线程池入门
线程池入门
- 前言
- 一、预定义线程池
-
- 1.1 FixedThreadPool
- 1.2 CachedThreadPool
- 1.3 SingleThreadExecutor
- 1.4 ScheduledThreadPool
- 二、自定义线程池
-
- 2.1 任务数多但资源占用不大
- 2.2 任务数不多但资源占用大
- 2.3 极端场景情况
- 三、简单使用
前言
在开发程序时,我们总会遇到一些经常使用的资源,例如数据库连接,线程等等,以线程为例,Java里线程并不能直接创建,而是映射到内核上的,此操作需要操作系统的介入才能完成,因此创建线程的代价非常昂贵,不可能在每次任务完成时就将线程丢弃,下次使用时重新创建,于是为了资源的重复利用,诞生了池的概念,使用线程池一方面让线程的创建更加规范,可以合理控制开辟线程的数量;另一方面线程的细节管理交给线程池处理,优化了资源的开销。
下面我们就对线程池的使用方法进行一个详细的概述。
一、预定义线程池
首先来看JDK中Executors类给我们预定义的几种线程池:
1.1 FixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
corePoolSize与maximumPoolSize相等,此方法会创建一个固定大小的线程池,池在创建时就会将其使用时所需的线程全部创建,而无需在池使用时再次创建。
keepAliveTime = 0 该参数默认对核心线程无效 除非设置了allowCoreThreadTimeOut。
workQueue 为LinkedBlockingQueue(无界阻塞队列),队列最大值为Integer.MAX_VALUE。如果任务提交速度持续大余任务处理速度,会造成队列大量阻塞。因为队列很大,很有可能在拒绝策略前,内存溢出,是其劣势。
FixedThreadPool的任务执行是无序的。
1.2 CachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
corePoolSize = 0,maximumPoolSize = Integer.MAX_VALUE,方法会创建一个可变大小的线程池,最大可创建2^29-1个线程(受ThreadPoolExecutor类CAPACITY属性控制)。
keepAliveTime = 60,当池中线程空闲时间大于60s时自动销毁。
workQueue 为 SynchronousQueue (直接提交队列or同步队列),此队列不会保存任务,而是在任务提交时,从池中选择一个空闲线程去执行,如果池中没有空闲线程,会触发线程的创建,创建时,如果池中核心线程数达到上限时会执行拒绝策略,但这几乎不可能,因为再此之前程序基本都已内存溢出(每个线程的创建都会促发栈的创建)。
1.3 SingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
此池的创建和newFixedThreadPool(1)很像,只是在其的基础上使用了FinalizableDelegatedExecutorService进行包装,保证池核心线程数的不可修改,我们看下效果。
public static void main(String[] args) {
ExecutorService fixedExecutorService = Executors.newFixedThreadPool(1);
((ThreadPoolExecutor) fixedExecutorService).setCorePoolSize(2);
ExecutorService singleExecutorService = Executors.newSingleThreadExecutor();
((ThreadPoolExecutor) singleExecutorService).setCorePoolSize(2);
}
运行main时我们会发现singleExecutorService在强转为ThreadPoolExecutor时报了一个异常
Exception in thread “main” java.lang.ClassCastException: java.util.concurrent.Executors$FinalizableDelegatedExecutorService cannot be cast to java.util.concurrent.ThreadPoolExecutor
从堆栈打印的信息我们可以看出FinalizableDelegatedExecutorService 的对象是无法强转为ThreadPoolExecutor的,因此,SingleThreadExecutor被定以后,无法修改其配置,做到了真正的Single。
1.4 ScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
这里池的创建方式好像有了些许不同,不再直接通过ThreadPoolExecutor而是换成ScheduledThreadPoolExecutor类,我们来瞧瞧这个类
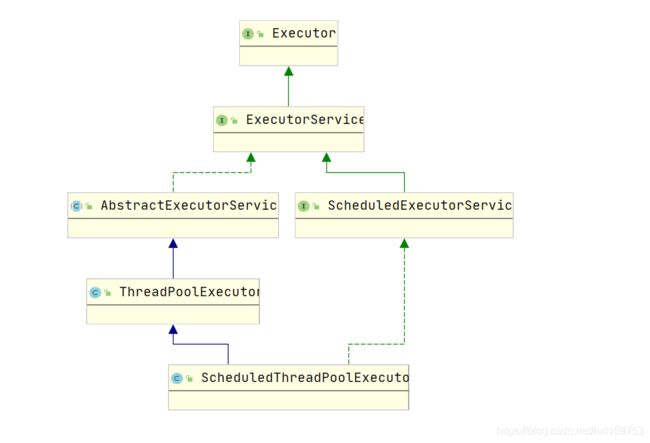
我们可以看到这个类继承了ThreadPoolExecutor,且其构造方法还是在调用ThreadPoolExecutor的构造方法。此队列也有其特点,用来实现定时任务。
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
二、自定义线程池
之前讲述的都是JDK自带的线程池,在开发中一般不推荐使用,因为不够灵活,在Java中线程池的创建一般是通过创建ThreadPoolExecutor对象完成的,以下是其构造方法及参数含义
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
| 名称 | 类型 | 含义 |
|---|---|---|
| corePoolSize | int | 核心线程池大小 |
| maximumPoolSize | int | 最大线程池大小 |
| keepAliveTime | long | 线程最大空闲时间 |
| unit | TimeUnit | 时间单位 |
| workQueue | BlockingQueue | 线程等待队列 |
| threadFactory | ThreadFactory | 线程创建工厂 |
| handler | RejectedExecutionHandler | 拒绝策略 |
相信阅读了以上内容,现在的你对线程池也有了一定的了解,我们不妨试着自己创建一个。
2.1 任务数多但资源占用不大
场景解读:该场景在开发中较为常见,例如短信通知及邮件等,占用资源非常少,处理效率高,但在高并发访问下,可能瞬间会产生大量的事务数,因此在重点在于控制并发线程数,大量的线程启用及线程的上下文频繁切换会导致内存使用率过高,CPU的内核态使用率过高等不良情况发生,通常可以在创建线程池时设置较长的任务队列,并以CPU内核数2-4倍(经验值)设置核心线程与扩展线程数。
BlockingQueue queue = new ArrayBlockingQueue<>(4096);
ThreadPoolExecutor executor = new ThreadPoolExecutor(32, 32, 0, TimeUnit.SECONDS, queue);
2.2 任务数不多但资源占用大
场景解读:该情况多发生于文件流、长文本对象或批量数据加工的处理,此场景下的任务往往会发生较大的资源消耗,通常可以在创建线程池时增加最大线程数量,同时设置较小的任务队列长度及线程回收等待时间,遇到任务数突增情况时,可以有更多的并发线程来应对,在空闲时也能更快的回收线程,
以节省不必要的开销。
BlockingQueue queue = new ArrayBlockingQueue<>(512);
ThreadPoolExecutor executor = new ThreadPoolExecutor(32, 128, 30, TimeUnit.SECONDS, queue);
2.3 极端场景情况
场景解读:如遇任务资源占用较大且任务数较多的场景下,由于任务处理效率不高,为保障系统的稳定性,首先需要考虑的是对任务的发起进行限流,任务的发起能力应当略小于任务处理能力,通过阻塞任务发起方的方式,保护系统的资源开销边界,但可能会导致CPU核心态的使用率高。一般使用直接提交队列
BlockingQueue queue = new SynchronousQueue<>();
ThreadPoolExecutor executor = new ThreadPoolExecutor(128, 128, 0, TimeUnit.SECONDS, queue);
三、简单使用
多线程的使用场景很多,以下将采用自定义线程及线程池的方式进行短信发送。
自定义线程方式代码:
void threadPoolDemo1() throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(100);
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
Thread thread = new Thread(() -> {
System.out.println("开始发送短信");
try {
//模拟耗时
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
});
thread.start();
}
countDownLatch.await();
long endTime = System.currentTimeMillis();
System.out.println("耗时" + (endTime - startTime));
System.out.println("自定义线程程序结束");
}
控制台输出如下

线程池方式代码:
void threadPoolDemo2() throws InterruptedException {
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(100);
//提前创建需要的线程
executor.prestartAllCoreThreads();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
executor.execute(() -> {
System.out.println("开始发送短信");
try {
//模拟耗时
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
executor.shutdown();
if (executor.awaitTermination(Long.MAX_VALUE, TimeUnit.DAYS)) {
long endTime = System.currentTimeMillis();
System.out.println("耗时" + (endTime - startTime));
//关闭线程池成功
} else {
//关闭线程池失败
}
System.out.println("线程池程序结束");
}
控制台打印如下
