《程序员的自我修养--链接、装载与库》笔记
写在前面:本文是我在阅读《程序员的自我修养–链接、装载与库》一书时做的笔记,所谓好记性不如烂笔头嘛,其中主要摘抄记录了本人着重阅读的章节;除此之外还有小部分本人对书中内容的个人理解、以及文章中出现的小错误标明(在博客中以“记录小错误”的这几个字标记)等。本文完全是按照原书结构做的笔记,如有侵权,立即删除。
如果有想要获取此书电子版的小伙伴,可以评论区留言或私信我获取;
目录
- 第一章
-
- 1.6 线程
-
- 1.6.1 线程基础
- 1.6.2 线程安全
- 第二章:编译和链接
-
- 2.1.1 预编译
- 第三章:目标文件里有什么
-
- 3.1 目标文件的格式
- 3.2 目标文件是什么样的
- 3.3 挖掘SimpleSection.o
- 3.5.4 extern “C”
- 第四章:静态链接
-
- 4.5 静态库链接
- 4.6 链接过程控制
- 4.8 本章小结
- 第三部分 装载与动态链接
- 第六章:可执行文件的装载与进程
-
- 6.1 进程虚拟地址空间
- 6.2 装载的方式
- 6.4 进程虚存空间分布
-
- 6.4.3 堆的最大申请数量
- 第七章:动态链接
-
- 7.1 为什么要动态链接
- 7.2 简单的动态链接例子
- 7.3 地址无关代码
-
- 7.3.4 共享模块的全局变量问题
- 7.6 动态链接的步骤和实现
- 第八章:linux共享库的组织
-
- 8.3 共享库系统路径
- 8.4 共享库查找过程
- 8.5 环境变量
- 8.6 共享库的创建和安装
-
- 8.6.1 共享库的创建
- 8.6.3 共享库的安装
- 8.6.4 共享库构造和析构函数
- 8.6.5 共享库脚本
- 第四部分 库与运行库
- 第10章 内存
-
- 10.1 程序的内存布局
- 10.2 栈与调用惯例
- 10.3 堆与内存管理
-
- 10.3.2 Linux进程堆管理
- 第11章:运行库
-
- 11.1 入口函数和程序初始化
-
- 11.1.3 运行库与I/O
第一章
1.6 线程
1.6.1 线程基础
一个进程通常由多个线程组成,各个线程之间共享程序的内存空间(包括代码段、数据段、堆等)及一些进程级的资源(如打开文件和信号)。经典的线程与进程的关系图:

线程中的访问权限
线程中的私有存储:
- 栈
- 线程局部存储(Thread Local Storage,TLS)
- 寄存器(包括PC寄存器)
从C的角度看:

1.6.2 线程安全
同步与锁
所谓同步,是指一个线程访问数据未结束时,其他线程不得对同一个数据进行访问。
同步最常用的方法是锁。
二元信号量:
最简单的一种锁,只有两种状态:占用和非占用。它适合只能被唯一一个线程独占访问的资源。当二元信号量处于非占用状态时,第一个试图获取该而原信号量的线程获得该锁,并将二元信号量置位占用状态,此后其他所有试图获取该二元信号量的线程将会等待,知道该锁被释放。
多元信号量:
简称信号量,允许多个线程并发访问的资源。一个初始值为N的信号量允许N个线程并发访问。线程访问资源的时候获取信号量,过程如下:
- 将信号量的值减1.
- 如果信号量小于0,则进入等待状态,否则继续执行。
访问完资源后,线程释放信号量,进行如下操作:
- 将信号量的值加1。
- 如果信号量的值大于1,唤醒一个等待中的进程。
记录小错误:
我感觉书中好像是写错了,书中写的是“小于1,我感觉应该是大于1”

互斥量(Mutex)
互斥量和二元信号量很类似,资源仅同时允许一个线程访问,但和信号量不同的是,信号量在整个系统可以被任意线程获取并释放,也就是说,同一个信号量可以被系统中的一个线程获取之后由另一个线程释放。而互斥量则要求哪个线程获取了互斥量,哪个线程就要负责释放这个锁,其他线程越俎代庖去释放互斥是无效的。
临界区(Critical Section)
临界区是比互斥量更加严格的同步手段。临界区和互斥量与信号量的区别在于,互斥量和信号量在系统的任何进程里都是可见的,也就是说,一个进程创建了一个互斥量或信号量,另一个进程试图去获取该锁是合法的。然而,临界区的作用范围仅限于本进程,其他的进程无法获取该锁。除此之外,临界区具有和互斥量相同的性质。
读写锁(Read-Write Lock)
读写锁分为共享的(shared)或独占的(Exclusive),即读锁和写锁;当锁处于自由的状态时,试图以任何一种方式获取锁都能成功,并将锁置于相应的状态。如果锁处于共享状态(读锁),其他线程以共享(读)的方式的获取锁时,可以获取成功,也就是说允许多个线程以共享(读)的方式获取读锁。然而,如果其他线程试图以独占(写)的方式去获取已经处于共享(读)状态的锁,那么它必须等待锁被所有的线程释放。相应的,处于独占(写)状态的锁将组织任何线程以任何方式获取该锁。总结如下:

条件变量
条件变量可以让许多线程一起等待某个事件的发生,当事件发生时(条件变量被唤醒),所有的线程可以一起恢复执行。
第二章:编译和链接
用GCC来编译Hello World程序生成a.out的过程可以分解为4个步骤:预处理(Prepressing)、编译(Compilation)、汇编(Assembly)、链接(Linking),如下图

2.1.1 预编译
把源码文件如hello.c和相关头文件如stdio.h等,被预编译器编译成一个.i文件。相当于以下指令:
gcc -E hello.c -o hello.i //-E表示只进行预编译
对于C++来说,将cpp或cxx文件及hpp头文件等预编译成.ii文件:
cpp hello.c > hello.i
预处理过程主要处理那些源码文件中以“#”开始的预编译指令。比如“#include”、“#define”等
第三章:目标文件里有什么
编译器编译源代码后生成的文件叫做目标文件,目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没有经过链接的过程,其中可能有些符号或有些地址还没有被调整。其实它本身就是按照可执行文件格式存储的,只是跟真正的可执行文件在结构上稍有不同。
3.1 目标文件的格式


3.2 目标文件是什么样的
一般C语言的编译后执行语句都编译成机器代码,保存在.text段;已初始化的全局变量和局部静态变量都保存在.data段;未初始化的全局变量和局部静态变量一般放在.bss段;.bss段只是为未初始化的全局变量和局部静态变量预留位置而已,并没有内容,在文件中也并不占据空间。
总体来说,程序源代码被编译以后主要分成两种段:程序指令和程序数据。代码段属于程序指令,数据段和.bss段属于程序数据。
数据和指令分段的好处:
- 程序被装载后,数据和指令分别映射到两个虚存区域。数据区域对于进程来说是可读写的,指令区域对于进程来说是只读的,所以这两个虚存区域的权限被分别设置为可读写和只读。这样可以防止程序的指令被改写。
- 对CPU的缓存命中率提高有好处。
- 最重要的原因是,当系统中运行着多个该程序的副本时,它们的指令都是一样的,所以内存中只需要保存一份改程序的指令部分。对于指令这种只读的区域,是可以共享的,即共享指令;当然每个副本进程的数据区域是不同且私有的。
3.3 挖掘SimpleSection.o
记录小错误:
0x00000090 - 0x00000034的结果应该是0x0000005C吧?文中写的5b?

3.5.4 extern “C”
C++为了与C兼容,在符号的管理上,C++有一个用来声明或定义一个C的符号的“extern “C””关键字用法:
extern “C”
{
int func(int);
int var;
}
C++编译器会将在extern “C”的大括号内部的代码当做C语言代码处理。所以很明显,上面的代码中,C++的名称修饰机制将不会起作用。它声明了一个C的函数func,定义了一个整形全部变量var。
很多时候我们会遇到有些头文件声明了一些C语言的函数和全局变量,但是这个头文件可能会被C语言代码或C++代码包含。比如很常见的,我们的C语言库函数中的string.h中声明了memset这个函数,原型为void *memset (void * , int , size_t);如果不加任何处理,当C语言程序包含string.h的时候,并且用到了memset这个函数,编译器会将memset符号引用正确处理,这没有任何问题。但是在C++语言中,如果包含了string.h文件并且用到了memset函数,编译器会认为这个memset函数是一个C++函数,将memset的符号修饰成_Z6memsetPvii,这样编译器就无法与C语言中的memset符号进行链接。所以对于C++来说,必须使用extern “C”来声明memset这个函数。但是C语言又不支持extern "C"语法,如果为了兼容C语言和C++语言定义两套头文件,未免过于麻烦。于是通过定义C++的宏“_cplusplus”,C++编译器会在编译C++的程序时默认定义这个宏,我们可以使用条件宏来判断当前编译单元是不是C++代码。如下:
#ifdef _cplusplus
extern "C" {
#endif
void *memset (void *, int , size_t);
#ifdef _cplusplus
}
#endif
第四章:静态链接
4.5 静态库链接
程序如何使用操作系统提供的API?在一般情况下,一种语言的开发环境往往会附带有语言库(Language Library)。这些库就是对操作系统的API的包装。
一个静态库可以简单地看成一组目标文件的集合,即很多目标文件经过压缩打包后行程的一个文件。比如Linux中最常用的C语言库libc位于/usr/lib/libc.a,它属于glibc项目的一部分;
在一个C语言运行库中,包含了很多跟系统功能相关的代码,比如输入输出、文件操作、事件日期、内存管理等。glibc本身使用C语言开发的,它有成百上千个C语言源文件组成,也就是说,编译完成后有想相同数量的目标文件,比如输入输出有printf.o,scanf.o;文件操作有fread.o,fwrite.o;时间时期有date.o,time.o;内存管理有malloc.o等。把这些零散的目标文件直接提供给库的使用者,很大程度上会造成文件传输、管理和组织的不便,于是通常使用“ar”压缩程序将这些目标文件压缩到一起,并且对其进行编号和索引,以便于查找和检索,就形成了libc.a这个静态库文件。
4.6 链接过程控制
ld链接器的链接脚本功能非常强大,前面在使用ld链接器的时候并没有指定链接脚本,其实ld在用户没有指定链接脚本的时候会使用默认链接脚本。
4.8 本章小结
本章介绍了静态链接的第一个步骤,即目标文件在被链接成最终可执行文件时,输入目标文件中的各个段是如何被合并到输出文件中的,链接器如何为他们分配在输出文件中的空间和地址。一旦输入端的最终地址被确定,接下来就可以进行符号的解析与重定位,链接器会把各个输入目标文件中对于外部符号的引用进行解析,把每个段中须重定位的指令和数据进行修补,使他们都指向正确的位置。
第三部分 装载与动态链接
第六章:可执行文件的装载与进程
可执行文件只有装载到内存以后才能被CPU执行。
这一章主要通过介绍ELF文件在linux下的装载过程,来探索文件装载的本质。首先介绍什么是进程的虚拟地址空间?为什么进行要有自己独立的虚拟地址空间?然后介绍装载的几种方式,包括覆盖装载、页映射;接着介绍进程虚拟地址空间的分布情况,比如代码段、数据段、BSS段、堆、栈分别在进程地址空间怎么分布,他们的位置和长度如何决定。
6.1 进程虚拟地址空间
没个程序运行起来后,它将拥有自己独立的虚拟地址空间,这个虚拟地址空间的大小由计算机的硬件平台决定,具体地说是由CPU的位数决定的。硬件地址决定了地址空间的最大理论上限,即硬件的寻址空间大小,比如32位的硬件平台决定了地址空间的地址为0到2^32 -1,即0x00000000~0xFFFFFFFF,也就是4G虚拟地址空间大小;
另外,从程序的角度看,可以通过判断C语言程序中指针所占的空间来计算虚拟地址空间的大小。一般来说,C语言指针大小的位数与虚拟空间的位数相同,如32位平台下的指针为32位,即4字节;64位平台下的指针为64位,即8字节。
6.2 装载的方式
程序执行时所需要的指令和数据必须在内存中才能够正常运行,最简单的方法就是将程序运行所需要的指令和数据全部装入内存中,这样程序就可以顺利运行,这就是最简单的静态装入的办法。但是很多情况下程序所需要的的内存数量大于物理内存的数量,也就是说内存并不够用;后来研究发现,程序运行时是有局部性原理的,所以我们可以将程序最常用的部分驻留在内存中,而将一些不太常用的数据存放在磁盘里面,这就是动态装入的基本原理。
**覆盖装入(Overlay)和页映射(paging)**是两种很典型的动态装载方法,他们所采用的思想都差不多,原则上都是利用了程序的局部性原理。动态装入的思想是程序用到哪个模块,就将哪个模块装入内存,如果不用就暂时不装入,存放在磁盘中。
6.4 进程虚存空间分布
6.4.3 堆的最大申请数量
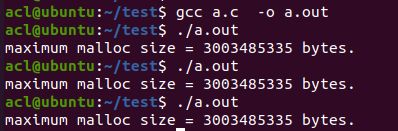
Linux下虚拟地址空间分给进程本身的是3G(windows默认是2GB),那么程序可以用的有多少呢?验证一下:
#include 书中记录的作者的linux机器上运行结果为2.9G左右。我本人运行的结果为2.79G左右(虚拟机中的Ubuntu 20.04),如下图所示。
第七章:动态链接
7.1 为什么要动态链接
静态链接的缺点:
1、对计算机内存和磁盘空间浪费很严重。
2、静态链接对程序的更新、部署和发布也会带来很多麻烦。
动态链接
要解决空间浪费和更新困难的问题这两个问题,最简单的办法就是把程序的模块相互分割开来,形成独立的文件,而不再将他们静态地链接在一起。简单的讲,就是不对那些组成程序的目标文件进行链接,等到要运行时才进行链接。也就是说,把链接这个过程推迟到了运行时再进行,这就是动态链接的基本思想。
程序可扩展性和兼容性
动态链接还有一个特点就是程序在运行时可以动态的选择加载各种程序模块,这个有点后来被人们用来制作程序的插件(Plug-in)。
动态链接的基本实现
目前主流的操作系统几乎都支持动态链接这种方式,在linux系统中,ELF动态链接文件被称为动态共享对象(DSO,Dynamic Shared Object),简称共享对象,一般以“.so”为扩展名的一些文件;而在Windows系统中,动态链接文件被称为动态链接库(Dynamic Linking Library),通常以“.dell”为扩展名的文件。
7.2 简单的动态链接例子
用几个源文件来演示简单地动态链接:Program1.c、Program2.c、Lib.c、Lib.h
Program1.c:
#include"Lib.h"
int main()
{
foobar(1);
return 0;
}
Program2.c:
#include"Lib.h"
int main()
{
foobar(2);
return 0;
}
Lib.h
#ifndef LIB_H
#define LIB_H
void foobar(int i);
#endif
Lib.c
#include 先将Lib.c编译成一个共享对象文件:
gcc -fPIC -shared -o Lib.so Lib.c //-shared表示产生共享对象
这时候得到了一个Lib.so文件,这既是包含了Lib.c的Foobar()函数的共享对象文件。然后分别链接Program1.c和Program2.c:
gcc -o Program1 Program1.c ./Lib.so
gcc -o Program2 Program2.c ./Lib.so
然后分别执行Program1和Program2:

此时,如果删除Lib.so,再去执行Program1和Program2,就会发现报错找不到Lib.so文件

同样的,如果再删掉Lib.so的情况下,像上面一样编译Program1和Program2,一样报错找不到链接文件Lib.so:

7.3 地址无关代码
关于上面在编译Lib.so时的-fPIC参数,作用是产生地址无关代码;

-fpic和-fPIC
使用GCC产生地址无关代码很简单,只需要使用“-fPIC”参数即可。实际上GCC还提供了另一个类似的参数“-fpic”,即“PIC”三个字母小写,这两个参数从功能上来讲完全一样,都是指示GCC产生地址无关代码。唯一的区别是,“-fPIC”产生的代码要大,而“-fpic”产生的代码相对较小,而且较快。那么为什么使用“-fPIC”而不是用“-fpic”呢?原因是,由于地址无关代码都是跟硬件平台相关的,不同的平台有着不同的实现,“-fpic”在某些平台上会有一些限制,比如全局符号的数量或者代码的长度等,而“fPIC”则没有这样的限制。
如何区分一个DSO是否为PIC
readelf -d foo.so | grep TENTREL
如果上面的命令有任何输出,那么foo.so就不是PIC的;如果上面的命令没有输出,那么foo.so就是PIC的。因为PIC的DSO是不会包含任何代码段重定位表的,TEXTREL表示代码段重定位表地址。
7.3.4 共享模块的全局变量问题
Q1:如果一个共享对象lib.so中定义了一个全局变量G,而进程A和进程B都使用了lib.so,那么当进程A改变这个全局变量G的值时,进程B中的G会受到影响吗?
A:不会,因为当lib.so被两个进程加载时,他的数据段部分在每个进程中都有独立的副本,从这个角度看,共享对象中的全局变量实际上和定义在程序内部的全局变量没什么区别。任何一个进程访问的只是自己的哪个副本而不会影响其他进程。
Q2:如果一个进程用到lib.so,而此进程里面的线程A和线程B是否能看到对方对lib.so中的全局变量G的修改呢?
A:对于同一个进程的两个线程来说,他们访问的是同一个进程地址空间,也就是同一个lib.so的副本,所以它们对G的修改,对方都是看得到的。
7.6 动态链接的步骤和实现
动态链接的步骤基本上分为3步:显示启动动态链接器本身,然后装载所有需要的共享对象,最后是重定位和初始化。
动态链接器是一个非常有特点的,也很特殊的共享对象,关于动态链接器(/lib/ld-linux.so.2)的实现的几个问题:
1、动态链接器本身是动态链接的还是静态链接的?
动态链接器本身应该是静态链接的,它不能依赖于其他共享对象,动态链接器本身是用来帮助其他ELF文件解决共享对象依赖问题的,如果它也依赖于其他共享对象,那么谁来帮它解决依赖问题?所以它本身必须不依赖于其他共享对象。这一点可以使用ldd来判断。
![]()
2、动态链接器本身必须是PIC的吗?
是不是PIC对于动态链接器来说并不关键,动态链接器可以是PIC的也可以不是,但往往使用PIC会更加的简单一些。一方面,如果不是PIC的话,会使得代码无法共享,浪费内存;另一方面也会使ld.so本身初始化更加复杂,因为自举时还需要对代码段进行重定位。实际上的ld-linux.so.2是PIC的。
3、动态链接器可以被当做可执行文件运行,那么装载地址应该是多少?
ls.so的装载地址跟一般的共享对象没区别,即为0x00000000.。这个装载地址是一个无效的装载地址,作为一个共享库,内核在装载它时会为其选择一个合适的装载地址。
第八章:linux共享库的组织
共享库的概念:从文件结构上讲,共享库和共享对象没什么区别,linux下共享库就是普通的ELF共享对象。由于共享对象可以被各个程序之间共享,所以他也就成为了库很好的存在形式,很多库的开发者都以共享对象的形式让程序来使用,久而久之,共享对象和共享库这两个概念已经很模糊了,所以广义上我们可以将他们看做是同一个概念。
8.3 共享库系统路径
目前大多数包括Linux在内的开源操作系统都遵守一个叫做FHS(File Hierarchy Standard)的标准,这个标准规定了一个系统中的系统文件应该如何存放,包括各个目录的结构、组织和作用,这有利于促进各个开源操作系统之间的兼容性。FHS规定,一个系统中主要有两个存放共享库的位置:
- /lib,这个位置主要存放系统最关键和基础的共享库,比如动态链接器、C语言运行库、数学库等,这些库主要是那些/bin 和 /sbin 下的程序所需要用到的库,还有系统启动时需要的库。
- /usr/lib,这个目录下主要保存的是一些非系统运行时所需要的关键性的共享库,主要是一些开发时用到的共享库,这些共享库一般不会被用户的程序或shell脚本直接用到。这个目录下面还包含了开发时可能用到的静态库、目标文件等。
- /usr/local/lib,这个目录用来安置一些跟操作系统本身并不十分相关的库,主要是一些第三方的应用程序的库。GNU的标准推荐第三方的程序应该默认将库安装到/usr/local/lib下。
所以总体来看,/lib 和 /usr/lib是一些很常用的、成熟的,一般是系统本身所需要的库;而/usr/local/lib是非系统所需的第三方程序的共享库。
8.4 共享库查找过程
为了程序的可移植性和兼容性,共享库的路径往往是相对的。
/etc/ld.so.conf是一个文本配置文件,它可能包含其他的配置文件,这些配置文件中存放着目录信息。作者的机器中,由ld.so.conf指定的目录是:
- /usr/local/lib
- /lib/i486-linux-gnu
- /usr/lib/i486-linux-gnu
如果动态链接器在每次查找共享库时都去遍历这些目录,那么将会非常耗时间。所以linux系统中都有一个叫ldconfig的程序,这个程序的作用是为共享目录下的各个共享库创建、删除或更新相应的SO-NAME(即相应的符号链接),这样每个共享库的SO-NAME就能够指向正确的共享库文件;并且这个程序还会将这些SO-NAME收集起来,集中存放在/etc/ld.so.cache文件里面,并建立一个SO-NAME的缓存。当动态链接器要查找共享库时,它可以直接从/etc/ld.so.cache的结构是经过特殊设计的,非常适合查找,所以这个设计大大加快了共享库的查找过程。
如果动态链接器在/etc/ld.so.cache里没有找到所需要的共享库,那么它会已办理/lib和/usr/lib这两个目录,如果还是没找到,就宣告失败。
所以理论上将,如果我们在系统指定的共享目录下添加、删除或更新任何一个共享库,或者我们更改了/ec/ld.so.conf的配置,都应该运行ldconfig这个程序,以便调整SO-NAME和/etc/ld.so.cache。很多软件包的安装程序往往在系统里面安装共享库以后都会调用ldconfig。
8.5 环境变量
LD_LIBRARY_PATH
改变共享库查找路径最简单的方法是使用LD_LIBRARY_PATH环境变量,这个方法可以临时改变某个应用程序的共享库查找路径,而不会影响系统中的其他程序。
在Linux系统中,LD_LIBRARY_PATH是一个由若干个路径组成的环境变量,每个路径之间由冒号隔开。默认情况下,LD_LIBRARY_PATH为空,如果我们为某个进程设置了LD_LIBRARY_PATH,那么进程在启动时,动态链接器在查找共享库时,会首先查找LD_LIBRARY_PATH指定的目录。这个环境变量可以很方便地让我们测试新的共享库或使用非标准的共享库。比如我们希望使用修改过的libc.so.6,可以将这个新版的libc放到我们的目录/home/usr中,然后指定LD_LIBRARY_PATH:
LD_LIBRARY_PATH=/home/usr /bin/ls
Linux中还有一种方法可以实现LD_LIBRARY_PATH类似的功能,那就是直接运行动态链接器来启动程序,比如:
/lib/ld-linux.so.2 -library-path /home/usr /bin /ls
就可以达到跟前面一样的效果。有了LD_LIBRARY_PATH之后,再来总节动态链接器查找共享库的顺序。动态链接器会按照下列顺序依次装载或查找共享对象(目标文件):
- 由环境变量LD_LIBRARY_PATH指定的路径。
- 由路径缓存文件?etc/ld.so.cache指定的路径
- 默认共享库目录,先/usr/lib,然后再/lib。
LD_LIBRARY_PATH对于共享库的开发和测试来说十分方便,但是不能滥用。LD_LIBRARY_PATH也会影响GCC编译时查找库的路径,它里面包含的目录相当于链接时GCC的“-L”参数。
LD_PRELOAD
系统中另外还有一个环境变量叫做LD_PRELOAD,这个文件中我们可以指定预先装载的一些共享库甚或是目标文件。在LD_PRELOAD里面指定的文件会在动态链接器按照固定搜索共享库之前装载,它比LD_LIBRARY_PATH里面所指定的目录还要优先。无论程序是否依赖于它们,LD_PRELOAD里面指定的共享库或目标文件都会被装载。
系统配置文件中有一个文件是/etc/ld.so.preload,它的作用跟LD_PRELOAD一样。
LD_DEBUG
另外还有一个非常有用的环境变量LD_DEBUG,这个变量可以打开动态链接器的调试功能,当设置这个变量时,动态链接器会在运行时打印出各种有用的信息,对于开发和调试共享库有很大的帮助。
例如:将LD_DEBUG设置成“files”,并且运行一个简单动态链接的HelloWorld:
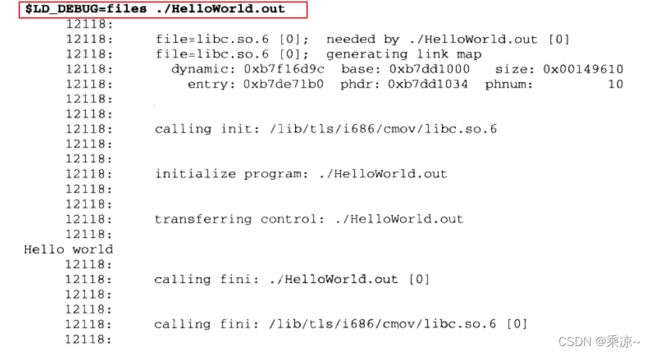
动态链接器打印出了整个装载过程,显示程序依赖于哪个共享库并且按照什么步骤装载和初始化,共享库装载时的地址等。LD_DEBUG还可以设置成其他值,比如:
- “binding”显示动态链接的符号绑定过程。
- “libs”显示共享库的查找过程。
- “versions”显示符号的版本依赖关系。
- “reloc”显示重定位过程。
- “symbols”显示符号表查找过程。
- “statistics”像是动态链接过程中的各种统计信息。
- “all”显示以上所有信息。
- “help”显示以上各种可选值的帮助信息。
8.6 共享库的创建和安装
8.6.1 共享库的创建
创建共享库,最关键的是使用GCC的两个参数,即“-shared”和“-fPIC”。“-shared”表示输出结果是共享库类型的;“-fPIC”表示使用地址无关代码技术来生产输出文件。另外还有一个参数是“-WI”,这个参数可以将指定的参数传递给链接器,比如使用“-WI、-soname、my_soname”时,GCC会将“-soname my_soname”传递给链接器,用来指定输出共享库的SO-NAME。如下
gcc -shared -Wl,-soname,my_soname -o library_name sourcefiles library_files
注意:如果不使用-soname来指定共享库的SO-NAME,那么该共享库默认就没有SO-NAME,即使用ldconfig更新SO-NAME的软连接时,对该共享库也没有效果。
举个例子:
如果有libfoo1.c和libfoo2.c两个源文件,希望产生一个libfoo.so.1.0.0的共享库,这个共享库依赖于libbar1.so和libbar2.so这两个共享库,使用如下命令:
gcc -shared -fPIC -Wl,-soname,libfoo.so.1 -o libfoo.so.1.0.0 \ libfoo1.c libfoo2.c \ -lbar1 -lbar2
或者分多步编译:
gcc -c -g -Wall -o libfoo1.o libfoo1.c
gcc -c -g -Wall -o libfoo2.o libfoo2.c
ls -shared -soname libfoo.so.1 -o libfoo.so.1.0.0 \ libfoo1.o libfoo2.o -lbar1 -lbar2
注意事项:
- 不要把输出共享库中的符号和调试信息去掉,也不要使用GCC的“-fomit-frame-pointer”选项,这样做虽然不会导致共享库停止运行,但是会影响调试共享库,给后面的工作带来很多麻烦。
- 在开发过程中,如果想要测试新库,但又不希望影响现有的程序正常运行,除了使用上面提到的LD_LIBRARY_PATH,还有一种方式即使用链接器的“-rpath”选项(或者GCC的-Wl,rpath),这种方式可以指定链接文件产生的目标程序的共享库查找路径。比如:
ld -rpath /home/mylib -o program.out program.o -lsomelib
这样输出的可执行文件program.out在被动态链接器装载时,动态链接器会首先在“/home/mylib”查找共享库。 - 默认情况下,链接器在产生可执行文件时,智慧将那些链接时被其他共享模块引用到的符号放到动态符号表,这样可以减少动态符号表的大小。也就是说,在共享模块中反向引用主模块中的符号时,只有那些在链接时被共享模块引用的符号才会被导出。有一种情况是,当程序使用dlopen()动态加载某个共享模块,而该共享模块须反向引用主模块的符号时,有可能主模块的某些符号因为在链接时没有被其他共享模块引用而没有被放到动态符号表里,导致了反向引用失败。ld链接器提供了一个“-export -dynamic”参数,表示链接器在生产可执行文件时,将所有全局符号导出到动态符号表,以防止出现上述问题。也可以在GCC中使用“-Wl,-export-dynamic”将该参数传递给链接器。
8.6.3 共享库的安装
创建库以后须将它安装在系统中,便于各种程序使用它。
方法1:将共享库复制到某个标准的共享库目录,如/lib、/usr/lib等,然后运行ldconfig即可。但是次方法需要root全向。
方法2:建立相应的SO-NAME软连接,并告诉编译器和程序如何查找该共享库,以便于编译器和程序都能正常运行。建立SO-NAME的办法也是使用ldconfig,不过需要指定共享库所在目录:
ldconfig -n shared_library_directory
在编译程序时,也需要指定共享库的位置,GCC提供了两个参数“-L”和“-l”,分别用于指定共享库搜索目录和共享库的路径。当然也可以使用“-rpath”参数,都可以指定共享库的位置。
比如我们把libtest.so放在/aaa/bbb/ccc目录下,那链接参数就是-L/aaa/bbb/ccc -ltest
8.6.4 共享库构造和析构函数
GCC提供了一种共享库的构造函数,只要在函数声明时加上“__attribute__((constructor))”的属性,即指定该函数为共享库构造函数,拥有这种属性的函数会在共享库被加载时运行,即在程序的main函数之前执行。
声明构造函数的格式如下:
void __attribute__((constructor)) init_function(void)
与共享库构造函数相对应的是析构函数,在函数声明时加上“__attribute__((destructor))”的属性,这种函数就会在main()函数执行完毕之后执行(或是程序调用exit()时执行)。
声明构造函数和析构函数的格式如下:
void __attribute__((destructor)) init_function(void)
另外还有一个问题是,如果需要有多个构造函数,那么默认情况下,他们的执行顺序是没有规定的。如果需要构造函数和析构函数按照一定的顺序执行,GCC提供了一个参数叫做优先级,可以指定某个构造或析构函数的优先级:
void __attribute__((constructor(5))) init_function(void)
void __attribute__((constructor(10))) init_function(void)
对于构造函数来说,属性中的数字越小的函数将会在优先级大的函数前面运行;而对于析构函数则正好相反。这种安排有利于构造函数和析构函数相匹配。比如某一对构造函数和析构函数分别用来申请内存和释放某个资源,那么他们可以拥有一样的优先级。这样做的结果是现申请的资源后释放,符合资源释放的一般原则。
8.6.5 共享库脚本
共享库还可以是符合一定格式的链接脚本文件。通过这种脚本文件,可以把几个现有的共享库通过一定的方式组合起来,从用户的角度看就是一个新的共享库。比如把C运行库和数学库组合成一个新的库libfoo.so,那么libfoo.so的内容可以如下:
GROUP( /lib/libc.so.6 /lib/libm.so.2)
第四部分 库与运行库
第10章 内存
10.1 程序的内存布局
在32位的系统里,这个内存拥有4GB(2的32次方)的寻址能力。Linux默认将高地址的1GB空间分配给内核。用户使用剩下的3GB内存空间成为用户空间。

Q:程序常常出现“段错误(segment fault)”或者“非法操作,该内存地址不能read/write”错误信息是什么情况?
A:这是典型的非法指针解引用造成的错误。当指针指向一个不允许读或写的内存地址,而程序却试图利用指针来读或写该地址的时候,就会出现这个错误。在Linux或Windows的内存布局中,有些地址是始终不能读写的,例如0地址。还有些地址是一开始不允许读写,应用程序必须事先请求获取这些地址的读写权,或者某些地址一开始并没有映射到实际的物理内存,应用程序必须事先请求将这些地址映射到实际的物理地址(commit),之后才能够自由地读写这片内存。当一只指针指向这些区域的时候,对它指向的内存进行读写就会引发错误。
所以最普遍的原因有两种:
1、程序员将指针初始化为NULL,之后没有给它一个合理的值就开始使用它。
2、程序员没有初始化栈上的指针,指针的值一般会是随机数,之后就直接开始使用指针。
所以如果程序出现这样的错误,着重检查指针使用情况。
10.2 栈与调用惯例
栈是一个特殊的容器,用户可以将数据压入栈中(入栈,push),也可以将压入栈中的数据弹出(出栈,pop),栈要遵循先入后出的原则。栈总是向下增长的。压栈的操作使栈顶的地址减小,弹出的操作使栈顶增大。
10.3 堆与内存管理
10.3.2 Linux进程堆管理
Linux下的进程堆管理提供了两种堆空间分配方式,即两个系统调用:一个是brk()系统调用,另一个是mmap()。
glibc的malloc函数是这样处理用户的空间请求的:对于小于128KB的请求来说,它会在现有的堆空间里面只能找对分配算法分配一块空间并返回;对于大于128KB的请求来说,使用mmap()函数分配一块匿名空间,然后再这个匿名空间中为用户分配空间。
第11章:运行库
11.1 入口函数和程序初始化
11.1.3 运行库与I/O
IO(或I/O)全称是Input/Output,即输入和输出。一个程序的I/O只带了程序与外界的交互,包括文件、管道、网络、命令行、信号等。C语言文件操作是通过一个FILE结构的指针来进行的。fopen函数返回一个FILE结构的指针,而其他函数如fwrite使用这个指针操作文件。
