【八大排序(五)】快排进阶篇-挖坑法+前后指针法
博主CSDN主页:杭电码农-NEO
⏩专栏分类:八大排序专栏⏪
代码仓库:NEO的学习日记
关注我带你学习排序知识
快排进阶篇
- 1. 前情回顾
- 2. 思路回顾
- 3. 单趟快排挖坑法
- 4. 挖坑法代码实现
- 5. 单趟快排前后指针法
- 6. 前后指针法代码实现
- 7. 总结以及拓展
1. 前情回顾
我们上一章快排初阶 中介绍了
快排的思想和代码实现.
上一期单趟快排
介绍的是hoare版本
今天给大家分享挖坑法和前后指针法
注意:本章介绍的方法均用左边作为基准值
2. 思路回顾
基本思想:
-
从待排序的数组中选取一个基准值.
(我们把基准值记为key) -
再将数组分为两部分:
1. 左子数组所有元素小于基准值
2. 右子数组所有元素大于基准值 -
左右子数组再选基准值重复这个过程
基准值key的选取:
采用三数取中法,详情见上一节快排初阶
怎么实现左右子序小于大于key:
有三种版本的方法:
hoare版本(发明快排的人想出的方法)挖坑版本(国内大佬想出的)前后指针版本
3. 单趟快排挖坑法
基本思路:
- 找到基准值,并记录下来
将基准值的位置挖个坑位- 右边r先走,找比基准值小的
找到后将这个值扔在坑中它本身变成新坑.以此类推- 当左边和右边相遇时
将记录下来的key放在坑位
我们先定义一个无序数组:
int a[10]={6,1,2,7,9,3,4,5,10,8};
我们把最左边元素作为基准值
画图理解:

就这样右找到扔进坑位,左再找扔进坑位
直到左右l 和 r相遇.会发生这种情况:
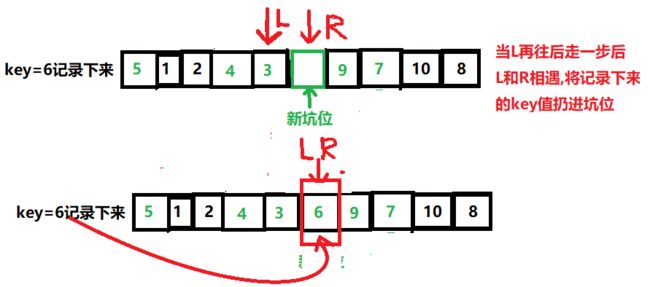
走完单趟快排后,基准值6的
左子数组都小于它
右子数组都大于它
这说明:
6这个值已经来到了最终排好序时
它应该出现的位置
接下来我们只需要不断递归
基准值的左右子序就可以使
整个数组有序
4. 挖坑法代码实现
这里我直接省略掉三数取中函数:
GetMidIndex详情请看快排初阶
这是单趟快排:
//单趟快排(挖坑版本)
int Partion2(int* a, int left, int right)
{
//三数取中--面对有序的情况不会栈溢出(key不会选到最大或者最小的数)
int mini = GetMidIndex(a, left, right);
swap(&a[left], &a[mini]);
int key = a[left];
int pit = left;//坑位起始位置是基准值的位置
while (left < right)
{
//右边找小,放在左边的坑位中
while (a[right] >= key && left < right)
{
right--;
}
a[pit] = a[right];//将找到的值扔进坑位
pit = right;//自身变成新坑位
//左边找大,放在右边的坑位中
while (a[left] <= key && left < right)
{
left++;
}
a[pit] = a[left];//找到的值扔进坑位
pit = left;//自己变成新坑位
}
a[pit] = key;//最终将相遇时的坑位给上最开始记录的key值
return pit;//返回基准值(或者叫坑位)的位置,方便递归
}
这是递归调用函数:
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int key = Partion2(a, left, right);
QuickSort(a, left, key - 1);//递归左子序列
QuickSort(a, key + 1, right);//递归右子序列
}
5. 单趟快排前后指针法
基本思路:
- 定义两个指针cur和prev
- cur指向第二个元素
- prev指向cur前面的元素
c找比基准值小的值找到后停下,p向后走一格再交换c和p指向的值- 最后c走完数组后:
交换key和prev的值
我们还是使用挖坑法的数组:
int a[10]={6,1,2,7,9,3,4,5,10,8};
我们把最左边元素作为基准值
画图理解:

和挖坑法一样:
走完单趟快排后,基准值6的
左子数组都小于它
右子数组都大于它
这说明:
6这个值已经来到了最终排好序时
它应该出现的位置
接下来我们只需要不断递归
基准值的左右子序就可以使
整个数组有序
并且前后指针法和挖坑法
得出的左右子数组顺序不一样
说明它们的底层思想是不同的
6. 前后指针法代码实现
单趟快排:
//单趟快排(前后指针版本)
int Partion3(int* a, int left, int right)
{
//三数取中--面对有序的情况不会栈溢出(key不会选到最大或者最小的数)
int mini = GetMidIndex(a, left, right);
swap(&a[left], &a[mini]);
int key = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
while (a[cur] >= a[key] && cur <= right)//cur指针找小于key的
{
++cur;
}
if (cur <= right)
{
swap(&a[++prev], &a[cur]);
cur++;//交换完后,cur要再往后走一步
}
}
swap(&a[key], &a[prev]);// 最后交换prev和key的值
return prev;//返回基准值的位置,方便下次递归
}
递归函数:
//快速排序
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int key = Partion3(a, left, right);
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}
7. 总结以及拓展
总结:
不管是hoare,挖坑还是指针版本
它们都有一个特性:
递归函数总体是不变的
改变的只是单趟快排实现的方法!
并且,不论是哪种方法实现单趟快排
算法效率也就是时间复杂度都是一样的
快排总归是抽象的
下面有一段快速排序过程
可以帮助你再深刻理解一下这个过程:
快速排序
拓展:
其实很多高效率的排序都是对
低效率的排序做的优化:
比如:
-
快速排序实质上
是对冒泡排序的一种改进 -
堆排序实质上
是对选择排序的一种改进 -
希尔排序实质上
是对插入排序的一种改进
排序在面试基本是必问的内容
往往面试官不会只问你快排的递归版
而是一层层剖析你的学识,问快排的递归
就会问快排的非递归.所以非递归版本
将是你和其他面试者
拉开差距的关键一环!

学编程这一行只能说学无止境
一种方法可以延申出无数种解法