[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds
摘要
However, these models are large, with complex network architectures and tens of denoising
As a result, high-end GPUs and cloud-based inference are required to run diffusion models at
This is costly and has privacy implications, especially when user data is sent
To overcome these challenges, we present a generic approach that, for the first time, unlocks running text-to-image diffusion models on mobile devices in less than 2 seconds .
We achieve so by introducing efficient network architecture and improving step distillation.
Specifically, we propose an efficient UNet by identifying the redundancy of the original model and reducing the computation of the image decoder via data distillation.
Further, we enhance the step distillation by exploring training strategies and introducing regularization from classifier-free guidance.
Our extensive experiments on MS-COCO show that our model with 8 denoising steps achieves better FID and CLIP scores than Stable Diffusion v 1 . 5 with 50 steps.
Our work democratizes content creation by bringing powerful text-to-image diffusion models to the hands of users 1 .
文本到图像的扩散模型可以从自然语言中创造出令人惊叹的图像与专业艺术家和摄影师的作品相媲美的描述。
然而,这些模型非常庞大,具有复杂的网络结构和数十次去噪迭代,使它们在计算上昂贵且运行缓慢。
因此,需要高端gpu和基于云的推理来运行扩散模型规模。
这是昂贵的,并且涉及隐私问题,特别是在发送用户数据时给第三方。
为了克服这些挑战,我们提出了一种通用方法,首次在不到2秒的时间内解锁移动设备上运行的文本到图像扩散模型。
我们通过引入高效的网络结构和改进步进蒸馏来实现这一目标。
具体来说,我们通过识别原始模型的冗余并通过数据蒸馏减少图像解码器的计算,提出了一种高效的UNet。
此外,我们通过探索训练策略和引入无分类器引导的正则化来增强步进蒸馏。
我们在MS-COCO上的大量实验表明,我们的模型具有8个去噪步骤,比具有50个步骤的Stable Diffusion v1.5获得更好的FID和CLIP分数。
我们的工作通过将强大的文本到图像的扩散模型带到用户手中,使内容创作民主化。
Introduction
Diffusion-based text-to-image models [1, 2, 3, 4] show remarkable progress in synthesizing photorealistic content using text prompts.
They profoundly impact the content creation [5, 6], image editing and in-painting [7, 8, 9, 10, 11], super-resolution [12], video synthesis [13, 14], and 3D assets generation [15, 16, 17], to name a few.
This impact comes at the cost of the substantial increase in the computation requirements to run such models [18, 19, 20].
As a result, to satisfy the necessary latency constraints large scale, often cloud-based inference platforms with high-end GPU are required.
This incurs high costs and brings potential privacy concerns, motivated by the sheer fact of sending private images, videos, and prompts to a third-party service.
基于扩散的文本到图像模型[1,2,3,4]在使用文本提示将pho合成为逼真内容方面取得了显著进展。它们深刻地影响着内容创作[5,6]、图像编辑和绘画[7,8,9,10,11]、超分辨率[12]、视频合成[13,14]和3D资产生成[15,16,17]等。
这种影响的代价是运行此类模型的计算需求大幅增加[18,19,20]。
因此,为了满足必要的大规模延迟约束,通常需要基于云的高端GPU推理平台。
这招致了高昂的成本,并带来了潜在的隐私问题,其动机是向第三方服务发送私人图像、视频和提示。
Recent works use quantization [ 21 , 22 ] or GPU-aware optimization to reduce the run time, i.e. , accelerating the diffusion pipeline to 11 . 5 s on Samsung Galaxy S23 Ultra [ 23 ].
While these methods effectively achieve a certain speed-up on mobile platforms, the
毫不奇怪,人们正在努力加快移动设备上文本到图像扩散模型的推断速度。
最近的研究使用量化[21,22]或gpu感知优化来缩短运行时间,即在三星Galaxy S23 Ultra上将扩散流水线加速到11.5s[23]。Speed is all you need
虽然这些方法在移动平台上有效地实现了一定的加速,但是获得的延迟不能提供无缝的用户体验。此外,现有的研究都没有通过定量分析系统地考察设备上模型的生成质量。
To achieve this, we mainly focus on improving the slow inference speed of the UNet and reducing the number of necessary denoising steps.
First , the architecture of UNet , which is the major bottleneck for the conditional diffusion model (as we show in Tab. 1 ), is rarely optimized in the literature.
Existing works primarily focus on post-training optimizations [ 24 , 25 ].
Consequently, the architecture redundancies are not fully exploited, resulting in a limited acceleration ratio.
Second , the flexibility of the denoising diffusion process is not well explored for the on-device model.
Directly reducing the number of denoising steps impacts the generative performance, while progressively distilling the steps can mitigate the impacts [ 31 , 32 ].
在这项工作中,我们提出了第一个文本到图像的扩散模型,该模型可以在不到2秒的时间内在移动设备上生成图像。
为了实现这一目标,我们主要关注提高UNet缓慢的推理速度和减少必要的去噪步骤。
首先,UNet的架构是条件扩散模型的主要瓶颈(如表1所示),在文献中很少进行优化。
现有的工作主要集中在训练后优化[24,25]。
传统的压缩技术,如模型修剪[26,27,28]和架构搜索[29,30],会降低预训练扩散模型的性能,如果没有大量的微调,很难恢复。
因此,架构冗余没有被充分利用,导致有限的加速比。
其次,对于器件上模型(on-device model),去噪扩散过程的灵活性没有得到很好的探索。
直接减少去噪步骤会影响生成性能,而逐步提取步骤(progressively distilling the steps)可以减轻影响[31,32]。
然而,步进蒸馏的学习目标和设备上模型的训练策略还有待深入研究,特别是对于使用大规模数据集训练的模型。
This work proposes a series of contributions to address the aforementioned challenges:
• We provide an in-depth analysis of the denoising UNet and identify the architecture redundancies.
• We propose a novel evolving training framework to obtain an efficient UNet that performs better than the original Stable Diffusion v1.52 while being significantly faster.
We also introduce a data distillation pipeline to compress and accelerate the image decoder.
• We improve the learning objective during step distillation by proposing additional regularization, including losses from the v-prediction and classifier-free guidance [33].
• Finally, we explore the training strategies for step distillation, especially the best teacher-student paradigm for training the on-device model.
Through the improved Step distillation and network architecture development for the difFusion model, our introduced model, SnapFusion, generates a 512 × 512 image from the text on mobile devices in less than 2 seconds, while with image quality similar to Stable Diffusion v1.5 [4] (see example images from our approach in Fig. 1).
这项工作提出了一系列应对上述挑战的贡献:
1 我们提供了去噪UNet的深入分析,并确定了架构冗余。
2 我们提出了一种新的进化训练框架,以获得比原来的Stable Diffusion v1.52更好的高效UNet,同时速度也明显快得多。
我们还引入了一个数据蒸馏管道来压缩和加速图像解码器。
3 我们通过提出额外的正则化来改进步进蒸馏过程中的学习目标,包括v-预测和无分类器引导的损失[33]。
4 最后,我们探讨了步进蒸馏的训练策略,特别是用于训练设备上模型的最佳师生范式。
通过改进的Step蒸馏和扩散模型的网络架构开发,我们引入的模型SnapFusion在不到2秒的时间内从移动设备上的文本生成512 × 512的图像,而图像质量与Stable difFusion v1.5[4]相似(参见图1中我们方法的示例图像)。
![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第1张图片](http://img.e-com-net.com/image/info8/75d59f8487b74d228354473d0c70fad9.jpg)
Here we comprehensively study the parameter and computation intensity of the SD-v1.5.
The in-depth analysis helps us understand the bottleneck to deploying text-to-image diffusion models on mobile devices from the scope of network architecture and algorithm paradigms. Meanwhile, the micro-level breakdown of the networks serves as the basis of the architecture redesign and search.
Macro Prospective.
As shown in Tab. 1 and Fig. 3, the networks of stable diffusion consist of three major components.
Text encoder employs a ViT-H model [40] for converting input text prompt into embedding and is executed in two steps (with one for CFG) for each image generation process, constituting only a tiny portion of inference latency (8 ms).
The VAE decoder takes the latent feature to generate an image, which runs as 369 ms.
Unlike the above two models, the denoising UNet is not only intensive in computation (1.7 seconds latency) but also demands iterative forwarding steps to ensure generative quality.
For instance, the total denoising timesteps is set to 50 for inference in SD-v1.5, significantly slowing down the on-device generation process to the minute level.
宏观经济预期。
从表1和图3可以看出,稳定扩散网络主要由三个部分组成。
1 文本编码器采用ViT-H模型[40]将输入文本提示转换为嵌入,每个图像生成过程分两步执行(其中一步用于CFG),仅占推理延迟的很小一部分(8 ms)。
2 VAE解码器利用潜特征生成图像,运行时间为369 ms。
3 与上述两种模型不同,去噪UNet不仅计算量大(1.7秒延迟),而且需要迭代转发步骤以确保生成质量。
例如,SD-v1.5中用于推断的总去噪时间步长设置为50,显著地将设备上的生成过程减慢到分钟级别。
![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第2张图片](http://img.e-com-net.com/image/info8/ca7d1afb8f9f4d48878678e67e521286.jpg)
Breakdown for UNet.
The time-conditional (t) UNet consists of cross-attention and ResNet blocks.
Specifically, a cross-attention mechanism is employed at each stage to integrate text embedding (c) into spatial features: Cross-Attention(Qzt , Kc, Vc) = Softmax( Qzt ·) · Vc, where Q is projected from noisy data zt, K and V are projected from text condition, and d is the feature dimension.
UNet also uses ResNet blocks to capture locality, and we can formulate the forward of UNet as:
UNet的细分。
时间条件(t) UNet由交叉注意块和ResNet块组成。
具体来说,在每个阶段采用交叉注意机制将文本嵌入(c)整合到空间特征中:交叉注意(Qzt, Kc, Vc) = Softmax(Qzt·)·Vc,其中Q是由噪声数据zt投影而来,K和V是由文本条件投影而来,d是特征维数。
UNet也使用ResNet块来捕获局部性,我们可以将UNet的forward表述为:
The distribution of parameters and computations of UNet is illustrated in Fig. 2, showing that parameters are concentrated on the middle (downsampled) stages because of the expanded channel dimensions, among which ResNet blocks constitute the majority.
In contrast, the slowest parts of UNet are the input and output stages with the largest feature resolution, as spatial cross-attentions have quadratic computation complexity with respect to feature size (tokens).
UNet的参数分布和计算如图2所示,由于通道尺寸的扩大,参数集中在中间(下采样)阶段,其中ResNet块占大多数。
相比之下,UNet中最慢的部分是具有最大特征分辨率的输入和输出阶段,因为空间交叉关注相对于特征大小(令牌)具有二次计算复杂度。
![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第3张图片](http://img.e-com-net.com/image/info8/1c9f3cfc4bc44cf19e91833f366a7f9e.jpg)
3 Architecture Optimizations
架构优化
Here we investigate the architecture redundancy of SD-v1.5 to obtain efficient neural networks.
However, it is non-trivial to apply conventional pruning [41, 42, 43, 44] or architecture search [45, 46,30] techniques, given the tremendous training cost of SD.
Any permutation in architecture may lead to degraded performance that requires fine-tuning with hundreds or thousands of GPUs days.
Therefore, we propose an architecture-evolving method that preserves the performance of the pre-trained UNet model while gradually improving its efficacy.
As for the deterministic image decoder, we apply tailored compression strategies and a simple yet effective prompt-driven distillation approach.
本文研究了SD-v1.5的架构冗余,以获得高效的神经网络。
然而,考虑到SD的巨大训练成本,应用传统的剪枝[41,42,43,44]或架构搜索[45,46,30]技术并非易事。
架构中的任何排列都可能导致性能下降,需要数百或数千个gpu天进行微调。
因此,我们提出了一种架构进化方法,在保持预训练UNet模型性能的同时逐步提高其效率。
对于确定性图像解码器(deterministic image decoder),我们采用定制tailored的压缩策略和简单而有效的提示驱动蒸馏方法。
3.1 Efficient UNet
From our empirical observation, the operator changes resulting from network pruning or searching lead to degraded synthesized images, asking for significant training costs to recover the performance.
Thus, we propose a robust training, and evaluation and evolving pipeline to alleviate the issue.
Robust Training.
Inspired by the idea of elastic depth [47, 48], we apply stochastic forward propagation to execute each cross-attention and ResNet block by probability p(·, I), where I refers to identity mapping that skips the corresponding block.
Thus, we have Eq. (4) becomes as follows:
ϵˆθ(t, zt) = Y {p(Cross-Attention(zt, c), I), p(ResNet(zt, t), I)}.
(5)
With this training augmentation, the network is robust to architecture permutations, which enables an accurate assessment of each block and a stable architectural evolution (more examples in Fig. 5).
从我们的经验观察来看,由于网络修剪或搜索导致的算子变化导致合成图像降级,需要大量的训练成本来恢复性能。
因此,我们提出了一个健全的培训、评估和发展管道来缓解这个问题。
Robust Training.
受弹性深度思想的启发[47,48],我们应用随机前向传播以概率p(·,I)执行每个交叉关注和ResNet块,其中I指跳过相应块的身份映射。
由此,我们得到(4)式为:![]()
有了这种训练增强,网络对体系结构排列具有鲁棒性,这使得网络能够实现
准确评估每个块和稳定的架构演变(图5中有更多示例)。
Figure 5: Advantages of robust training .
Prompts of top row: a photo of an astronaut riding a horse on mars and bottom row:
A pikachu fine dining with a view to the Eiffel Tower .
(a) Images from SD-v1.5.
(b) Removing cross-attention (CA) blocks in downsample stage of SD-v1.5.
(c) - (e) Removing cross-attention (CA) blocks in {downsample (DS), middle (mid.), upsample (US)} using our model after robust training. (f) - (h) Removing ResNet blocks (RB) in different stages using our model.
The model with robust training maintains reasonable performance after dropping blocks.图5: 健壮训练的优点。
上一行提示:宇航员在火星上骑马的照片,下一行提示:
能看到埃菲尔铁塔的皮卡丘餐厅。
(a)来自SD-v1.5的图像。
(b)去除SD-v1.5下采样阶段的交叉注意(CA)块。
(c) - (e)在鲁棒训练后使用我们的模型去除{downsample(DS),middle(mid.),upsample(US)}中的交叉注意(CA)块。
(f) - (h)使用我们的模型在不同阶段移除ResNet块(RB)。经过鲁棒训练的模型在丢块后仍能保持合理的性能
![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第4张图片](http://img.e-com-net.com/image/info8/3d82999aa1c5466783174a531b50eb71.jpg)
Evaluation and Architecture Evolving.
We perform online network changes of UNet using the model from robust training with the constructed evolution action set:
A ∈ {A+,−Cross-Attention[i,j] , A+,−ResNet[i,j]}, where A+,− denotes the action to remove (−) or add (+) a cross-attention or ResNet block at the corresponding position (stage i, block j). Each action is evaluated by its impact on execution latency and generative performance.
For latency, we use the lookup table built in Sec. 2.2 for each possible configuration of cross-attention and ResNet blocks.
Note we improve the UNet for on-device speed; the optimization of model size can be performed similarly and is left as future work.
For generative performance, we choose CLIP score [40] to measure the correlation between generated images and the text condition.
We use a small subset (2K images) of MS-COCO validation set [49], fixed steps (50), and CFG scale as 7.5 to benchmark the score, and it takes about 2.5 A100 GPU hours to test each action.
For simplicity, the value score of each action is defined as CLIP ∆Latency , where a block with lower latency and higher contribution to CLIP tends to be preserved, and the opposite is removed in architecture evolving (more details in Alg. 1).
To further reduce the cost for network optimization, we perform architecture evolving, i.e., removing redundant blocks or adding extra blocks at valuable positions by executing a group of actions at a time.
Our training paradigm successfully preserves the performance of pre-trained UNet while tolerating large network permutations (Fig. 5).
The details of our final architecture is presented in Sec. A.
我们使用鲁棒训练的模型和构建的进化动作集来执行UNet的在线网络变化:
A∈{A+,−Cross-Attention[i,j], A+,−ResNet[i,j]},其中A+,−表示在相应位置(阶段i,块j)移除(−)或添加(+)交叉注意或ResNet块的动作。
每个动作通过其对执行延迟和生成性能的影响来评估。
对于延迟,我们使用2.2节中构建的查找表来查找交叉注意和ResNet块的每种可能配置。![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第5张图片](http://img.e-com-net.com/image/info8/bd5edcc04e75477f9b5aafdb63f2cd64.jpg)
注意,我们改进了UNet的设备上速度;模型尺寸的优化可以类似地进行,并留给未来的工作。
对于生成性能,我们选择CLIP分数[40]来衡量生成的图像与文本条件之间的相关性。
我们使用MS-COCO验证集[49]的一个小子集(2K图像),固定步骤step(50),CFG尺度为7.5来基准测试分数,每个动作测试大约需要2.5 A100 GPU小时。
为简单起见,将每个动作的价值评分定义为∆CLIP/∆Latency,其中倾向于保留延迟较低且对CLIP贡献较大的块,而在架构演变中删除相反的块(详见图1)。
为了进一步降低网络优化的成本,我们执行架构进化,即通过一次执行一组操作来删除冗余块或在有价值的位置添加额外块。
我们的训练范式成功地保留了预训练UNet的性能,同时容忍了大的网络排列(permutations )(图5)。
我们最终架构的细节在章节A中给出。
Sec A
We provide the detailed architecture of our efficient UNet in Tab. 3 .
We perform denoising diffusion in latent space [ 4 ].
Consequently, the input and output resolution for UNet is H / 8 × W / 8 , which is 64 × 64 for generating an image of 512 × 512 .
In addition to mobile phones, we show the latency and memory benchmarks on Nvidia A100 40G GPU, as in Tab. 4 .
We demonstrate that our efficient UNet achieves over 12 × speedup compared to the original SD-v1.5 on a server-level GPU and shrinks 46% running memory.
The analysis is performed via the public TensorRT [ 62 ] library in single precision.我们在表3中提供了高效UNet的详细架构。
我们在潜空间中进行去噪扩散[4]。
因此,UNet的输入和输出分辨率为H8 × w8,这是64×64,用于生成512×512的图像。
除了手机,我们还展示了Nvidia A100 40G GPU上的延迟和内存基准测试,如表4所示。
我们证明,与服务器级GPU上的原始SD-v1.5相比,我们的高效UNet实现了超过12倍的加速,并缩减了46%的运行内存。
分析是通过公共TensorRT[62]库以单精度执行的。
![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第6张图片](http://img.e-com-net.com/image/info8/833ba642f2e043eab5bf628737afdf41.jpg)
![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第7张图片](http://img.e-com-net.com/image/info8/2ca7dcd56f3b4fc6844dc45502e4a047.jpg)
![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第8张图片](http://img.e-com-net.com/image/info8/14d28b4d2adf42fe95c8fe0178f9c4f9.jpg)
![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第9张图片](http://img.e-com-net.com/image/info8/6ace2da1383c4409b3d3275e860fd226.jpg)
3.2 Efficient Image Decoder 压缩解码器
For the image decoder, we propose a distillation pipeline that uses synthetic data to learn the efficient image decoder obtained via channel reduction, which has 3.8× fewer parameters and is 3.2× faster than the one from SD-v1.5.
Here we only train the efficient decoder instead of following the training of VAE [4, 37, 38] that also learns the image encoder. We use text prompts to get the latent representation from the UNet of SD-v1.5 after 50 denoising steps and forward it to our efficient image decoder and the one of SD-v1.5 to generate two images.
We then optimize the decoder by minimizing the mean squared error between the two images. Using synthetic data for distillation brings the advantage of augmenting the dataset on-the-fly where each prompt be used to obtain unlimited images by sampling various noises.
Quantitative analysis of the compressed decoder can be found in Sec. B.2.
对于图像解码器,我们提出了一个蒸馏管道,该管道使用合成数据来学习通过信道约简(channel reduction)获得的高效图像解码器,其参数比SD-v1.5少3.8倍,速度比SD-v1.5快3.2倍。
这里我们只训练有效的解码器,而不是遵循同样学习图像编码器的VAE[4,37,38]的训练。
我们使用文本提示从SD-v1.5的UNet中获得50步去噪后的潜在表示,并将其转发给我们的高效图像解码器和SD-v1.5的解码器,生成两幅图像。
然后我们通过最小化两幅图像之间的均方误差来优化解码器。
使用合成数据进行蒸馏的优点是可以实时增加数据集,每个提示都可以通过采样各种噪声来获得无限的图像。
压缩解码器的定量分析可以在第B.2节中找到。
B.2 VAE DecoderWe provide qualitative visualizations and quantitive results of our compressed VAE decoder in Fig. 7 .The main paper shows that the image decoder constitutes a small portion of inference latency ( 369 ms) compared to the original UNet from SD-v1.5.
However, regarding our optimized pipeline ( 230 ms × 8 steps), the decoder consumes a considerable portion of overall latency.
We propose an effective distillation paradigm to compress the VAE decoder.
Specifically, we obtain the latent-image pairs by forwarding the text prompts into the original SD-v1.5 model.
The student, which is the compressed decoder, takes the latent from the teacher model as input and generates an output image that is optimized with the ones from the teacher model by the mean squared error.
Our proposed method wields the following advantages.
First, our approach does not demand paired text-image samples, and it can generate unlimited data on-they-fly, benefiting the generalization of the compressed decoder.Second, the distillation paradigm is simple and straightforward, requiring minimal implementation efforts compared to conventional VAE training.
As in Fig. 7 , our compressed decoder ( 116ms) provides comparable generative quality, and the performance degradation compared to the original VAE decoder is negligible.我们在图7中提供了压缩VAE解码器的定性可视化和定量结果。
主要论文表明,与SD-v1.5的原始UNet相比,图像解码器构成了一小部分推理延迟(369ms)。
然而,对于我们优化的管道(230ms × 8步),解码器消耗了相当大一部分的总延迟。
(与原始的UNet(50step)耗时相比,decoder时间消耗占比较少,但是对于本文优化的unet(8step)相比这个时间就很多了。)
我们提出了一种有效的压缩VAE解码器的蒸馏范式。
具体来说,我们通过将文本提示转发到原始SD-v1.5模型中来获得潜在图像对。
student model,也就是compressed decoder,将教师模型的latent作为输入,并生成一个输出图像,该输出图像通过均方误差(mean squared error)与教师模型的隐函数进行优化。
我们提出的方法具有以下优点。
首先,我们的方法不需要配对的文本图像样本,并且它可以动态生成无限的数据,有利于压缩解码器的泛化。
第二,蒸馏范例简单而直接,与传统的VAE培训相比,需要最少的实现努力。
如图7所示,我们的压缩解码器(116ms)提供了相当的生成质量,与原始VAE解码器相比,性能下降可以忽略不计。
左图:上面是原始的,下面是compressed decoder
右图:
FID评价图像真实度(FID 值越低,越好。)
CLIP评价文本、图像相关性(CLIP值越大,越好)Version:0.9 StartHTML:0000000105 EndHTML:0000009532 StartFragment:0000000141 EndFragment:0000009492Citing the wisdom from previous studies [ 32 , 31 ], step distillation works best with the v -predictiontype, i.e. , UNet outputs velocity v [ 32 ] instead of the noise ϵ . Thus, we fine-tune SD-v1.5 to vprediction (for notation clarity, we useˆvθ to mean the SD model in v -prediction vs. its ϵ -predictioncounterpart ϵ ˆ θ ) before step distillation, with the following original loss L ori :L ori = E t ∼ U [0 , 1] , x ∼ p data ( x ) , ϵ ∼N ( 0 , I ) ||ˆvθ ( t, z t , c ) − v || 2
右下角比较好图7:使用MS-COCO 2014验证集进行评估[49]。
(a) 使用SD-v1.5的解码器和本文compressed image decoder。
UNet是我们高效的UNetCFG的指导等级为9.0。
(b) 6K采样的定量比较。考虑到广泛使用的CFG尺度,即从7到9,我们的压缩解码器的性能与原始解码器相似,并且仍然优于SD-v1.5。
![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第10张图片](http://img.e-com-net.com/image/info8/bae2daa27f12411c89ebee383cfe8dda.jpg)
4 Step Distillation
We follow the research direction of step distillation [32] , where the inference steps are reduced by distilling the teacher, e.g., at 32 steps , to a student that runs at fewer steps, e.g., 16 steps .
This way, the student enjoys 2× speedup against the teacher.
Here we employ different distillation pipelines and learning objectives from existing works [ 32 , 31 ] to improve the image quality, which we elaborate on as follows.
除了提出扩散模型的高效架构外,我们还进一步考虑减少UNet的迭代去噪步骤,以实现更大的加速。
我们遵循步骤蒸馏的研究方向[32](Progressive Distillation for Fast Sampling),其中通过将教师(例如,32步)蒸馏为以较少步骤(例如,16步)运行的学生来减少推理步骤。
通过这种方式,学生可以享受2倍的速度。
在这里,我们采用不同的蒸馏管道和现有作品中的学习目标[32,31]来提高图像质量,具体说明如下。
4.1 Overview of Distillation Pipeline
Thus, we fine-tune SD-v1.5 to v prediction (for notation clarity, we use ˆ vθ to mean the SD model in v -prediction vs. its ϵ -prediction counterpart ϵ ˆ θ ) before step distillation, with the following original loss Lori:
引用先前研究[32,31]的智慧,step distillation最适合v-prediction类型,即UNet输出速度v[32]而不是噪声ε。
因此,我们将SD-v1.5微调到v prediction(为了表示法清晰,我们使用了vθ表示步进蒸馏前v-预测中的SD模型与ϵ-prediction对应的λ θ),原始损失Lori如下:
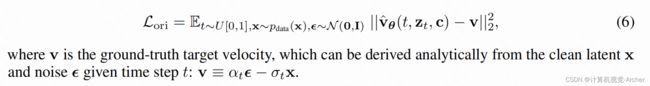
其中v为GT速度,它可以由给定时间步长t的干净潜函数x和噪声函数λ解析得出:v≡α tλ−σtx。
First , we do step distillation on SD-v1.5 to obtain the UNet with 16 steps that reaches the performance of the 50 -step model.
(Note here we use a 32 -step SD-v1.5 to perform distillation directly, instead of doing it progressively , e.g. , using a 128 -step model as a teacher to obtain the 64 -step model and redo the distillation progressively. )
The reason is that we empirically observe that progressive distillation is slightly worse than direct distillation (see Fig. 6 (a) for details).
Second , we use the same strategy to get our 16 -step efficient UNet.
Finally , we use the 16 -step SD-v1.5 as the teacher to conduct step distillation on the efficient UNet that is initialized from its 16 -step counterpart.
This will give us the 8-step efficient UNet, which is our final UNet model.
我们的蒸馏管道包括三个步骤。
1 首先,我们在SD-v1.5上进行分步蒸馏,以获得16步的UNet,达到50步模型的性能。
16step的Unet达到50step的性能
(请注意,这里我们使用32步SD-v1.5直接执行蒸馏,而不是逐步执行,例如,使用128步模型作为教师来获得64步模型并逐步重做蒸馏。)
原因是我们根据经验观察到,渐进蒸馏比直接蒸馏略差(详见图6(a))。![[读论文][2s生成] SnapFusion: Text-to-Image Diffusion Model on MobileDevices within Two Seconds_第11张图片](http://img.e-com-net.com/image/info8/f48d0b4d63554e51ab91b5e039943143.jpg) 蓝色(SD50s) 红色(直接蒸馏8s) 黑色(渐进蒸馏8s)
蓝色(SD50s) 红色(直接蒸馏8s) 黑色(渐进蒸馏8s)
2 其次,我们使用相同的策略来获得16步高效的UNet。
3 最后,我们使用16步的SD-v1.5作为教师,对从16步对应程序初始化的高效UNet进行步骤蒸馏。
这将给我们8步高效的UNet,这是我们最终的UNet模型。
简单来说就是用32步SD-v1.5先蒸馏出16step Unet,然后蒸馏出8step Unet
4.2 CFG-Aware Step Distillation
CFG(Classifier-Free Guidance)是 SD 推理阶段的必备技巧,可以大幅提升图片质量,非常关键!尽管已有工作对扩散模型进行步数蒸馏(Step Distillation)来加速 [4],但是它们没有在蒸馏训练中把 CFG 纳入优化目标,也就是说,蒸馏损失函数并不知道后面会用到 CFG。这一点根据我们的观察,在步数少的时候会严重影响 CLIP score。
为了解决这个问题,我们提出在计算蒸馏损失函数之前,先让 teacher 和 student 模型都进行 CFG,这样损失函数是在经过 CFG 之后的特征上计算,从而显式地考虑了不同 CFG scale 的影响。实验中我们发现,完全使用 CFG-aware Distillation 尽管可以提高 CLIP score, 但 FID 也明显变差。我们进而提出了一个随机采样方案来混合原来的 Step Distillation 损失函数和 CFG-aware Distillation 损失函数,实现了二者的优势共存,既显著提高了 CLIP score,同时 FID 也没有变差。这一步骤,实现进一步推理阶段加速 6.25 倍,实现总加速约 46 倍。
实验部分可以参考这个知乎文章
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了 - 知乎