【NLP模型】文本建模(2)TF-IDF关键词提取原理
一、说明
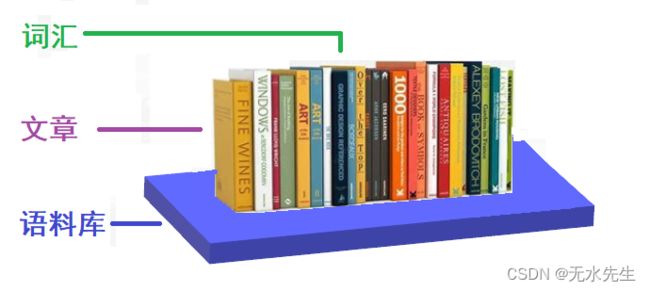
tf-idf是个可以提取文章关键词的模型;他是基于词频,以及词的权重综合因素考虑的词价值刻度模型。一般地开发NLP将包含三个层次单元:最大数据单元是语料库、语料库中有若干文章、文章中有若干词语。这样从词频上说,就有词在文章的频率,词在预料库的频率,文章在预料库的频率等概念,合理用这些概念,提取词的真实价值,起到提取关键词的目的。
二、TF-IDF基本概念
2.1 预料库、文章、单词的关系
一般地开发NLP将包含三个层次单元:最大数据单元是语料库、语料库中有若干文章、文章中有若干词语。这里先对这个数据结构进行说明:
- 语料库:预料库由海量的文章组成,并且各领域的文章的分布不能太偏。
- 文章:每个文章都属于一个领域,不同领域的文章高频高频词汇是不同的。
- 词汇:每个文章都由词汇构成,每个词汇的出现频率可以用对应直方图表示。
2.2 什么是tf,什么是idf
假设文库中有两本书《金陵税负考》、《宇宙能量分析》词频高在文章中往往是停用词,“的”,“是”,“了”等,这些在文档中最常见但对结果毫无帮助、需要过滤掉的词,用TF可以统计到这些停用词并把它们过滤。当高频词过滤后就只需考虑剩下的有实际意义的词。
但这样又会遇到了另一个问题,我们可能发现"量化"、"系统"、"架构"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?事实上系统应该在其他文章比较常见,所以在关键词排序上,“量化”和“架构”应该排在“系统”前面,这个时候就需要IDF,IDF会给常见的词较小的权重,它的大小与一个词的常见程度成反比。
TF-IDF 代表记录的词频逆文档频率。它可以定义为计算系列或语料库中的单词与文本的相关程度。含义与单词在文本中出现的次数成比例地增加,但由语料库(数据集)中的单词频率补偿。
1)TF-术语频率:
术语频率:在文档 d 中,频率表示给定单词 t 的实例数。因此,我们可以看到当一个词出现在文本中时,它变得更相关,这是合理的。由于术语的顺序并不重要,我们可以使用向量来描述术语模型包中的文本。
什么是 TF(词频)?
术语频率的工作原理是查看您关注的特定术语相对于文档的频率。有多种定义频率的度量或方法:
- 单词在文档中出现的次数(原始计数)。
- 根据文档长度调整的词频(原始出现次数除以文档中的单词数)。
- 对数标度频率(例如 log(1 + raw count))。
- 布尔频率(例如,如果该术语出现,则为 1;如果该术语未出现,则为 0,在文档中)。
文档中出现的术语的权重与术语频率成正比。举个例子:
下图表示8篇文章组成语料库,其中“能量”这个词在【1,3,4】文章中频率较高,说明对于【1,3,4】“能量”是该文章的特征,可以视其为关键词。

2)DF-文档频率
-
Document Frequency:测试整个语料库中文本的含义,与TF非常相似。唯一的区别是在文档d中,TF是词条t的频率计数器,而df是词条t在文档集合N中出现的次数。换句话说,出现该词的论文的数量是 DF。
df(t) = 有N篇文章出现 t关键词
下图的蓝色区域表示”但是“这个词分布很广,全部9个文章中都出现,
df(t="但是")=9
显然,单词”但是“既然分布在各种各样的文章中,因此它与文章的特征无关,不能作为关键词,应该删除。

3)IDF-反向文档频率
反向文档频率:这个概念是用来模拟语言的使用环境。这时需要一个语料库(corpus)。

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
2.4 计算TF-IDF
Tf-idf :是确定术语对系列或语料库中的文本有多重要的最佳指标之一。
tf-idf 是一种加权系统,它根据词频 (tf) 和倒数文档频率 (tf) (idf) 为文档中的每个词分配权重。权重较高的词被认为更重要。
通常,tf-idf 权重由两项组成
- 归一化词频 (tf)
- 反向文档频率 (idf)
三、TF-IDF的python实验
3.1 基本调用方法
在 python 中,可以使用 sklearn 模块中的 TfidfVectorizer() 方法计算 tf-idf 值。
1)句法格式:
sklearn.feature_extraction.text.TfidfVectorizer(input)
2)参数说明:
input:指传递的参数文档,可以是文件名,文件或内容本身。
属性:
vocabulary_:它返回一个术语字典作为键和值作为特征索引。
idf_:它返回作为参数传递的文档的逆文档频率向量。
3)返回说明return:
fit_transform():它返回一组术语以及 tf-idf 值。
get_feature_names():它返回特征名称列表。
3.2 循序渐进的方法:
1)导入Python3模块。
|
|
-
从文档中收集字符串并创建一个语料库,其中包含文档 d0、d1 和 d2 中的字符串集合。
-
Python3
|
|
2) 从 fit_transform() 方法获取 tf-idf 值。
|
|
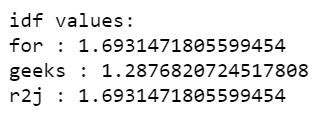
3)显示语料库中出现的单词的 idf 值。
|
|
Output:
4)显示 tf-idf 值以及索引。
|
|
Output:

结果变量由独特的单词和 tf-if 值组成。可以使用下图对其进行详细说明:
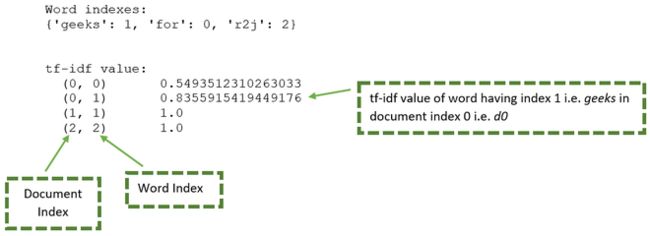
从上图可以生成下表:
| 文章 | 单词 | 文章序号 | 单词序号 | tf-idf值 |
|---|---|---|---|---|
| d0 | for | 0 | 0 | 0.549 |
| d0 | geeks | 0 | 1 | 0.8355 |
| d1 | geeks | 1 | 1 | 1.000 |
| d2 | r2j | 2 | 2 | 1.000 |
四、计算语料库中单词的 tf-idf 值的示例
4.1 示例 1:
下面是基于上述方法的完整程序:
Python3
|
|
Output:

4.2 示例 2:
此处,tf-idf 值是根据具有唯一值的语料库计算得出的。
Python3
|
|
Output:

4.3 示例 3:
在此程序中,tf-idf 值是根据具有相似文档的语料库计算的。
Python3
|
|
Output:
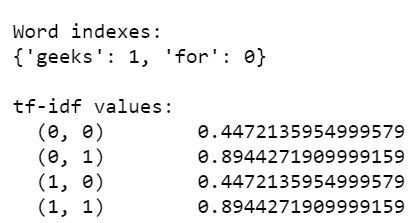
4.4 示例 4:
下面是我们尝试计算单个单词 geeks 在多个文档中重复多次的 tf-idf 值的程序。
Python3
|
|
Output:

4.5 另一个文本分析例子TF-IDF
""" sklearn > feature_extraction > text > TfidfTransformer 将计数矩阵转换为标准化的 tf 或 tf-idf 表示 Tf 表示词频(即出现的原始频率) Tf-idf 表示术语频率乘以逆文档频率 Tf-idf 的目标是减少频繁出现的标记的影响 参数 范数:l1、l2 或无。用于规范化术语向量的范数 use_idf :布尔值。启用反向文档频率重新加权 smooth_idf :布尔值。平滑 idf 权重并防止零划分 sublienar_tf :布尔值。应用次线性 tf 缩放(即替换 tf 用 1 + log(tf)) 方法 fit(X[,y]) :学习 idf 向量(全局项权重) fit_transform(X[,y]) :适合数据,然后转换 get_params([deep]) :获取此估计器的参数 set_params(**params) : 设置这个估计器的参数 transform(X[,copy]) :将计数矩阵转换为 tf 或 tf-df 表示
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
corpus = [ '原子弹 芒果 应用', '芒果 应用', '原子弹 应用', '应用']
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
X = vectorizer.fit_transform(corpus)
tfidf = transformer.fit_transform(X)
word = vectorizer.get_feature_names()
weight = tfidf.toarray()
for i in range(len(weight)):
print("-------第", i+1, "段文本的词语tf-idf权重------")
for j in range(len(word)):
print(word[j], weight[i][j])