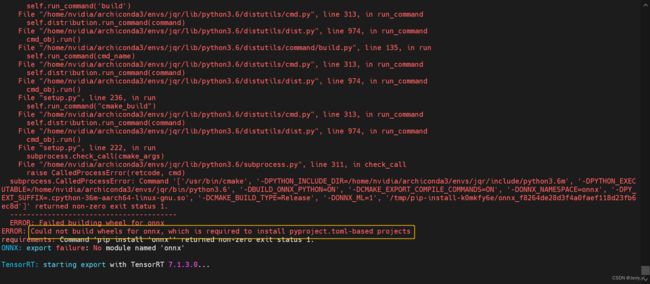
提示自动安装 onnx 时报错,根据提示说明缺少构建 ONNX 所需的一些依赖项或编译环境不完整导致的,
这种情况大概率是由于网络不通畅导致的,开代理使用如下命令来处理:
conda install -c conda-forge onnx
conda-forge: 是一个社区驱动的 Conda 软件包源,它提供了大量的开源软件包供用户安装和使用。与默认的 Conda 软件包源相比,conda-forge 提供了更广泛的软件包选择和更新频率更高的版本更新。
运行之后出现如下提示,提示将安装和更新以下包:
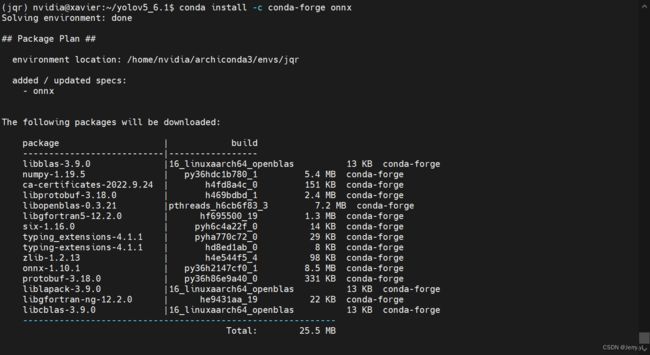
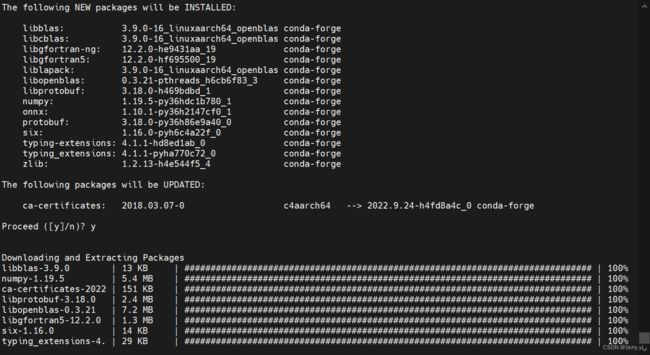
按照提示输入 Y 即可安装所有,安装完成后,通过 conda list onnx 查看安装结果

安装成功,再次执行如下指令,即可生成加速模型了
python3 export.py --weights best.pt --data ./dataset/dataset.yaml --include engine --half --int8 --device 0 --workspace 16
3.7 推理时指定的长方形图片输入尺寸在使用 pt 模型时正常而使用 engine 加速模型时报出输入尺寸和模型尺寸不匹配的问题(不建议“导出”与“训练”指定不同的图片尺寸,该问题旨在进一步熟悉来龙去脉)
博主发现推理输入尺寸是 640 * 640,而博主的原始输入图片是 1080 * 1920,根据同比例缩放,应该是 360 * 640,所以博主尝试使用如下指令导出 tensorrt 加速模型
python3 export.py --weights best.pt --data ./dataset/dataset.yaml --include engine --imgsz 360 640 --half --int8 --device 0 --workspace 16
结果后续使用以上指令导出的加速模型进行推理时,发现推理过程输出的推理输入尺寸是 384 * 640,回溯导出加速模型的调试输出信息时发现如下提示

说是 --imgsz 的参数值必须是 32 的倍数,已自动更新为 384(384 = 32 * 12),博主认为 384 比 352(352 = 32 * 11)与 360 的差值大,所以选择了 352,一是更符合原始图片 1080*1920 的固定缩放比,二是进一步降低了计算的像素数,所以最终选择了 352 * 640 的图片尺寸来导出加速模型
但是当使用如下指令来使用 352 * 640 的加速模型来进行推理时结果却报错:
python3 detect.py --weights best.engine --data dataset/dataset.yaml --source xxx --half --imgsz 352 640
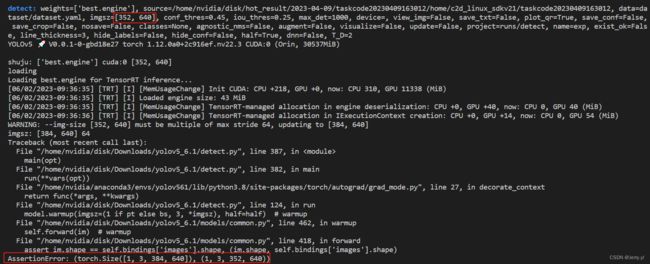
从报错信息可以看出图片输入尺寸与加速模型图片尺寸不一致,加速模型使用的图片尺寸是 352 * 640,表明之前导出的加速模型是没有问题的,而明明指定了推理图片的输入尺寸是 352 * 640,为啥变成了 384 * 640 呢?
其实上图中输出的调试信息已经有提示,就在图片中间位置:
WARNING: --img-size [352, 640] must be multiple of max stride 64, updating to [384, 640]
相关处理代码如下:
detect.py
def run()
......
# 此处省略一部分代码
......
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data)
stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.engine
imgsz = check_img_size(imgsz, s=stride) # check image size
print('imgsz:',imgsz, stride)
......
# 此处省略一部分代码
......
general.py
def check_img_size(imgsz, s=32, floor=0):
# Verify image size is a multiple of stride s in each dimension
if isinstance(imgsz, int): # integer i.e. img_size=640
new_size = max(make_divisible(imgsz, int(s)), floor)
else: # list i.e. img_size=[640, 480]
new_size = [max(make_divisible(x, int(s)), floor) for x in imgsz]
if new_size != imgsz:
LOGGER.warning(f'WARNING: --img-size {imgsz} must be multiple of max stride {s}, updating to {new_size}')
return new_size
commom.py
class DetectMultiBackend(nn.Module):
# YOLOv5 MultiBackend class for python inference on various backends
def __init__(self, weights='yolov5s.pt', device=None, dnn=False, data=None):
......
# 此处省略一部分代码
......
pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs = self.model_type(w) # get backend
# 定义 stride 的初始值为 64
stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaults
w = attempt_download(w) # download if not local
if data: # data.yaml path (optional)
with open(data, errors='ignore') as f:
names = yaml.safe_load(f)['names'] # class names
if pt: # PyTorch
model = attempt_load(weights if isinstance(weights, list) else w, map_location=device)
# 根据模型 stride 值更新 stride
stride = max(int(model.stride.max()), 32) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
self.model = model # explicitly assign for to(), cpu(), cuda(), half()
......
# 此处省略一部分代码
......
elif engine: # TensorRT
LOGGER.info(f'Loading {w} for TensorRT inference...')
import tensorrt as trt # https://developer.nvidia.com/nvidia-tensorrt-download
check_version(trt.__version__, '7.0.0', hard=True) # require tensorrt>=7.0.0
Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
logger = trt.Logger(trt.Logger.INFO)
with open(w, 'rb') as f, trt.Runtime(logger) as runtime:
model = runtime.deserialize_cuda_engine(f.read())
bindings = OrderedDict()
for index in range(model.num_bindings):
name = model.get_binding_name(index)
dtype = trt.nptype(model.get_binding_dtype(index))
shape = tuple(model.get_binding_shape(index))
data = torch.from_numpy(np.empty(shape, dtype=np.dtype(dtype))).to(device)
bindings[name] = Binding(name, dtype, shape, data, int(data.data_ptr()))
binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
context = model.create_execution_context()
batch_size = bindings['images'].shape[0]
......
# 此处省略一部分代码
......
# locals() 返回当前作用域中的所有局部变量和它们的值。返回类型是字典,其中键是变量名,值是变量的值。
# self.__dict__ 字典,表示类的实例对象的属性。通过该字典我们可以访问和操作类的实例对象的属性
self.__dict__.update(locals()) # assign all variables to self
原来是使用加速模型进行推理时,传入 check_img_size 的 stride 为 64 (较小的步幅可以保留更多的细节信息,但计算量较大;而较大的步幅可以加快计算速度,但可能会损失一些细节信息),而指定的图片输入尺寸 352 不是 64 的倍数,通过此函数自动调整成 384 了,
至于为什么传入的 stride 是 64,那是因为在 DetectMultiBackend 类的 init 函数中,当检测到是 tensorrt 的加速模型时,直接使用了 stride, names = 64, [f’class{i}’ for i in range(1000)] # assign defaults 语句定义的值 64
而 best.pt 模型(PyTorch)是自适应输入图片尺寸的,所以不会报出图片尺寸不匹配的问题
4 相关说明
4.1 stride 说明
是指网络中卷积层的步幅(stride)参数。其作用是控制特征图(feature map)相对于输入图像的缩小比例。
在 yolov5 中,模型使用了一系列的卷积层来逐步提取图像特征。每个卷积层通常都会使用一个固定的 stride 值来决定其输出特征图的尺寸和感受野。较小的 stride 值会导致输出特征图尺寸相对于输入图像尺寸较大,而较大的stride 值会导致输出特征图尺寸相对于输入图像尺寸较小。
改变特征图分辨率: 较大的 stride 值会导致特征图分辨率相对于输入图像降低。这可以帮助模型捕获更广阔的上下文信息,并在一定程度上减少计算量。
改变感受野: 较小的 stride 值可以增大卷积层的感受野(即每个像素在输入图像上所关注的区域),使模型能够获取更多的局部和全局上下文信息。
物体检测精度和定位准确性: 较小的 stride 值有助于提高物体检测的精度和定位准确性,因为模型可以更细致地检测和定位较小的目标物体。
需要注意的是,较小的 stride 值会导致网络的计算和内存消耗增加,可能会减慢训练和推理速度。因此,在选择模型的 stride 值时,需要根据具体应用场景进行权衡,平衡精度和速度之间的关系。