【ceph】CephFS文件系统和管理
目录
CephFS简介
CephFS组件间通信
CephFS MDS组件
CephFS使用方式
CephFS Layout
CephFS认证
CephFS的 FSCK & Repair
CephFS客户端
内核客户端
FUSE客户端
Rank
设置Rank数量
减少Rank数量
Rank状态查看
高可用配置
CephFS管理命令
文件系统相关
设置相关
最大文件大小和性能
down掉集群
快速关闭群集以进行删除或灾难恢复
守护进程
最低客户端版本
全局设置
高级用法
CephFS简介
cephfs文件系统环境搭建介绍
一、cephfs简介。
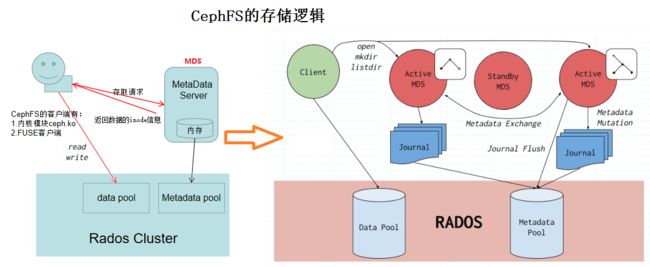
cephfs是一个基于ceph集群且兼容POSIX标准的文件系统。创建cephfs文件系统时需要在ceph集群中添加mds服务,该服务负责处理POSIX文件系统中的metadata部分,实际的数据部分交由ceph集群中的OSDs处理。
cephfs支持以内核模块方式加载也支持fuse方式加载。无论是内核模式还是fuse模式,都是通过调用libcephfs库来实现cephfs文件系统的加载,而libcephfs库又调用librados库与ceph集群进行通信,从而实现cephfs的加载。
cephfs整体框架图如下图所示。
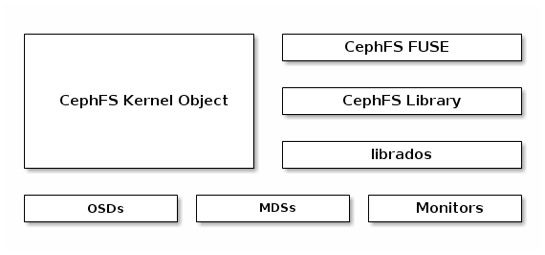
最底层还是基础的OSDs和Monitors,添加了MDSs,上层是支持客户端的CephFS kernel object,CephFS FUSE,CephFS Library等。
CephFS作为Ceph集群最早原生支持的客户端,但成熟的最晚,而最成熟的还是RBD。要想在集群中可以使用CephFS客户端,需要创建至少一个metadata Pool + 一个Data Pool。metadata Pool用来管理元数据信息,并向客户端输出 一个倒置树状的层级结构,这里面存放了真实数据的对应关系,相当于一个索引,Data Pool用来存储真正的数据。
cephFS 在ceph中的位置:

cephFS 在业务流中的位置:
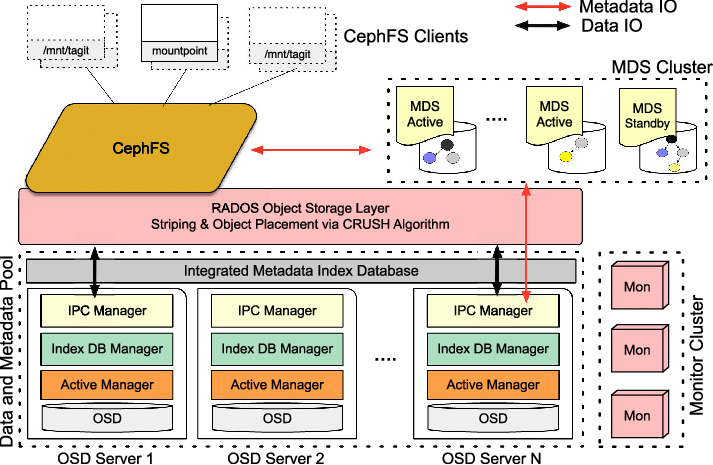
CephFS组件间通信
connections
如上图所示,CephFS各个组件间通信如下:
-
Client <--> MDS
元数据操作和capalities
-
Client <--> OSD
数据IO
-
Client <--> Monitor
认证,集群map信息等
-
MDS <--> Monitor
心跳,集群map信息等
-
MDS <--> OSD
元数据IO
-
Monitor <--> OSD
心跳,集群map信息等
链接:https://www.jianshu.com/p/30a6a54296bf
CephFS MDS组件
Ceph MDS设计的比较强大,作为一个能存储PB级数据的文件系统,它充分考虑了对元数据服务器的要求,设计了MDS集群。另外也引入了MDS的动态子树迁移,MDS的热度负载均衡。
但也正是这么超前的设计,使得MDS集群很难做到稳定,所以目前Jewel版本里默认还是单MDS实例,用户可配置主从MDS实例,提高可用性。 但在未来,MDS集群的这些属性都将稳定下来,为我们提供超强的元数据管理性能。
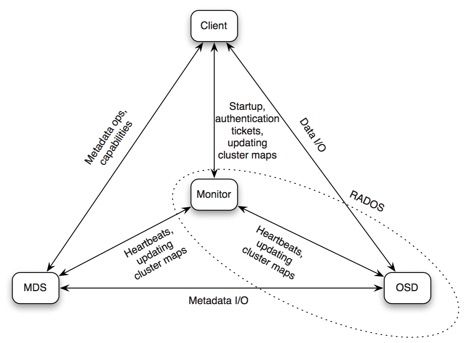
cephfs mds
上图描述了CephFS的Dynamic subtree partition功能,它支持目录分片在多个MDS之间服务,并支持基于MDS负载均衡的动态迁移。
Client跟MDS通信后,会缓存对应的“目录-MDS”映射关系,这样Client任何时候都知道从哪个MDS上获取对应的元数据信息。
MDS自身的元数据有:
-
per-MDS journal
每个MDS都有一个对应的journal文件,支持大到几百兆字节的size,保证元数据的一致性和顺序提交的性能,它也是直接存储到OSD cluster里的
-
CephFS MetaData
MDS管理的CephFS的元数据也以文件格式存储到OSD cluster上,有些元数据信息会存到object的OMAP里
链接:https://www.jianshu.com/p/30a6a54296bf
CephFS使用方式
与通常的网络文件系统一样,要访问cephfs,需要有对应的client端。cephfs现在支持两种client端:
- CephFS kernel client
- since 2.6.34
- CephFS FUSE
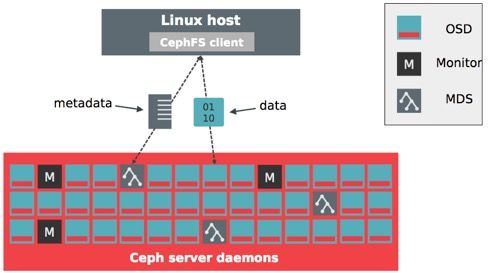 cephfs client
cephfs client
Client端访问CepFS的步骤如下:
- client端与MDS节点通讯,获取metadata信息(metadata也存在osd上)
- client直接写数据到OSD
Client端访问CephFS示例
- Client发送open file请求给MDS
- MDS返回file inode,file size,capability和stripe信息
- Client直接Read/Write数据到OSDs
- MDS管理file的capability
- Client发送close file请求给MDS,释放file的capability,更新file详细信息
这里cephfs并没有像其他分布式文件系统设计的那样,有分布式文件锁来保障数据一致性
它是通过文件的capability来保证的
CephFS相关命令
创建MDS Daemon
# ceph-deploy mds create <…>
创建CephFS Data Pool
# ceph osd pool create <…>
创建CephFS Metadata Pool
# ceph osd pool create <…>
创建CephFS
# ceph fs new <…>
查看CephFS
# ceph fs ls
name: tstfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
删除CephFS
# ceph fs rm --yes-i-really-mean-it
查看MDS状态
# ceph mds stat
e8: tstfs-1/1/1 up tstfs2-0/0/1 up {[tstfs:0]=mds-daemon-1=up:active}
- e8
- e表示epoch
- 8是epoch号
- tstfs-1/1/1 up
- tstfs是cephfs名字
- 三个1分别是 mds_map.in/mds_map.up/mds_map.max_mds
- up是cephfs状态
- {[tstfs:0]=mds-daemon-1=up:active}
- [tstfs:0]指tstfs的rank 0
- mds-daemon-1是服务tstfs的mds daemon name
- up:active是cephfs的状态为 up & active
mount使用CephFS
- CephFS kernel client
# mount -t ceph :6789 /mntdir
# umount /mntdir
- CephFS FUSE
安装ceph-fuse pkg
# yum install -y ceph-fuse
# ceph-fuse -m :6789 /mntdir
# fusermount -u /mntdir
centos7里没有fusermount命令,可以用umount替代
FUSE的IO Path较长,会先从用户态调用到内核态,再返回到用户态使用CephFS FUSE模块访问Ceph集群,如下图所示:
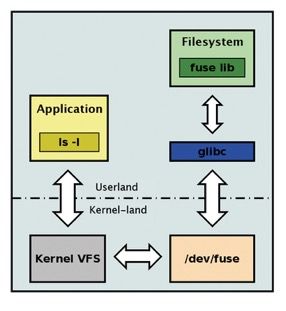 fuse io path
fuse io path
对比
- 性能:Kernel client > ceph-fuse
- Quota支持:只有ceph-fuse(client-side quotas)
Quota不是在CephFS后端实现的,而是在client-side实现的。若某些应用中要求使用Quota,这时就必须考虑使用CephFS FUSE了
CephFS Layout
Cephfs支持配置目录、文件的layout和stripe,这些元数据信息保存在目录和文件的xattr中。
- 目录的layout xattrs为:ceph.dir.layout
- 文件的layout xattrs为:ceph.file.layout
CephFS支持的layout配置项有:
- pool
数据存储到指定pool - namespace
数据存储到指定namespace,比pool更细的粒度(rbd/rgw/cephfs都还不支持) - stripe_unit
条带大小,单位Byte - stripe_count
条带个数
默认文件/目录继承父目录的layout和striping
示例: 配置一个目录的Layout
# setfattr -n ceph.dir.layout -v "stripe_unit=524288 stripe_count=8 object_size=4194304 pool=cephfs_data2" /mnt/mike512K/
目录中一个9MB的文件的layout分布图为:
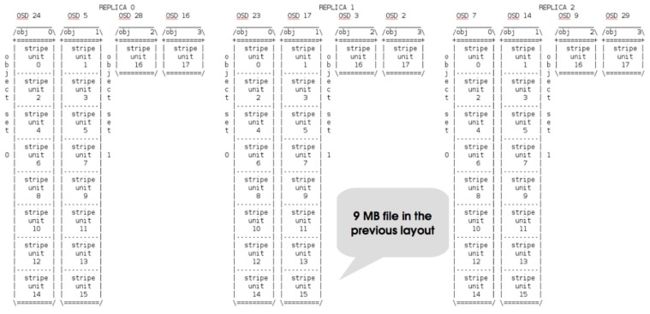 layout example
layout example
CephFS认证
有时候可能应用有这样的需求,不同的用户访问不同的CephFS目录,这时候就需要开启CephFS的认证。
不过首先需要开启的是Ceph集群的认证,然后就可以创建CephFS认证的client端了,指定client对mon,mds,osd的访问权限。
开启Ceph集群认证
配置ceph.conf
# vim /etc/ceph/ceph.conf
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
创建CephFS认证的client
# ceph auth get-or-create client.*client_name* \
mon 'allow r' \
mds 'allow r, allow rw path=/*specified_directory*' \
osd 'allow rw pool=’
示例与解释:
# ceph auth get-or-create client.tst1 mon ‘allow r’ mds ‘allow r, allow rw path=/tst1’ osd ‘allow rw pool=cephfs_data'
-
mon ‘allow r’
允许client从monitor读取数据;必须配置
-
mds ‘allow r, allow rw path=/tst1’
允许client从MDS读取数据,允许client对目录/tst1读写;
其中‘ allow r’必须配置,不然client不能从mds读取数据,mount会报permission error; -
osd ‘allow rw pool=cephfs_data’
允许client从osd pool=cephfs_data 上读写数据;
若不配置,client只能从mds上获取FS的元数据信息,没法查看各个文件的数据
对osd的权限也是必须配置的,不然client只能从mds上获取fs的元数据信息,没法查看文件的数据
检查ceph auth
# ceph auth get client.tst1
exported keyring for client.tst1
[client.tst]
key = AQCd+UBZxpi4EBAAUNyBDGdZbPgfd4oUb+u41A==
caps mds = allow r, allow rw path=/tst1"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs_data"
mount测试
# mount -t ceph :6789:/tst1 /mnt -o name=tst1,secret=AQCd+UBZxpi4EBAAUNyBDGdZbPgfd4oUb+u41A==
认证机制不完善
CephFS的认证机制还不完善,上述client.tst1可以mount整个CephFS目录,能看到并读取整个CephFS的文件
# mount -t ceph :6789:/ /mnt -o name=tst1,secret=AQCd+UBZxpi4EBAAUNyBDGdZbPgfd4oUb+u41A==
另外没找到能支持readonly访问某一目录的方法。
只验证了cephfs kernel client,没试过ceph-fuse的认证
CephFS的 FSCK & Repair
FS的fsck和repair对一个文件系统是非常重要的,如果这个没搞定,一个文件系统是不会有人敢用的。
Ceph在Jewel版本里提供了Ready的CephFS的scrub和repair工具,它哪能处理大部分的元数据损坏。
但在使用中请记住两点:
- 修复命令==慎重执行==,需要专业人士操作
- 若命令支持,修复前请先备份元数据
cephfs journal工具
cephfs-journal-tool,用来修复损坏的MDS journal,它支持的命令有下面几类,详细的介绍看下help就明白了。
cephfs-journal-tool:
- inspect/import/export/reset
- header get/set
- event get/apply/recover_dentries/splice
cephfs online check/scrub
ceph tell mds. damage ls
ceph tell mds. damage rm
# scrub an inode and output results
ceph mds mds. scrub_path {force|recursive|repair [force|recursive|repair...]}
cephfs offline repair
cephfs-data-scan init [--force-init]
cephfs-data-scan scan_extents [--force-pool]
cephfs-data-scan scan_inodes [--force-pool] [--force-corrupt]
cephfs-data-scan scan_frags [--force-corrupt]
cephfs-data-scan tmap_upgrade
作者:ictfox
链接:https://www.jianshu.com/p/30a6a54296bf
来源:简书
CephFS客户端
在开始使用CephFS之前需要创建CephFS接口,参考《集群部署之创建CephFS》:https://www.linux-note.cn/?p=85#cephfs。
Ceph支持两种类型的客户端,一种是基于内核模块ceph.ko,这种需要客户端安装ceph-common程序包,并在/etc/ceph/目录下有ceph.conf集群配置文件和用于认证的密钥文件。
另外一种客户端为FUSE客户端,当有些操作系统无法使用ceph.ko内核的时候就可以使用此客户端连接。要求需要安装ceph-fuse程序软件,该客户端也需要从从/etc/ceph目录加载ceph集群配置文件和keyring文件进行连接。
关于如何授权这里也不做过多介绍,参考《认证与授权》,本案例所使用授权如下。
[client.cephfs]
key = AQCoKNVcATH5FxAAQ3m90iGjtLvsTtiKEFGl7g==
caps mds = "allow *"
caps mon = "allow r"
caps osd = "allow * pool=cehpfs-metadata, allow * pool=cehpfs-data"授权命令如下。
~]$ ceph auth add client.cephfs mds "allow *" mon "allow r" osd "allow * pool=cehpfs-metadata, allow * pool=cehpfs-data"需要指定对源数据存储池和实际数据存储池都有权限。
内核客户端
安装ceph-common软件包,复制集群配置文件和用户keyring文件至目标节点/etc/ceph目录。
命令行挂载
~]# mount -t ceph 192.168.6.126:6789,192.168.6.127:6789,192.168.6.128:6789:/ /mnt -o name=cephfs,secretfile=/etc/ceph/cephfs.key- -t:指定使用ceph协议,接着后面指定mon节点的访问IP与端口,可以指定多个,使用逗号分隔,默认端口为6789。最后使用 / 代表要挂载根目录,挂载到本地的/mnt目录。
- -o:指定挂载的选项,name为用户名,这里的用户为用户ID,不可使用用户标识。secretfile指定该用户的Key,可以指定Key文件路径,也可以直接指定Key字符串。
注意:cephfs.key文件内只能包含用户的Key。
挂载成功后在客户端节点使用下面命令可以查看挂载的信息。
~]# stat -f /mnt
通过fstab客户端挂载
在/etc/fstab文件内写下如面格式的内容即可。
192.168.6.126:6789,192.168.6.127:6789,192.168.6.128:6789:/ /mnt ceph name=cephfs,secretfile=/etc/ceph/cephfs.key,_netdev,noatime 0 0(注意!!如果手工修改了 /etc/fstab文件,一定要执行 sudo findmnt --verify 来检查一下。因为 /etc/fstab 文件改错了导致系统重启起不来)
卸载
~]# umount /mntFUSE客户端
安装ceph-fuse软件包,复制集群配置文件和用户keyring文件至目标节点/etc/ceph目录。
命令行挂载
~]# ceph-fuse -n client.cephfs -m 192.168.6.126:6789,192.168.6.127:6789,192.168.6.128:6789 /mnt/- -n:指定用户标识。
- -m:指定monitor节点信息,之后再指定挂载的目标 。
通过fatab文件挂载
在/etc/fstab文件内写下如面格式的内容即可。
none /mnt fuse.ceph ceph.id=cephfs,ceph.conf=/etc/ceph/ceph.conf,_netdev,noatime 0 0ceph.id需要为用户的ID,而不是用户标识。
(注意!!手工修改了 /etc/fstab文件,一定要执行 sudo findmnt --verify 来检查一下。因为 /etc/fstab 文件改错了导致系统重启起不来)
卸载
~]# fusermount /mnt/Rank
在MDS集群中每一个MDS进程由一个Rank进行管理,Rank数量由max_mds参数配置,默认为1。每个Rank都有一个编号。编号从0开始。
rank有三种状态:
- up:代表 Rank已经由某个MDS守护进程接管。
- failed:代表未被接管。
- damaged:代表损坏,元数据丢失或崩溃,可以使用命令ceph mds repaired修复,在未被修复之前Rank不会被分配给任何守护进程。
如果要对MDS进程做高可用,就可以启动多个MDS,然后设置多个Rank,这时候每个MDS就会关联至对应的Rank来实现高用。通常MDS的数量为Rank数量的两倍,这样可以保证任何一个Rank出现问题(Rank出现问题也就相当于MDS出现问题)有另外的MDS进程马上进行替换。
设置Rank数量
~]$ ceph fs set cephfs max_mds 2减少Rank数量
减少Rank数量就也使用max_mds参数设置,设置的数量小于当前数量就相当于减少。如果Rank数减少需要手动关闭被停止的Rank,可以使用命令ceph fs status查看减少后被停止的Rank,然后执行如下命令关闭被停止的Rank。
~]$ ceph mds deactivate 1这里的 1为rank的编号。
Rank状态查看
[cephadmin@ceph-monitor-1 ~]$ ceph mds stat
cephfs-2/2/2 up {0=ceph-monitor-1=up:active,1=ceph-monitor-2=up:active}, 1 up:standby- cephfs-2/2/2 up:cephfs是CephFS的名称,后面3个分别是已经分配的 Rank数、正常up的Rank数和设置的最大Rank数。
- 0=ceph-monitor-1=up:active:代表第0个rank关联到了ceph-monitor-1节点,并且状态为up。
- 1 up:standby:代表有1个备份。
高可用配置
假设启动4个MDS进程,设置2个Rank。这时候有2个MDS进程会分配给两个Rank,还剩下2个MDS进程分别作为另外个的备份。
1. 增加MDS实例数量与Rank数量。
2. 增加完成后再查看CephFS状态如下。
[SDS_Admin@rdma58 bin]$ ceph fs status
2022-01-22 17:14:31.867395 7f58a0bcc700 3063830 80 WARN 0 -- 172.17.31.58:0/24016594 >> 172.17.31.56:6829/1928792 conn(0x7f588400fb50 :54914 s=STATE_OPEN_MESSAGE_READ_FRONT pgs=40403 cs=1 l=1).process read message front not complete, len: 1854
CAPFS - 0 clients
=====
+------+--------+------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------+---------------+-------+-------+
| 0 | active | mds1 | Reqs: 0 /s | 0 | 0 |
+------+--------+------+---------------+-------+-------+
+--------------------------+----------+-------+-------+
| Pool | type | used | avail |
+--------------------------+----------+-------+-------+
| .capfs.metadata.Metadata | metadata | 2600k | 788G |
| .capfs.data.datapool0 | data | 1331M | 3938G |
+--------------------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| mds2 |
| mds0 |
+-------------+
+--------------------------------------------------------------------------------------------------------+---------+
| version | daemons |
+--------------------------------------------------------------------------------------------------------+---------+
| unknown | mds2 |
| ceph version 12.2.1-UniStorOS_V100R001B61 (63a744c16fdbb7855b3ab6d5b361a628ebb1e9be) luminous (stable) | mds1 |
| ceph version 12.2.1-UniStorOS_V100R001B62 (d81977ed9a8ef9885005c26bc23d4f5cf2d83801) luminous (stable) | mds0 |
+--------------------------------------------------------------------------------------------------------+---------+通过上图可以看出有两个Rank,分别关联到了ceph-monitor-1和ceph-monitor-2的MDS,并且状态为active。在最后面有两个备份的MDS,分别为ceph-monitor-3和ceph-storage-2。
3. 设置每个Rank的备份MDS,也就是如果此Rank当前的MDS出现问题马上切换到另个MDS。设置备份的方法有很多,常用选项如下。
- mds_standby_replay:值为true或false,true表示开启replay模式,这种模式下主MDS内的数量将实时与从MDS同步。如果主宕机,从可以快速的切换。如果为false只有宕机的时候才去同步数据,这样会有一段时间的中断。
- mds_standby_for_name:设置当前MDS进程只用于备份于指定名称的MDS。
- mds_standby_for_rank:设置当前MDS进程只用于备份于哪个Rank,通常为Rank编号。另外在存在之个CephFS文件系统中,还可以使用mds_standby_for_fscid参数来为指定不同的文件系统。
- mds_standby_for_fscid:指定CephFS文件系统ID,需要联合mds_standby_for_rank生效,如果设置mds_standby_for_rank,那么就是用于指定文件系统的指定Rank,如果没有设置,就是指定文件系统的所有Rank。
上面的配置需要写在ceph.conf配置文件,按本实验目标,在管理节点上修改ceph.conf配置文件,配置如下。
[mds.ceph-monitor-3]
mds_standby_for_name = mon.ceph-monitor-2
mds_standby_replay = true
[mds.ceph-storage-2]
mds_standby_for_name = mon.ceph-monitor-1
mds_standby_replay = true通过以上的配置mon.ceph-monitor-3就作为了mon.ceph-monitor-2的备份,并且实时的同步数据。而mon.ceph-storage-2为mon.ceph-monitor-1的备份,也是实时的同步数据。如果想让某一个MDS可以作用于多个MDS的备份,可配置如下。
[mds.ceph-storage-2]
mds_standby_for_fscid = 1指定CephFS文件系统的ID为1,如果不指定mds_standby_for_rank,代表备份于编号1的文件系统下面的所有MDS,此方法无法实际同步数据。
修完配置后需要同步到指定的节点,然后重启MDS进程所对应的服务。
摘抄or参考自:Ceph存储(七)CephFS详解https://www.linux-note.cn/?p=218
CephFS管理命令
腿快抖断了2019-12-25 11:24:26博主文章分类:Ceph©著作权
这些命令在你的Ceph集群中的CephFS文件系统上运,注意,默认情况下仅允许使用一个文件系统,要启用创建多个文件系统,请使用 ceph fs flag set enable_multiple true命令
文件系统相关
ceph fs new
这条命令创建一个新的文件系统,文件系统名称和元数据池名称很清晰明了。指定的数据池是默认数据池,一旦设置便无法更改,每个文件系统都有自己的一组MDS守护程序分配给等级,因此请确保你有足够的备用守护程序来容纳新文件系统
ceh fs ls
列出已有的文件系统
ceph fs dump [epoch]
这将在给定的时期(默认值:当前)转储FSMap,其中包括所有文件系统设置,MDS守护程序及其所拥有的等级以及备用MDS守护程序的列表
ceph fs rm
[–yes-i-really-mean-it]
销毁CephFS文件系统,这会从FSMap擦除有关文件系统状态的信息,元数据池和数据池保持不变,必须分别销毁。
ceph fs get
获取有关命名文件系统的信息,包括设置和等级,这是来自fs dump命令的相同信息的子集
ceph fs set
更改文件系统上的设置,这些设置特定于命名文件系统,并且不影响其他文件系统
ceph fs add_data_pool
将数据池添加到文件系统,该池可用于文件布局,作为存储文件数据的备用位置。
ceph fs rm_data_pool
此命令从文件系统的数据池列表中删除指定的池,如果有任何文件具有已删除数据池的布局,则文件数据将不可用,无法删除默认数据池(在创建文件系统时创建的第一个数据池)
设置相关
ceph fs set
max_file_size
CephFS具有可配置的最大文件大小,默认情况下为1TB,如果希望在CephFS中存储大文件,则可以将此限制设置得更高,它是一个64位字段。 将max_file_size设置为0不会禁用该限制,它将仅限制客户端的权限为仅有权限创建空文件。
最大文件大小和性能
CephFS在追加文件或设置文件大小时会强制执行最大文件大小限制,它不影响以任何存储方式存储的任何内容。 当用户创建一个巨大的文件(不必向其写入任何数据)时,某些操作(例如删除)会导致MDS必须执行大量操作,检查是否存在可能存在的RADOS对象(根据文件大小)
max_file_size设置可防止用户创建艾字节大小的文件,导致MDS上的负载,因为它在进行统计或删除之类的操作期间会尝试枚举对象。
down掉集群
通过设置down 参数来关闭CephFS集群
ceph fs set
down true
恢复集群
ceph fs set
down false
这还将恢复max_mds的先前值,以某种方式关闭MDS守护程序,以便将日记刷新到元数据池,并停止所有客户端的I / O操作。
快速关闭群集以进行删除或灾难恢复
要允许快速删除文件系统(以进行测试)或快速关闭文件系统和MDS守护程序,可以使用fs fail命令,此命令设置文件系统标志,以防止备用文件在文件系统上被激活
ceph fs fail
也可以通过以下操作手动完成此过程
ceph fs set
joinable false
然后,操作员可能会使所有ranks失败,这会导致MDS守护进程作为备用程序重生,文件系统将处于降级的状态
ceph mds fail
:
一旦所有ranks都不活动,也可以删除文件系统或将其保留在该状态下以用于其他目的(也许是灾难恢复),要恢复集群,只需设置joinable标志
ceph fs set
joinable true
守护进程
大多数操作mds的命令都采用
:
:
操作MDS守护程序的命令
ceph mds fail
将MDS守护进程标记为失,这相当于集群将执行这个操作,当MDS守护进程未能向mon发送MDS_beacon_grace second消息的时候。如果守护进程处于活动状态,并且有合适的备用服务器可用,则使用mds fail将强制故障转移到备用服务器。
如果MDS守护进程实际上仍在运行,那么使用MDS fail将导致守护进程重新启动。如果它处于活动状态,并且有备用程序可用,则“失败”的守护程序将作为备用程序返回
ceph tell mds.
command …
将命令发送到MDS守护程序,使用mds.*将命令发送到所有守护程序,使用ceph tell mds.*来查看帮助文档
ceph mds repaired
获取有关Mon的已知的给定MDS的元数据
ceph mds repaired
将文件系统等级标记为已修复,顾名思义,此命令不会更改MDS,它操作已标记为已损坏的文件系统ranks
最低客户端版本
有时需要设置客户端的最低Ceph版本能够正常运行才能连接到CephFS群集。较早的客户端有时可能仍在运行带有可能导致客户端之间锁定问题的错误(由于功能发布)。 CephFS提供了一种设置最低客户端版本的机制
ceph fs set
min_compat_client
例如,仅允许Nautilus客户端使用
ceph fs set cephfs min_compat_client nautilus
运行旧版本的客户端将自动被驱逐
全局设置
ceph fs flag set
[ ]
设置全局CephFS标志(即不特定于特定文件系统),当前,唯一的标志设置是“ enable_multiple”,它允许具有多个CephFS文件系统。 有些标志要求您使用“ –yes-i-really-mean-it”或类似的字符串来提示以确认。在继续之前,请仔细考虑这些操作,因为他们是一些比较危险的操作
高级用法
这些命令在正常操作中不是必需的,在特殊情况下可以使用。不正确地使用这些命令可能会导致严重的问题,例如文件系统无法访问
ceph mds compat rm_compat # 删除兼容性的功能标志
ceph mds compat rm_incompat # 删除不兼容性的功能标志
ceph mds compat show # 显示MDS兼容性标志
ceph mds rmfailed # 从失败的集合中删除rank
ceph fs reset# 此命令将文件系统状态重置为默认名称(名称和池除外),非零rank保存在停止集
摘抄or参考自:CephFS管理命令 https://blog.51cto.com/u_11093860/2461612
推荐文章:https://www.liukui.tech/2019/09/04/Ceph-cephfs%E8%AF%A6%E8%A7%A3/
CEPHFS 内部实现(一):概念篇 - 简书 :https://www.jianshu.com/p/ebb3f44b67b4